Entraîner votre modèle classifieur d’images avec PyTorch
Remarque
Pour une plus grande fonctionnalité, PyTorch peut également être utilisé avec DirectML sur Windows.
Dans l’étape précédente de ce tutoriel, nous avons acquis le jeu de données que nous allons utiliser pour effectuer la formation de notre classifieur d’images avec PyTorch. À présent, il est temps d’utiliser ces données.
Pour former le classifieur d’images avec PyTorch, vous devez effectuer les étapes suivantes :
- Chargez les données. Si vous avez effectué l’étape précédente de ce didacticiel, vous les avez déjà gérées.
- Définissez un réseau neuronal de convolution.
- Définissez une fonction de perte.
- Formez le modèle sur les données de formation.
- Testez le réseau sur les données de test.
Définissez un réseau neuronal de convolution.
Pour créer un réseau neuronal avec PyTorch, vous allez utiliser le package torch.nn. Ce package contient des modules, des classes extensibles et tous les composants requis pour générer des réseaux neuronaux.
Ici, vous allez créer un réseau neuronal de convolution (CNN) élémentaire pour classer les images à partir du jeu de données CIFAR10.
Un CNN est une classe de réseaux neuronaux, définis comme des réseaux neuronaux multicouches conçus pour détecter des fonctionnalités complexes dans les données. Celles-ci sont le plus souvent utilisées dans les applications de vision par ordinateur.
Notre réseau sera structuré avec les 14 couches suivantes :
Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> MaxPool -> Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> Linear.
Couche de convolution
La couche de convolution est une couche principale du CNN qui nous aide à détecter des fonctionnalités dans les images. Chacune des couches possède un certain nombre de canaux pour détecter des fonctionnalités spécifiques dans les images, et un certain nombre de noyaux pour définir la taille de la fonctionnalité détectée. Par conséquent, une couche de convolution avec 64 canaux et un noyau de taille 3 x 3 détecterait 64 fonctionnalités distinctes, chacune de taille 3 x 3. Lorsque vous définissez une couche de convolution, vous fournissez le nombre de canaux d’entrée, le nombre de canaux de sortie et la taille du noyau. Le nombre de canaux de sortie de la couche sert de nombre de canaux d'entrée à la couche suivante.
Par exemple : une couche de convolution avec in-channels=3, out-channels=10, et kernel-size=6 recevra l'image RGB (3 canaux) comme entrée, et elle appliquera 10 détecteurs de fonctionnalités aux images avec la taille de noyau de 6 x 6. Des noyaux de plus petite taille réduiront le temps de calcul et le partage de pondérations.
Autres couches
Les autres couches suivantes sont impliquées dans notre réseau :
- La couche
ReLUest une fonction d’activation permettant de définir toutes les fonctionnalités entrantes à une valeur supérieure ou égale à 0. Lorsque vous appliquez cette couche, tout nombre inférieur à 0 est transformé en zéro, tandis que les autres restent inchangés. - La couche
BatchNorm2dapplique une normalisation sur les entrées pour obtenir une moyenne nulle et une variance unitaire et augmenter la précision du réseau. - La couche
MaxPoolnous aide à garantir que l’emplacement d’un objet dans une image n’affectera pas la capacité du réseau neuronal à détecter ses fonctionnalités spécifiques. - La couche
Linearest la couche finale de notre réseau, qui calcule les scores de chacune des classes. Le jeu de données CIFAR10 comporte dix classes d’étiquettes. L’étiquette avec le score le plus élevé est celle qui sera prédite par un modèle. Dans la couche linéaire, vous devez spécifier le nombre de fonctionnalités d’entrée et le nombre de fonctionnalités de sortie qui doivent correspondre au nombre de classes.
Comment fonctionne un réseau neuronal ?
Le CNN est un réseau de transfert de flux. Au cours du processus de formation, le réseau traite l’entrée à travers toutes les couches, calcule la perte pour comprendre dans quelle mesure l’étiquette prédite de l’image s’éloigne de l’étiquette correcte, et propage les gradients dans le réseau pour mettre à jour les pondérations des couches. En effectuant une itération sur un jeu de données d’entrées volumineux, le réseau « apprend » à définir ses pondérations pour obtenir les meilleurs résultats.
Une fonction Forward calcule la valeur de la fonction de perte, tandis que la fonction Backward calcule les dégradés des paramètres en apprentissage. Lorsque vous créez notre réseau neuronal avec PyTorch, vous devez définir la fonction Forward. La fonction Backward est définie automatiquement.
- Copiez le code suivant dans le fichier
PyTorchTraining.pydans Visual Studio pour définir le CCN.
import torch
import torch.nn as nn
import torchvision
import torch.nn.functional as F
# Define a convolution neural network
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*10*10, 10)
def forward(self, input):
output = F.relu(self.bn1(self.conv1(input)))
output = F.relu(self.bn2(self.conv2(output)))
output = self.pool(output)
output = F.relu(self.bn4(self.conv4(output)))
output = F.relu(self.bn5(self.conv5(output)))
output = output.view(-1, 24*10*10)
output = self.fc1(output)
return output
# Instantiate a neural network model
model = Network()
Remarque
Vous souhaitez en savoir plus sur le réseau neuronal avec PyTorch ? Consultez la documentation PyTorch
Définir une fonction de perte
Une fonction de perte calcule une valeur qui estime la distance entre la sortie et la cible. L’objectif principal est de réduire la valeur de la fonction de perte en modifiant les valeurs de vecteur de pondération par le biais de la rétropropagation dans les réseaux neuronaux.
La valeur de perte est différente de la précision du modèle. La fonction de perte nous permet de comprendre comment un modèle se comporte après chaque itération d’optimisation sur l’ensemble de formations. La précision du modèle est calculée sur les données de test et indique le pourcentage de la prédiction appropriée.
Dans PyTorch, le package de réseau neuronal contient différentes fonctions de perte qui forment les éléments constitutifs des réseaux neuronaux profonds. Dans ce tutoriel, vous utiliserez une fonction de perte de classification basée sur la fonction de définition de la perte avec la perte de Classification Cross-Entropy et un optimiseur Adam. Le taux d’apprentissage (learning rate, lr) définit le contrôle de la quantité d’ajustement des pondérations de notre réseau en respectant le gradient de perte. Vous allez le définir sur 0,001. Plus l’opération est faible, plus la formation sera lente.
- Copiez le code suivant dans le fichier
PyTorchTraining.pydans Visual Studio pour définir la fonction de perte et un optimiseur.
from torch.optim import Adam
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Formez le modèle sur les données de formation.
Pour former le modèle, vous devez effectuer une boucle sur notre itérateur de données, alimenter les entrées sur le réseau et effectuer l’optimisation. PyTorch ne dispose pas d’une bibliothèque dédiée pour l’utilisation du GPU, mais vous pouvez définir manuellement l’appareil d’exécution. L’appareil sera un GPU NVIDIA s’il existe sur votre ordinateur, ou votre processeur, le cas échéant.
- Ajoutez le code suivant au fichier
PyTorchTraining.py
from torch.autograd import Variable
# Function to save the model
def saveModel():
path = "./myFirstModel.pth"
torch.save(model.state_dict(), path)
# Function to test the model with the test dataset and print the accuracy for the test images
def testAccuracy():
model.eval()
accuracy = 0.0
total = 0.0
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
with torch.no_grad():
for data in test_loader:
images, labels = data
# run the model on the test set to predict labels
outputs = model(images.to(device))
# the label with the highest energy will be our prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
accuracy += (predicted == labels.to(device)).sum().item()
# compute the accuracy over all test images
accuracy = (100 * accuracy / total)
return(accuracy)
# Training function. We simply have to loop over our data iterator and feed the inputs to the network and optimize.
def train(num_epochs):
best_accuracy = 0.0
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device")
# Convert model parameters and buffers to CPU or Cuda
model.to(device)
for epoch in range(num_epochs): # loop over the dataset multiple times
running_loss = 0.0
running_acc = 0.0
for i, (images, labels) in enumerate(train_loader, 0):
# get the inputs
images = Variable(images.to(device))
labels = Variable(labels.to(device))
# zero the parameter gradients
optimizer.zero_grad()
# predict classes using images from the training set
outputs = model(images)
# compute the loss based on model output and real labels
loss = loss_fn(outputs, labels)
# backpropagate the loss
loss.backward()
# adjust parameters based on the calculated gradients
optimizer.step()
# Let's print statistics for every 1,000 images
running_loss += loss.item() # extract the loss value
if i % 1000 == 999:
# print every 1000 (twice per epoch)
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
# zero the loss
running_loss = 0.0
# Compute and print the average accuracy fo this epoch when tested over all 10000 test images
accuracy = testAccuracy()
print('For epoch', epoch+1,'the test accuracy over the whole test set is %d %%' % (accuracy))
# we want to save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
Testez le modèle sur les données de test.
À présent, vous pouvez tester le modèle avec un lot d’images à partir de notre jeu de test.
- Ajoutez le code suivant au fichier
PyTorchTraining.py.
import matplotlib.pyplot as plt
import numpy as np
# Function to show the images
def imageshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# Function to test the model with a batch of images and show the labels predictions
def testBatch():
# get batch of images from the test DataLoader
images, labels = next(iter(test_loader))
# show all images as one image grid
imageshow(torchvision.utils.make_grid(images))
# Show the real labels on the screen
print('Real labels: ', ' '.join('%5s' % classes[labels[j]]
for j in range(batch_size)))
# Let's see what if the model identifiers the labels of those example
outputs = model(images)
# We got the probability for every 10 labels. The highest (max) probability should be correct label
_, predicted = torch.max(outputs, 1)
# Let's show the predicted labels on the screen to compare with the real ones
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(batch_size)))
Enfin, nous allons ajouter le code principal. Cette opération lance la formation du modèle, enregistre le modèle et affiche les résultats à l’écran. Nous n’exécuterons que deux itérations [train(2)] sur l’ensemble de formations de sorte que le processus de formation ne prendra pas trop de temps.
- Ajoutez le code suivant au fichier
PyTorchTraining.py.
if __name__ == "__main__":
# Let's build our model
train(5)
print('Finished Training')
# Test which classes performed well
testAccuracy()
# Let's load the model we just created and test the accuracy per label
model = Network()
path = "myFirstModel.pth"
model.load_state_dict(torch.load(path))
# Test with batch of images
testBatch()
Nous allons exécuter le test ! Assurez-vous que les menus déroulants de la barre d’outils supérieure sont définis sur Debug. Remplacez la plateforme de solution par la plateforme x64 pour exécuter le projet sur votre ordinateur local s’il s’agit d’un appareil 64 bits, ou par la plateforme x86 s’il s’agit d’un appareil 32 bits.
Le choix du nombre d’époques (nombre de passes complètes dans le jeu de données de formation) égal à deux ([train(2)]) signifie que le jeu de données de test complet de 10 000 images fait l’objet de deux itérations. La formation prend environ 20 minutes sur un processeur Intel de 8e génération, et le modèle devrait atteindre un taux de réussite de plus ou moins 65 % dans la classification de dix étiquettes.
- Pour exécuter le projet, cliquez sur le bouton Démarrer le débogage sur la barre d’outils, ou appuyez sur F5.
Dans la fenêtre de la console qui s’affiche, vous pouvez voir le processus de formation.
Comme vous l’avez défini, la valeur de perte sera imprimée tous les 1 000 lots d’images ou cinq fois pour chaque itération sur l’ensemble de formation. Vous vous attendez à ce que la valeur de perte diminue à chaque boucle.
Vous verrez également la précision du modèle après chaque itération. La précision du modèle est différente de la valeur de perte. La fonction de perte nous permet de comprendre comment un modèle se comporte après chaque itération d’optimisation sur l’ensemble de formations. La précision du modèle est calculée sur les données de test et indique le pourcentage de la prédiction appropriée. Dans notre cas, il nous indique combien d’images de l’ensemble de test de 10 000 images notre modèle a été capable de classer correctement après chaque itération de formation.
Une fois la formation terminée, vous devez vous attendre à voir la sortie similaire à celle ci-dessous. Vos chiffres ne seront pas exactement les mêmes - la formation dépend de nombreux facteurs et ne donne pas toujours des résultats identiques - mais ils devraient être similaires.
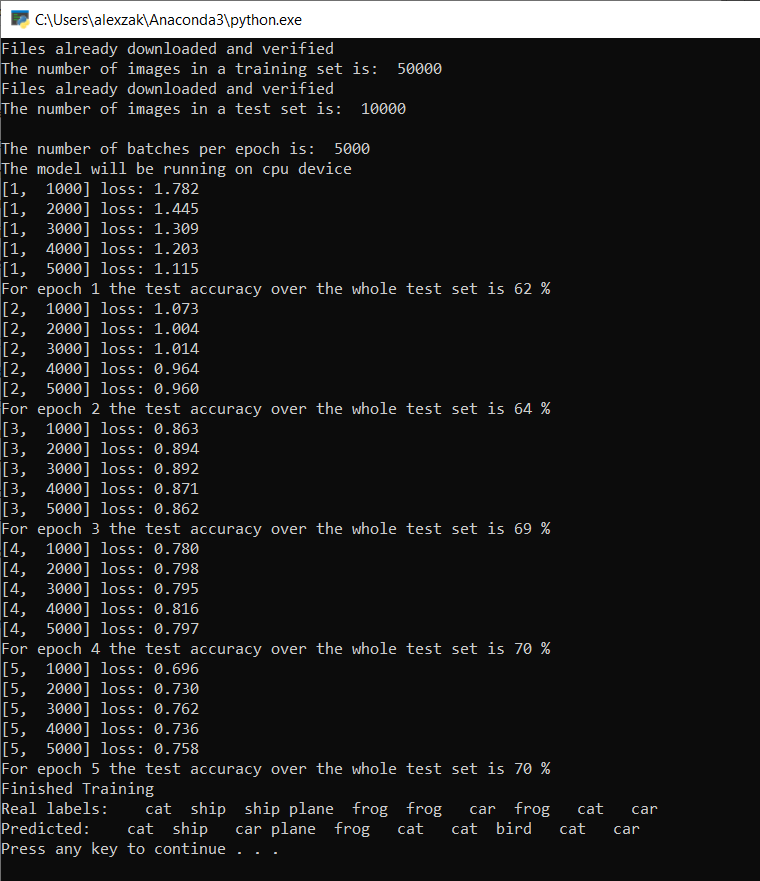
Après avoir exécuté seulement 5 époques, le taux de réussite du modèle est de 70 %. C’est un bon résultat pour un modèle de base formé pendant une période limitée.
Dans le test réalisé avec le lot de 10 images, le modèle a obtenu 7 images. Pas mal du tout et conforme au taux de réussite du modèle.

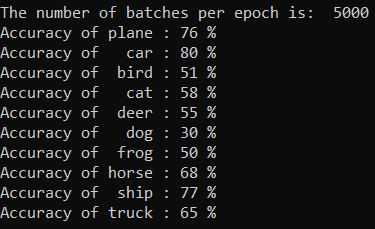
Vous pouvez contrôler les classes que notre modèle peut prédire le mieux. Ajoutez simplement le code ci-dessous :
- Facultatif - ajoutez la fonction
testClassesssuivante dans le fichierPyTorchTraining.py, puis ajoutez un appel de cette fonction -testClassess()à l’intérieur de la fonction principale -__name__ == "__main__".
# Function to test what classes performed well
def testClassess():
class_correct = list(0. for i in range(number_of_labels))
class_total = list(0. for i in range(number_of_labels))
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(batch_size):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(number_of_labels):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
La sortie se présente comme suit :
Étapes suivantes
Maintenant que nous disposons d’un modèle de classification, l’étape suivante consiste à convertir le modèle au format ONNX