Préparer les données
Remarque
Pour une plus grande fonctionnalité, PyTorch peut également être utilisé avec DirectML sur Windows.
Dans l’étape précédente de ce tutoriel, nous avons installé PyTorch sur votre ordinateur. À présent, nous allons l’utiliser pour configurer notre code avec les données que nous allons utiliser pour créer notre modèle.
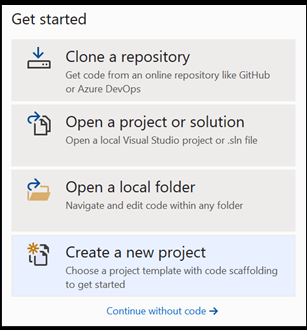
Ouvrez un nouveau projet dans Visual Studio.
- Ouvrez Visual Studio et choisissez
create a new project.
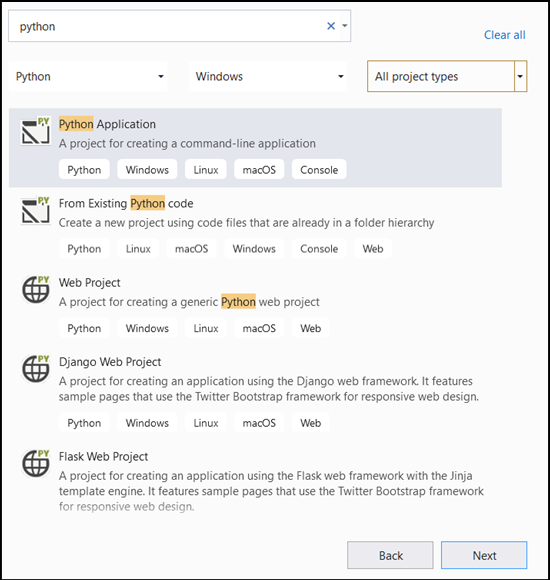
- Dans la barre de recherche, tapez
Pythonet sélectionnezPython Applicationcomme modèle de projet.
- Dans la fenêtre de configuration :
- Nommez votre projet. Ici, nous l’appelons PyTorchTraining.
- Choisissez l’emplacement du projet.
- Si vous utilisez VS 2019, vérifiez que la case
Create directory for solutionest cochée. - Si vous utilisez VS2017, vérifiez que la case
Place solution and project in the same directoryn’est pas cochée.
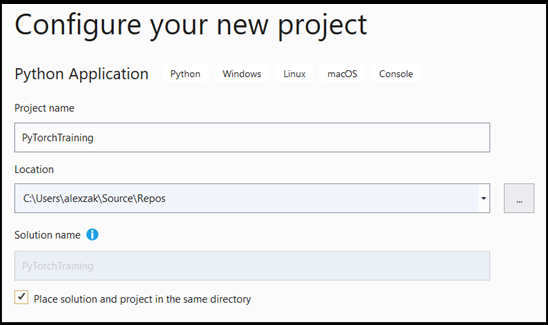
Appuyez sur create pour créer votre projet.
Créer un interpréteur Python
Maintenant, vous devez définir un nouvel interpréteur Python. Cela doit inclure le package PyTorch que vous avez récemment installé.
- Accédez à sélection de l’interpréteur, puis sélectionnez
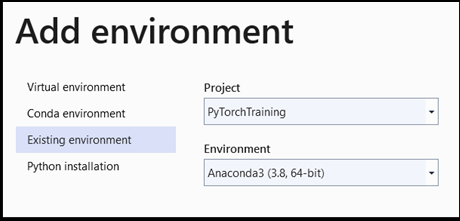
Add environment:
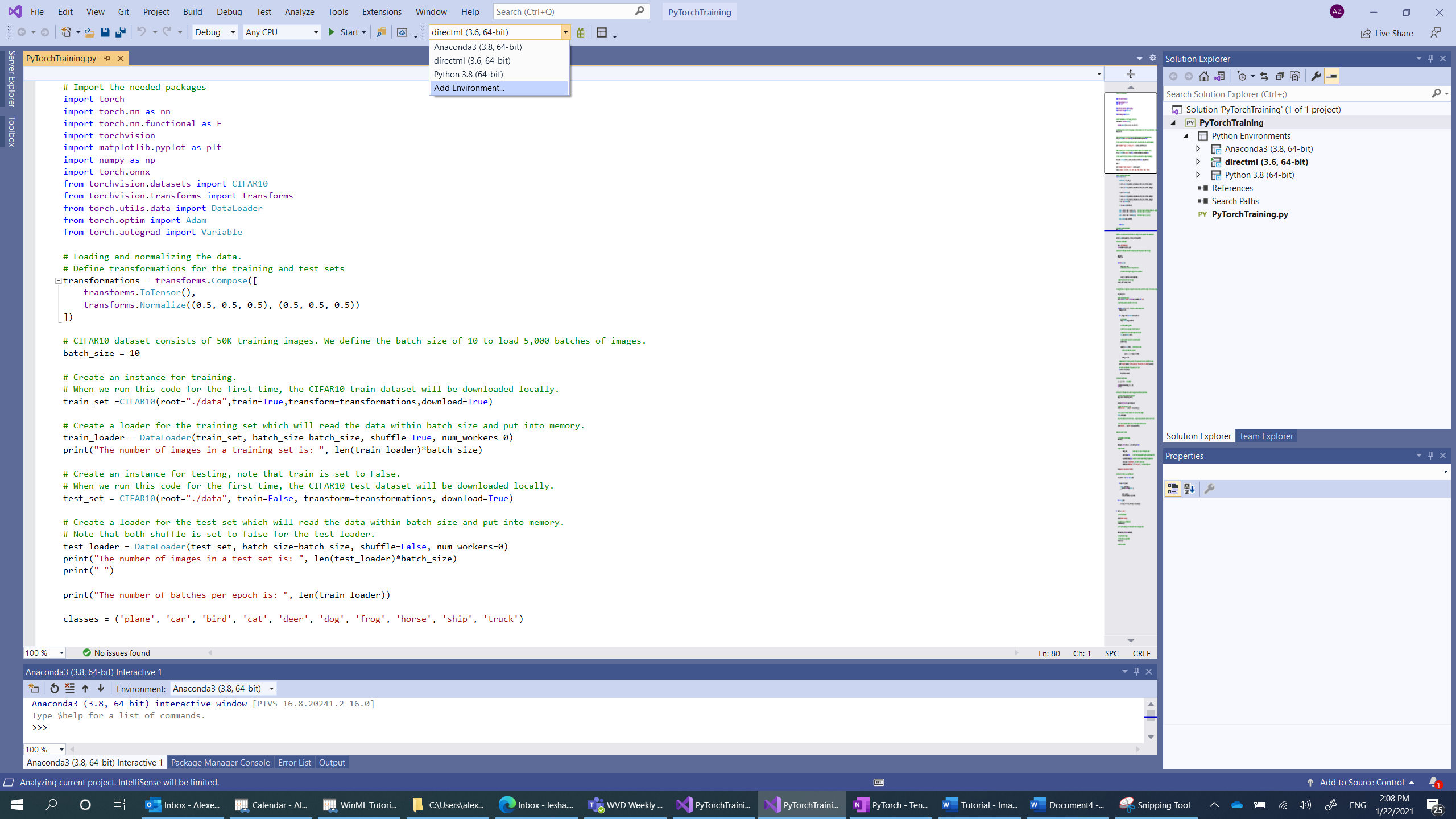
- Dans la fenêtre
Add environment, sélectionnezExisting environment, puis choisissezAnaconda3 (3.6, 64-bit). Cela inclut le package PyTorch.
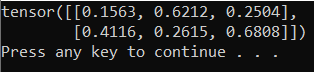
Pour tester le nouvel interpréteur Python et le nouveau package PyTorch, entrez le code suivant dans le fichier PyTorchTraining.py :
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
La sortie doit être un tenseur 5x3 aléatoire semblable à celle ci-dessous.
Remarque
Vous voulez en savoir plus ? Visitez le site web officiel de PyTorch.
Chargement du jeu de données
Vous utiliserez la classe torchvision PyTorch pour charger les données.
La bibliothèque Torchvision comprend plusieurs jeux de données populaires tels que Imagenet, CIFAR10, MNIST, etc., des architectures de modèle et des transformations d’image courantes pour la vision par ordinateur. Cela facilite assez bien le chargement des données dans PyTorch.
CIFAR10
Ici, nous allons utiliser le jeu de données CIFAR10 pour créer et effectuer l’entraînement du modèle de classification d’images. CIFAR10 est un jeu de données largement utilisé pour la recherche de Machine Learning. Il se compose de 50 000 images d’entraînement et de 10 000 images de test. Toutes sont de taille 3x32x32, ce qui signifie que les images de couleur à 3 canaux ont une taille de 32x32 pixels.
Les images sont divisées en 10 classes : « avion » (0), « automobile » (1), « oiseau » (2), « chat » (3), « cerf » (4), « chien » (5), « grenouille » (6), « cheval » (7), « bateau » (8), « camion » (9).
Vous allez suivre trois étapes pour charger et lire le jeu de données CIFAR10 dans PyTorch :
- Définissez les transformations à appliquer à l’image : pour entraîner le modèle, vous devez transformer les images en tenseurs de plages normalisées [-1, 1].
- Créez une instance du jeu de données disponible et chargez le jeu de données : pour charger les données, vous allez utiliser la classe
torch.utils.data.Dataset, une classe abstraite permettant de représenter un jeu de données. Le jeu de données est téléchargé localement uniquement la première fois que vous exécutez le code. - Accédez aux données à l’aide de DataLoader. Pour accéder aux données et les placer en mémoire, vous allez utiliser la classe
torch.utils.data.DataLoader. DataLoader dans PyTorch inclut dans un wrapper un jeu de données et fournit l’accès aux données sous-jacentes. Ce wrapper contiendra des lots d’images par taille de lot définie.
Vous allez répéter ces trois étapes à la fois pour les jeux d’entraînement et les jeux de test.
- Ouvrez le
PyTorchTraining.py filedans Visual Studio, puis ajoutez le code suivant. Cela permet de gérer les trois étapes ci-dessus pour les jeux de données d’entraînement et de test à partir du jeu de données CIFAR10.
from torchvision.datasets import CIFAR10
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
# Loading and normalizing the data.
# Define transformations for the training and test sets
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR10 dataset consists of 50K training images. We define the batch size of 10 to load 5,000 batches of images.
batch_size = 10
number_of_labels = 10
# Create an instance for training.
# When we run this code for the first time, the CIFAR10 train dataset will be downloaded locally.
train_set =CIFAR10(root="./data",train=True,transform=transformations,download=True)
# Create a loader for the training set which will read the data within batch size and put into memory.
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
print("The number of images in a training set is: ", len(train_loader)*batch_size)
# Create an instance for testing, note that train is set to False.
# When we run this code for the first time, the CIFAR10 test dataset will be downloaded locally.
test_set = CIFAR10(root="./data", train=False, transform=transformations, download=True)
# Create a loader for the test set which will read the data within batch size and put into memory.
# Note that each shuffle is set to false for the test loader.
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)
print("The number of images in a test set is: ", len(test_loader)*batch_size)
print("The number of batches per epoch is: ", len(train_loader))
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
La première fois que vous exécutez ce code, le jeu de données CIFAR10 est téléchargé sur votre appareil.

Étapes suivantes
Une fois les données prêtes à l’emploi, il est temps d’effectuer l’entraînement de notre modèle PyTorch