Comprendre les pipelines
Les pipelines dans Microsoft Fabric encapsulent une séquence d’activités qui effectuent des tâches de déplacement et de traitement des données. Vous pouvez utiliser un pipeline pour définir des activités de transfert et de transformation de données, et orchestrer ces activités via des activités de flux de contrôle qui gèrent le branchement, le bouclage et d’autres logiques de traitement standard. Le canevas de pipeline graphique dans l’interface utilisateur Fabric vous permet de créer des pipelines complexes avec un développement minimal ou nul.
Concepts principaux des pipelines
Avant de créer des pipelines dans Microsoft Fabric, vous devez comprendre quelques concepts de base.
Activités
Les activités sont les tâches exécutables dans un pipeline. Vous pouvez définir un flux d’activités en les connectant dans une séquence. Le résultat d’une activité particulière (réussite, échec ou achèvement) peut être utilisé pour diriger le flux vers l’activité suivante dans la séquence.
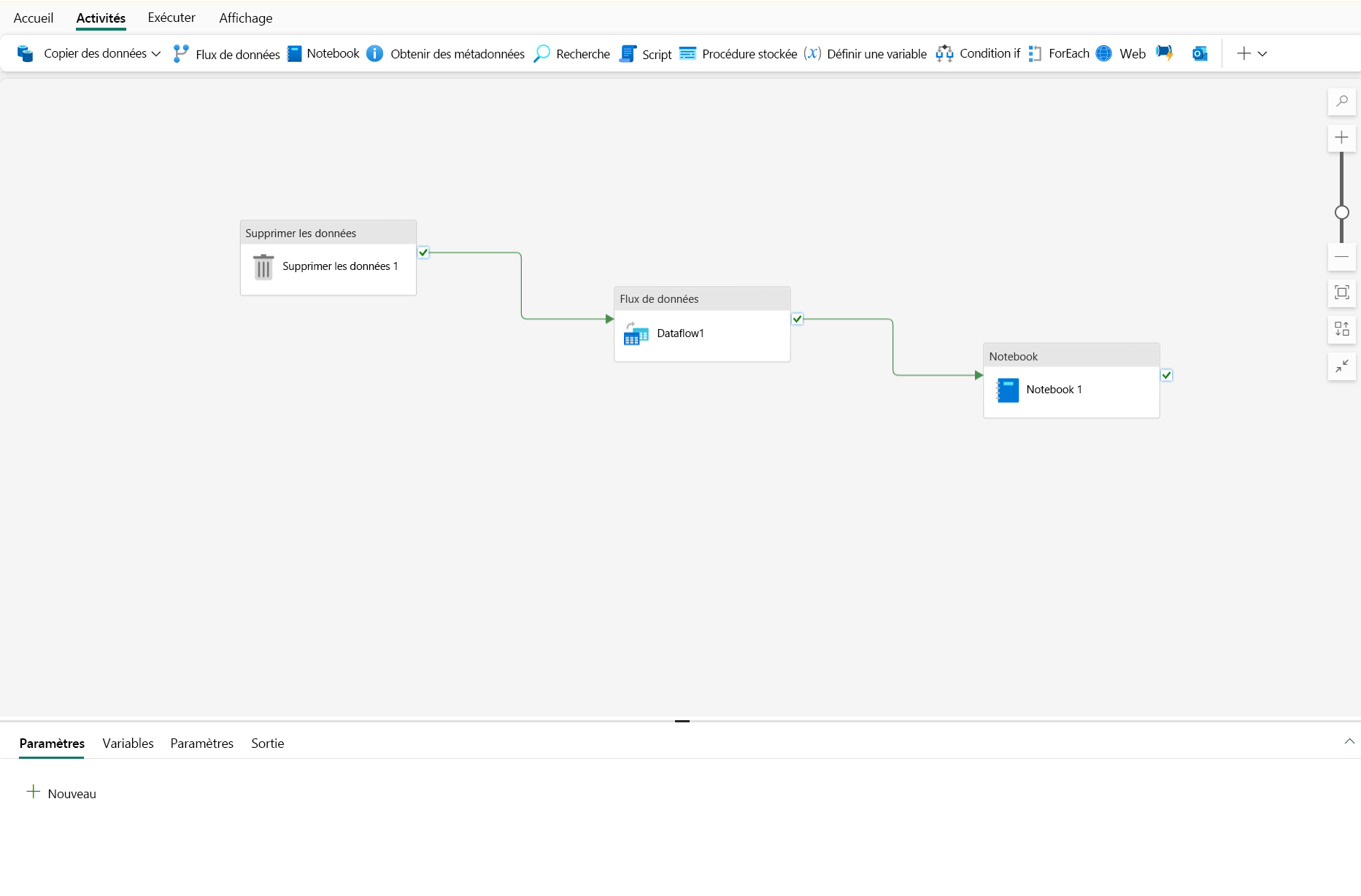
Il existe deux grandes catégories d’activités dans un pipeline.
Activités de transformation des données : activités qui encapsulent des opérations de transfert de données, y compris les activités de copie de données simples qui extraient des données d’une source et les chargent dans une destination, et les activités de flux de données plus complexes qui encapsulent des flux de données (Gen2) qui appliquent des transformations aux données au fur et à mesure qu’elles sont transférées. Parmi les autres activités de transformation des données citons les activités de notebook, pour exécuter un notebook Spark, les activités de procédure stockée, pour exécuter du code SQL, et les activités de suppression de données, pour supprimer des données existantes. Dans OneLake, vous pouvez configurer la destination sur un lakehouse, un entrepôt, une base de données SQL ou d’autres options.
Activités de flux de contrôle : activités que vous pouvez utiliser pour implémenter des boucles, des branches conditionnelles, ou pour gérer des valeurs de variables et de paramètres. Le large éventail d’activités de flux de contrôle vous permet d’implémenter une logique de pipeline complexe pour orchestrer l’ingestion et le flux de transformation des données.
Conseil
Pour plus d’informations sur l’ensemble complet des activités de pipeline disponibles dans Microsoft Fabric, consultez Vue d’ensemble des activités dans la documentation de Microsoft Fabric.
Paramètres
Les pipelines peuvent être paramétrisés, ce qui vous permet de fournir des valeurs spécifiques à utiliser chaque fois qu’un pipeline est exécuté. Par exemple, vous pouvez utiliser un pipeline pour enregistrer les données ingérées dans un dossier, mais avoir la possibilité de spécifier un nom de dossier chaque fois que le pipeline est exécuté.
L’utilisation de paramètres augmente la réutilisabilité de vos pipelines, ce qui vous permet de créer des processus flexibles d’ingestion et de transformation des données.
Exécutions de pipeline
Chaque fois qu’un pipeline est exécuté, une exécution de pipeline de données est lancée. Les exécutions peuvent être lancées à la demande dans l’interface utilisateur de Fabric ou planifiées pour démarrer à une fréquence spécifique. Utilisez l’ID d’exécution unique pour passer en revue les détails de l’exécution afin de vérifier qu’elle s’est déroulée correctement et d’examiner les paramètres spécifiques utilisés pour chaque exécution.