Prise en main des index columnstore pour l’analytique opérationnelle en temps réel
S’applique à : ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Base de données SQL dans Microsoft Fabric
Base de données SQL dans Microsoft Fabric
SQL Server 2016 (13.x) introduit l’analytique opérationnelle en temps réel, la possibilité d’exécuter à la fois des charges de travail analytiques et OLTP sur les mêmes tables de base de données en même temps. Outre l’exécution de l’analytique en temps réel, vous pouvez également éliminer le besoin d’opérations d’extraction, de transformation et de chargement ainsi que le besoin d’un entrepôt de données.
Analytique opérationnelle en temps réel expliquée
En règle générale, les entreprises ont des systèmes séparés pour les charges de travail opérationnelles (autrement dit, OLTP) et analytiques. Pour ces systèmes, les tâches d’extraction, de transformation et de chargement (ETL) déplacent régulièrement les données du magasin opérationnel vers un magasin d’analytiques. Les données analytiques sont généralement stockées dans un entrepôt de données ou un mini-Data Warehouse dédié à l’exécution de requêtes analytiques. Même si cette solution constitue la norme, elle présente les trois principaux inconvénients suivants :
Complexité. L’implémentation des opérations ETL peut nécessiter un codage important, en particulier pour charger uniquement les lignes modifiées. Il peut être difficile d’identifier les lignes qui ont été modifiées.
Coût : L’implémentation des opérations ETL implique le coût de l’achat de licences logicielles et matérielles supplémentaires.
Latence des données. L’implémentation des opérations ETL ajoute un délai pour l’exécution de l’analytique. Par exemple, si la tâche ETL est exécutée à la fin de chaque journée de travail, les requêtes analytiques sont exécutées sur des données qui ont au moins un jour. Pour de nombreuses entreprises, ce délai est inacceptable, car les affaires dépendent de l’analyse des données en temps réel. Par exemple, la détection des fraudes nécessite l’analytique en temps réel des données opérationnelles.
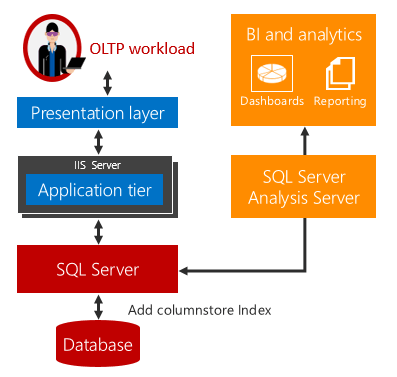
L’analytique opérationnelle en temps réel offre une solution à ces inconvénients.
Il n’existe aucun délai quand les charges de travail analytiques et OLTP sont exécutées sur la même table sous-jacente. Pour les scénarios qui peuvent utiliser l’analytique en temps réel, les coûts et la complexité sont considérablement réduits en éliminant le besoin d’opérations ETL et la nécessité d’acheter et de gérer un entrepôt de données distinct.
Remarque
L’analytique opérationnelle en temps réel cible le scénario d’une source de données unique comme une application ERP (Enterprise Resource Planning) sur laquelle vous pouvez exécuter à la fois les charges de travail opérationnelles et analytiques. Cela ne remplace pas la nécessité d’un entrepôt de données distinct quand vous avez devez intégrer des données provenant de plusieurs sources avant d’exécuter la charge de travail analytique ou que vous avez besoin de performances analytiques très élevées avec des données préagrégées telles que des cubes.
L’analytique en temps réel utilise un index columnstore modifiable sur une table rowstore. L’index columnstore gère une copie des données pour que les charges de travail OLTP et analytiques soient exécutées sur des copies distinctes des données. Cela réduit l’impact sur les performances de ces deux charges de travail en cours d’exécution en même temps. SQL Server gère automatiquement les modifications d’index pour que les changements OLTP soient toujours à jour pour l’analytique. Grâce à cette conception, il est possible et pratique d’exécuter l’analytique en temps réel sur des données à jour. Cela fonctionne aussi bien pour les tables sur disque que pour les tables optimisées en mémoire.
Exemple de prise en main
Pour commencer à utiliser l’analytique en temps réel :
Identifiez les tables de votre schéma opérationnel qui contiennent les données requises pour l’analytique.
Pour chaque table, supprimez tous les index d’arbre B principalement conçus pour accélérer l’analytique existante sur votre charge de travail OLTP. Remplacez-les par un index columnstore unique. Cela peut améliorer les performances globales de votre charge de travail OLTP, car il y aura moins d’index à gérer.
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;L’index columnstore sur une table en mémoire permet l’analytique opérationnelle en intégrant des technologies OLTP et columnstore en mémoire pour offrir des performances élevées pour les charges de travail OLTP et analytiques. L’index columnstore sur une table en mémoire doit inclure toutes les colonnes.
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON ); GO
Vous êtes maintenant prêt à exécuter l’analytique opérationnelle en temps réel sans apporter aucune modification à votre application. Les requêtes analytiques sont exécutées sur l’index columnstore et les opérations OLTP continuent de s’exécuter sur les index d’arbre B (B-tree) OLTP. Les charges de travail OLTP continuent de fonctionner, mais encourent une surcharge supplémentaire pour gérer l’index columnstore. Consultez les optimisations des performances dans la section suivante.
Remarque
De manière générale, la documentation SQL Server utilise le terme B-tree en référence aux index. Dans les index rowstore, le moteur de base de données implémente une structure B+. Cela ne s’applique pas aux index columnstore ou aux index sur les tables à mémoire optimisée. Pour plus d’informations, consultez le Guide de conception et d’architecture d’index SQL Server et Azure SQL.
Billets de blog :
Lisez les billets de blog suivants pour en savoir plus sur l’analytique opérationnelle en temps réel. Il peut être plus facile de comprendre les sections relatives aux conseils en matière de performances si vous consultez d’abord les billets de blog.
Using a nonclustered columnstore index for real-time operational analytics
How SQL Server maintains a nonclustered columnstore index on a transactional workload
Minimizing the impact of nonclustered columnstore index maintenance by using a filtered index
Minimizing the impact of nonclustered columnstore index maintenance by using compression delay
Analytique opérationnelle en temps réel à l’aide de tables à mémoire optimisée
Vidéos
La série vidéo Data Exposed en détails sur certaines fonctionnalités et considérations.
- Partie 1 : Comment Azure SQL active l’analytique opérationnelle en temps réel (HTAP)
- Partie 2 : Optimiser les bases de données et applications existantes avec l’analytique opérationnelle
- Partie 3 : Comment créer une analytique opérationnelle avec Window Functions.
Conseil en matière de performances 1 : Utiliser des index filtrés pour améliorer les performances des requêtes
L’exécution de l’analytique opérationnelle en temps réel peut avoir un impact sur les performances de la charge de travail OLTP. Cet impact doit être minime. L’exemple A montre comment utiliser des index filtrés pour réduire l’impact de l’index columnstore non cluster sur la charge de travail transactionnelle tout en fournissant des analyses en temps réel.
Pour réduire les frais de gestion d’un index non cluster columnstore sur une charge de travail opérationnelle, vous pouvez utiliser une condition filtrée pour créer un index non cluster columnstore uniquement sur les données tièdes ou à évolution lente. Par exemple, dans une application de gestion de commandes, vous pouvez créer un index non cluster columnstore sur les commandes qui ont déjà été expédiées. Une fois que la commande a été expédiée, elle est rarement modifiée et peut par conséquent être considérée comme des données tièdes. Avec un index filtré, les données dans un index non cluster columnstore nécessitent moins de mises à jour, ce qui réduit l’impact sur la charge de travail transactionnelle.
Les requêtes analytiques accèdent en toute transparence aux données tièdes et chaudes selon les besoins pour fournir l’analytique en temps réel. Si une partie importante de la charge de travail opérationnelle affecte les données « chaudes », ces opérations ne nécessitent pas de maintenance supplémentaire de l’index columnstore. Il est recommandé d’avoir un index cluster rowstore sur les colonnes utilisées dans la définition de l’index filtré. SQL Server utilise l’index cluster pour analyser rapidement les lignes qui n’ont pas respecté la condition filtrée. Sans cet index cluster, une analyse complète de la table du rowstore est nécessaire pour trouver les lignes qui peuvent avoir un impact négatif considérable sur les performances de la requête analytique. En l’absence d’index cluster, vous pouvez créer un index d’arbre B non cluster filtré complémentaire pour identifier ces lignes, mais cela n’est pas recommandé, car l’accès à une grande plage de lignes via les index d’arbre B non cluster est coûteux.
Remarque
Un index non cluster columnstore filtré n’est pris en charge que sur les tables sur disque. Il n’est pas pris en charge sur les tables optimisées en mémoire.
Exemple A : Accès aux données chaudes à partir de l’index d’arbre B, aux données tièdes à partir de l’index columnstore
Cet exemple utilise une condition filtrée (accountkey > 0) pour établir les lignes qui se trouveront dans l’index columnstore. L’objectif est de concevoir la condition filtrée et les requêtes suivantes pour accéder aux données « chaudes » qui changent fréquemment à partir de l’index d’arbre B et pour accéder aux données « tièdes » plus stables à partir de l’index columnstore.

Remarque
L’optimiseur de requête prend en compte, mais ne choisit pas toujours, l’index columnstore pour le plan de requête. Quand l’optimiseur de requête choisit l’index columnstore filtré, il associe en toute transparence à la fois les lignes de l’index columnstore et les lignes qui ne respectent pas la condition filtrée pour permettre l’analytique en temps réel. Cela est différent d’un index non cluster filtré standard qui peut être utilisé uniquement dans les requêtes qui se limitent aux lignes présentes dans l’index.
--Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
Customername nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50));
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fulfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
where orderstatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT top 5 customername, sum (PurchasePrice)
FROM orders
WHERE purchaseprice > 100.0
Group By customername;
La requête analytique est exécutée avec le plan de requête suivant. Vous pouvez voir que les lignes ne respectant pas la condition filtrée sont accessibles via l’index d’arbre B cluster.

Pour plus d’informations, consultez Blog : Index columnstore non cluster filtré.
Conseil en matière de performances 2 : Décharger l’analytique sur une base de données secondaire accessible en lecture Always On
Même si vous pouvez réduire la maintenance des index columnstore en utilisant un index columnstore filtré, les requêtes analytiques peuvent néanmoins nécessiter d’importantes ressources de calcul (processeur, E/S, mémoire) qui ont un impact sur les performances de la charge de travail opérationnelle. Pour les charges de travail les plus critiques, notre recommandation est d’utiliser la configuration Always On. Dans cette configuration, vous pouvez éliminer l’impact de l’exécution de l’analytique en la déchargeant sur une base de données secondaire accessible en lecture.
Conseil en matière de performances 3 : Réduire la fragmentation de l’index en conservant les données chaudes dans les rowgroups delta
Les tables avec l’index columnstore peuvent être considérablement fragmentées (c’est-à-dire des lignes supprimées) si la charge de travail met à jour/supprime des lignes qui ont été compressées. Un index columnstore fragmenté entraîne une utilisation inefficace de la mémoire/du stockage. Outre l’utilisation inefficace des ressources, l’impact est également négatif sur les performances des requêtes analytiques en raison d’E/S supplémentaires et de la nécessité de filtrer les lignes supprimées du jeu de résultats.
Les lignes supprimées ne sont pas physiquement retirées tant que vous n’avez pas exécuté la défragmentation d’index avec la commande REORGANIZE, ou que vous n’avez pas reconstruit l’index columnstore sur la table entière ou les partitions affectées. Les opérations d’index REORGANIZE et REBUILD sont toutes deux des opérations consommant des ressources de façon intensive, qui pourraient sans cela être utilisées pour la charge de travail. En outre, si les lignes compressées trop tôt, il peut être nécessaire de les compresser plusieurs fois en raison de mises à jour entraînant une surcharge de compression perdue.
Vous pouvez réduire la fragmentation des index avec l’option COMPRESSION_DELAY.
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY. The columnstore index will keep the rows in closed delta rowgroup for 100 minutes
-- after it has been marked closed
CREATE NONCLUSTERED COLUMNSTORE index t_colstor_cci on t_colstor (accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION= COLUMNSTORE, COMPRESSION_DELAY = 100);
Pour plus d’informations, consultez Blog : Délai de compression.
Voici les bonnes pratiques recommandées :
Charge de travail d’insertion/d’interrogation : si votre charge de travail insère et interroge principalement des données, l’option COMPRESSION_DELAY avec la valeur par défaut 0 est l’option recommandée. Les lignes nouvellement insérées sont compressées quand 1 million de lignes ont été insérées dans un rowgroup delta unique.
Voici quelques exemples de telles charges de travail : (a) une analyse de flux de travail DW classique (b) lorsque vous devez analyser le modèle de sélection dans une application web.Charge de travail OLTP : si la charge de travail est lourde DML (c’est-à-dire une combinaison intensive de mise à jour, de suppression et d’insertion), vous pouvez voir la fragmentation d’index columnstore en examinant la vue DMV
sys. dm_db_column_store_row_group_physical_stats. Si vous voyez que > de 10 % des lignes sont marquées comme supprimées dans des rowgroups récemment compressés, vous pouvez utiliser l’option COMPRESSION_DELAY pour ajouter un délai quand les lignes sont éligibles pour la compression. Si les données récemment insérées pour votre charge de travail restent « chaudes » (autrement dit, si elles sont mises à jour plusieurs fois) pendant, par exemple, 60 minutes, vous devez choisir la valeur 60 pour COMPRESSION_DELAY.
A priori, la plupart des clients n’auront rien à faire. La valeur par défaut de l’option COMPRESSION_DELAY doit fonctionner pour eux.
Pour les utilisateurs avancés, nous vous recommandons d’exécuter la requête suivante et de collecter % des lignes supprimées au cours des sept derniers jours.
SELECT row_group_id,cast(deleted_rows as float)/cast(total_rows as float)*100 as [% fragmented], created_time
FROM sys. dm_db_column_store_row_group_physical_stats
WHERE object_id = object_id('FactOnlineSales2')
AND state_desc='COMPRESSED'
AND deleted_rows>0
AND created_time > GETDATE() - 7
ORDER BY created_time DESC;
Si le nombre de lignes supprimées dans les rowgroups compressés > 20 %, la mise en plateau dans les rowgroups plus anciens avec < une variation de 5 % (appelée groupes de lignes froids) est définie COMPRESSION_DELAY = (youngest_rowgroup_created_time - current_time). Cette approche fonctionne mieux avec une charge de travail stable et relativement homogène.
Contenu connexe
- Index columnstore : Vue d’ensemble
- Index columnstore - Conseils en matière de chargement de données
- Index columnstore - Performances des requêtes
- Index Columnstore dans l’entreposage de données
- Optimiser la maintenance des index pour améliorer les performances des requêtes et réduire la consommation des ressources