Section 2 : Configurer et inscrire vos données
Si vous n’avez pas de sources de données disponibles pour l’analyse, vous pouvez suivre ces étapes pour déployer entièrement un exemple Azure Data Lake Stroage (ADLS Gen2).
Conseil
Si vous disposez déjà d’une source de données dans le même locataire que votre compte Microsoft Purview, passez à la prochaine partie de cette section pour analyser vos ressources.
Dans un patrimoine de données réel, vous trouverez de nombreux systèmes différents en cours d’utilisation pour différentes applications de données. Il existe des environnements de création de rapports tels que Fabric et Snowflake où les équipes utilisent des copies de données pour créer des solutions analytiques et alimenter leurs rapports et tableaux de bord. Il existe des systèmes de données opérationnels qui alimentent les applications utilisées par les équipes ou les clients pour effectuer des processus métier qui collectent ou ajoutent des données en fonction des décisions prises pendant le processus.
Pour créer un patrimoine de données plus réaliste, il est recommandé d’afficher de nombreuses sources de données dans le catalogue, ce qui peut couvrir l’éventail des différentes utilisations de données que n’importe quelle entreprise peut avoir. Les types de données nécessaires pour alimenter un cas d’usage peuvent être très différents avec les utilisateurs professionnels qui ont besoin de rapports et de tableaux de bord, les analystes ont besoin de dimensions et de faits conformes pour créer des rapports, les scientifiques des données ou les ingénieurs données ont besoin de données sources brutes qui proviennent directement du système qui collecte les données toutes ces et plus permettent à différents utilisateurs de voir l’importance de trouver, compréhension et accès aux données au même endroit.
Pour d’autres didacticiels sur l’ajout de données à votre patrimoine, vous pouvez suivre ces guides :
- Didacticiel Fabric Lakehouse : fournit la base d’un environnement de création de rapports
- base de données Azure SQL (exemple) : fournit un exemple bien structuré d’un magasin de données opérationnel
Configuration requise
- Abonnement dans Azure : Créer votre compte Gratuit Azure aujourd’hui
- Microsoft Entra ID pour votre locataire : Gouvernance Microsoft Entra ID
- Un compte Microsoft Purview
- Administration l’accès au compte Microsoft Purview (il s’agit de la valeur par défaut si vous avez créé le compte Microsoft Purview. Autorisations dans la nouvelle préversion du portail Microsoft Purview | Microsoft Learn)
- Toutes les ressources ; Microsoft Purview, votre source de données et Microsoft Entra ID doivent se trouver dans le même locataire cloud.
Étapes de configuration de votre patrimoine de données
Créer et remplir un compte de stockage
- Suivez ce guide pour créer un compte de stockage : Créer un compte de stockage pour Azure Data Lake Storage Gen2
- Créez des conteneurs pour votre nouveau lac de données :
- Accédez à la page Vue d’ensemble de notre compte de stockage.
- Sélectionnez l’onglet Conteneurs sous la section Stockage de données.
- Sélectionnez le bouton + Conteneur
- Nommez « bronze » et sélectionnez le bouton Créer
- Répétez ces étapes pour créer un conteneur « gold »
- Téléchargez des exemples de données CSV à partir de data.gov : Covid-19 Vaccination and Case Trends by Age Group, États-Unis
- Chargez le fichier CSV dans le conteneur nommé « bronze » dans le compte de stockage que vous avez créé.
- Sélectionnez le conteneur nommé « bronze », puis sélectionnez le bouton Charger .
- Parcourez l’emplacement où vous avez enregistré le fichier CSV et sélectionnez le fichier Covid-19_Vaccination_Case _Trends .
- Sélectionnez Télécharger.
Créer un Azure Data Factory
Cette étape montre comment les données se déplacent entre les couches d’un lac de données medallion et s’assure que les données sont dans un format standardisé que les consommateurs s’attendent à utiliser. Il s’agit d’une étape préalable à l’exécution de la qualité des données.
Suivez ce guide pour créer un Azure Data Factory : Créer un Azure Data Factory
Copiez les données du fichier CSV dans le conteneur « bronze » vers le conteneur « gold » en tant que table au format Delta à l’aide de ce guide Azure Data Factory : Transformer des données à l’aide d’un flux de données de mappage
Ouvrez l’expérience Azure Data Factory (ADF) à partir de la Portail Azure en sélectionnant le bouton Lancer studio sous l’onglet Vue d’ensemble de la ressource ADF créée.

Sélectionnez l’onglet Auteur dans ADF Studio.
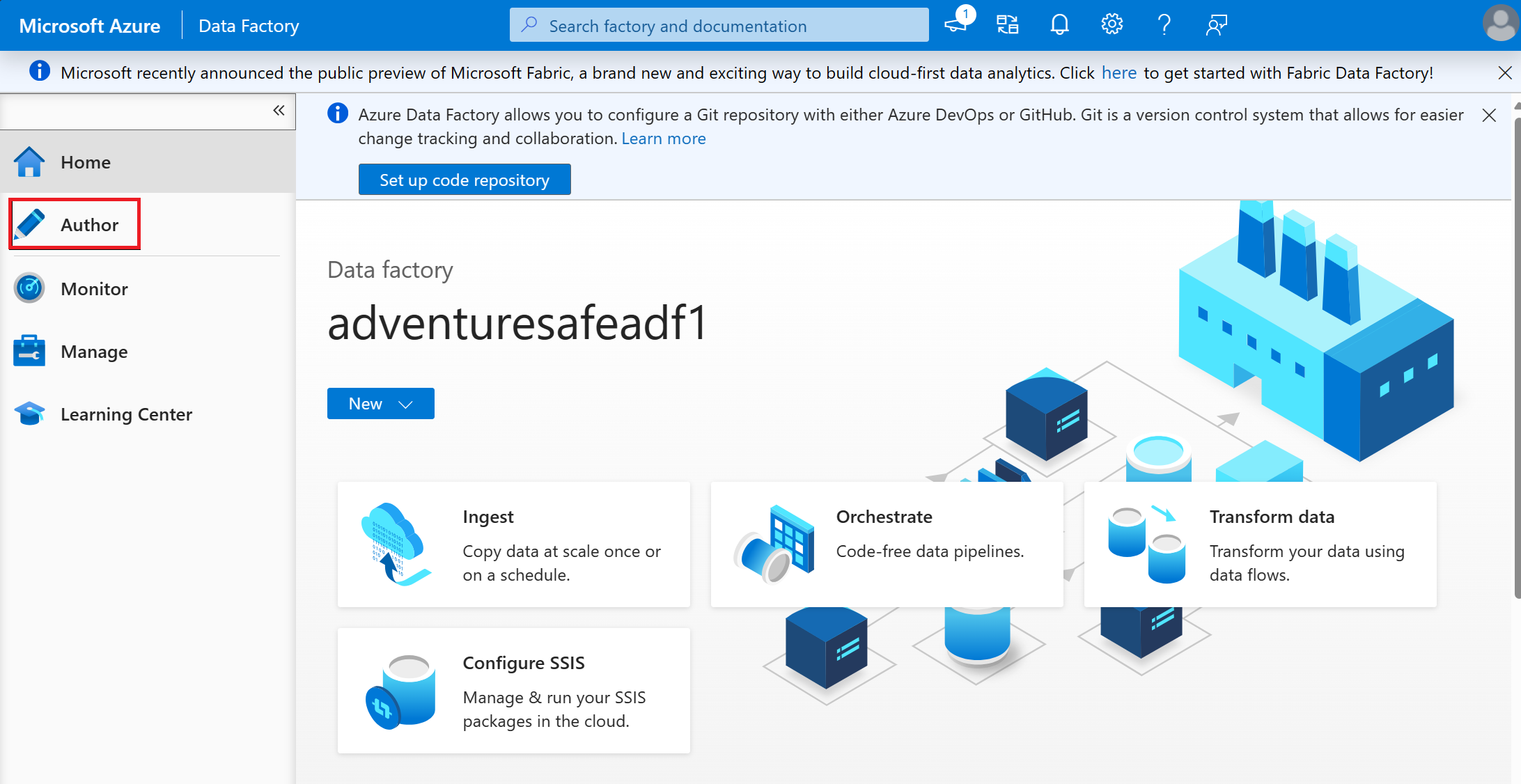
Sélectionnez le + bouton et sélectionnez Flux de données dans le menu déroulant.
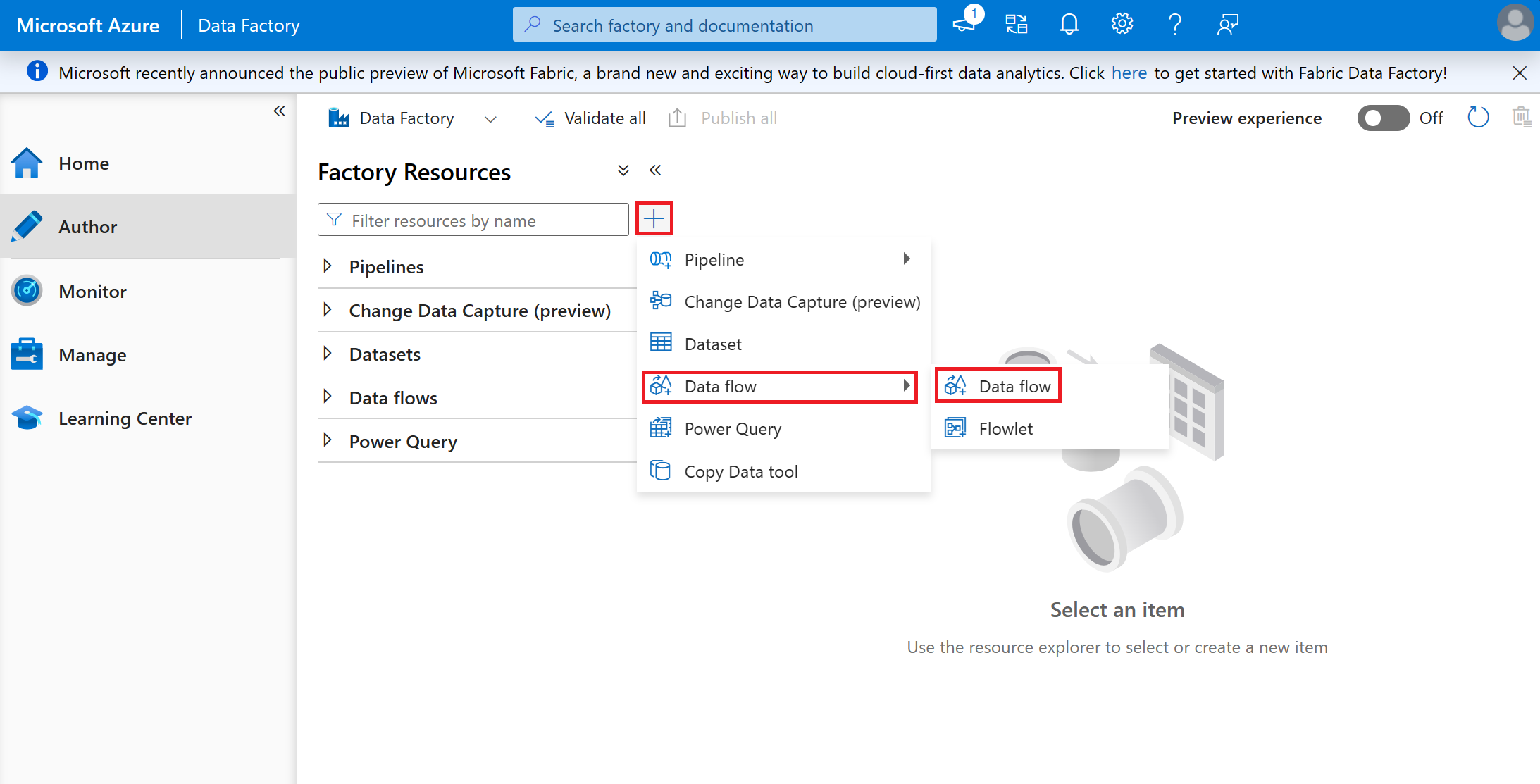
Nommez le flux de données « CSVtoDeltaC19VaxTrends ».
Sélectionnez Ajouter une source dans la zone vide.
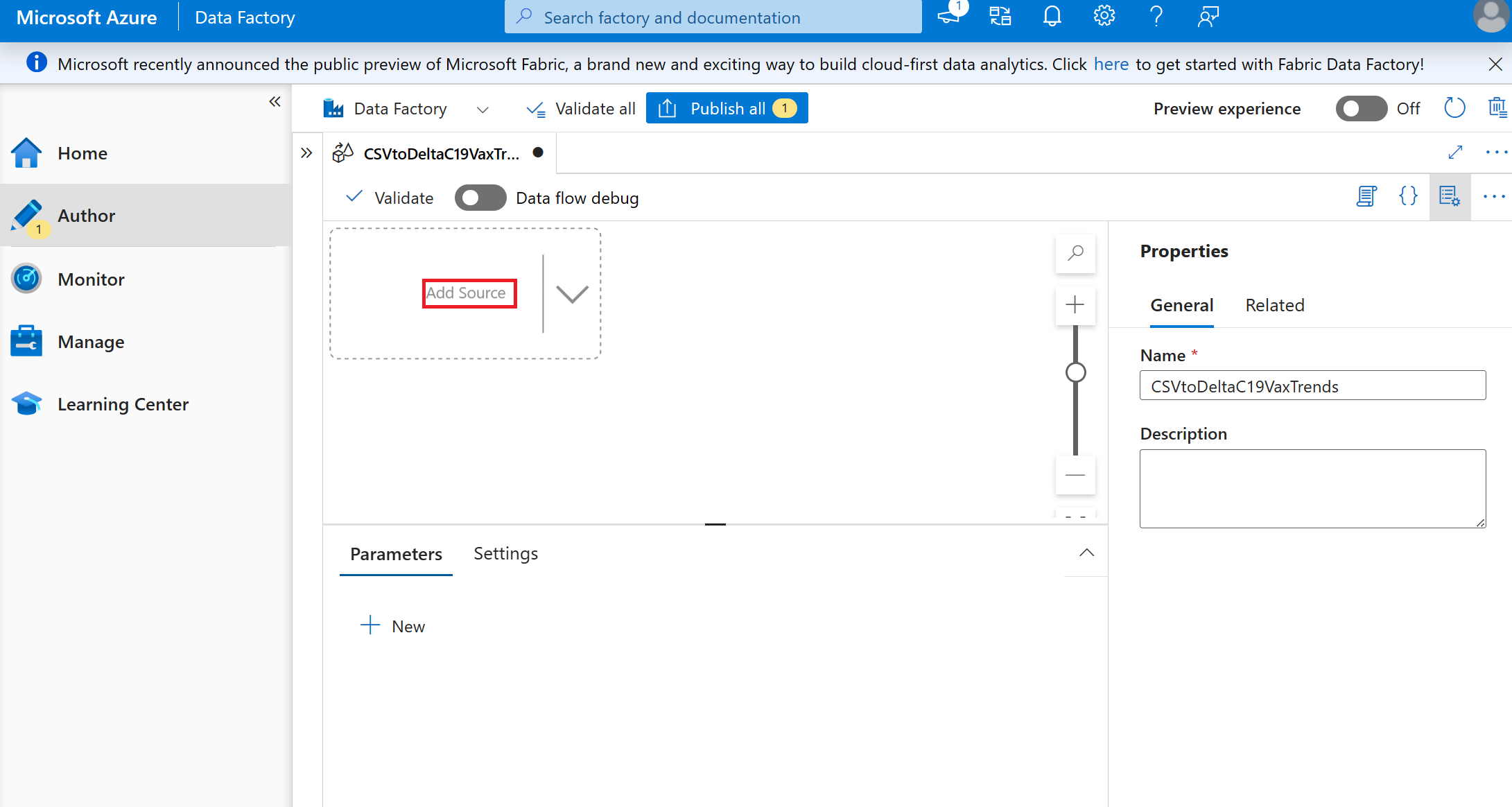
Définissez Paramètres de la source sur :
- Nom du flux de sortie : « C19csv »
- Description : laissez vide
- Type de source : Inline
- Type de jeu de données inline : Texte délimité
- Service lié : sélectionnez le lac de données dans lequel vous avez stocké le fichier csv
Définissez Options de la source sur :
- Mode fichier : Fichier
- Chemin d’accès au fichier : /bronze/ Covid-19_Vaccination_Case _Trends
- Autoriser l’absence de fichiers trouvés : laissez décochée
- Capture des modifications de données : laissez décochée
- Type de compression : Aucun
- Encodage : par défaut (UTF-8)
- Délimiteur de colonne : Virgule (,)
- Délimiteur de ligne : par défaut(\r, \n ou\r\n)
- Caractère de guillemet : Guillemet double (")
- Caractère d’échappement : barre oblique inverse ()
- Première ligne comme en-tête : CHECKED
- Laissez le reste comme valeurs par défaut
Sélectionnez la petite + En regard de la source créée, puis sélectionnez Récepteur
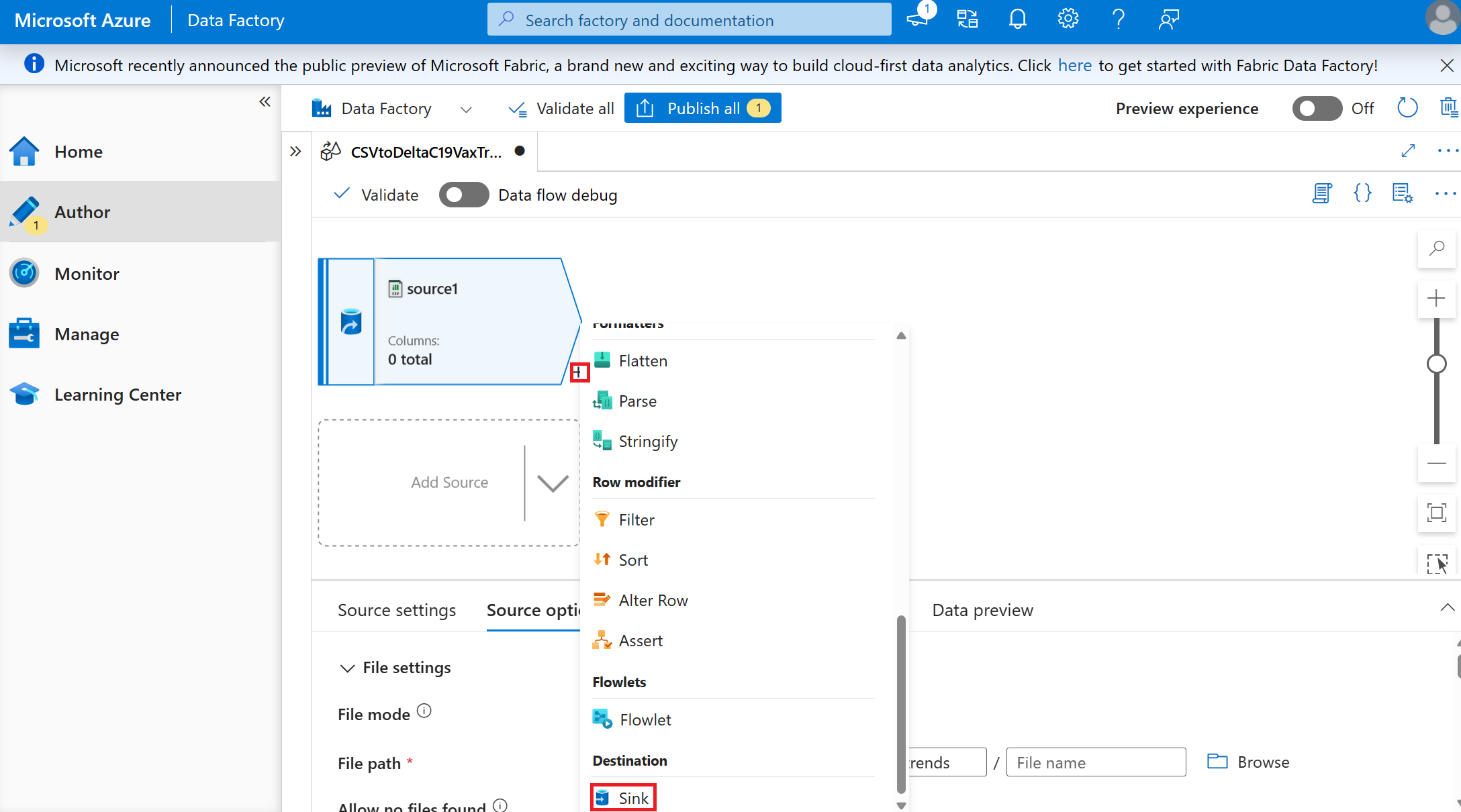
Créez le récepteur dans lequel le format et l’emplacement des données à stocker pour déplacer les données d’un fichier csv en « bronze » vers une table delta en « or ».
- Définissez les valeurs du récepteur (conservez tous les paramètres par défaut, sauf indication contraire)
- Type de récepteur : Inline
- Type de jeu de données inline : Delta
- Service lié : le même lac de données que celui utilisé dans la source, car nous allons stocker dans un autre conteneur.
Définissez les valeurs De paramètre (conservez tous les paramètres par défaut, sauf indication contraire)
- Chemin d’accès au dossier : vaccin or/Covid19 et tendances des cas
Vous devez entrer la valeur, car ce nom correspond à la façon dont nous voulons que les données soient stockées et qu’il n’existe pas de sélection.
Sélectionnez Valider pour vérifier votre flux de données et fournir des instructions pour corriger les erreurs éventuelles.
Sélectionnez Publier tout.
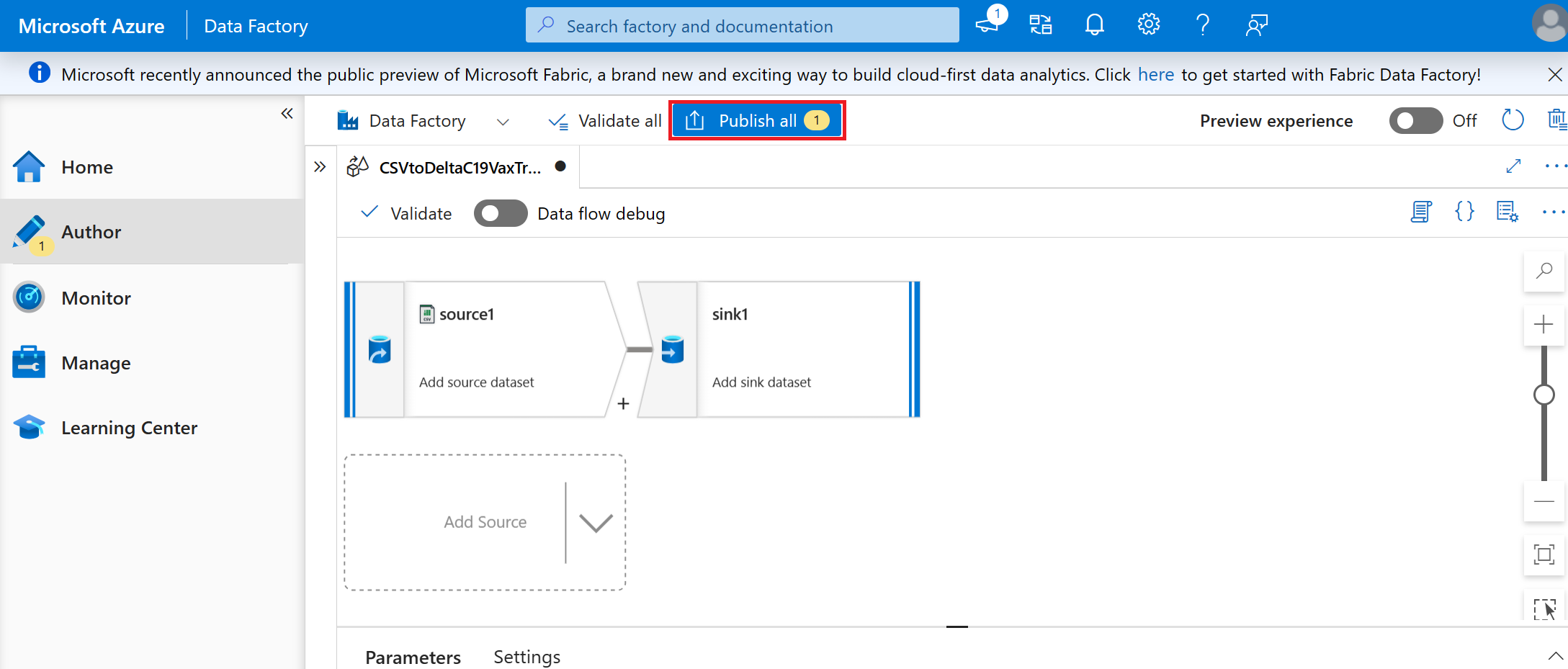
Sélectionnez le + bouton et sélectionnez pipeline dans le menu déroulant
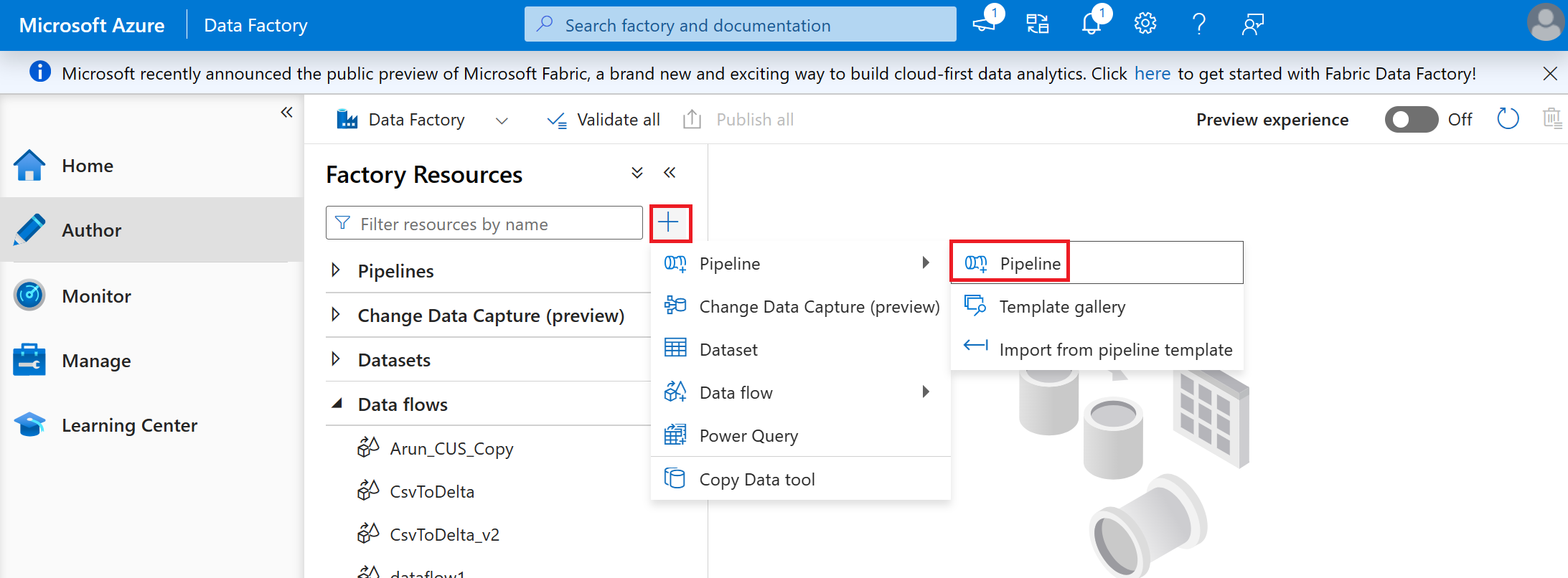
Nommez votre pipeline « CSV to Delta C19 Vax Trends »
Sélectionnez le flux de données créé dans les étapes précédentes CSV vers Delta (C19VaxTrends) et faites-le glisser-déplacer sur l’onglet du pipeline ouvert.
Sélectionnez Valider.
Sélectionnez Publier.
Sélectionnez Déboguer (utiliser le runtime d’activité) pour exécuter le pipeline.
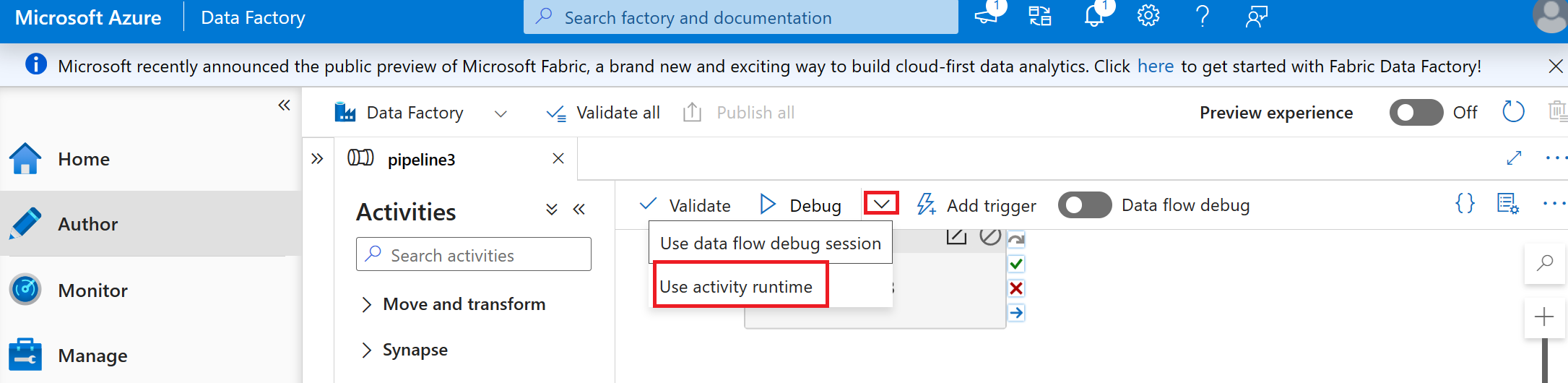
Conseil
Si vous rencontrez des erreurs pour des espaces ou des caractères inappropriés pour le format delta : ouvrez le fichier CSV téléchargé et apportez des corrections. Ensuite, rechargez et remplacez le fichier CSV dans la zone bronze. Réexécutez ensuite votre pipeline.
Accédez à votre conteneur Gold dans le lac de données. Vous devez maintenant voir la nouvelle table Delta créée pendant le pipeline.
Analyser vos ressources
Si vous n’avez pas analysé les ressources de données dans votre Mappage de données Microsoft Purview, vous pouvez suivre ces étapes pour remplir votre mappage de données.
L’analyse des sources dans votre patrimoine de données collecte automatiquement les métadonnées des ressources de données (tables, fichiers, dossiers, rapports, etc.) dans ces sources. En inscrivant une source de données et en créant l’analyse, vous établissez la propriété technique sur les sources et les ressources affichées dans le catalogue et vous assurez que vous contrôlez qui peut accéder aux métadonnées dans Microsoft Purview. En inscrivant et en stockant les sources et les ressources au niveau du domaine, elles seront stockées au niveau le plus élevé de la hiérarchie d’accès. En règle générale, il est préférable de créer des collections dans lesquelles vous allez analyser les métadonnées de la ressource et établir la hiérarchie d’accès correcte pour ces données.
-
Fournir un accès en lecture pour l’identité managée Microsoft Purview (MSI) à votre lac de données ou à un autre magasin de données.
Conseil
Le MSI est le nom de compte du instance Microsoft Purview.
Si vous avez choisi d’utiliser Microsoft Fabric ou SQL, vous pouvez utiliser ces guides pour fournir l’accès :
Inscrire votre lac de données et analyser vos ressources
Dans Mappage de données Microsoft Purview sous l’onglet Domaines, sélectionnez attributions de rôles pour le domaine (il s’agit du nom du compte Microsoft Purview) :
- Ajoutez-vous en tant qu’administrateur de source de données et conservateur de données au domaine.
- Sélectionnez l’icône de personne en regard du rôle Administrateur de source de données.
- Recherchez votre nom tel qu’il est dans Microsoft Entra ID (il peut vous obliger à entrer votre nom complet exactement comme dans Microsoft Entra ID).
- Sélectionnez OK.
- Répétez ces étapes pour le curateur de données.
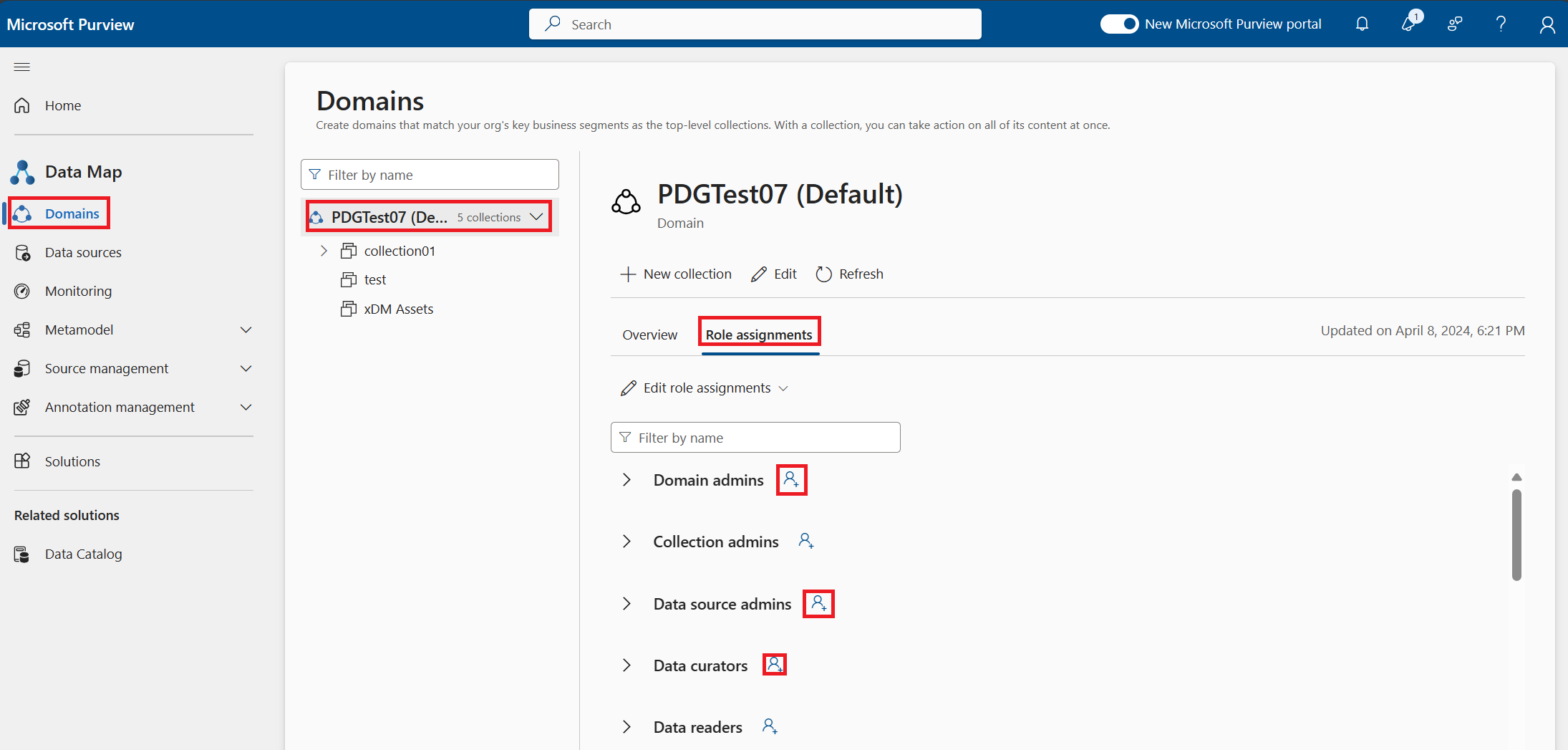
- Ajoutez-vous en tant qu’administrateur de source de données et conservateur de données au domaine.
Inscrivez le lac de données :
- Sélectionnez l’onglet Sources de données .
- Sélectionner Inscription.
- Sélectionnez le type de stockage Azure Data Lake Storage Gen2.
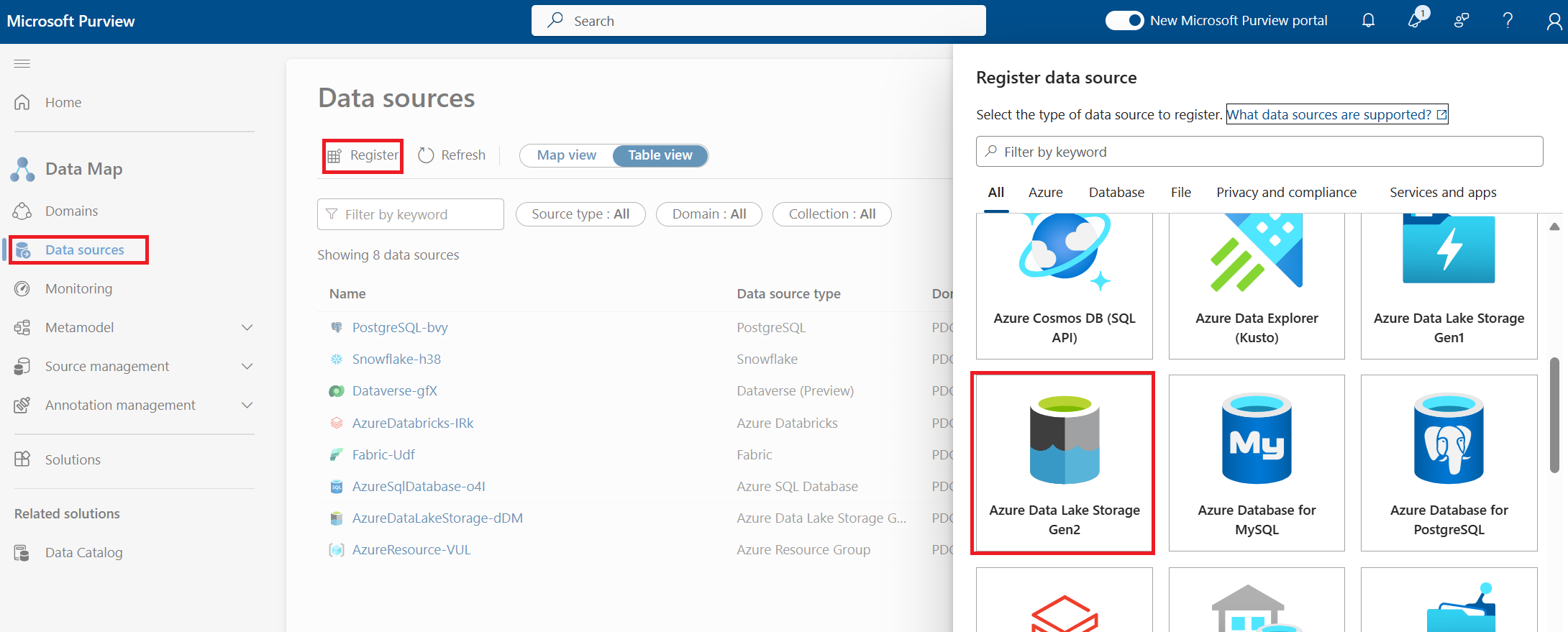
Fournissez les détails pour vous connecter :
- Abonnement (facultatif)
- Nom de la source de données (il s’agit du nom de la source ADLS Gen2)
- Collection dans laquelle les métadonnées des ressources doivent être stockées (facultatif)
- Sélectionnez Inscrire.
Une fois l’inscription de la source de données terminée, vous pouvez configurer l’analyse. L’inscription signifie que Microsoft Purview est connecté à la source de données et l’a placée dans la collection appropriée pour la propriété. L’analyse lit ensuite les métadonnées de la source et remplit les ressources dans le mappage de données.
Sélectionnez la source que vous avez inscrite dans l’onglet Sources de données
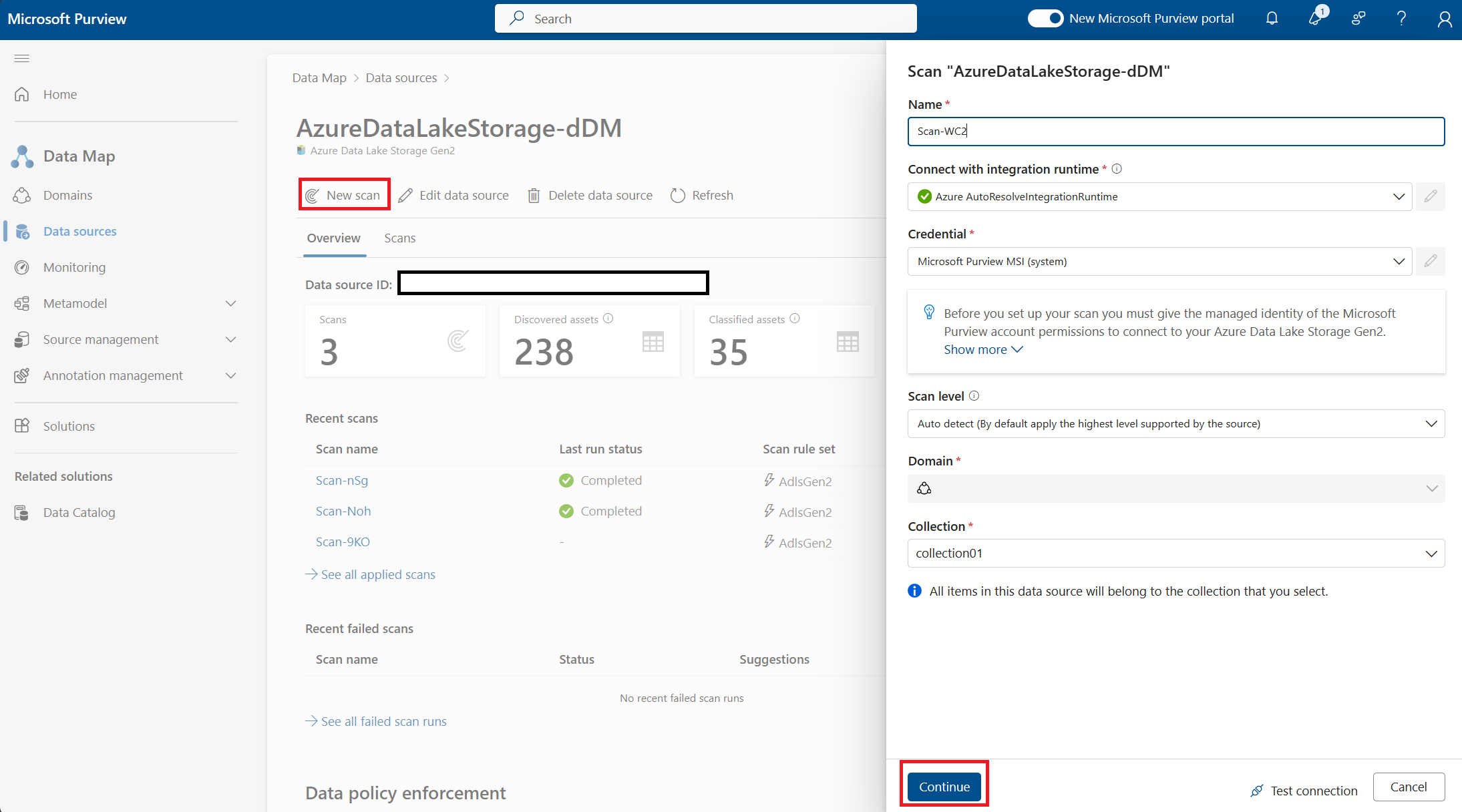
Sélectionnez une nouvelle analyse et fournissez des détails :
- Utiliser le runtime d’intégration par défaut pour cette analyse
- Les informations d’identification doivent être Microsoft Purview MSI (système)
- Le niveau d’analyse est Détection automatique
- Sélectionnez une collection ou utilisez le domaine (la collection doit être la même collection ou collection enfant que celle où la source de données a été inscrite)
- Sélectionnez Continuer
Conseil
À ce stade, Microsoft Purview teste la connexion pour vérifier qu’une analyse peut être effectuée. Si vous n’avez pas accordé l’accès lecteur MSI Microsoft Purview à la source de données, cela échoue. Si vous n’êtes pas le propriétaire de la source de données ou si vous disposez d’un accès utilisateur contributeur l’analyse échoue, car elle s’attend à ce que vous ayez l’autorisation de créer la connexion.
À présent, sélectionnez uniquement le conteneur « gold » dans lequel nous avons placé la table delta dans la section des données de construction du didacticiel. Cela empêchera l’analyse des autres ressources de données qui se trouvent dans votre magasin de données.
- Si vous n’avez qu’un seul case activée bleu en regard de l’or, vous pouvez laisser des vérifications à côté de tout, car il analysera la source complète et créera les ressources que nous utiliserons et bien plus encore.
- Sélectionnez Continuer
Dans l’écran Sélectionner un ensemble de règles d’analyse, vous devez utiliser l’ensemble de règles d’analyse par défaut.
Sélectionnez Continuer
Dans Définir un déclencheur d’analyse, vous définissez la fréquence de l’analyse afin que vous continuez à ajouter des ressources de données au conteneur gold du lac, il continue à remplir la carte de données. Sélectionnez Une fois.
Cliquez sur Continuer.
Sélectionnez Enregistrer et exécuter. Cette opération crée une analyse qui lit uniquement les métadonnées du conteneur Gold de votre lac de données et remplit la table que nous utiliserons dans Catalogue unifié Microsoft Purview dans les sections suivantes. Si vous sélectionnez uniquement Enregistrer, l’analyse n’est pas exécutée et les ressources ne s’affichent pas. Une fois l’analyse en cours d’exécution, vous verrez l’analyse que vous avez créée avec un status de dernière exécutionde En file d’attente. Une fois l’analyse terminée, vos ressources sont prêtes pour la section suivante. Cette opération peut prendre quelques minutes ou quelques heures en fonction du nombre de ressources que vous avez dans votre source.