Analyses et insights en libre-service (préversion)
L’analytique et les insights en libre-service font référence aux données, outils et plateformes qui permettent aux utilisateurs professionnels d’accéder, d’analyser et de générer des insights à partir de données indépendamment. L’application de gouvernance des données Microsoft Purview publie un modèle de domaine de métadonnées dans Fabric OneLake et AdlsG2 (Stockage Azure Data Lake), ce qui permet aux clients d’analyser et de générer des insights en apportant leurs propres outils et calculs. L’analytique en libre-service des métadonnées de gouvernance des données est précieuse pour favoriser l’amélioration continue de la gestion de l’intégrité du patrimoine de données des clients et favoriser une culture pilotée par les données dans l’ensemble du organization en démocratisant l’accès aux insights sur le patrimoine de données et à la gestion de l’intégrité.
Composants clés
- Modèle de données : modèle 3NF avec détails des domaines et des dimensions
-
Métadonnées: Métadonnées de gouvernance des données qui incluent :
- Domaines de gouvernance
- Produits de données
- Ressources de données
- Termes du glossaire
- Demande d’abonnement
- Règles sur la qualité des données
- Dimensions
- Faits sur la qualité des données (nombres de réussites et d’échecs)
- Actions d’intégrité des données (y compris les actions de qualité des données)
- et bien d’autres
Avantages
- Autonomisation: Permet aux praticiens des données, aux propriétaires de produits de données, aux gestionnaires de données et aux analystes d’explorer les métadonnées de gouvernance des données et de lier les métadonnées de différentes sources pour dériver des insights.
- Flexibilité et efficacité : Le client peut créer des rapports personnalisés en plus des rapports prêtes à l’emploi dans la gestion de l’intégrité.
- Agilité: Permet aux organisations des clients de répondre plus rapidement aux problèmes de gestion de l’intégrité et à la correction.
- Rentable: Réduit la nécessité de configurer des plateformes et des outils de génération. Toutes les données sont disponibles dans OneLake et le client peut utiliser les outils disponibles (modèle sémantique Fabric, rapports PBI, flux de données et notebook) dans OneLake.
Rapports actuellement disponibles (prêtes à l’emploi)
Voici les rapports prêtes à l’emploi disponibles. Ces rapports ne sont pas personnalisables.
- Ressources classiques : vue d’ensemble des ressources par type et collection, ainsi que de leurs status de curation.
- Adoption du catalogue classique : pour comprendre en un coup d’œil comment Catalogue unifié est utilisé. votre glossaire, en fournissant une instantané de termes et leur status.
- Classifications classiques : vue d’ensemble des ressources classifiées et des types de classifications.
- Gestion des données classique : vue d’ensemble des ressources classifiées et des types de classifications.
- Glossaire classique : intégrité et utilisation des termes du glossaire.
- Étiquettes de confidentialité classiques : vue d’ensemble des ressources auxquelles des étiquettes de confidentialité sont appliquées et des types d’étiquettes appliquées.
- Gouvernance des données : le rapport d’intégrité de la gouvernance des données permet à votre équipe de suivre la progression de votre intégrité en un coup d’œil et d’identifier les domaines qui nécessitent plus de travail.
- Intégrité de la qualité des données : rapports sur les performances des dimensions de la qualité des données et des règles de qualité des données.
Modèle de données pour les métadonnées d’analyse en libre-service
Le modèle de domaine 3NF fait partie du processus de normalisation dans la conception de base de données relationnelle, ce qui garantit que la base de données est exempte d’anomalies de redondance et de mise à jour. Un schéma de base de données se trouve dans la troisième forme normale s’il répond aux exigences des première et deuxième Forms normales et que tous ses attributs dépendent uniquement de la clé primaire. L’objectif du modèle de domaine 3NF est utilisé pour structurer les données de manière à réduire la duplication et à garantir l’intégrité des données. Il se concentre sur la décomposition des données en tables connexes plus petites où chaque élément d’information n’est stocké qu’une seule fois.
Caractéristiques:
- Élimination des dépendances transitives : les attributs non clés ne doivent pas dépendre d’autres attributs non clés.
- Regroupement logique : les données sont regroupées logiquement en domaines en fonction de leur fonction ou de leur signification.
- Diagrammes Entity-Relationship (ERD) : couramment utilisés pour représenter des modèles de domaine 3NF, montrant comment les entités sont liées les unes aux autres.
| Nom du tableau | Description | Clés de relation |
|---|---|---|
| État d’approvisionnement de la stratégie d’accès | Les informations sur l’état d’approvisionnement sont stockées dans cette table. | ProvisioningStateId |
| Type de ressource de stratégie d’accès | Les informations sur les ressources Porlich Access sont stockées dans cette table. | ResourceTypeId |
| Ensemble de stratégies d’accès | Les informations générales sur la stratégie d’accès, les détails du cas d’utilisation de la stratégie et l’emplacement où la stratégie a été appliquée, etc. sont stockées dans cette table. | AccessPolicySetId (UniqueId), ResourceTypeId (FK), ProvisioningStateId (FK) |
| Domaine d’entreprise | Le nom de domaine métier, la description, les status et les détails de propriété sont publiés dans la table Domaine d’entreprise | PARENT Business Domain ID (FK), Created by User ID (FK), Last Modified by User ID (FK) |
| Classification | Les informations de classification des ressources de données sont stockées dans cette table. | ClassificationId |
| Cas d’usage de l’accès personnalisé | Les informations de cas d’usage Access sont stockées dans cette table. | AccessPolicySetId |
| Ressource de données | Le nom, la description et les informations de source de la ressource de données sont stockés dans cette table. | DataAssetId (UniqueId), DataAssetTypeId (FK), CreatedByUserId (FK), LastModifiedByUserId (FK) |
| Colonne de ressource de données | Le nom de la colonne de ressource de données, la description de la colonne et les références sont stockés dans cette table. | DataAssetId (FK), ColumnId (Unique), DataAssetTypeId (FK), DataTypeId (FK), Created By User ID (FK), Last Modified By User ID (FK) |
| Affectation de classification de colonne de ressource de données | Les clés de référence liées à l’affectation de classification des données sont stockées dans cette table. | DataAssetId (FK), ColumnId (FK), ClassificationId (FK) |
| Attribution de domaine de ressource de données | Les informations relatives à l’attribution de domaine de gouvernance des ressources de données sont disponibles dans ce tableau. | DataAssetId (FK), BusinessDomainId (FK), AssignedByUserId (FK) |
| Propriétaire de ressource de données | Informations sur le propriétaire de la ressource de données stockées dans cette table. | DataAssetOwnerId |
| Affectation du propriétaire de ressource de données | Les informations d’affectation du propriétaire de la ressource de données sont stockées dans cette table. | DataAssetId, DataAssetOwnerId |
| Type de données de type de ressource | Les informations de type de ressource de données sont stockées dans cette table. | DataTypeId (UniqueId), DataAssetTypeId (FK) |
| Produit de données | Nom du produit de données, description, cas d’usage, status et autres informations pertinentes stockées dans cette table. | DataProductId (UniqueId), DataProductTypeId (FK), DataProductStatusId (FK), UpdateFrequencyId (FK), CreatedByUserId (FK), LastUpdatedByUserId (FK) |
| Affectation d’une ressource de produit de données | Les informations d’affectation des ressources de données et des produits de données sont stockées dans cette table. | DataProductId, DataAssetId |
| Attribution de domaine métier de produit de données | Les informations d’attribution de domaine de gouvernance et de produit de données sont stockées dans cette table. | DataProductId (FK), BusinessDomainId (FK), AssignedByUserId (FK) |
| Documentation du produit de données | Les informations de référence de la documentation des produits de données sont stockées dans cette table. | DataProductId, DocumentationId |
| Propriétaire du produit de données | Les informations du propriétaire du produit de données sont stockées dans cette table. | DataProductId, DataProductOwnerId |
| État du produit de données | Le produit de données status (comme les informations publiées ou brouillons) stockées dans cette table. | DataProductStatusId |
| Conditions d’utilisation du produit de données | Les informations relatives aux conditions d’utilisation des produits de données sont stockées dans cette table. | DataProductId, TermOfUsedId, DataAssetId |
| Type de produit de données | Les informations sur les types de produits de données (Master, Reference, Operational, etc.) sont stockées dans cette table. | DataProductTypeId |
| Fréquence de mise à jour des produits de données | Les informations sur la fréquence à laquelle les données de ce produit de données sont mises à jour sont stockées dans cette table. | UpdateFrequencyId |
| Exécution des règles de ressource de qualité des données | Résultats de l’analyse de la qualité des données stockés dans cette table | RuleId (FK), DataAssetId (FK), JobExecutionId (FK) |
| Exécution d’un travail de qualité des données | Le status d’exécution des travaux de qualité des données est stocké dans cette table. | JobExecutionId (UniqueId) |
| Règle de qualité des données | Des informations sur les règles de qualité des données sont stockées dans cette table. | RuleId (UniqueId), RuleTypeId (FK), BusinessDomainId (FK), DataProductId (FK), DataAssetId (FK), JobTypeDisplayName (FK), RuleOriginDisplayName (FK), RuleTargetObjectType (FK), CreatedByUserId (FK), LastUpdatedByUserId (FK) |
| Exécution de la colonne de règle de qualité des données | Les informations sur le nombre de réussites et d’échecs des règles de qualité des données, le score de qualité des données au niveau des colonnes et les détails d’exécution des travaux de qualité des données sont stockées dans cette table. | RuleId (FK), DataAssetId (FK), ColumnId (FK), JobExecutionId (FK) |
| Type de règle de qualité des données | Le type de règle de qualité des données et les dimensions associées sont stockés dans cette table. | RuleTypeId (UniqueId), DimensionDisplayName (FK) |
| Demande d’abonnement aux données | Informations sur les abonnés aux données, les stratégies appliquées, les status de demande d’abonnement et d’autres informations pertinentes stockées dans cette table. | SubscriberRequestId (UniqueId), SubscriberIdentityTypeDisplayName (FK), RequestorIdentityTypeDisplayName (FK), RequestorStatusDisplayName (FK) |
| Terme du glossaire | Des informations sur le terme du glossaire, la description et la status globale du terme de glossaire sont stockées dans cette table. | GlossaireTermId (UniqueId), ParentGlossaryTermId (FK), CreatedByUserId (FK), LastModifiedByUserId (FK) |
| Glossaire Terme Attribution de domaine métier | Des informations sur l’attribution et les états de domaine de gouvernance des termes de glossaire sont stockées dans cette table. | GlossaryTermId (FK), BusinessDomainId (FK), AssignedByUserId (FK), GlossaryTermStatusId (FK), CreatedByUserId (FK), LastUpdatedByUserId (FK) |
| Affectation de produit de données de terme de glossaire | Des informations sur l’attribution de produit de données de terme de glossaire sont stockées dans cette table. | GlossaryTermId (FK), DataProductId (FK), AssignedByUserId (FK), GlossaryTermStatusId (FK), CreatedByUserId (FK), LastUpdatedByUserId (FK) |
| Approbateur d’ensemble de stratégies | L’ensemble de stratégies et les informations de l’approbateur sont stockés dans cette table. | SubscriberRequestId (FK), AccessPolicySetId (FK), ApproverUserId (FK) |
| Relation | Les informations relatives au type source et à la cible sont stockées dans cette table. | AccountId, SourceId, TargetId |
| Action d’intégrité | Des informations sur la gouvernance des données et les actions de qualité des données sont stockées dans cette table. | ActionId, TargetEntityId, CreatedByUserId |
| Type de recherche d’action d’intégrité | Les actions d’intégrité des données Les types de recherche sont stockées dans cette table. | FindingTypeId |
| Action d’intégrité - Recherche d’un sous-type | Les actions d’intégrité des données Recherche de sous-types sont stockées dans cette table. | FindingSubTypeId, FindingTypeId |
| Affectation de l’utilisateur de l’action d’intégrité | Les informations d’affectation de l’utilisateur des actions d’intégrité des données sont stockées dans cette table. | ActionId, AssignedToUserId |
Ce diagramme illustre la relation d’entité pour le modèle de domaine expliquée dans le tableau ci-dessus : 
S’abonner Catalogue unifié métadonnées à Fabric OneLake
Vous pouvez vous abonner aux métadonnées de gouvernance des données de Microsoft Purview pour l’analytique et dériver des insights en procédant comme suit :
- Dans le portail Microsoft Purview, sélectionnez Paramètres, puis Catalogue unifié, puis Intégrations de solutions (préversion) .
- Sélectionnez Modifier.
- Ajoutez le type de stockage et Activé l’installation.
- Ajouter une URL d’emplacement (exemple :
https://onelake.dfs.fabric.microsoft.com/workspace name/lakehouse name/Files/purviewmetadata)- Sélectionnez Propriétés pour copier l’URL.

- Copiez l’URL à partir de la page Propriétés .

Ajouter le nom du dossier à la fin de l’URL - exemple : /DEH (voir la capture d’écran)
Accordez contributeur accès à Microsoft Purview Manage Service Identity (MSI) à votre espace de travail Fabric.
Tester la connexion.

Sélectionnez Enregistrer pour enregistrer la configuration afin de publier des métadonnées Purview dans votre espace de travail OneLake.

Créer un modèle sémantique dans OneLake
Un modèle sémantique dans le contexte des données et de l’analytique fait référence à une représentation structurée des données qui définit la signification, les relations et les règles au sein d’un domaine spécifique. Il fournit une couche d’abstraction qui permet aux utilisateurs de comprendre et d’interagir avec des données complexes en les rendant plus intuitives et plus accessibles, en particulier dans le contexte de l’aide à la décision (BI) et des plateformes d’analyse. Un modèle sémantique est toujours nécessaire avant de pouvoir générer des rapports. Dans l’entrepôt, un utilisateur peut ajouter des objets d’entrepôt ( tables ou vues) à son modèle sémantique Power BI par défaut. Ils peuvent également ajouter d’autres propriétés de modélisation sémantique, telles que des hiérarchies et des descriptions. Ces propriétés sont ensuite utilisées pour créer les tables du modèle sémantique Power BI. Les utilisateurs peuvent également supprimer des objets du modèle sémantique Power BI par défaut.
Pour créer un modèle sémantique à partir du modèle de domaine de métadonnées De gouvernance des données Microsoft Purview :
Ouvrez Lakehouse dans votre espace de travail Fabric.
Utiliser le raccourci pour créer un raccourci du modèle de domaine à partir de OneLake et dans OneLake
- Sélectionnez le bouton de sélection (...) de Tables
- Sélectionnez Nouveau raccourci , puis Microsoft OneLake à partir de la page Nouvelles sources de raccourci.
- Sélectionner la table de modèle de domaines pour le raccourci
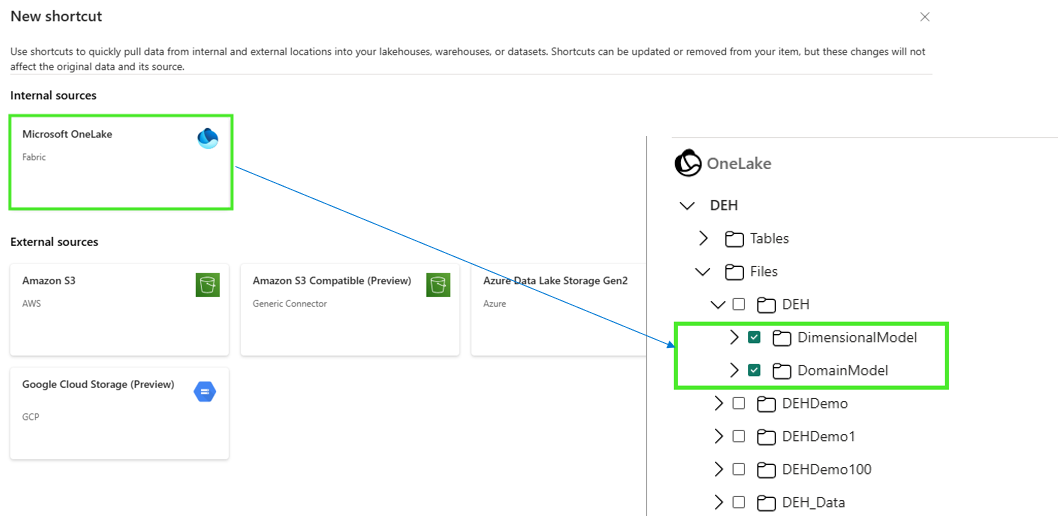
Créez un raccourci directement au niveau de la table pour tous les fichiers, ce qui élimine les enregistrements en double.



Après avoir publié tous les fichiers dans des tables delta via un raccourci, vous pouvez ajouter les tables delta au modèle sémantique.
- Basculez vers la page du point de terminaison d’analytique SQL à partir de la page Lakehouse.
- Sélectionnez Rapports dans le coin supérieur gauche de la page du point de terminaison SQL Analytics .
- Sélectionnez Gérer le modèle sémantique par défaut.
- Sélectionnez les tables dbo > Tables que vous souhaitez ajouter au modèle sémantique pour la création de rapports.

Pour ajouter des objets tels que des tables ou des vues au modèle sémantique Power BI par défaut, sélectionnez Mettre à jour automatiquement le modèle sémantique.

Remarque
Vous pouvez cliquer avec le bouton droit pour ajouter des tables associées afin de créer une relation.
Si vous préférez ne pas vous abonner aux métadonnées purvew pour l’analytique en libre-service, vous pouvez désactiver manuellement l’analytique en libre-service (abonnement aux métadonnées) : accédez à Paramètres > de solution Catalogue unifié > Analytique en libre-service Intégrations > de solutions, puis cliquez sur le bouton bascule pour la désactiver. Vous avez besoin du rôle d’administrateur de gouvernance des données pour activer et désactiver cette fonctionnalité.
S’abonner aux métadonnées du catalogue Microsoft Purview au stockage AdlsG2
Vous pouvez vous abonner aux métadonnées de gouvernance des données de Microsoft Purview pour publier et stocker dans votre stockage AdlsG2 à des fins d’analytique et dériver des insights en procédant comme suit :
Sélectionnez Paramètres dans le volet gauche, sélectionnez Catalogue unifié, puis intégrations de solutions.
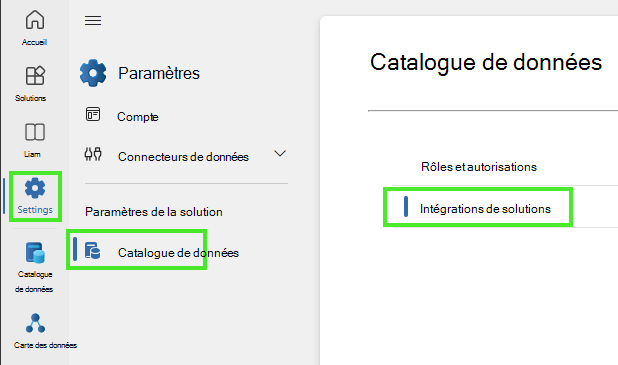
Sélectionnez Modifier.
Sélectionnez Type de stockage. et Activé l’installation.
Ajoutez l’URL d’emplacement, il doit s’agir du chemin d’accès AdlsG2 + « /(nom du conteneur) »
- Accéder à portal.azure.com
- Sélectionner le stockage adlsg2 (Accueil > adlsg2)
- Accédez à Paramètres>Points de terminaison et sélectionnez Point de terminaison principal de votre data lake storage.
Accorder à contributeur de données Blob du stockage l’accès à Microsoft Purview Manage Service Identity (MSI) à votre conteneur AdlsG2
Tester la connexion.
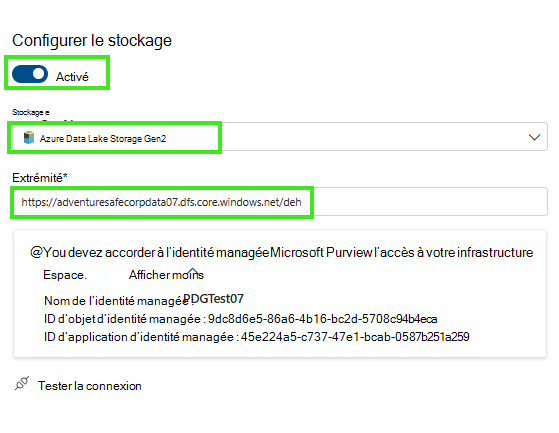
Sélectionnez l’onglet Enregistrer pour enregistrer la configuration et publier le modèle de domaine dans votre stockage adlsg2.

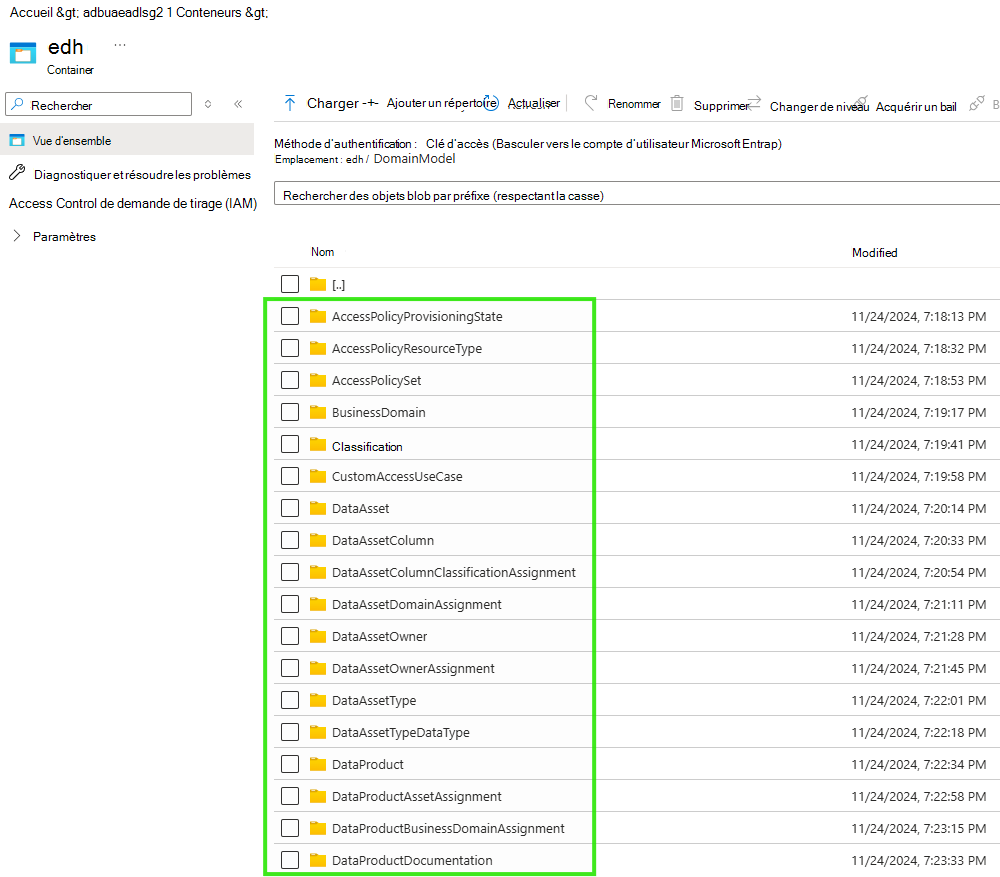
Passer en revue le modèle et les données publiées
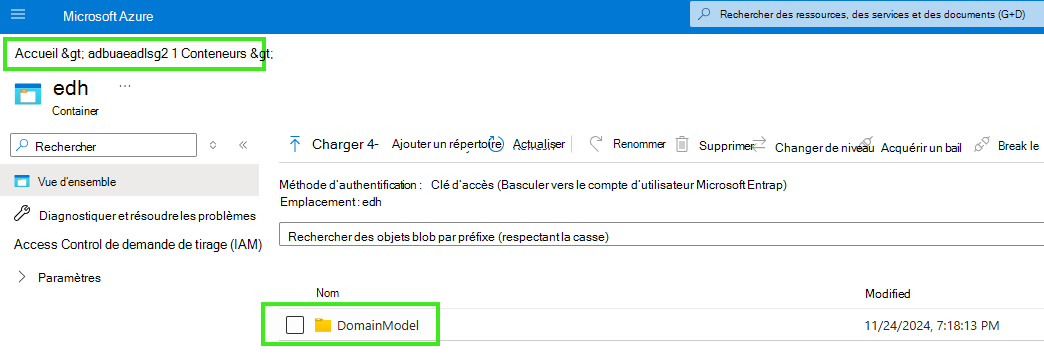
Ouvrir portal.azure.com
Sélectionner votre stockage adlsg2
sélectionnez le conteneur que vous avez ajouté avec le point de terminaison adlsg2 dans purview
Parcourez la liste des fichiers parquet delta publiés dans le conteneur.
Parcourez le modèle et les métadonnées publiés (voir les images ci-dessous).


Créer un rapport Power BI
Power BI est intégré en mode natif à l’ensemble de l’expérience Fabric. Cette intégration native inclut un mode unique, appelé DirectLake, pour accéder aux données à partir de lakehouse afin de fournir l’expérience de requête et de création de rapports la plus performante. DirectLake est une nouvelle fonctionnalité révolutionnaire qui vous permet d’analyser des modèles sémantiques volumineux dans Power BI. Avec DirectLake, vous chargez des fichiers au format Parquet directement à partir d’un lac de données sans avoir à interroger un entrepôt de données ou un point de terminaison lakehouse, et sans avoir à importer ou dupliquer des données dans un modèle sémantique Power BI. DirectLake est un chemin d’accès rapide pour charger les données du lac de données directement dans le moteur Power BI, prêt à être analysé.
En mode DirectQuery traditionnel, le moteur Power BI interroge directement les données de la source pour chaque exécution de requête, et les performances des requêtes dépendent de la vitesse de récupération des données. DirectQuery élimine la nécessité de copier des données, ce qui garantit que toutes les modifications apportées à la source sont immédiatement reflétées dans les résultats de la requête.
Pour plus d’informations , suivez les instructions : Comment créer un rapport Power BI dans Microsoft Fabric.
Importante
- Le cycle d’actualisation par défaut est toutes les 24 heures.
- Purview MSI a besoin contributeur accès à votre espace de travail Fabric si vous vous abonnez aux métadonnées Microsoft Purview pour les publier dans votre espace de travail Fabric.
- Purview MSI a besoin d’un accès Contributeur aux données Blob du stockage à votre Azure Data Lake Storage Gen2 si vous vous abonnez aux métadonnées purview pour les publier dans votre conteneur adlsg2.
- La planification du travail d’actualisation des données n’est pas encore prise en charge.
- Le réseau virtuel n’est pas encore pris en charge.
- Nous publions uniquement des données de ressources régies. Les ressources de données associées à un produit de données sont classées comme des ressources régies. Les ressources Data Map qui ne sont pas régies n’apparaissent pas dans la table des ressources de données d’analyse en libre-service.
- Nous avons implémenté le contrôle d’accès en fonction du rôle dans le catalogue, ce qui garantit que tous les utilisateurs ne peuvent pas afficher tous les domaines ou tous les produits de données. Toutefois, pour l’analytique en libre-service, nous publions toutes les données, ce qui permet à toute personne ayant accès à ces données d’afficher l’intégralité du catalogue. Le contrôle d’accès pour les métadonnées en libre-service dépend de l’emplacement où les données sont stockées : le propriétaire de l’espace de travail Fabric ou le propriétaire du stockage ADLS Gen2 peut gérer l’accès.
- Si vous préférez ne pas vous abonner aux métadonnées purvew pour l’analytique en libre-service, vous pouvez désactiver manuellement l’analytique en libre-service (abonnement aux métadonnées) : accédez à Paramètres > de solution Catalogue unifié > Analytique en libre-service Intégrations > de solutions, puis cliquez sur le bouton bascule pour la désactiver. Vous avez besoin du rôle d’administrateur de gouvernance des données pour activer et désactiver cette fonctionnalité.
{kind=link}