Interpréter les résultats de modèle dans Machine Learning Studio (classique)
S’APPLIQUE À :  Machine Learning Studio (classique)
Machine Learning Studio (classique)  Azure Machine Learning
Azure Machine Learning
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Cette rubrique vous explique comment visualiser et interpréter les résultats de prédiction dans Machine Learning Studio (classique). Après avoir formé un modèle et effectué des prédictions sur celui-ci (c’est-à-dire « noté le modèle »), vous avez besoin de comprendre et d’interpréter les résultats de prédiction.
Il existe quatre principaux types de modèles Machine Learning dans Machine Learning Studio (classique) :
- classification ;
- Clustering
- régression ;
- systèmes de recommandation.
Les modules utilisés pour la prédiction en plus de ces modèles sont :
- Noter le modèle pour la classification et la régression
- Attribuer aux clusters pour le clustering
- Noter la recommandation Matchbox pour les systèmes de recommandation
Découvrez comment choisir des paramètres pour optimiser vos algorithmes dans ML Studio (classique).
Pour savoir comment évaluer vos modèles, consultez Comment évaluer les performances d’un modèle.
Si vous débutez avec ML Studio (classique), découvrez comment créer une expérience simple.
classification ;
Il existe deux sous-catégories de problèmes de classification :
- Problèmes avec uniquement deux classes (classification double classe ou binaire)
- Problèmes avec plus de deux classes (classification multiclasse)
Machine Learning Studio (classique) propose différents modules pour traiter chacun de ces types de classification, mais les méthodes permettant d’interpréter les résultats des prédictions sont similaires.
Classification double classe.
Exemple d'expérience
Un exemple de problème de classification double classe est la classification de fleurs d’iris. La tâche consiste à classer les fleurs d’iris en fonction de leurs caractéristiques. Le jeu de données Iris fourni dans Machine Learning Studio (classique) constitue un sous-ensemble de ce fameux Jeu de données Iris contenant des instances d’uniquement deux espèces de fleur (classes 0 et 1). Chaque fleur comporte quatre caractéristiques (la longueur des sépales, la largeur des sépales, la longueur des pétales et la largeur des pétales).
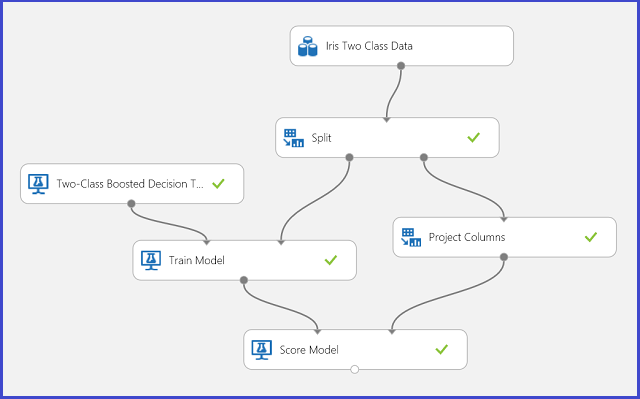
Figure 1. Expérience d’un problème de classification double classe iris
Une expérience a été réalisée pour résoudre ce problème, comme mentionnée dans la Figure 1. Un modèle d'arbre de décision augmentée, double classe a été formé et noté. Vous pouvez dès à présent visualiser les résultats de prédiction du module Noter le modèle en cliquant sur le port de sortie du module Noter le modèle, puis sur Visualiser dans le menu qui s’affiche.
Ceci affiche les résultats de notation, comme mentionné dans la Figure 2.
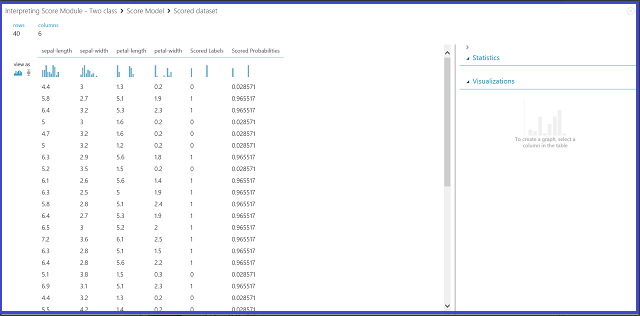
Figure 2 : Visualisation du résultat du modèle de notation dans la classification double classe
Interprétation du résultat
La table des résultats est constituée de six colonnes. Les quatre colonnes de gauche représentent les quatre fonctionnalités. Les deux colonnes de droite, Étiquettes notées et Probabilités notées, représentent les résultats de prédiction. La colonne Probabilités notées indique la probabilité qu’une fleur appartienne à la classe positive (Classe 1). Par exemple, le premier numéro indiqué dans la colonne (0,028571) signifie qu’il y a une probabilité de 0,028571 que la première fleur appartienne à la Classe 1. La colonne Étiquettes notées indique la classe prédite pour chaque fleur. Elle est déterminée en fonction de la colonne Probabilités notées. Si la probabilité notée d’une fleur est supérieure à 0,5, elle est prédite en tant que Classe 1. Sinon, elle est prédite en tant que classe 0.
Publication du service web
Une fois que les résultats de prédiction ont été compris et considérés comme pertinents, l’expérience peut être publiée en tant que service web pour vous permettre de la déployer sur différentes applications et être sollicitée pour obtenir des prédictions de classe sur n’importe quelle nouvelle fleur d’iris. Pour savoir comment modifier une expérience de formation en une expérience de scoring et la publier en tant que service web, consultez le tutoriel 3 : Déployer un modèle de risque de crédit. Cette procédure vous permet de bénéficier d’une expérience de notation, comme indiqué dans la Figure 3.
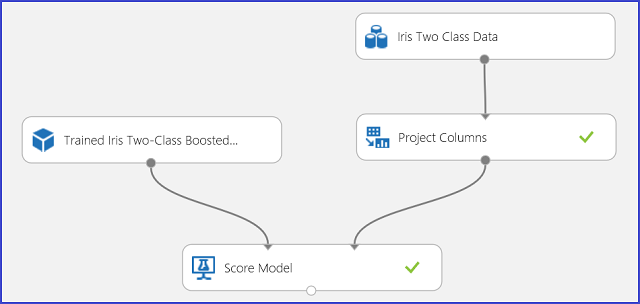
Figure 3. Notation de l’expérience d’un problème de classification double classe Iris
Vous devez à présent définir l’entrée et la sortie du service web. L’entrée est caractérisée par le port d’entrée droit de Noter le modèle, qui représente l’entrée des fonctionnalités de la fleur d’iris. La sortie est, quant à elle, définie en fonction de l’intérêt que vous portez à la classe prédite (étiquette notée), à la probabilité notée ou bien aux deux. Dans cet exemple, on considère ici que vous êtes intéressé par les deux. Pour sélectionner les colonnes de sortie souhaitées, nous devons utiliser un module Sélectionner des colonnes dans le jeu de données. Cliquez sur le module Sélectionner des colonnes dans le jeu de données, sur Lancer le sélecteur de colonne situé dans le volet droit, puis sélectionnez Étiquettes notées et Probabilités notées. Une fois le port de sortie du module Sélectionner des colonnes dans le jeu de données configuré et exécuté à nouveau, nous devons être en mesure de publier l’expérience de notation en tant que service web en cliquant sur le bouton du bas, intitulé PUBLIER LE SERVICE WEB. L'expérience finale est semblable à celle mentionnée dans la Figure 4.
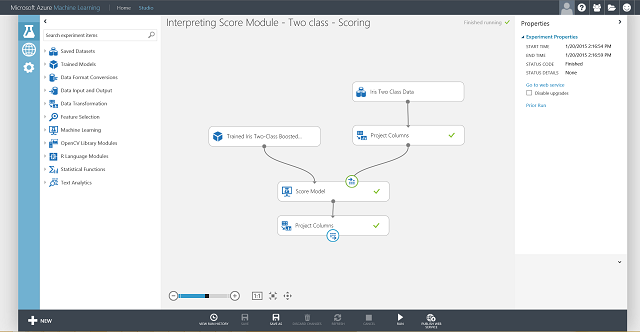
Figure 4. Expérience de notation finale d’un problème de classification double classe Iris
Une fois le service web exécuté et certaines valeurs caractéristiques d’une instance de test saisies, le résultat fournit deux nombres. Le premier nombre représente l’étiquette notée, le deuxième la probabilité notée. Cette fleur est prédite en tant que Classe 1 avec une probabilité de 0,9655.
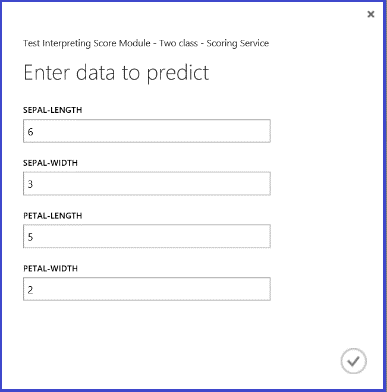

Figure 5. Résultat du service web de classification double classe Iris
Classification multiclasse.
Exemple d'expérience
Lors de cette expérience, vous réalisez une tâche de reconnaissance de lettres en tant qu’exemple de classification multiclasse. Le classificateur essaye de prédire une lettre %28classe%29, compte tenu de certaines valeurs d’attribut manuscrites, extraites d’images manuscrites.
Dans les données de formation, 16 caractéristiques sont extraites d’images de lettres écrites. Les 26 lettres forment nos 26 classes. La figure 6 montre une expérience qui va former un modèle de classification multiclasse de reconnaissance de lettres et établir des prédictions sur le même ensemble de fonctionnalités d’un jeu de données de test.
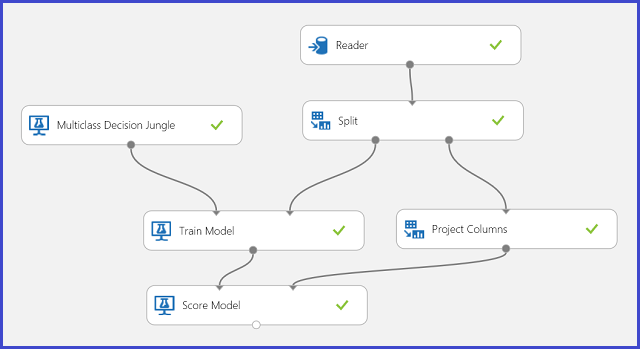
Figure 6. Expérience de problème de classification multiclasse de reconnaissance de lettre
Lorsque vous visualisez les résultats du module Noter le modèle en cliquant sur le port de sortie du module Noter le modèle, puis sur Visualiser, vous devez voir apparaître une fenêtre, comme illustré dans la Figure 7.
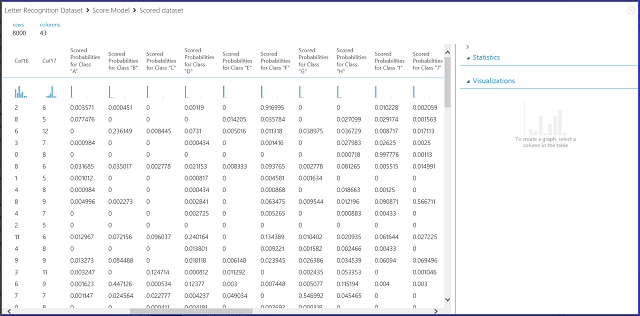
Figure 7. Visualisation du résultat de modèle de notation dans la classification multiclasse
Interprétation du résultat
Les 16 colonnes de gauche représentent les valeurs caractéristiques de l’ensemble du test. Les colonnes intitulées Probabilités notées de classe « XX » sont similaires à la colonne Probabilités notées dans le cas d’utilisation d’une classification double classe. Elles indiquent la probabilité que l'entrée correspondante est comprise dans une certaine classe. Par exemple, pour la première entrée, il y a une probabilité de 0,003571 que ce soit un « A », une probabilité de 0,000451 que ce soit un « B », et ainsi de suite. La dernière colonne (Étiquettes notées) est identique aux Étiquettes notées dans le cas d’utilisation d’une classification double classe. Elle sélectionne la classe présentant la probabilité notée la plus élevée en tant que classe prédite de l'entrée correspondante. Par exemple, pour la première entrée, l’étiquette notée est un « F », car elle présente la probabilité la plus élevée que ce soit un « F » (0,916995).
Publication du service web
Vous pouvez également obtenir l’étiquette notée pour chaque entrée et la probabilité de l’étiquette notée. La logique de base consiste à trouver la probabilité la plus élevée parmi toutes les probabilités notées. Pour ce faire, vous devez utiliser le module Exécuter le script R. Le code R est mentionné dans la Figure 8 et le résultat de l’expérience dans la Figure 9.

Figure 8. Code R permettant d’extraire les étiquettes notées et les probabilités associées des étiquettes
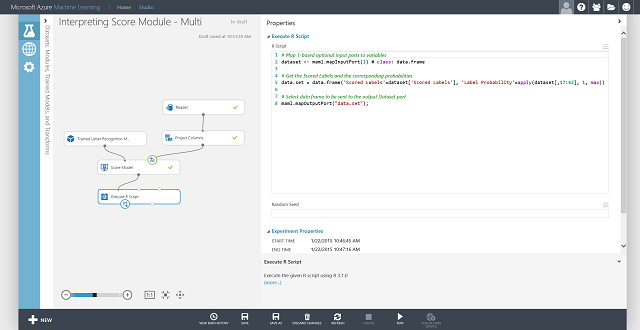
Figure 9. Expérience de notation finale d’un problème de classification multiclasse de reconnaissance de lettres
Une fois le service web publié et exécuté, et certaines valeurs caractéristiques d’une instance de test saisies, le résultat renvoyé est semblable à celui mentionné dans la Figure 10. Cette lettre écrite, accompagnée de ses 16 caractéristiques extraites, est prédite pour être un « T » avec une probabilité de 0,9715.

Figure 10. Résultat du service web de classification multiclasse
régression ;
Les problèmes de régression sont différents des problèmes de classification. Dans un problème de classification, vous essayez de prédire les classes discrètes, telles que la classe à laquelle appartient une fleur d’iris. Mais dans un problème de régression, comme indiqué dans l’exemple suivant, nous essayons de prédire une variable continue, comme le prix d’une voiture.
Exemple d'expérience
Utilisez la prédiction du prix d’une voiture comme exemple de régression. Vous essayez de prédire le prix d’une voiture en fonction de ses fonctionnalités comme la marque, le type de carburant, le type de voiture, le type de traction, etc. L'expérience est indiquée dans la Figure 11.
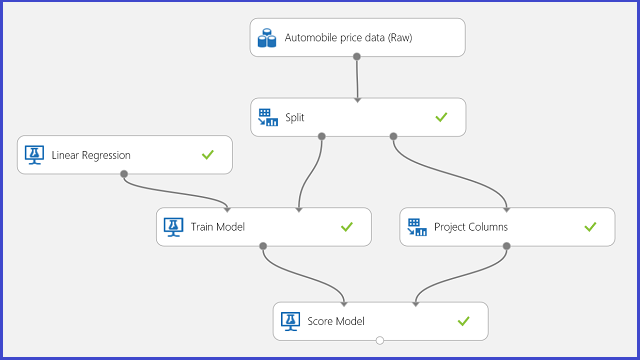
Figure 11. Expérience de problème de régression de prix des véhicules automobiles
Visualisation du module Noter le modèle, le résultat est semblable à celui mentionné dans la Figure 12.
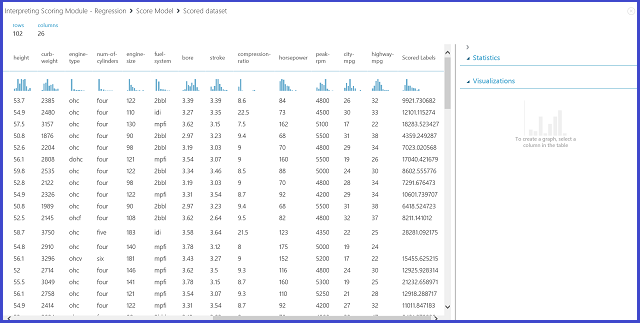
Figure 12. Résultats d’évaluation du problème de prédiction du prix des véhicules automobiles
Interprétation du résultat
Les étiquettes notées représentent la colonne de résultat dans ce résultat de notation. Les nombres constituent le prix prédit pour chaque voiture.
Publication du service web
Vous pouvez publier l’expérience de régression dans un service web et la solliciter pour prédire le prix d’une voiture de la même manière que dans le cas d’utilisation d’une classification double classe.
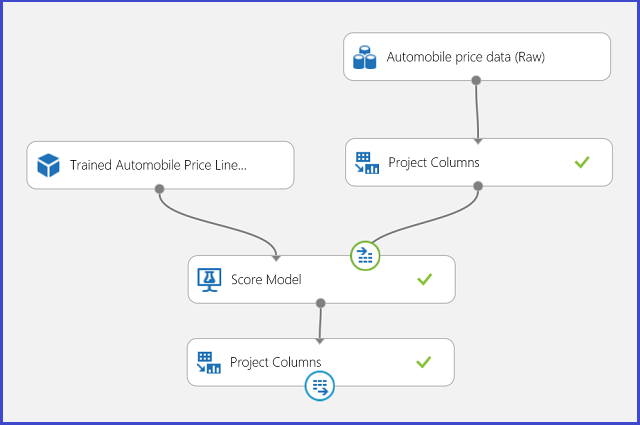
Figure 13. Expérience de notation pour un problème de prédiction du prix des véhicules automobiles
Exécution du service web, le résultat renvoyé est semblable à celui indiqué dans la Figure 14. Le prix prédit de cette voiture est de 15 085,52 $.
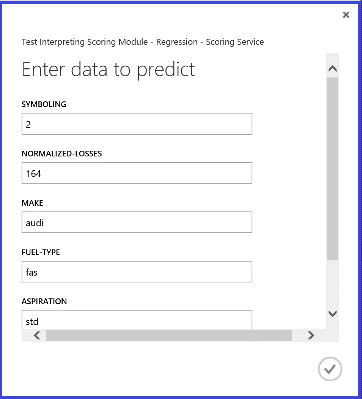

Figure 14 : Résultat du service web d’un problème de régression du prix d’une voiture
Clustering
Exemple d'expérience
Utilisons le jeu de données Iris pour réaliser une expérience de clustering. Nous filtrons ici les étiquettes de classe dans le jeu de données de manière à ce qu’il ne contienne que des caractéristiques et puisse être utilisé uniquement pour le clustering. Dans ce cas d’utilisation Iris, définissez deux clusters lors du processus de formation, pour regrouper les fleurs en deux classes. L'expérience est indiquée dans la Figure 15.
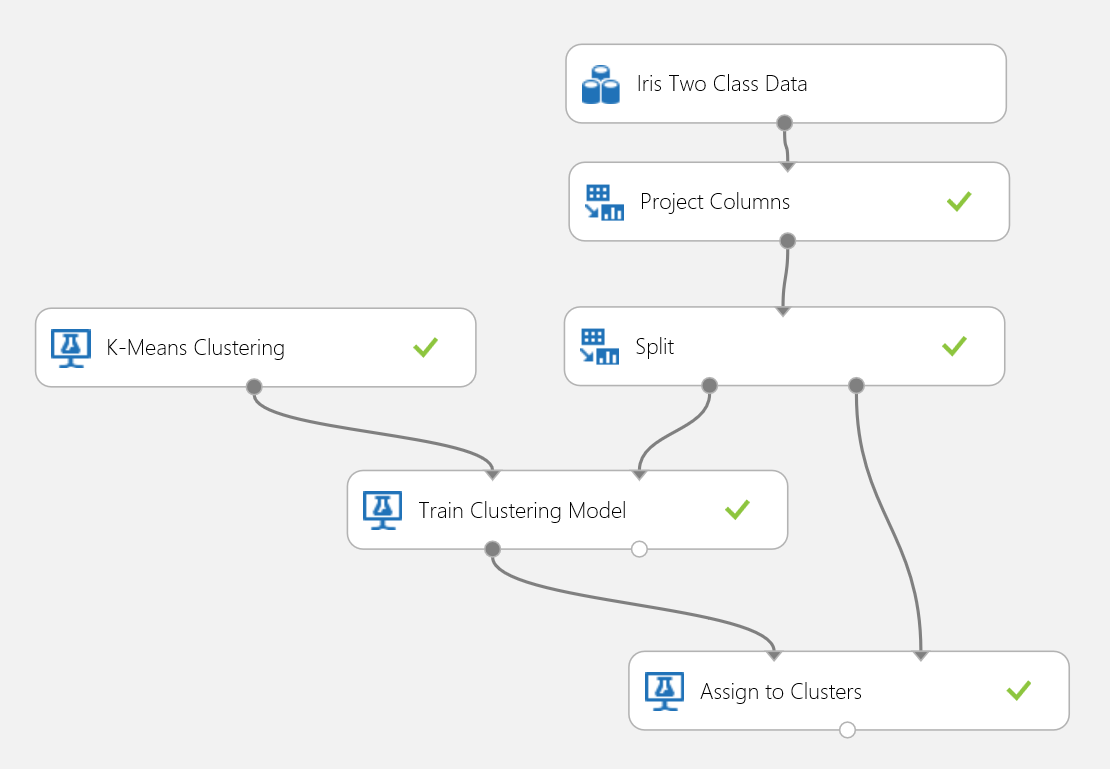
Figure 15 : Expérience d’un problème de clustering Iris
Le clustering diffère de la classification, car le jeu de données d’apprentissage ne dispose pas lui-même des étiquettes réelles. Le clustering regroupe les instances du jeu de données de formation dans des groupes distincts. Lors du processus de formation, le modèle étiquette les entrées en prenant compte des différences existantes entre leurs fonctionnalités. Le modèle formé peut être ensuite utilisé pour classifier les entrées futures. Deux parties du résultat nous intéressent au sein d'un problème de clustering. La première partie est l’étiquetage du jeu de données d’apprentissage et le second est le classement du nouveau jeu de données avec le modèle formé.
La première partie du résultat peut être visualisée en cliquant sur le port de sortie gauche de Former le modèle de clustering, puis sur Visualiser. La visualisation est présentée dans la Figure 16.
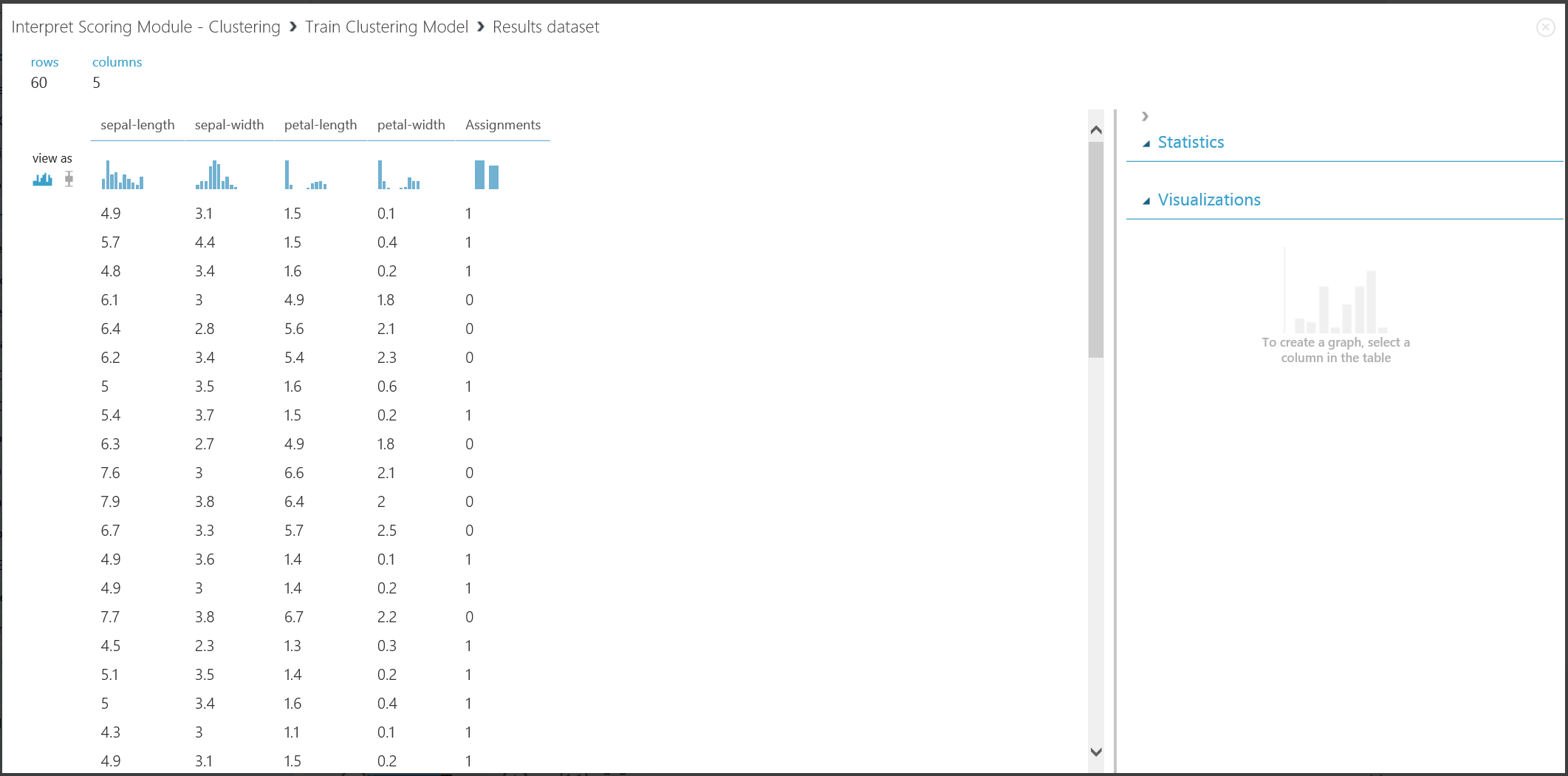
Figure 16 : Visualisation du résultat de clustering pour le jeu de données de formation
Le résultat de la deuxième partie, regroupant de nouvelles entrées avec le modèle de clustering formé, est indiqué dans la Figure 17.
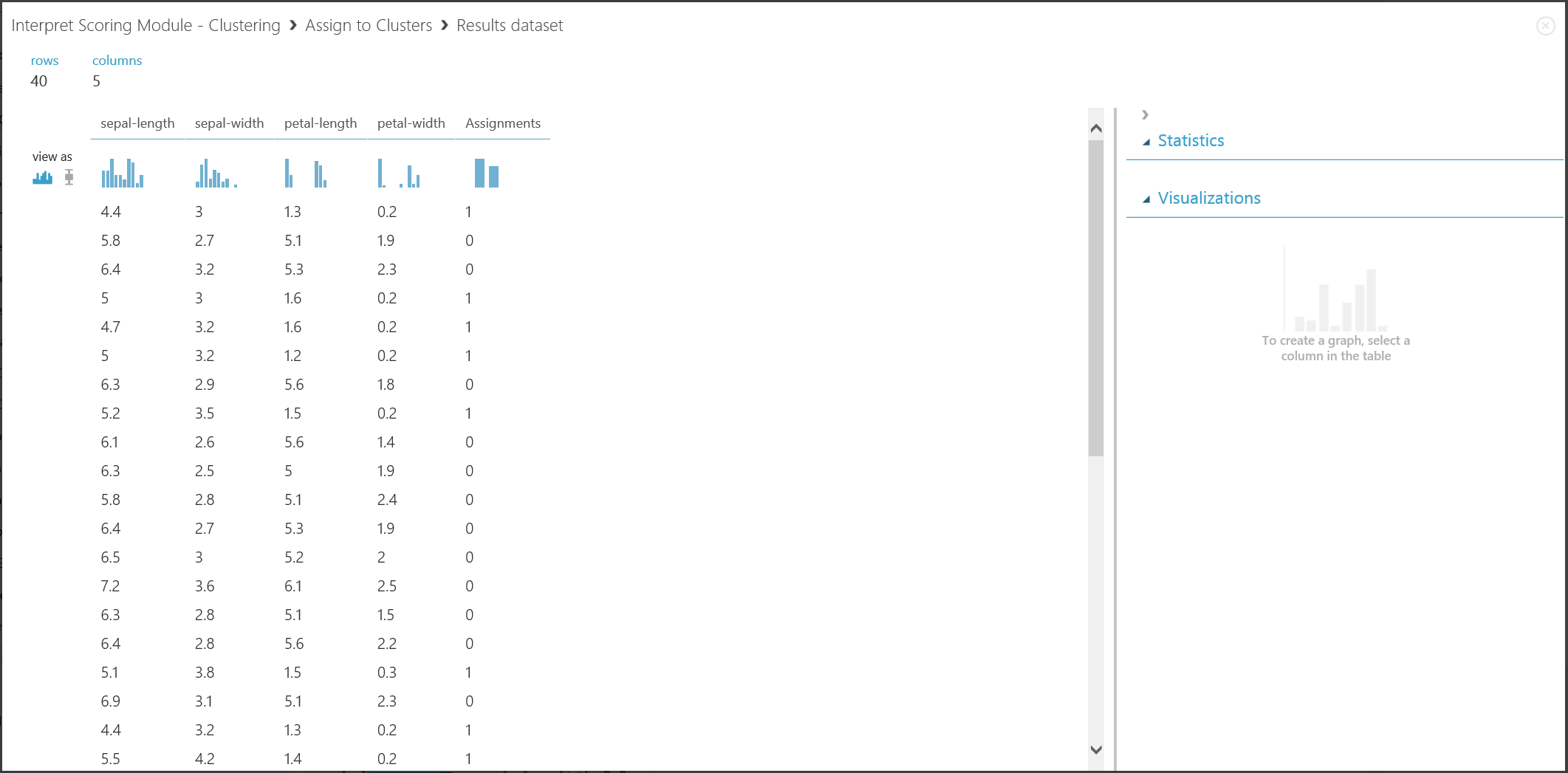
Figure 17 : Visualisation du résultat de clustering sur un nouveau jeu de données
Interprétation du résultat
Bien que provenant d’étapes d’expérience différentes, les résultats des deux parties sont similaires et interprétés de la même manière. Les quatre premières colonnes représentent les caractéristiques. La dernière colonne, Affectations, représente les résultats de prédiction. Les entrées affectées du même numéro sont prédites dans le même groupe, c’est-à-dire qu’elles partagent d’une certaine façon des similitudes (cet te expérience utilise la mesure de la distance euclidienne par défaut). Étant donné que vous avez spécifié 2 comme nombre de clusters, les entrées dans Affectations sont étiquetées 0 ou 1.
Publication du service web
Vous pouvez publier l’expérience de clustering dans un service web et la solliciter pour des prédictions de clustering de la même manière que dans le cas d’utilisation d’une classification double classe.
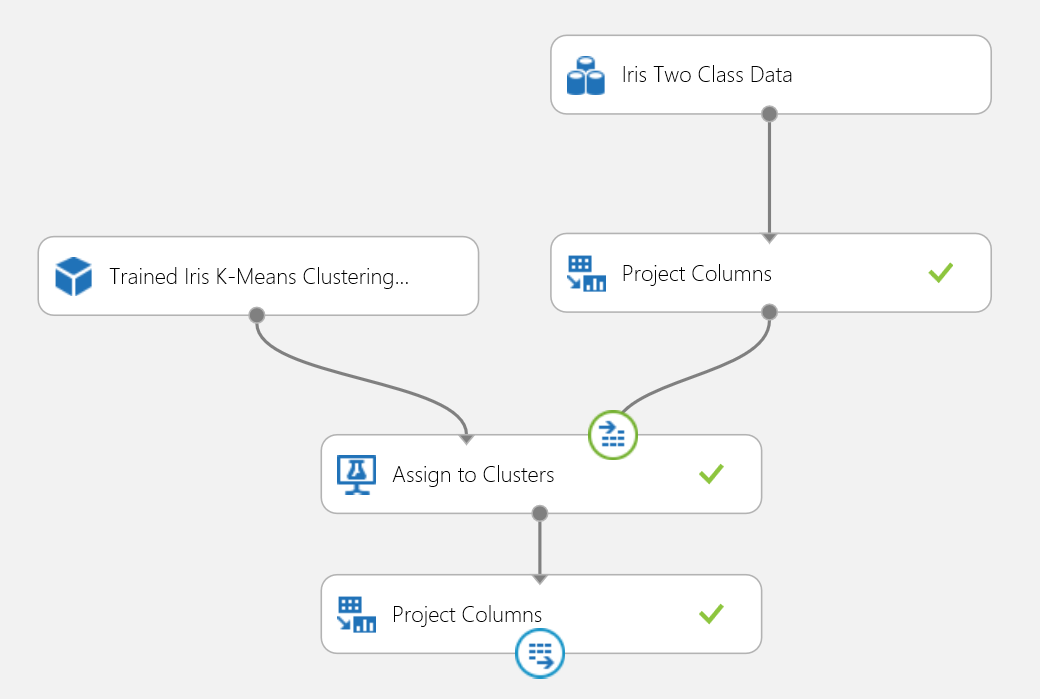
Figure 18 : Expérience de notation d’un problème de clustering Iris
Une fois le service web exécuté, le résultat renvoyé est semblable à celui indiqué dans la Figure 19. Cette fleur est prédite dans le cluster 0.
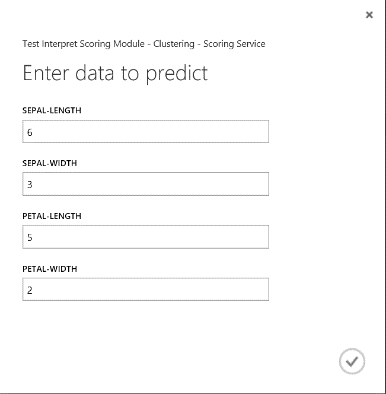

Figure 19 : Résultat du service web de classification double classe Iris
Système de recommandation
Exemple d'expérience
Pour les systèmes de recommandation, vous pouvez utiliser le problème de recommandation de restaurants à titre d’exemple : recommander des restaurants aux clients en fonction de leur historique de notation. Les données d'entrée sont composées de trois parties :
- Notations de restaurants attribuées par les clients
- Données caractéristiques des clients
- Données sur les caractéristiques de restaurants
Plusieurs tâches peuvent être effectuées via le module Former la recommandation Matchbox de Machine Learning Studio (classique), à savoir :
- Prédire des notations pour un utilisateur et un élément donné
- Recommander des éléments à un utilisateur donné
- Trouver des utilisateurs associés à un utilisateur donné
- Trouver des éléments associés à un élément donné
Vous pouvez choisir ce que vous voulez en sélectionnant parmi les quatre options du menu Type de prédiction de recommandation. Vous pouvez parcourir quatre scénarios.
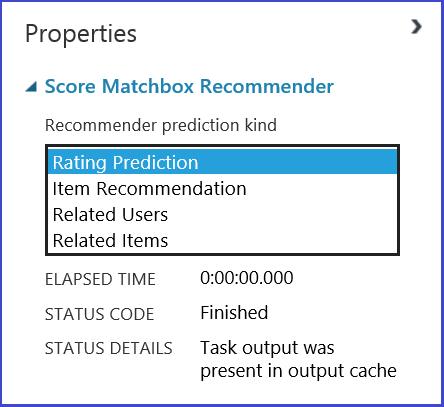
Une expérience Azure Machine Learning Studio (classique) type pour un système de recommandation est semblable à celui de la Figure 20. Pour plus d’informations sur l’utilisation de ces modules de système de recommandation, consultez les rubriques Former la recommandation Matchbox et Noter la recommandation Matchbox.
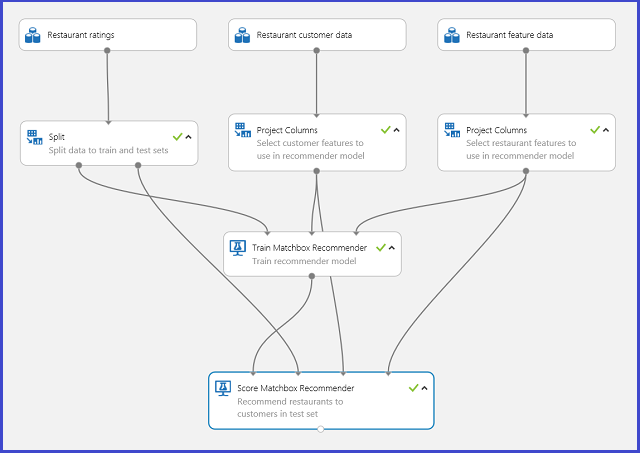
Figure 20 : Expérience du système de recommandation
Interprétation du résultat
Prédire des notations pour un utilisateur et un élément donné
En sélectionnant Prédiction de notation dans le menu Type de prédiction de recommandation, vous demandez au système de recommandation de prédire la notation pour un utilisateur et un élément donné. La visualisation de la sortie Noter la recommandation Matchbox est semblable à celle mentionnée dans la Figure 21.
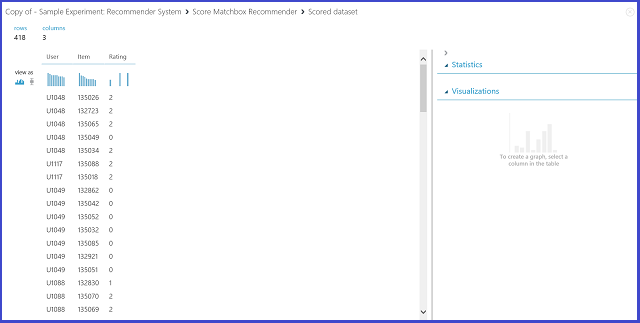
Figure 21 : Visualisation du résultat de notation du système de recommandation - Prédiction de notation
Les deux premières colonnes représentent les paires utilisateur-élément fournies par les données d'entrée. La troisième colonne représente la notation prédite d'un utilisateur pour un élément donné. Par exemple, dans la première ligne, le client U1048 est censé attribuer au restaurant 135 026 la note de 2.
Recommander des éléments à un utilisateur donné
En sélectionnant Recommandation d’éléments dans le menu Type de prédiction de recommandation, vous demandez au système de recommandation de recommander des éléments à un utilisateur donné. Le dernier paramètre à choisir dans ce scénario est la sélection d’éléments recommandés. L'option À partir d'éléments notés (pour l'évaluation de modèle) est principalement utilisée pour l'évaluation de modèle lors du processus de formation. Pour cette étape de prédiction, nous choisissons À partir de tous les éléments. La visualisation de la sortie Noter la recommandation Matchbox est semblable à celle mentionnée dans la Figure 22.
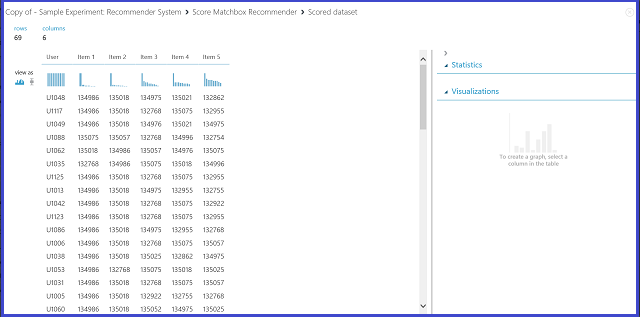
Figure 22 : Visualisation du résultat de notation du système de recommandation - Recommandation d’éléments
La première des six colonnes représente le nom de l’utilisateur donné pour lequel nous recommandons des éléments, fournis par les données d’entrée. Les cinq colonnes restantes représentent les éléments recommandés à l’utilisateur, classés par ordre décroissant en fonction de leur pertinence. Par exemple, dans la première ligne, le restaurant le plus recommandé au client U1048 est le restaurant 134986, suivi des restaurants 135018, 134975, 135021 et 132862.
Trouver des utilisateurs associés à un utilisateur donné
En sélectionnant Utilisateurs associés dans Type de prédiction de recommandation, nous demandons au système de recommandation de trouver des utilisateurs associés à un utilisateur donné. Les utilisateurs associés sont les utilisateurs qui ont des préférences similaires. Le dernier paramètre à choisir dans ce scénario est la sélection de l’utilisateur associé. L’option À partir d’utilisateurs qui ont noté des éléments (pour l’évaluation de modèle) est principalement utilisée pour l’évaluation de modèle lors du processus de formation. Pour cette étape de prédiction, choisissez À partir de tous les utilisateurs. La visualisation de la sortie Noter la recommandation Matchbox est semblable à celle mentionnée dans la Figure 23.
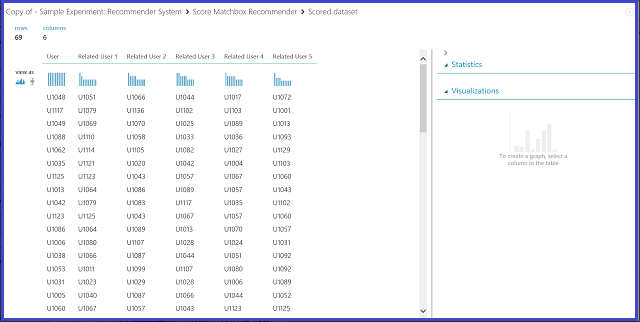
Figure 23 : Visualisation du résultat de notation du système de recommandation - Utilisateurs associés
La première des six colonnes contient les ID utilisateurs donnés nécessaires pour rechercher des utilisateurs liés, comme fournis par les données d’entrée. Les cinq colonnes restantes répertorient les utilisateurs associés prédits, classés par ordre décroissant en fonction de leur pertinence. Par exemple, dans la première ligne, le client le plus pertinent pour le client U1048 est le client U1051, suivi des clients U1066, U1044, U1017 et U1072.
Trouver des éléments associés à un élément donné
En sélectionnant Éléments associés dans le menu Type de prédiction de recommandation, vous demandez au système de recommandation de trouver des éléments associés à un élément donné. Les éléments associés sont les éléments les plus susceptibles d'être appréciés par le même utilisateur. Le dernier paramètre à choisir dans ce scénario est la sélection de l’article associé. L'option À partir d'éléments notés (pour l'évaluation de modèle) est principalement utilisée pour l'évaluation de modèle lors du processus de formation. Pour cette étape de prédiction, nous choisissons À partir de tous les éléments . La visualisation de la sortie Noter la recommandation Matchbox est semblable à celle mentionnée dans la Figure 24.
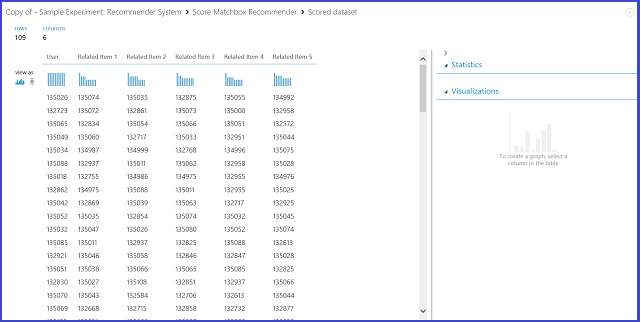
Figure 24 : Visualisation du résultat de notation du système de recommandation - articles associés
La première des six colonnes représente le nom de l’élément donné pour les éléments associés, fournis par les données d’entrée. Les cinq colonnes restantes répertorient les éléments associés prédits, classés par ordre décroissant en fonction de leur pertinence. Par exemple, dans la première ligne, l’élément le plus pertinent pour l’élément 135026 est l’élément 135074, suivi des éléments 135035, 132875, 135055 et 134992.
Publication du service web
Le processus de publication de ces expériences en tant que services web permettant d'obtenir des prédictions est similaire pour chacun des quatre scénarios. Nous nous attardons ici sur le second scénario, la recommandation d’éléments à un utilisateur donné, à titre d’exemple. Vous pouvez suivre la même procédure pour les trois autres.
Enregistrement du système de recommandation formé en tant que modèle formé et filtrage des données d’entrée dans une colonne d’ID utilisateur unique (tel que cela a été demandé), vous pouvez raccorder l’expérience, comme mentionné dans la Figure 25, et la publier en tant que service web.
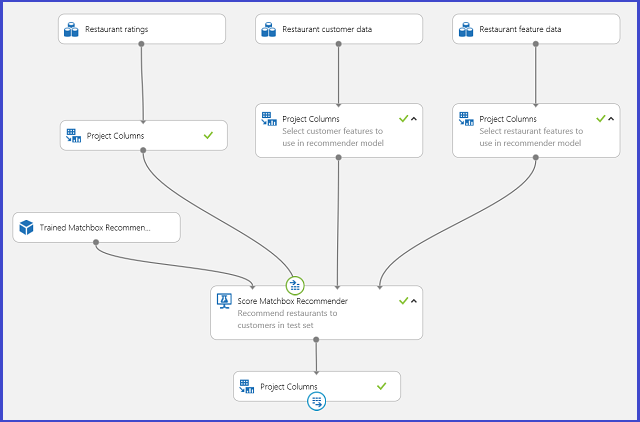
Figure 25 : Expérience de notation d’un problème de recommandation de restaurants
Exécution du service web, le résultat renvoyé est semblable à celui indiqué dans la Figure 26. Les cinq restaurants recommandés pour l’utilisateur U1048 sont les restaurants 134986, 135018, 134975, 135021 et 132862.
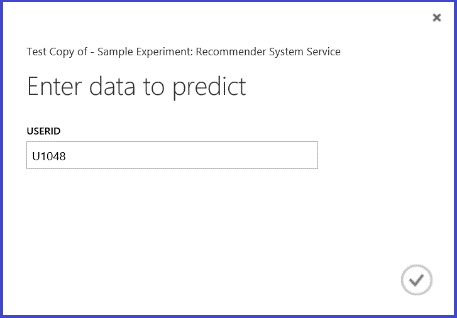

Figure 26 : Résultat du service web d’un problème de recommandation de restaurants