Choisir les paramètres permettant d’optimiser des algorithmes dans Machine Learning Studio (classique)
S’APPLIQUE À :  Machine Learning Studio (classique)
Machine Learning Studio (classique)  Azure Machine Learning
Azure Machine Learning
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Cette rubrique explique comment choisir le bon ensemble d’hyperparamètres pour un algorithme dans Machine Learning Studio (classique). La plupart des algorithmes Machine Learning ont des paramètres qui doivent être définis. Lorsque vous gérez l’apprentissage d’un modèle, vous devez fournir des valeurs pour ces paramètres. L’efficacité du modèle formé dépend des paramètres de modèle choisis. Le processus de recherche de l’ensemble optimal de paramètres est connu sous le nom de sélection du modèle.
Il existe différentes manières d’effectuer une sélection de modèle. Dans Machine Learning, la méthode de validation croisée est l’une des plus largement utilisées pour la sélection de modèle. Il s’agit du mécanisme par défaut utilisé à cette fin dans Machine Learning Studio (classique). Comme les langages R et Python sont pris en charge par Machine Learning Studio (classique), vous pouvez toujours implémenter votre propre mécanisme de sélection de modèle dans l’un ou l’autre de ces langages.
Le processus de recherche de l’ensemble de paramètres idéal comprend quatre étapes :
- Définir l’espace de paramètre : pour l’algorithme, vous devez d’abord déterminer les valeurs de paramètres exactes que vous souhaitez prendre en compte.
- Définir les paramètres de validation croisée : déterminez comment choisir les plis de validation croisée pour le jeu de données.
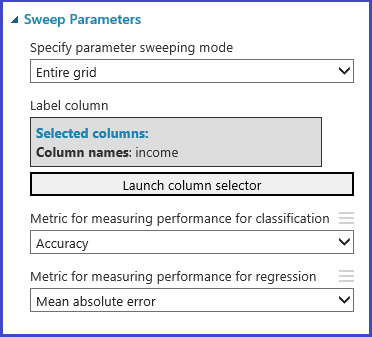
- Définir la mesure : déterminez la mesure à utiliser pour évaluer l’ensemble de paramètres le plus approprié (exactitude, erreur quadratique moyenne, précision, rappel ou f-score).
- Apprentissage, évaluation et comparaison : pour chaque combinaison unique de valeurs de paramètres, la validation croisée est effectuée selon la mesure d’erreur que vous définissez. Après évaluation et comparaison, vous pouvez choisir le modèle le plus performant.
L’image ci-dessous illustre cette opération dans Machine Learning Studio (classique).
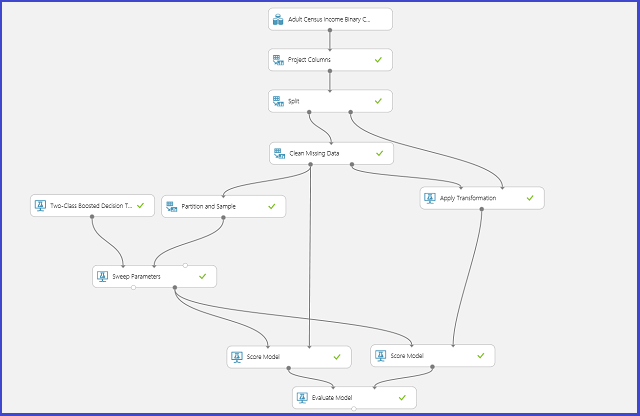
Définir l’espace de paramètre
L’ensemble de paramètres peut être défini lors de l’étape d’initialisation du modèle. Le volet de paramètres de l’ensemble des algorithmes ML propose deux modes de formation : Paramètre unique et Plage de paramètres. Choisissez le mode Plage de paramètres. En mode Plage de paramètres, vous pouvez entrer plusieurs valeurs pour chaque paramètre. Vous pouvez entrer des valeurs séparées par des virgules dans la zone de texte.
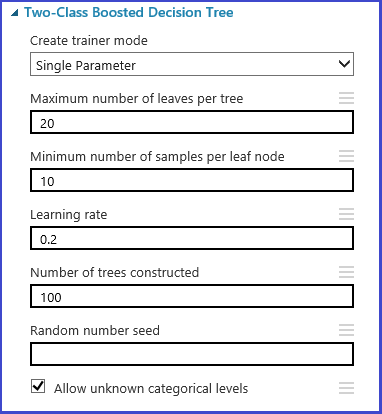
Vous pouvez également définir les points minimum et maximum de la grille et le nombre total de points à générer à l’aide de l’option Utiliser le générateur de plage. Par défaut, les valeurs de paramètre sont générées sur une échelle linéaire. Cependant, si l’option Échelle logarithmique est activée, les valeurs sont générées sur une échelle logarithmique (selon laquelle le rapport entre les points adjacents est constant, et non leur différence). Pour les paramètres entiers, vous pouvez définir une plage à l’aide d’un trait d’union. Par exemple, « 1-10 » signifie que tous les entiers compris entre 1 et 10 (tous deux inclus) forment le jeu de paramètres. Un mode mixte est également pris en charge. Par exemple, l’ensemble de paramètres « 1-10, 20, 50 » inclut les entiers 1 à 10, 20 et 50.
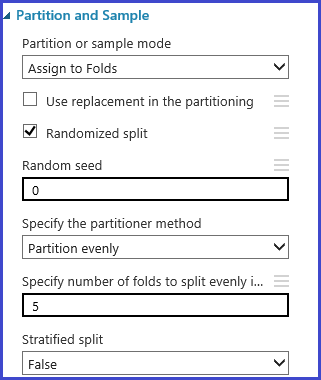
Définir les plis de validation croisée
Le module Partition et échantillon peut être utilisé pour affecter des plis aux données, de manière aléatoire. Dans l’exemple de configuration suivant pour ce module, nous allons définir cinq plis et affecter au hasard le nombre de plis aux exemples d’instances.
Définir la mesure
Le module Tune Model Hyperparameters assure la prise en charge de la sélection empirique du meilleur ensemble de paramètres pour un algorithme et un jeu de données spécifiques. En plus d’autres informations concernant l’apprentissage du modèle, le volet des propriétés de ce module comprend la mesure à utiliser pour déterminer le meilleur ensemble de paramètres. Il présente deux listes déroulantes différentes pour les algorithmes de classification et de régression, respectivement. Si l’algorithme en question est un algorithme de classification, la mesure de régression est ignorée, et vice versa. Dans cet exemple, la mesure est Exactitude .
Apprentissage, évaluation et comparaison
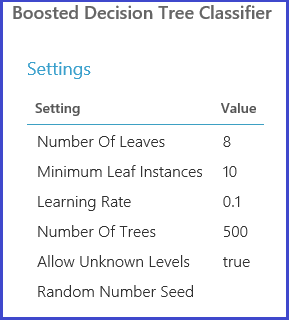
Le même module Tune Model Hyperparameters gère l’apprentissage de tous les modèles correspondant à l’ensemble de paramètres, évalue diverses mesures et crée ensuite le meilleur modèle formé en fonction de la mesure choisie. Ce module dispose de deux entrées obligatoires :
- Apprenant non formé
- Jeu de données
Le module dispose également d’un jeu de données d’entrée facultatif. Connectez le jeu de données incluant des informations sur les plis au jeu de données en entrée obligatoire. Si le jeu de données n’est associé à aucune information sur les plis, une validation croisée de 10 plis est exécutée automatiquement, par défaut. Si l’affectation de plis n’est pas effectuée et si un jeu de données de validation est fourni au port de jeu de données facultatif, un mode de test de formation est sélectionné et le premier jeu de données est utilisé pour gérer l’apprentissage du modèle pour chaque combinaison de paramètres.
Le modèle est ensuite évalué sur le jeu de données de validation. Le port de sortie de gauche du module affiche des mesures différentes comme fonctions des valeurs de paramètres. Le port de sortie de droite indique le modèle formé correspondant au modèle le plus performant, en fonction de la mesure choisie (dans ce cas, l’exactitude).
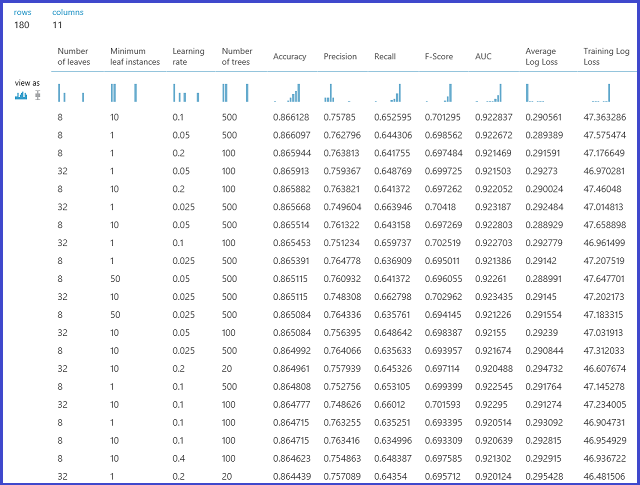
Vous pouvez voir les paramètres exacts choisis en visualisant le port de sortie de droite. Ce modèle peut être utilisé lors du calcul de la notation d’un ensemble de test ou dans un service web mis en œuvre après l’enregistrement en tant que modèle formé.