Scale-out du modèle sémantique Power BI
Le scale-out du modèle sémantique permet à Power BI de fournir des performances rapides pendant que vos rapports et tableaux de bord sont consommés par un grand public. La fonctionnalité Scale-out de jeux de données utilise votre capacité Premium pour héberger un ou plusieurs réplicas en lecture seule de votre modèle sémantique principal. En augmentant le débit, les réplicas en lecture seule veillent à ce que les performances ne ralentissent pas lorsque plusieurs utilisateurs envoient des requêtes en même temps.
Lorsque Power BI crée des réplicas en lecture seule, il les sépare du modèle sémantique en lecture-écriture primaire. Les réplicas en lecture seule servent des requêtes de rapport et de tableau de bord Power BI, et le modèle sémantique en lecture-écriture est utilisé lorsque des opérations d’écriture et d’actualisation sont effectuées. Pendant des opérations d’écriture et d’actualisation, les réplicas en lecture seule continuent de servir vos requêtes de rapports et tableaux de bord sans être interrompus. Par défaut, les modèles sémantiques en lecture seule et en lecture-écriture sont automatiquement synchronisés afin que les réplicas en lecture seule soient conservés à jour. Toutefois, vous pouvez désactiver la synchronisation automatique et choisir de synchroniser manuellement sur la ligne de commande ou par script.
Le tableau suivant montre la synchronisation requise pour chaque méthode d’actualisation lorsque le scale-out du modèle sémantique Power BI est activé, et que la synchronisation automatique est désactivée:
| Refresh, méthode | Synchronisation |
|---|---|
| Interface utilisateur OnDemand | Synchrone toujours |
| Actualisation planifiée | Synchrone toujours |
| API REST De base | Synchronisation manuelle requise 1 |
| API REST avancée | Synchronisation manuelle requise 1 |
| XMLA | Synchronisation manuelle requise 1 |
1 : avec autoSyncReadOnlyReplicas dans queryScaleOutSettings réglé sur la valeur false.
Gestion des réplicas
Le scale-out crée un réplica de modèle sémantique en lecture-écriture et autant de réplicas en lecture seule qu’il est nécessaire. Toutes les opérations d’écriture sont dirigées vers le réplica en lecture-écriture. Cela inclut les requêtes sur les sessions qui ciblent explicitement le réplica en lecture-écriture, autrement dit celles qui n’utilisent pas ?readonly dans la chaîne de connexion. Ces requêtes peuvent entraîner une utilisation interactive élevée du processeur sur le réplica en lecture-écriture. Dans ce cas, aucun nouveau réplica n’est créé, car la charge de requête ciblant le réplica en lecture-écriture ne peut pas être distribuée aux réplicas en lecture seule.
Le nombre de réplicas en lecture seule est déterminé en fonction du nombre d’unités de requête consommées par vos requêtes. Si la demande dépasse les ressources de calcul actuellement disponibles sur un nœud où le modèle est chargé et reste élevé, un réplica en lecture seule supplémentaire peut être créé sur un autre nœud pour distribuer la charge. Toutefois, le nombre total d’unités de requête consommées par tous les réplicas combinés ne peut pas dépasser le nombre maximal d’unités de certification qu’un seul modèle est autorisé à consommer sur votre référence SKU de capacité donnée.
Par exemple, un modèle sémantique donné sur une capacité F64 aura suffisamment de ressources sur un nœud unique pour consommer toutes les unités de certification autorisées sur cette référence SKU. Par conséquent, les capacités F64 ne sont généralement pas mises à l’échelle au-delà d’un seul réplica en lecture seule. En revanche, les capacités F256 et F1024+ sont plus susceptibles de créer un deuxième réplica en lecture seule, car un seul nœud peut ne pas suffire pour fournir toutes les unités de gestion autorisées à être utilisées sur une capacité F256/F1024+.
QSO est conçu pour tirer parti de la puissance de calcul disponible d’une référence SKU de capacité donnée aussi efficacement et en toute transparence que possible avec le moins de réplicas en lecture seule et sans surcharge de gestion pour les propriétaires de modèles sémantiques.
Toutefois, la charge actuelle sur une capacité peut être suffisamment élevée pour provoquer une limitation si d’autres réplicas sont ajoutés. La limitation empêche les réplicas en lecture seule supplémentaires d’atteindre une utilisation soutenue du processeur. Dans ce cas, aucun réplica de scale-out en lecture seule n’est créé.
Un réplica est supprimé lorsque l’utilisation de cu pour le modèle réduit suffisamment et reste constamment suffisamment faible.
Prérequis
Par défaut, le scale-out est activé pour votre locataire, mais il n’est pas activé pour les modèles sémantiques de votre locataire. Pour activer la fonctionnalité Scale-out pour un modèle sémantique, vous devez utiliser les API REST Power BI. Avant l’activation, les conditions préalables suivantes doivent être remplies :
Les requêtes scale-out pour les modèles sémantiques volumineux paramètre pour votre locataire sont activées (par défaut).
Votre espace de travail réside sur une capacité Power BI Premium :
- Premium par utilisateur (PPU)
- Références SKU Power BI Premium P
- Power BI Une référence SKU pour le service Power BI Embedded (également appelé incorporer pour vos clients).
- Références SKU Fabric F
Le paramètre format de stockage de modèle sémantique volumineux est activé.
Pour gérer des modèles sémantiques à l’aide de l’API REST, utilisez les cmdlet*de commande de gestion Power BI. Installez en ouvrant PowerShell en mode Administrateur et en exécutant la commande :
Install-Module -Name MicrosoftPowerBIMgmtLes versions d’application, de bibliothèque et de service suivantes (ou ultérieures) prennent en charge la connexion à des réplicas en lecture seule :
Application, bibliothèque ou service Version Fournisseur Microsoft Analysis Services OLE DB pour Microsoft SQL Server (MSOLAP) 16.0.20.201 (mars 2022) Microsoft.AnalysisServices.AdomdClient (ADOMD.NET) 19.36.0 (mars 2022) Power BI Desktop Juin 2022 SQL Server Management Studio (SSMS) 19,0 Éditeur tabulaire 2 2.16.6 Éditeur tabulaire 3 3.2.3 DAX Studio 3.0.0
Configurer le scale-out pour un modèle sémantique
Pour savoir comment activer ou désactiver le scale-out pour un modèle sémantique, ou obtenir un état scale-out à l’aide de PowerShell et des API REST, consultez Configurer un scale-out de modèle sémantique.
Se connecter à un type de modèle sémantique spécifique
Lorsque la fonctionnalité Scale-Out est activée, les connexions suivantes sont conservées :
Par défaut, Power BI Desktop se connecte à un réplica en lecture seule.
Les rapports de connexion active se connectent à un réplica en lecture seule.
Les applications clientes XMLA se connectent au modèle sémantique en lecture-écriture par défaut.
Actualise dans le service Power BI et actualise à l’aide de l’API REST d’actualisation améliorée se connecter au modèle sémantique en lecture-écriture.
Vous pouvez vous connecter à un réplica en lecture seule ou au modèle sémantique en lecture-écriture en ajoutant l’une des chaînes suivantes à l’URL du modèle sémantique :
- Lecture seule -
?readonly - Lecture/écriture -
?readwrite
Désactiver le scale-out du modèle sémantique pour votre locataire
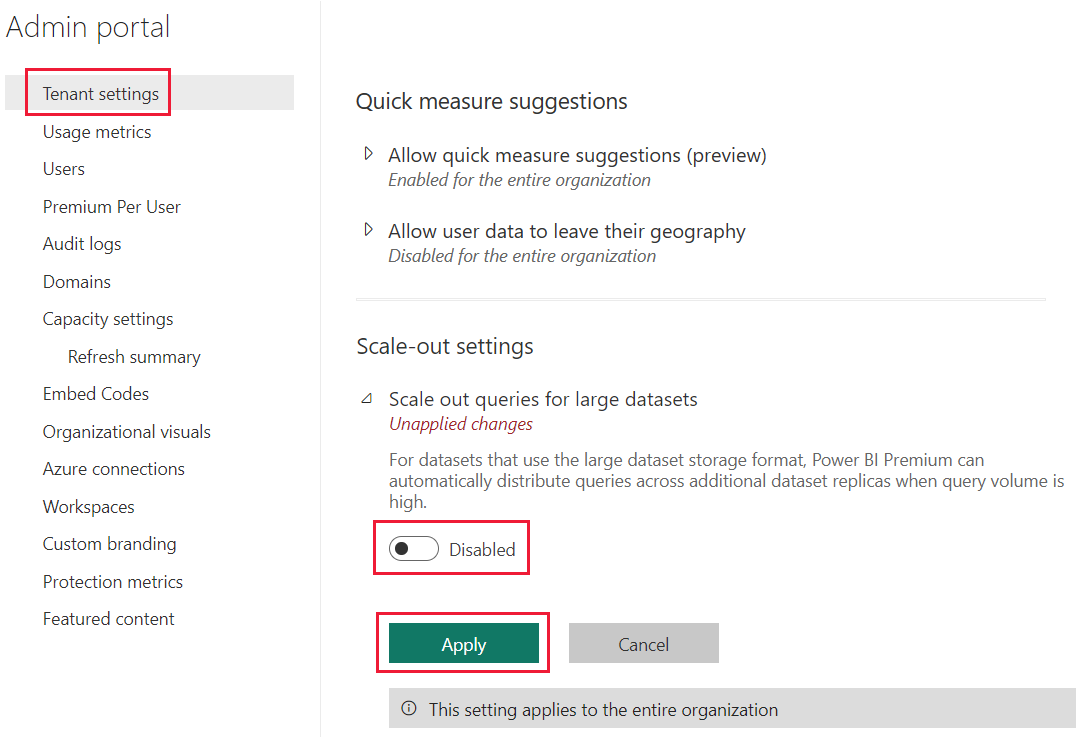
Le scale-out du modèle sémantique Power BI est activé par défaut pour un locataire. Les administrateurs de locataires Power BI peuvent désactiver ce paramètre. Pour désactiver le scale-out du modèle sémantique pour le locataire, procédez comme suit :
Accédez aux paramètres de votre locataire.
Dans paramètres de scale-out, développez requêtes scale-out pour les modèles sémantiques volumineux.
Basculez le commutateur sur Disabled (Désactivé).
Sélectionnez Appliquer.
Observations et limitations
Les applications clientes peuvent se connecter à un réplica en lecture seule via le point de terminaison XMLA, à condition qu’elles prennent en charge le mode spécifié sur la chaîne de connexion. Les applications clientes peuvent également se connecter à l’instance en lecture/écriture en utilisant le point de terminaison XMLA.
Les actualisations manuelles et planifiées sont toujours automatiquement synchronisées avec la dernière version des réplicas en lecture seule. Les actualisations de l’API REST respectent la configuration de synchronisation automatique. Si la synchronisation automatique est désactivée, votre modèle sémantique doit être synchronisé avec les réplicas en lecture seule à l’aide de l’API REST de synchronisation manuelle.
Une fois la synchronisation automatique désactivée, les mises à jour et les actualisations XMLA doivent être synchronisées avec les copies de modèle sémantique en lecture seule à l’aide de l’API REST de synchronisation.
Lors de la suppression d’un modèle sémantique de scale-out Power BI et de la création d’un autre modèle sémantique portant le même nom, autorisez cinq minutes à passer avant de créer le nouveau modèle sémantique. Power BI peut prendre un certain temps pour supprimer les réplicas du modèle sémantique principal.
Lorsque le scale-out du modèle sémantique Power BI est activé et que
autoSyncReadOnlyReplicas=false, les modifications apportées aux fonctionnalités suivantes ne sont pas prises en charge :- Ajout ou suppression de rôles
- Mise à jour de l’ensemble d’appartenances aux rôles pour n’importe quel rôle
- Modification d’une source de données
- Suppression de sources de données utilisées par DirectQuery ou une table DUAL
- Modifications apportées aux expressions de sécurité au niveau des objets (OLS) ou de sécurité dynamique au niveau des lignes (RLS)
Pour apporter des modifications à ces fonctionnalités, désactivez la fonctionnalité Scale-Out et patientez quelques minutes pour que la modification soit prise en compte avant de réactiver la fonctionnalité.
La découverte des appartenances aux rôles à l’aide de l’ensemble de lignes de vue de gestion dynamique (DMV) TMSCHEMA_ROLE_MEMo ERSHIPS ne retourne aucun résultat en cas d’exécution sur le réplica en lecture seule.
Les rapports qui utilisent une connexion active se connectent toujours au réplica en lecture seule, même si la chaîne de connexion utilise
?readwrite. Toutefois, dans Power BI Desktop, les rapports à connexion active utilisant?readwritese connectent au réplica en lecture-écriture.Les ensembles de lignes de vue de gestion dynamique (DMV) DBSCHEMA_CATALOGS et DISCOVER_XML_METADATA retournent des informations sur les réplicas en lecture-écriture en cas d’utilisation de
?readonlydans la chaîne de connexion.SQL Server Profiler ne fonctionne pas avec la chaîne de connexion
?readonly.Ces opérations déclenchent la synchronisation automatique même lorsque celle-ci est désactivée (
AutoSync=Off).- Migration d’un espace de travail d’une capacité vers une autre
- Changement (ou rotation) de la version de la clé de chiffrement utilisée pour Bring Your Own Key (BYOK)
- Déplacement de l’espace de travail d’un modèle sémantique d’une capacité qui n’utilise pas BYOK vers une capacité qui utilise BYOK
- Déplacement de l’espace de travail d’un modèle sémantique d’une capacité qui utilise BYOK vers une capacité qui n’utilise pas BYOK
- Restauration d’un modèle sémantique à l’aide du point de terminaison XMLA public
La désactivation du format de stockage de modèle sémantique volumineux désactive le scale-out et entraîne la perte de toutes les informations de synchronisation.