Configurer des connecteurs Microsoft Graph dans le Centre d’administration Microsoft 365
Cet article décrit les étapes de configuration d’un connecteur Microsoft Graph dans le Centre d’administration Microsoft 365. Le processus d’installation est simplifié, avec des entrées minimales qui simplifient la création de la connexion. Toutefois, vous pouvez opter pour une configuration personnalisée pour affiner des paramètres spécifiques.
Remarque
Le processus d’installation est similaire pour tous les connecteurs Microsoft Graph, mais il n’est pas exactement le même. En plus de lire cet article, veillez à lire les informations spécifiques au connecteur pour votre source de données.
Remarque
Vous pouvez ajouter un maximum de trente (30) connexions Microsoft Graph à chaque locataire.
Conseil
Enquête sur les produits
Pour nous aider à comprendre vos besoins liés à la connexion d’un plus grand nombre de sources de données à Copilot ou Microsoft Search, nous vous demandons de prendre quelques minutes pour remplir ce formulaire d’enquête. Sur la base des résultats de l’enquête, Microsoft créera des connecteurs pour les sources de données les plus demandées.
Configuration requise
Avant de commencer, vérifiez les points suivants :
- accès Administration : vous devez disposer de l’un des rôles suivants dans le Centre d’administration Microsoft 365 pour configurer un connecteur Graph : administrateur général, administrateur de recherche ou administrateur Copilot.
- Informations d’identification de la source de données : Collectez les informations d’identification et les autorisations nécessaires pour la source de données que vous souhaitez connecter.
- Compte de service (le cas échéant) : Si votre source de données nécessite un compte de service, vérifiez qu’elle dispose des rôles ou autorisations nécessaires.
Étape 1 : Ajouter un connecteur Microsoft Graph
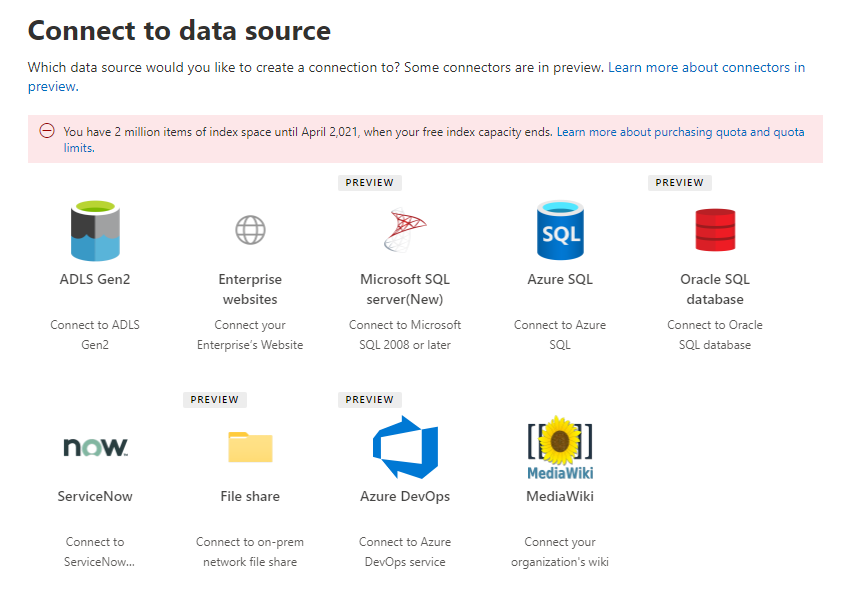
Effectuez les étapes suivantes pour configurer l’un des connecteurs Microsoft Graph (ou cliquez ici pour accéder directement au catalogue de connecteurs) :
Ouvrez le Centre Administration Microsoft 365 :
- Connectez-vous au Centre d’administration Microsoft 365.
Accédez à Paramètres :
- Dans le volet de navigation gauche, sélectionnez Paramètres.
- Cliquez sur Rechercher & intelligence.
Ajouter une nouvelle source de données :
- Accédez à l’onglet Sources de données.
- Cliquez sur +Ajouter.
- Dans la liste des connecteurs disponibles, sélectionnez la source de données que vous souhaitez connecter (par exemple, ServiceNow Knowledge ou Salesforce).
Étape 2 : Entrer les détails de connexion de base

Nom complet :
- Pour aider les utilisateurs à reconnaître la source dans Copilot et les résultats de la recherche, entrez un nom pour identifier le connecteur.
- Un nom par défaut est fourni, mais vous pouvez le personnaliser en fonction des besoins de votre organization.
URL de la source de données :
- Indiquez l’URL de votre source de données. Par exemple, si vous vous connectez à ServiceNow, l’URL peut ressembler
https://your-organization-name.service-now.comà .
- Indiquez l’URL de votre source de données. Par exemple, si vous vous connectez à ServiceNow, l’URL peut ressembler
Type d’authentification :
- Choisissez une méthode d’authentification pour accéder à la source de données.
Déploiement auprès d’un public limité
- Au départ, vous pouvez déployer le connecteur sur un sous-ensemble d’utilisateurs à des fins de validation dans Copilot et d’autres surfaces de recherche. Cette fonctionnalité vous permet de tester l’intégration avant un déploiement plus large.
Remarque
Pour la plupart des connecteurs, les paramètres par défaut sont optimisés pour la source de données. Ces paramètres incluent les autorisations d’accès, le schéma et la fréquence de synchronisation. Si vous souhaitez modifier l’un de ces paramètres, vous devez choisir l’option « Installation personnalisée ».
Étape 3 : Créer la connexion
- Cliquez sur Créer pour configurer la connexion. Le connecteur commence à indexer le contenu de votre source de données à l’aide des paramètres par défaut.

Une fois la connexion créée, vous pouvez ajouter une description de la connexion dans l’écran de réussite. Pour aider Copilot à améliorer les résultats de connexion pour les utilisateurs, la description doit répondre brièvement aux questions suivantes :
- Quel type de contenu cette connexion a-t-elle ?
- Comment les utilisateurs font-ils référence à cette source de contenu dans leur organisation respective ?
- Quelle partie du flux de travail les utilisateurs font-ils référence à ce contenu dans leur travail quotidien ?
- Quelles sont les caractéristiques du contenu ?
Pour plus d’informations, consultez l’article Amélioration de la découverte Microsoft Copilot avec le contenu du connecteur Graph.
Configuration personnalisée (facultatif)
Les administrateurs qui souhaitent davantage de contrôle sur la configuration peuvent choisir l’option Configuration personnalisée . Cette option permet d’accéder à trois onglets pour les paramètres détaillés : Utilisateurs, Contenu et Synchronisation.
Utilisateurs

Autorisations d’accès :
- Choisissez si les données indexées sont visibles pour :
- Tous les organization.
- Uniquement les personnes ayant accès au contenu dans la source de données.
- Choisissez si les données indexées sont visibles pour :
Mapper les identités :
- Par défaut, les utilisateurs sont mappés en vérifiant si leur adresse e-mail dans la source de données correspond à un
UserPrincipalNameouMaildans Microsoft Entra ID. - Si cette valeur par défaut ne fonctionne pas pour votre organization, fournissez une formule de mappage personnalisée.
- Par défaut, les utilisateurs sont mappés en vérifiant si leur adresse e-mail dans la source de données correspond à un
Contenu

Gérer les propriétés :
- Configurez les propriétés de la source de données, par exemple en les rendant consultables, interrogeables ou refinisables.
- Affectez des étiquettes sémantiques et des alias pour améliorer la pertinence de la recherche.
Pour plus d’informations sur La gestion des propriétés, consultez ci-dessous.
Synchronisation

Intervalles d’actualisation :
Configurez la fréquence des synchronisations de données entre la source de données et l’index du connecteur Graph.
- Analyse complète : Synchronise toutes les données à des intervalles planifiés.
- Analyse incrémentielle : Mises à jour uniquement les données modifiées ou nouvelles.
Ajustez les paramètres de synchronisation par défaut en fonction des besoins de votre organization.
Pour plus d’informations sur les paramètres de synchronisation, consultez ci-dessous.
Plus de ressources
Instructions pour « gérer les propriétés »
Content, propriété
Nous vous recommandons de sélectionner une propriété Content dans le menu déroulant des options, ou de conserver la valeur par défaut si elle est présente. Cette propriété est utilisée pour l’indexation de texte intégral du contenu, la génération d’extraits de page de résultats de recherche, la participation au cluster de résultats , la détection de langue, la prise en charge html/texte, le classement et la pertinence et la formulation de requêtes.
Si vous sélectionnez une propriété de contenu, vous avez la possibilité d’utiliser la propriété générée par le système ResultSnippet lorsque vous créez votre type de résultat. Cette propriété sert d’espace réservé pour les extraits de code dynamiques générés à partir de la propriété de contenu au moment de la requête. Si vous utilisez cette propriété dans votre type de résultat, les extraits de code sont générés dans vos résultats de recherche.
Alias pour les propriétés sources
Vous pouvez ajouter des alias à vos propriétés sous la colonne « Alias ». Les alias sont des noms conviviaux pour vos propriétés. Ils sont utilisés dans les requêtes et dans la création de filtres. Ils sont également utilisés pour normaliser les propriétés sources de plusieurs connexions de sorte qu’elles aient le même nom. De cette façon, vous pouvez créer un seul filtre pour un vertical avec plusieurs connexions. Pour plus d’informations, consultez Personnaliser la page des résultats de la recherche.
Étiquettes sémantiques pour les propriétés sources
Vous pouvez affecter des étiquettes sémantiques à vos propriétés sources. Les étiquettes sont des balises bien connues fournies par Microsoft qui fournissent une signification sémantique. Ils permettent à Microsoft d’intégrer vos données de connecteur dans des expériences Microsoft 365 telles que Copilot, la recherche améliorée, les cartes de personnes, la découverte intelligente, etc.
Le tableau suivant répertorie les étiquettes actuellement prises en charge et leurs descriptions.
| Étiquette | Description |
|---|---|
| title | Titre de l’élément que vous souhaitez afficher dans la recherche et d’autres expériences |
| url | URL cible de l’élément dans le système source |
| Créé par | Nom de la personne qui a créé l’élément |
| Auteur de la dernière modification | Nom de la personne qui a modifié l’élément le plus récemment |
| Authors | Nom des personnes qui ont participé/collaboré sur l’élément |
| Date et heure de création | Heure de création de l’élément |
| Date et heure de la dernière modification | Heure à laquelle l’élément a été modifié le plus récemment |
| Nom de fichier | Nom de l’élément de fichier |
| Extension de fichier | Type d’élément de fichier tel que pdf ou doc |
Les propriétés de cette page sont présélectionnés en fonction de votre source de données, mais vous pouvez modifier cette sélection s’il existe une autre propriété mieux adaptée à une étiquette particulière.
Le titre de l’étiquette est l’étiquette la plus importante. Nous vous recommandons vivement d’affecter une propriété à cette étiquette pour que votre connexion participe à l’expérience de cluster de résultats.
Le mappage incorrect des étiquettes entraîne une détérioration de l’expérience de recherche. Il est possible que certaines étiquettes n’aient pas de propriété qui leur soit affectée.
Attributs de schéma de recherche
Remarque
Les propriétés de type de données « int » ne peuvent pas être affinées, même si elles sont marquées comme pouvant être définies comme pouvant être définies.
Vous pouvez définir les attributs du schéma de recherche pour contrôler la fonctionnalité de recherche de chaque propriété source. Un schéma de recherche permet de déterminer les résultats affichés sur la page des résultats de la recherche et les informations que les utilisateurs finaux peuvent afficher et accéder.
Les attributs de schéma de recherche incluent des options pour Interroger, Rechercher, Récupérer et Affiner. Le tableau suivant répertorie chacun des attributs pris en charge par les connecteurs Microsoft Graph et explique leurs fonctions.
| Attribut de schéma de recherche | Fonction | Exemple |
|---|---|---|
| RECHERCHER | Rend le contenu textuel d’une propriété pouvant faire l’objet d’une recherche. Le contenu de la propriété est inclus dans l’index de recherche en texte intégral. | Si la propriété a la valeur title, une requête pour Enterprise retourne des réponses qui contiennent le mot Entreprise dans n’importe quel texte ou titre. |
| REQUÊTE | Recherche par requête une correspondance pour une propriété particulière. Le nom de la propriété peut ensuite être spécifié dans la requête par programmation ou textuellement. | Si la propriété Title peut être interrogée, la requête Title : Enterprise est prise en charge. |
| RÉCUPÉRER | Seules les propriétés récupérables peuvent être utilisées dans le type de résultat et affichées dans le résultat de recherche. | |
| RAFFINER | L’option d’affinement peut être utilisée dans la page des résultats de recherche Microsoft. | Les utilisateurs de votre organization peuvent filtrer par URL dans la page des résultats de la recherche si la propriété d’affinement est marquée pendant la configuration de la connexion. |
Pour tous les connecteurs à l’exception du connecteur de partage de fichiers, les types personnalisés doivent être définis manuellement. Pour activer les fonctionnalités de recherche pour chaque champ, vous avez besoin d’un schéma de recherche mappé à une liste de propriétés. La configuration de la connexion assistant sélectionne automatiquement un schéma de recherche en fonction de l’ensemble des propriétés sources que vous choisissez. Vous pouvez modifier ce schéma en sélectionnant les zones case activée pour chaque propriété et attribut dans la page du schéma de recherche.

Restrictions et recommandations pour les paramètres de schéma de recherche
La propriété content ne peut faire l’objet d’une recherche que. Une fois que vous l’avez sélectionnée dans la liste déroulante, cette propriété ne peut pas être utilisée avec les options récupérer ou interroger.
Des problèmes de performances importants se produisent lorsque les résultats de la recherche s’affichent avec la propriété content . Par exemple, le champ Contenu texte d’un article de la base de connaissances ServiceNow est un exemple.
Seules les propriétés marquées comme récupérables sont affichées dans les résultats de la recherche et peuvent être utilisées pour créer des types de résultats modernes (MRT).
Seules les propriétés de chaîne peuvent être marquées comme pouvant faire l’objet d’une recherche.
Remarque
Pour mettre à jour le schéma après avoir créé une connexion, reportez-vous à l’article Gérer le schéma de recherche .
Recommandations pour les paramètres de synchronisation
L’intervalle d’actualisation détermine la fréquence à laquelle vos données sont synchronisées entre la source de données et Recherche Microsoft. Chaque type de source de données a un ensemble différent de planifications d’actualisation optimales en fonction de la fréquence à laquelle les données sont modifiées et du type de modifications.
Il existe deux types d’intervalles d’actualisation : Actualisation complète et Actualisation incrémentielle, mais les actualisations incrémentielles ne sont pas disponibles pour certaines sources de données.
Avec une actualisation complète, le moteur de recherche traite et indexe les éléments qui ont changé dans la source de contenu, indépendamment des analyses précédentes. Une actualisation complète fonctionne mieux pour ces situations :
- Détection des suppressions de données.
- L’actualisation incrémentielle a détecté des erreurs et a échoué.
- Les listes de contrôle d’accès (Access Control Listes) ont été modifiées.
- Les règles d’analyse ont été modifiées.
- Le schéma de la connexion a été mis à jour.
Avec une actualisation incrémentielle, le moteur de recherche peut traiter et indexer uniquement les éléments qui ont été créés ou modifiés depuis la dernière analyse réussie. Par conséquent, toutes les données de la source de contenu ne sont pas réindexées. Les actualisations incrémentielles fonctionnent mieux pour détecter le contenu, les métadonnées et d’autres mises à jour.
Remarque
Les analyses incrémentielles ne prennent actuellement pas en charge le traitement des mises à jour des autorisations.
Les actualisations incrémentielles sont plus rapides que les actualisations complètes, car les éléments inchangés ne sont pas traités. Toutefois, si vous choisissez d’exécuter des actualisations incrémentielles, vous devez toujours exécuter des actualisations complètes régulièrement pour maintenir une synchronisation correcte des données entre la source de contenu et l’index de recherche.
Planification de l’analyse
Vous pouvez configurer des analyses complètes et incrémentielles en fonction des options de planification avancées présentes dans la page Paramètres d’actualisation. Certains connecteurs ne prennent pas en charge les analyses incrémentielles et l’option de configuration des analyses incrémentielles n’est pas disponible pour ces connecteurs. Pour d’autres, l’analyse incrémentielle est une analyse facultative et est activée par défaut. Une planification d’analyse est sélectionnée par défaut en fonction du type de connecteur. Ce paramètre par défaut peut être modifié lors de la création de la connexion ou modifié après la publication d’une connexion à partir du flux « Modifier » d’une connexion. Vous pouvez choisir parmi ces champs :
- Périodicité : vous pouvez choisir d’exécuter les analyses chaque jour, semaine, 2e semaine ou 4e semaine.
- Jour(s) : cette option est activée lorsque vous choisissez d’exécuter des analyses uniquement sur des jours spécifiques de la semaine.
- Exécuter une fois par jour case activée box vous permet de choisir l’heure de début de l’analyse dans une journée. Si cette option n’est pas sélectionnée, les analyses se répètent par défaut dans un jour. Vous pouvez choisir l’intervalle de répétition dans la liste déroulante.
- Fréquence : sélectionnez cette option si vous souhaitez répéter les analyses dans un jour après certains intervalles de temps. La plus petite fréquence de répétition est de 15 minutes, et la plus grande est de 12 heures.
- Heure de début : sélectionnez l’heure à laquelle vous souhaitez que l’analyse démarre.
- Réinitialiser : cette option réinitialise la planification par défaut du connecteur.
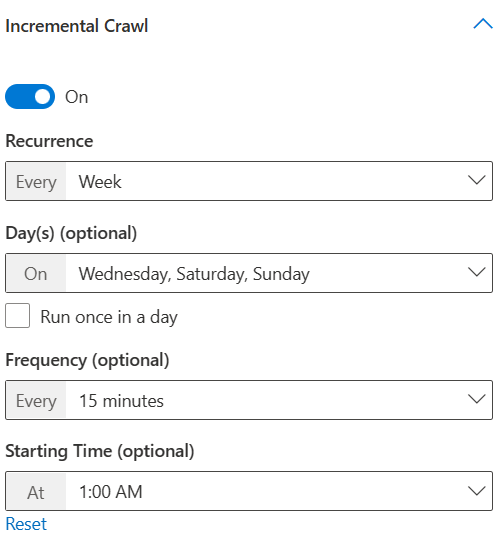
Voici certains points à noter lors de la configuration de la planification de l’analyse :
- Si vous laissez l’un des champs vides ou non sélectionnés, les connecteurs Graph sélectionnent le meilleur moment pour démarrer une analyse. Par exemple, si vous choisissez une périodicité d’analyse comme « Jour » et que vous ne sélectionnez pas l’heure de début, les connecteurs Graph choisissent l’heure en fonction de votre dernière analyse pour démarrer la nouvelle analyse. Si vous ne souhaitez pas spécifier une heure de début de l’analyse, il est recommandé de laisser le connecteur décider quand démarrer l’analyse.
- Même si l’heure de début est mentionnée, le démarrage de l’analyse peut différer d’une heure. Ce délai peut être dû à des raisons telles que la charge réseau, etc.
- Si l’analyse précédente est dépassée jusqu’à l’heure de la prochaine analyse, nous n’arrêtons pas l’analyse en cours et nous ne mettons pas en file d’attente l’analyse suivante. Une fois l’analyse en cours terminée, nous exécutons l’analyse en file d’attente uniquement si elle est d’un type différent (complet/incrémentiel) de l’analyse précédente. Par exemple, si une analyse incrémentielle dépasse l’analyse complète suivante, nous ne suspendons pas l’analyse incrémentielle et nous ne mettons pas en file d’attente l’analyse complète. Une fois l’analyse incrémentielle terminée, étant donné que l’analyse en file d’attente est de type différent (complète), nous la commençons immédiatement.
Voici quelques-uns des scénarios suivants :
- Exécuter l’analyse incrémentielle quotidiennement après toutes les 15 minutes
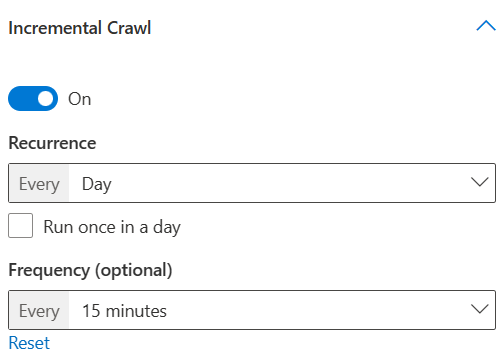
Ici, en cochant la case « Exécuter une fois par jour », vous pouvez choisir l’heure de début pour exécuter l’analyse incrémentielle une seule fois par jour à partir de l’heure spécifiée. Toutefois, le désélectionnement vous permet de choisir la fréquence des répétitions d’analyse dans une journée. Si vous souhaitez que vos données soient actualisées en continu, vous pouvez choisir d’exécuter des analyses incrémentielles fréquemment au cours d’une journée. Toutefois, si le nombre d’éléments dans la source de données est élevé et que les analyses ont tendance à être plus longues, ou si des mises à jour fréquentes ne sont pas nécessaires pour le contenu, vous pouvez choisir l’analyse incrémentielle à exécuter une fois par jour.
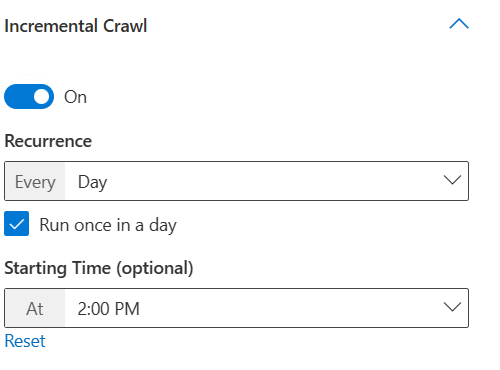
- Exécuter l’analyse incrémentielle chaque semaine le mercredi, le samedi et le dimanche en répétant toutes les 15 minutes et à partir de 1h00
- Exécuter l’analyse complète tous les jours à 1:00

- Exécuter l’analyse complète chaque semaine le vendredi à 20h00

Règles de pare-feu IP
Les règles de pare-feu IP sont configurées pour sécuriser l’accès à votre source de données en autorisant uniquement des adresses IP spécifiques. Dans ce scénario, autorisez l’accès aux plages d’adresses IP du service connecteurs Graph pour autoriser l’accès à votre source de données. Spécifiez les plages d’adresses IP suivantes dans les paramètres de pare-feu de votre plateforme SaaS.
| Région | Microsoft 365 Entreprise | Microsoft 365 Secteur public |
|---|---|---|
| NAM | 52.250.92.252/30, 52.224.250.216/30 | 52.245.230.216/30, 20.141.117.64/30 |
| EUR | 20.54.41.208/30, 51.105.159.88/30 | N/A |
| APC | 52.139.188.212/30, 20.43.146.44/30 | N/A |