Charger des fichiers en tant que source de connaissances
Vous pouvez télécharger vos propres documents pour les utiliser comme source de connaissances au niveau agent, que votre agent utilise ensuite pour générer des réponses avec l’IA générative.
Note
Lorsque vous téléchargez des documents en utilisant cette méthode, les documents sont disponibles pour votre agent à tous les niveaux. Cependant, vous pouvez télécharger des documents dans des nœuds de réponses génératives. Cette autre option vous permet de mieux contrôler la spécification des nœuds de réponses génératives individuels qui ne doivent pas utiliser les documents téléchargés .
Lorsqu’un utilisateur agent pose une question et que le agent n’a pas de rubrique défini à utiliser, le agent génère une réponse à partir de vos documents téléchargés. L’agent répond à la question de l’utilisateur à l’aide de l’IA générative et fournit une réponse dans un style conversationnel.
Les documents chargés sont stockés en toute sécurité dans Dataverse. Le nombre de documents que vous pouvez charger est limité par l’espace de stockage de fichiers disponible pour votre environnement Dataverse.
Pour télécharger des fichiers en tant que source de connaissances, procédez comme suit :
Ouvrez le agent.
Sélectionner Ajoutez des connaissances à partir des pages Présentation ou Connaissances ou des Propriétés d’un nœud de réponses génératives.
Chargez le fichier par glisser-déposer ou en naviguant jusqu’à l’emplacement du fichier.
Ajoutez un nom (par défaut, le nom du fichier est utilisé).
Ajoutez une description. La description doit être aussi détaillée que possible, surtout si l’IA générative est activée, car la description facilite l’orchestration de l’IA .
Sélectionnez Ajouter pour finir d’ajouter la source de connaissances.
Types de document pris en charge
- Word (doc, docx)
- Excel (xls, xlsx)
- PowerPoint (ppt, pptx)
- PDF (pdf)
- Texte (.txt, .md, .log)
- HTML (html, htm)
- CSV (csv)
- XML (xml)
- OpenDocument (odt, ods, odp)
- EPUB (epub)
- Rich Text Format (rtf)
- Apple iWork (pages, clé, nombres)
- JSON (json)
- YAML (yml, yaml)
- LaTeX (tex)
Prise en charge des images annotées (version préliminaire)
Les images annotées intégrées dans les fichiers PDF sont également prises en charge. Annotation, également appelé texte alternatif, est une description textuelle de l’image. Pour de meilleurs résultats, fournissez des informations détaillées sur l’image intégrée dans le texte alternatif.
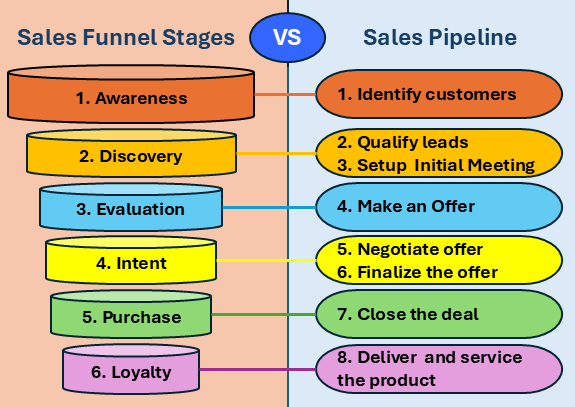
Les utilisateurs peuvent poser des questions et recevoir des réponses à partir des informations contenues dans les images annotées. Par exemple, l’image suivante qui a été intégrée dans un fichier PDF fournit des informations sur un entonnoir de vente et les étapes d’un pipeline de vente. Les utilisateurs du agent contenant cette image intégrée comme source de connaissances peuvent poser des questions telles que : "Quelles sont les étapes d’un entonnoir de vente ? » Le agent peut ensuite renvoyer une réponse basée sur les informations contenues dans l’image annotée.
Important
- Les images annotées dans les fichiers PDF ne sont prises en charge que dans les fichiers nouvellement téléchargés. Si vous avez déjà téléchargé un fichier PDF annoté, vous devez supprimer le fichier existant et le télécharger à nouveau.
- Les images, Vidéo, les exécutables et les fichiers audio ne peuvent pas être utilisés comme documents téléchargés.
- Les images ne sont prises en charge que lorsqu’elles sont intégrées dans des fichiers PDF.
- Les images intégrées ne sont prises en charge qu’en Suisse et aux États-Unis.
- Les icônes ne sont pas prises en charge.
- Les fichiers supérieurs à 512 Mo ne sont pas pris en charge.
- Les fichiers contenant du contenu chiffré, protégés par mot de passe ou contenant des balises confidentielles ne sont pas pris en charge.
- Le nombre maximum de fichiers pouvant être inclus en tant que connaissances dans un agent est de 500 fichiers.