Acheminer des flux de données en fonction du contenu dans les flux d’événements Fabric
Cet article explique comment router des événements en fonction du contenu des Eventstreams Microsoft Fabric.
Vous pouvez maintenant utiliser l’éditeur sans code dans le canevas principal des Eventstreams Fabric pour créer une logique de traitement de flux complexe sans écrire de code. Cette fonctionnalité vous permet de personnaliser, de transformer et de gérer plus facilement vos flux de données. Après avoir défini vos opérations de traitement de flux, vous pouvez envoyer en toute transparence vos flux de données à différentes destinations en fonction du schéma spécifique et des données du flux.
Opérations prises en charge
Voici la liste des opérations prises en charge pour le traitement des données en temps réel :
Agréger : prend en charge les fonctions SUM, AVG, MIN et MAX qui effectuent des calculs sur une colonne de valeurs, en retournant un résultat unique.
Développer : Développez une valeur de tableau et créez une ligne pour chaque valeur dans un tableau.
Filtre : sélectionnez ou filtrez des lignes spécifiques dans le flux de données en fonction d’une condition.
Grouper par : agréger toutes les données d’événement dans une certaine fenêtre de temps, avec la possibilité de regrouper une ou plusieurs colonnes.
Gérer les champs : ajouter, supprimer ou modifier le type de données d’un champ ou d’une colonne de vos flux de données.
Union : connecter deux flux de données ou plus avec des champs partagés du même nom et du même type de données en un seul flux de données. Les champs qui ne correspondent pas sont exclus.
Jointure: combiner des données à partir de deux flux en fonction d’une condition correspondante entre eux.
Destinations prises en charge
Les destinations prises en charge sont les suivantes :
Lakehouse : cette destination vous permet de transformer vos événements en temps réel avant leur ingestion dans votre lakehouse. Les événements en temps réel sont convertis au format Delta Lake, puis stockés dans les tables lakehouse désignées. Cette destination vous aide avec les scénarios d’entrepôt de données.
Eventhouse: cette destination vous permet d’ingérer vos données d’événements en temps réel dans Eventhouse, où vous pouvez utiliser le puissant langage de requête Kusto (KQL) pour interroger et analyser les données. Avec les données dans Eventhouse, vous pouvez obtenir des insights plus approfondis sur vos données d’événement et créer des rapports et tableaux de bord enrichis.
Fabric Activator : cette destination vous permet de connecter directement vos données d’événements en temps réel à un Fabric Activator. Activator est un type d’agent intelligent qui contient toutes les informations nécessaires pour se connecter aux données, surveiller les conditions et effectuer des actions. Lorsque les données atteignent certains seuils ou correspondent à d’autres modèles, Activator effectue automatiquement des actions appropriées, comme l’alerte des utilisateurs ou le lancement de flux de travail Power Automate.
Point de terminaison personnalisé (précédemment application personnalisée) : avec cette destination, vous pouvez facilement acheminer vos événements en temps réel vers une application personnalisée. Cette destination vous permet de connecter vos propres applications à l’Eventstream et de consommer les données d’événement en temps réel. Ceci est utile lorsque vous voulez faire sortir des données en temps réel vers un système externe qui ne fait pas partie de Microsoft Fabric.
Flux : cette destination représente l’Eventstream brut par défaut transformé par une série d’opérations, également appelé flux dérivé. Une fois créé, vous pouvez afficher le flux à partir du hub en temps réel.
L’exemple suivant montre comment trois destinations d’Eventstream Fabric distinctes peuvent servir des fonctions distinctes pour une source de flux de données unique. Un Eventhouse est désigné pour stocker des données brutes, un second Eventhouse consiste à conserver des flux de données filtrés et le Lakehouse est utilisé pour stocker des valeurs agrégées.
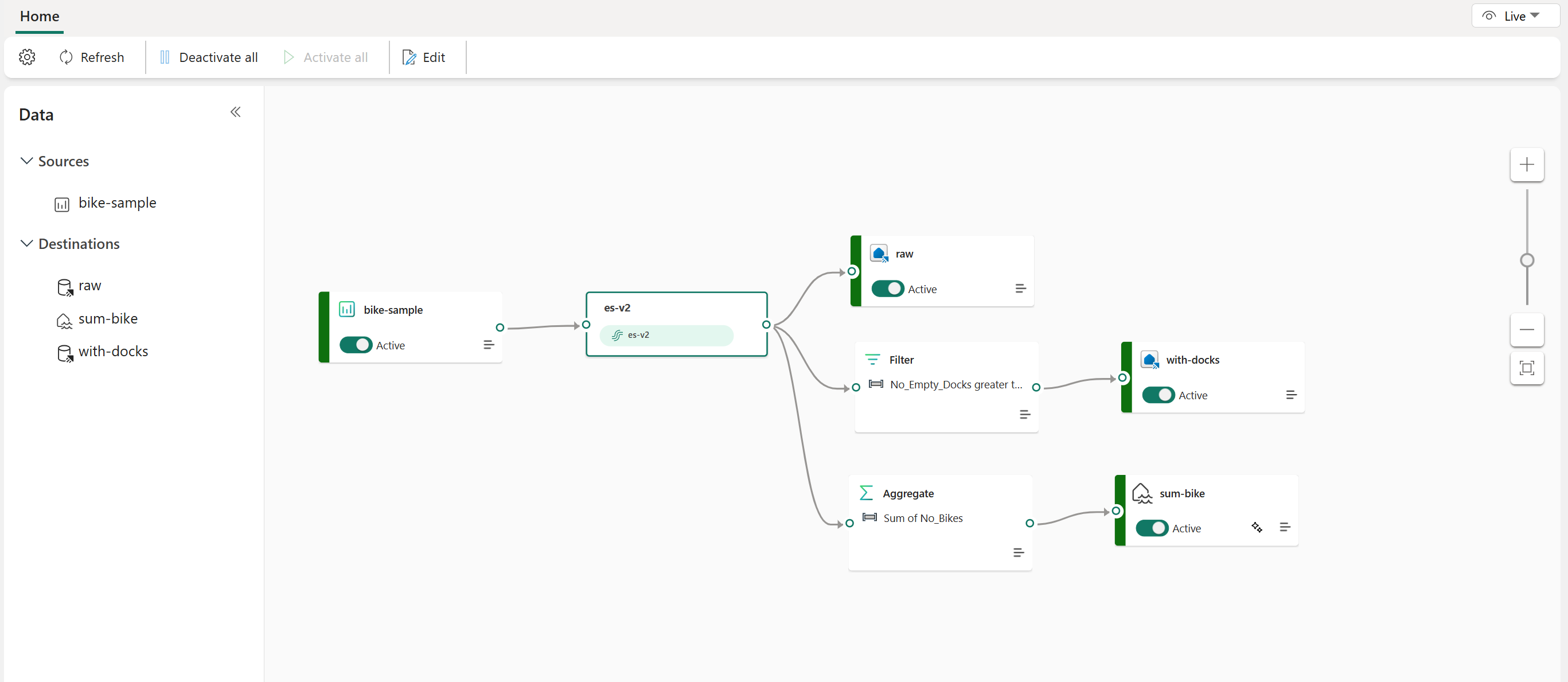
Pour transformer et router votre flux de données en fonction du contenu, suivez les étapes de Modification et publication d’un Eventstream et commencez à concevoir des logiques de traitement de flux pour votre flux de données.