Intégrer Databricks Unity Catalog à OneLake
Ce scénario montre comment intégrer des tables Delta externes de Unity Catalog à OneLake à l’aide de raccourcis. Une fois ce tutoriel terminé, vous pourrez synchroniser automatiquement vos tables Delta externes de Unity Catalog sur un lakehouse Microsoft Fabric.
Prérequis
Avant de vous connecter, vous devez avoir :
- Un espace de travail Fabric.
- Un lakehouse Fabric dans votre espace de travail.
- Tables Delta de Unity Catalog externes créées dans votre espace de travail Azure Databricks.
Configurer votre connexion de stockage Cloud
Tout d’abord, examinez les emplacements de stockage dans Azure Data Lake Storage Gen2 (ADLS Gen2) que vos tables Unity Catalog utilisent. Cette connexion de stockage cloud est utilisée par les raccourcis OneLake. Pour créer une connexion cloud à l’emplacement de stockage de UnityCatalog approprié :
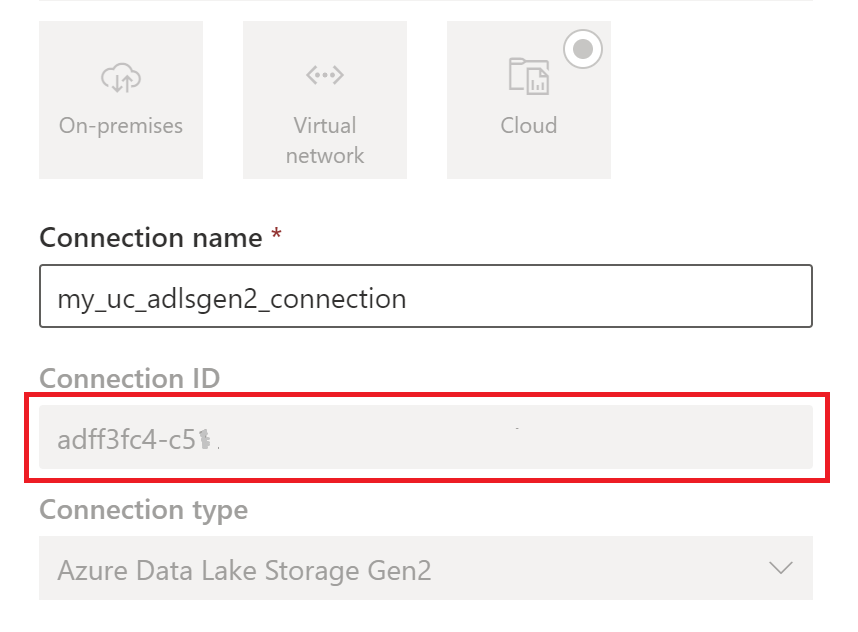
Créez une connexion de stockage cloud utilisée par vos tables Unity Catalog. Découvrez comment configurer une connexion ADLS Gen2.
Une fois que vous avez créé la connexion, obtenez l’ID de connexion en sélectionnant Paramètres
 >Gérer les connexions et les passerelles>Connexions>Paramètres.
>Gérer les connexions et les passerelles>Connexions>Paramètres.
Remarque
L’octroi aux utilisateurs d’un accès direct au niveau du stockage à un emplacement externe dans ADLS Gen2 ne respecte pas les autorisations accordées ou les audits gérés par Unity Catalog. L’accès direct contourne l’audit, la traçabilité et d’autres fonctionnalités de sécurité/surveillance de Unity Catalog, notamment le contrôle d’accès et les autorisations. Vous êtes responsable de la gestion de l’accès direct au stockage via ADLS Gen2 et de vous assurer que les utilisateurs disposent des autorisations appropriées accordées via Fabric. Évitez tous les scénarios accordant un accès en écriture direct au niveau de stockage pour les compartiments stockant des tables managées Databricks. La modification, la suppression ou l’évolution d’objets directement via le stockage qui ont été gérés à l’origine par Unity Catalog peuvent entraîner une altération des données.
Exécuter le bloc-notes
Une fois l’ID de connexion cloud obtenu, intégrez les tables Unity Catalog au lakehouse Fabric comme suit :
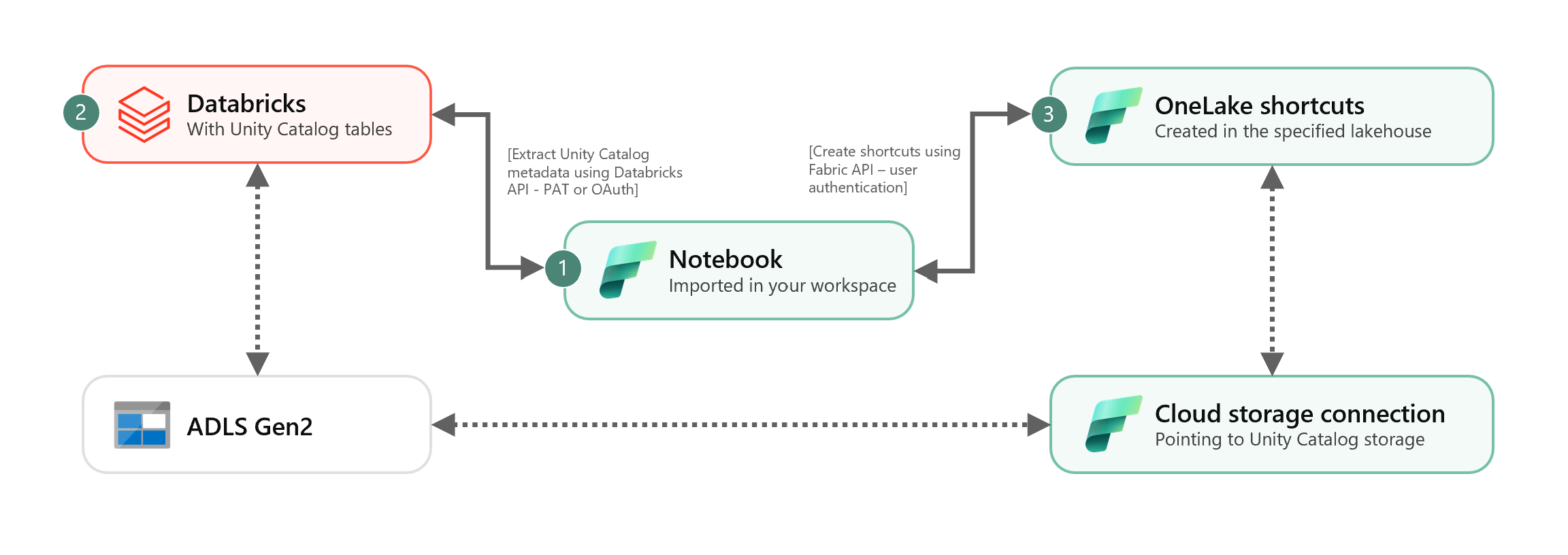
Importez le notebook de synchronisation dans votre espace de travail Fabric. Ce notebook exporte toutes les métadonnées des tables Unity Catalog à partir d’un catalogue et de schémas donnés dans votre metastore.
Configurez les paramètres dans la première cellule du notebook pour intégrer les tables Unity Catalog. L’API Databricks, authentifiée via le jeton PAT, est utilisée pour exporter des tables Unity Catalog. L’extrait de code suivant est utilisé pour configurer les paramètres source (Unity Catalog) et de destination (OneLake). Veillez à les remplacer par vos propres valeurs.
# Databricks workspace dbx_workspace = "<databricks_workspace_url>" dbx_token = "<pat_token>" # Unity Catalog dbx_uc_catalog = "catalog1" dbx_uc_schemas = '["schema1", "schema2"]' # Fabric fab_workspace_id = "<workspace_id>" fab_lakehouse_id = "<lakehouse_id>" fab_shortcut_connection_id = "<connection_id>" # If True, UC table renames and deletes will be considered fab_consider_dbx_uc_table_changes = TrueExécutez toutes les cellules du notebook pour commencer à synchroniser les tables Delta de Unity Catalog vers OneLake à l’aide de raccourcis. Une fois le notebook terminé, les raccourcis vers les tables Delta de Unity Catalog sont disponibles dans le modèle sémantique, le point de terminaison d'analytique SQL et le lakehouse.
Planifier le notebook
Si vous souhaitez exécuter le notebook à intervalles réguliers pour intégrer des tables Delta de Unity Catalog à OneLake sans resynchroniser/réexécuter manuellement, vous pouvez planifier le notebook ou utiliser une activité de notebook dans un pipeline de données dans Fabric Data Factory.
Dans ce dernier scénario, si vous envisagez de transmettre des paramètres à partir du pipeline de données, désignez la première cellule du notebook comme cellule de paramètre bascule et fournissez les paramètres appropriés dans le pipeline.

Autres considérations
- Pour les scénarios de production, nous vous recommandons d’utiliser Databricks OAuth pour l’authentification et Azure Key Vault pour gérer les secrets. Par exemple, vous pouvez utiliser les utilitaires d’informations d’identification MSSparkUtils pour accéder aux secrets dans Key Vault.
- Le notebook fonctionne avec les tables Delta externes de Unity Catalog. Si vous utilisez plusieurs emplacements de stockage cloud pour vos tables Unity Catalog, c’est-à-dire plusieurs ADLS Gen2, il est recommandé d’exécuter le notebook séparément pour chaque connexion cloud.
- Les tables Delta gérées par Unity Catalog, les vues, les vues matérialisées, les tables de diffusion en continu et les tables non Delta ne sont pas prises en charge.
- Les modifications apportées aux schémas de table Unity Catalog, tels que les colonnes d’ajout/suppression, sont répercutées automatiquement dans les raccourcis. Toutefois, certaines mises à jour telles que le renommage et la suppression d’une table de Unity Catalog nécessitent une resynchronisation/réexécution d’un notebook. Ceci est considéré par le paramètre
fab_consider_dbx_uc_table_changes. - Pour les scénarios d’écriture, l’utilisation de la même couche de stockage sur différents moteurs de calcul peut avoir des conséquences inattendues. Assurez-vous de bien comprendre les implications de l’utilisation de différents moteurs de calcul Apache Spark et de différentes versions du runtime.