Ingérer des exemples de données et créer des objets et des données supplémentaires
S’applique à : ✅base de données SQL dans Microsoft Fabric
Vous pouvez entrer des données dans la base de données SQL dans Fabric à l’aide d’instructions Transact-SQL (T-SQL). Vous pouvez également importer des données dans votre base de données à l’aide d’autres composants Microsoft Fabric, tels que la fonctionnalité Dataflow Gen2 ou les pipelines de données. Pour le développement, vous pouvez vous connecter à n’importe quel outil qui prend en charge le protocole TDS (Tabular Data Stream), tel que Visual Studio Code ou SQL Server Management Studio.
Pour débuter cette section, vous pouvez utiliser les exemples de données fournis SalesLT comme point de départ.
Prérequis
- Terminez toutes les étapes précédentes de ce didacticiel.
Ouvrir l’éditeur de requête dans le portail Fabric
Ouvrez la base de données SQL dans la base de données Fabric que vous avez créée à la dernière étape du tutoriel. Vous pouvez le trouver dans la barre de navigation du portail Fabric ou en le trouvant dans votre espace de travail pour ce didacticiel.
Sélectionnez le bouton Exemple de données. Remplir votre base de données du didacticiel avec les exemples de données SalesLT prend un peu de temps.
Vérifiez la zone Notifications pour vous assurer que l’importation est terminée avant de continuer.
Notifications vous montre lorsque l’importation des exemples de données est terminée. Votre base de données SQL dans Fabric contient désormais le schéma
SalesLTainsi que les tableaux associés.

Utilisez la base de données SQL dans l’éditeur SQL
L’éditeur SQL web pour la base de données SQL dans Fabric fournit une interface d’explorateur d’objets et d’exécution de requêtes de base. Une nouvelle base de données SQL dans Fabric s’ouvre automatiquement dans l’éditeur web SQL et une base de données existante peut être ouverte dans l’éditeur web SQL en la sélectionnant dans le portail Fabric.
Il existe plusieurs éléments dans la barre d’outils de l’éditeur web, notamment l’actualisation, les paramètres, une opération de requête et la possibilité d’obtenir des informations sur les performances. Vous allez utiliser ces fonctionnalités tout au long de ce tutoriel.
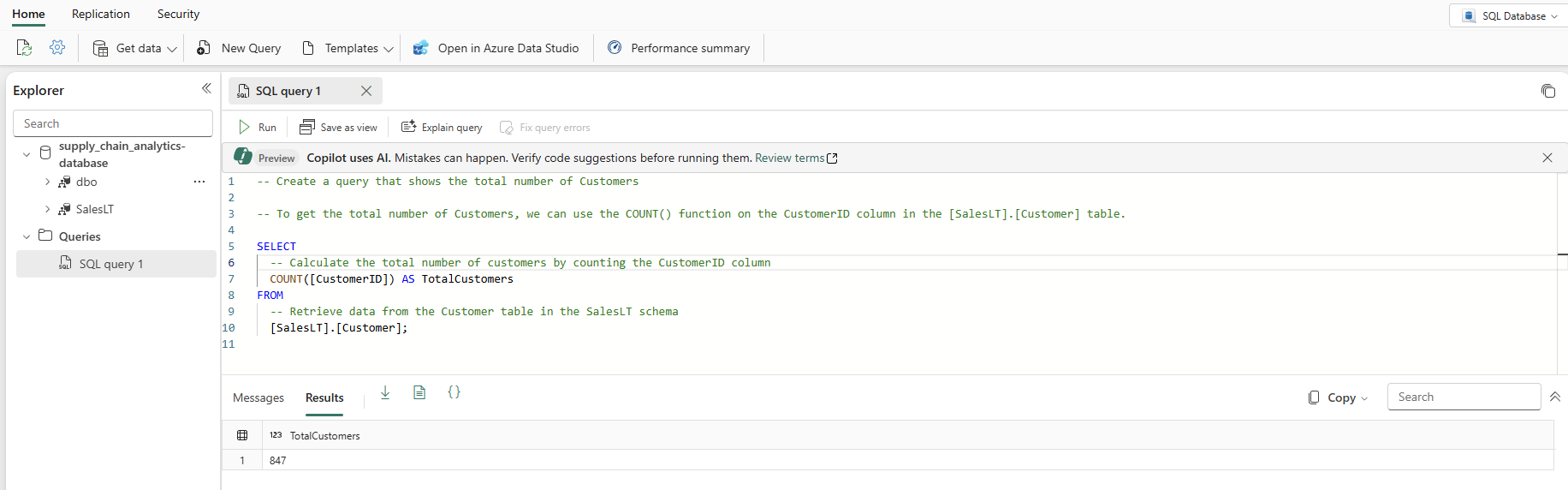
Dans la vue de votre base de données, commencez par sélectionner Nouvelle Requête dans la barre d’icônes. Cela affiche un éditeur de requête, qui possède la fonctionnalité d’IA Copilot pour vous aider à écrire votre code. Copilot pour la base de données SQL peut vous aider à terminer une requête ou à en créer une.
Tapez un commentaire T-SQL en haut de la requête, tel que
-- Create a query that shows the total number of customerset appuyez sur Entrée. Vous recevez un résultat similaire à celui-ci :
Appuyez sur la touche « Tab » pour implémenter le code suggéré :
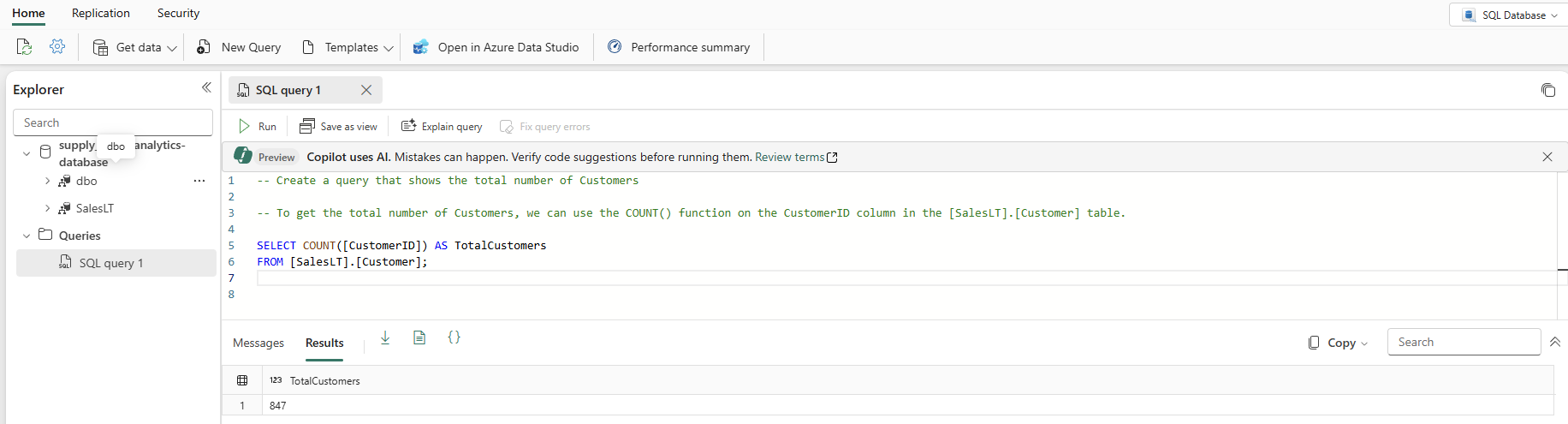
Sélectionnez Expliquer la requête dans la barre d’icônes de l’éditeur de requête pour insérer des commentaires dans votre code pour expliquer chaque étape principale :
Remarque
Copilot essaie de déterminer votre intention mais vous devez toujours vérifier le code qu’il crée avant de l’exécuter et toujours tester dans un environnement différent que celui de la production.



Dans un environnement de production, vous pouvez avoir des données dans un format déjà normalisé pour les opérations d’application quotidiennes alors que vous les avez simulées ici avec les données SalesLT . Lorsque vous créez une requête, elle est enregistrée automatiquement dans l’élément Requêtes dans le volet de l’Explorateur. Vous devriez voir votre requête en tant que « Requête SQL 1 ». Par défaut, le système numérote les requêtes comme « Requête SQL 1 » mais vous pouvez sélectionner les points de suspension à côté du nom de la requête pour dupliquer, renommer ou supprimer la requête.
INsérer des données à l’aide de Transact-SQL
Vous avez été invité à créer de nouveaux objets pour suivre la chaîne d’approvisionnement de l’organisation. Vous devez donc ajouter un ensemble d’objets pour votre application. Dans cet exemple, vous allez créer un objet unique dans un nouveau schéma. Vous pouvez ajouter d’autres tableaux pour normaliser l’application entièrement. Vous pouvez ajouter plus de données comme plusieurs composants par produit, avoir plus d’informations sur les fournisseurs, etc. Plus loin dans ce tutoriel, vous verrez comment les données sont mises en miroir sur le point de terminaison d’analyse SQL ainsi que comment vous pouvez interroger les données avec une API GraphQL pour s’ajuster automatiquement au fil des objets ajoutés ou modifiés.
Les étapes suivantes utilisent un script T-SQL pour créer un schéma, un tableau et des données pour les données simulées pour l’analyse de la chaîne logistique.
Sélectionnez le bouton Nouvelle requête dans la barre d’outils de la base de données SQL pour créer une requête.
Collez le script suivant dans la zone Requête et sélectionnez Exécuter pour l’exécuter. Le script T-SQL suivant :
- Crée un schéma nommé
SupplyChain. - Crée un tableau nommé
SupplyChain.Warehouse. - Remplit le tableau
SupplyChain.Warehouseavec des données de produit créées de manière aléatoire à partir deSalesLT.Product.
/* Create the Tutorial Schema called SupplyChain for all tutorial objects */ CREATE SCHEMA SupplyChain; GO /* Create a Warehouse table in the Tutorial Schema NOTE: This table is just a set of INT's as Keys, tertiary tables will be added later */ CREATE TABLE SupplyChain.Warehouse ( ProductID INT PRIMARY KEY -- ProductID to link to Products and Sales tables , ComponentID INT -- Component Identifier, for this tutorial we assume one per product, would normalize into more tables , SupplierID INT -- Supplier Identifier, would normalize into more tables , SupplierLocationID INT -- Supplier Location Identifier, would normalize into more tables , QuantityOnHand INT); -- Current amount of components in warehouse GO /* Insert data from the Products table into the Warehouse table. Generate other data for this tutorial */ INSERT INTO SupplyChain.Warehouse (ProductID, ComponentID, SupplierID, SupplierLocationID, QuantityOnHand) SELECT p.ProductID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS ComponentID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS SupplierID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS SupplierLocationID, ABS(CHECKSUM(NEWID())) % 100 + 1 AS QuantityOnHand FROM [SalesLT].[Product] AS p; GOVotre base de données SQL dans la base de données Fabric inclut désormais des informations sur l’entrepôt. Vous allez utiliser ces données lors d’une étape plus loin dans ce didacticiel.
- Crée un schéma nommé
Vous pouvez sélectionner ces tableaux dans le volet de l’Explorateur pour afficher les données du tableau. Il n’y a pas besoin d’écrire une requête pour les voir.
Insérer des données à l’aide d’un pipeline Microsoft Fabric
Une autre façon d’importer des données et d’exporter des données dans et hors de votre base de données SQL dans Fabric consiste à utiliser un pipeline de données Microsoft Fabric. Les pipelines de données offrent une alternative à l’utilisation des commandes, au lieu d’utiliser une interface graphique utilisateur. Un pipeline de données constitue un regroupement logique d’activités qui exécutent ensemble une tâche d’ingestion des données. Les pipelines vous permettent de gérer les activités d’extraction, de transformation et de chargement (ETL) au lieu de les gérer individuellement.
Microsoft Fabric Pipelines peut contenir un flux de données. Dataflow Gen2 utilise une interface Power Query qui vous permet d’effectuer des transformations et d’autres opérations sur les données. Vous utiliserez cette interface pour importer des données à partir de l’entreprise Northwind Traders avec laquelle Contoso collabore. Ils utilisent actuellement les mêmes fournisseurs. Vous allez donc importer leurs données et afficher les noms de ces fournisseurs à l’aide d’une vue que vous allez créer dans une autre étape de ce tutoriel.
Pour commencer, ouvrez la vue de la base de données SQL de l’exemple de base de données dans le portail Fabric, si ce n’est pas déjà fait.
Sélectionnez le bouton Obtenir des données dans la barre de menus.
Sélectionnez Nouveau Dataflow Gen2.
Dans la vue Power Query, sélectionnez le bouton Obtenir des données. Cela commence un processus guidé au lieu de passer à une zone de données particulière.
Dans la zone de recherche de Choisir une source de données, afficher le type odata.
Sélectionnez OData dans les résultats Nouvelles sources.
Dans la zone de texte URL de la vue Se connecter à la source de données, tapez le texte :
https://services.odata.org/v4/northwind/northwind.svc/pour le flux Open Data de l’exemple de base de donnéesNorthwind. Sélectionnez le bouton Suivant pour continuer.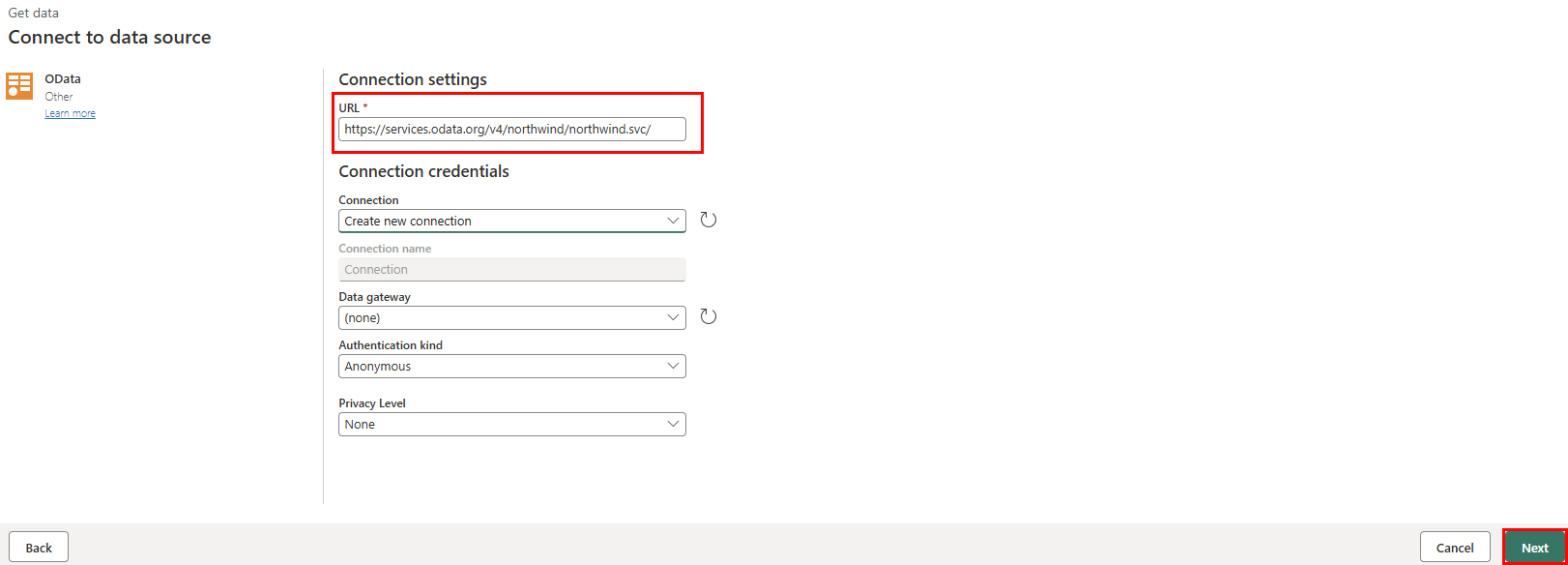
Faites défiler vers le bas jusqu’au tableau Fournisseurs à partir du flux OData puis cochez la case à côté de celle-ci. Ensuite, cliquez sur le bouton Créer.
Maintenant, sélectionnez le symbole plus + à côté de la section Destination de données des paramètres de requête puis sélectionnez Base de données SQL dans la liste.
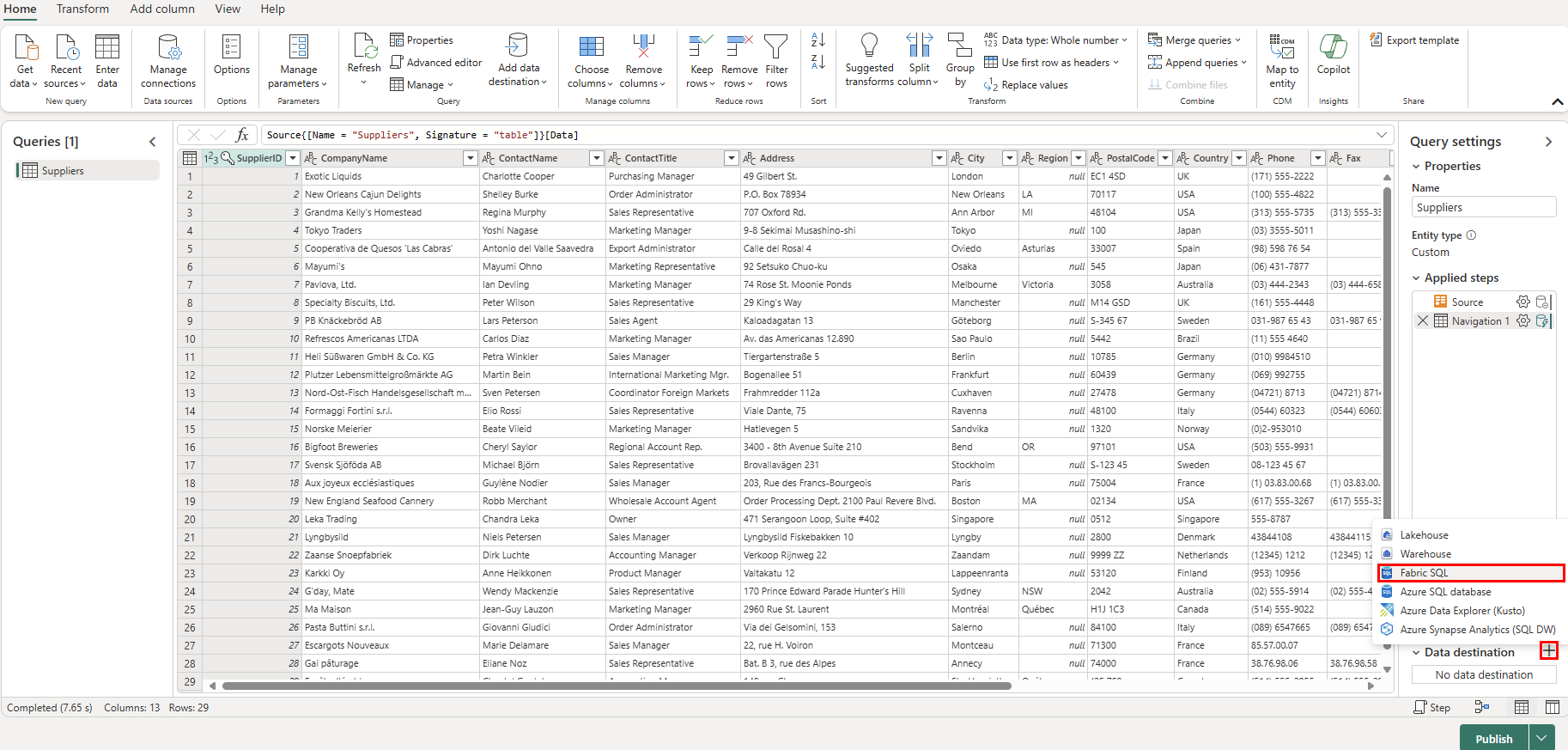
Dans la page Se connecter à la destination des données, vérifiez que le Type d’authentification est défini sur Compte organisationnel. Sélectionnez Se connecter et entrez vos informations d’identification Microsoft Entra ID dans la base de données.
Une fois connecté, sélectionnez le bouton Suivant.
Sélectionnez le nom de l’espace de travail que vous avez créé à la première étape de ce didacticiel dans la section Choisir la cible de destination.
Sélectionnez votre base de données qui s’affiche sous celle-ci. Vérifiez que la case d’option Nouveau tableau est sélectionnée et laissez le nom du tableau en tant que Fournisseurs et sélectionnez le bouton Suivant.
Laissez le curseur Utiliser les paramètres automatiques défini sur la vue Choisir les paramètres de destination puis sélectionnez le bouton Enregistrer les paramètres.
Sélectionnez le bouton Publier pour démarrer le transfert de données.
Vous êtes retourné à votre vue Espace de travail où vous pouvez trouver le nouvel élément du flux de données.

Lorsque la colonne actualisée affiche la date et l’heure actuelles, vous pouvez sélectionner le nom de votre base de données dans l’Explorateur puis étendre le schéma
dbopour afficher le nouveau tableau. (Vous devrez peut-être sélectionner l’icône Actualiser dans la barre d’outils.)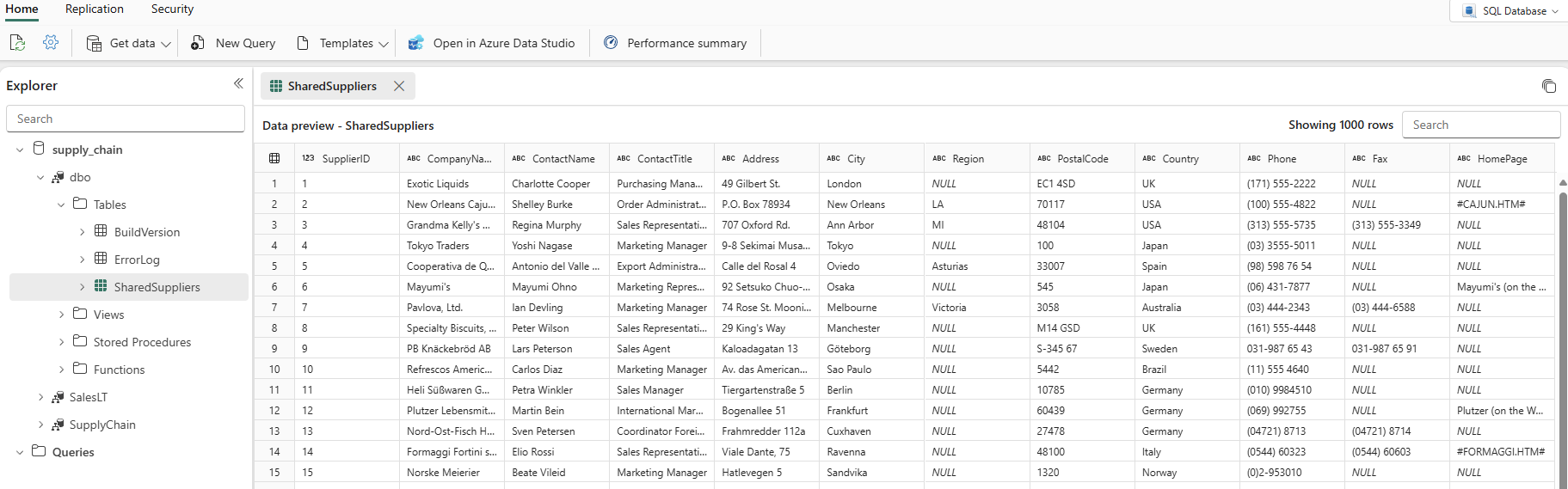




Les données sont désormais ingérées dans votre base de données. Vous pouvez maintenant créer une requête qui combine les données du tableau Suppliers à l’aide de ce tableau tertiaire. Vous ferez cela lors d’une étape ultérieure de noter tutoriel.
Étape suivante
Contenu connexe
- configurer votre connexion de base de données SQL dans Data Factory (préversion)
- vue d’ensemble du connecteur de base de données SQL (préversion)
- Configurer une base de données SQL dans une activité de copie (préversion)