Explorer les données de votre base de données mise en miroir avec des notebooks
Vous pouvez explorer les données répliquées à partir de votre base de données mise en miroir avec des requêtes Spark dans des notebooks.
Les notebooks sont un élément de code puissant pour vous permettre de développer des travaux Apache Spark et des expériences d’apprentissage automatique sur vos données. Vous pouvez utiliser des notebooks dans Fabric Lakehouse pour explorer vos tables mise en miroir.
Prérequis
- Suivez le tutoriel pour créer une base de données mise en miroir à partir de votre base de données source.
- Tutoriel : configurer la base de données mise en miroir Microsoft Fabric pour Azure Cosmos DB (préversion)
- Didacticiel : configurer des bases de données Microsoft Fabric mises en miroir à partir d’Azure Databricks (préversion)
- Didacticiel : configurer des bases de données Microsoft Fabric mise en miroir depuis la base de données Azure SQL Database
- Tutoriel : configurer des bases de données en miroir Microsoft Fabric à partir d'Azure SQL Managed Instance (Préversion)
- Tutoriel : Configurer des bases de données mises en miroir Microsoft Fabric à partir de Snowflake
Créer un raccourci
Vous devez d’abord créer un raccourci à partir de vos tables mise en miroir dans Lakehouse, puis créer des notebooks avec des requêtes Spark dans votre Lakehouse.
Dans le portail Fabric, ouvrez Ingénierie des données.
Si vous n’avez pas encore créé de Lakehouse, sélectionnez Lakehouse et créez un lakehouse en lui donnant un nom.
Sélectionnez Obtenir des données ->Nouveau raccourci.
Sélectionnez OneLake Microsoft.
Vous pouvez voir toutes vos bases de données mise en miroir dans l’espace de travail Fabric.
Sélectionnez la base de données mise en miroir que vous souhaitez ajouter à votre Lakehouse en tant que raccourci.
Sélectionnez les tables souhaitées dans la base de données mise en miroir.
Sélectionnez Suivant, puis Créer.
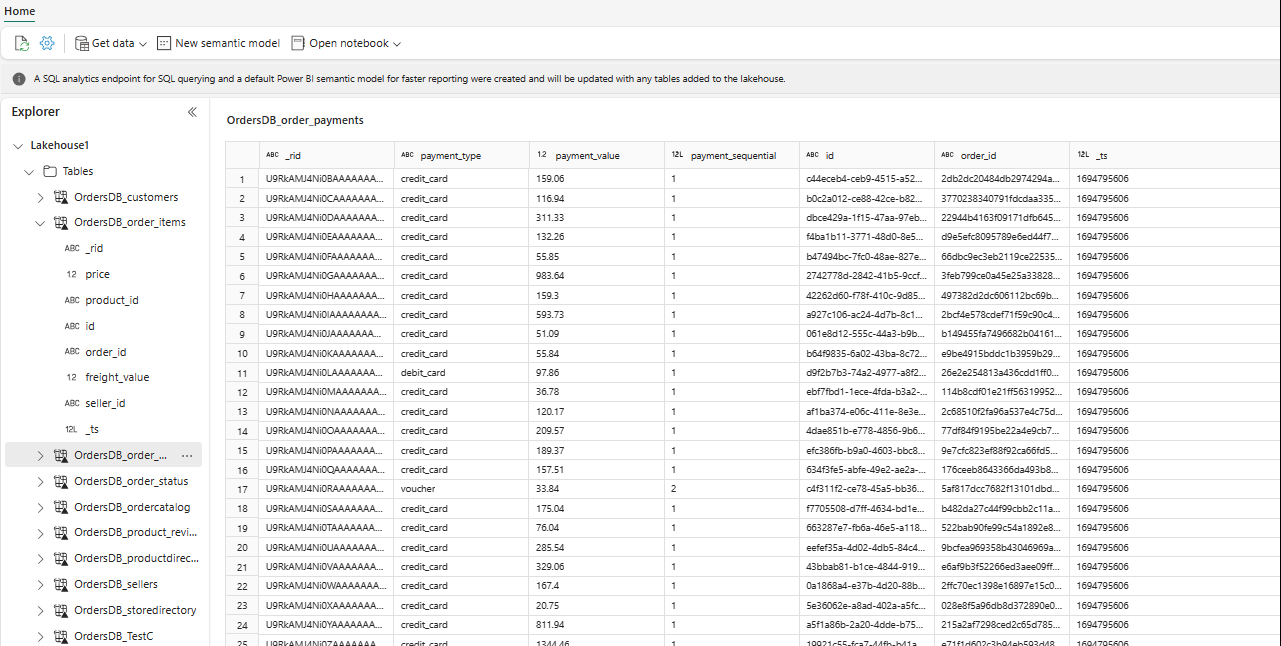
Dans l’Explorateur, vous pouvez maintenant voir les données de table sélectionnées dans votre Lakehouse.
Conseil
Vous pouvez ajouter d’autres données directement dans Lakehouse ou apporter des raccourcis tels que S3, ADLS Gen2. Vous pouvez accéder au point de terminaison d’analytique SQL du Lakehouse et joindre les données à toutes ces sources avec des données mise en miroir en toute transparence.
Pour explorer ces données dans Spark, sélectionnez les points
...en regard de n’importe quelle table. Sélectionnez Nouveau notebook ou notebook existant pour commencer l’analyse.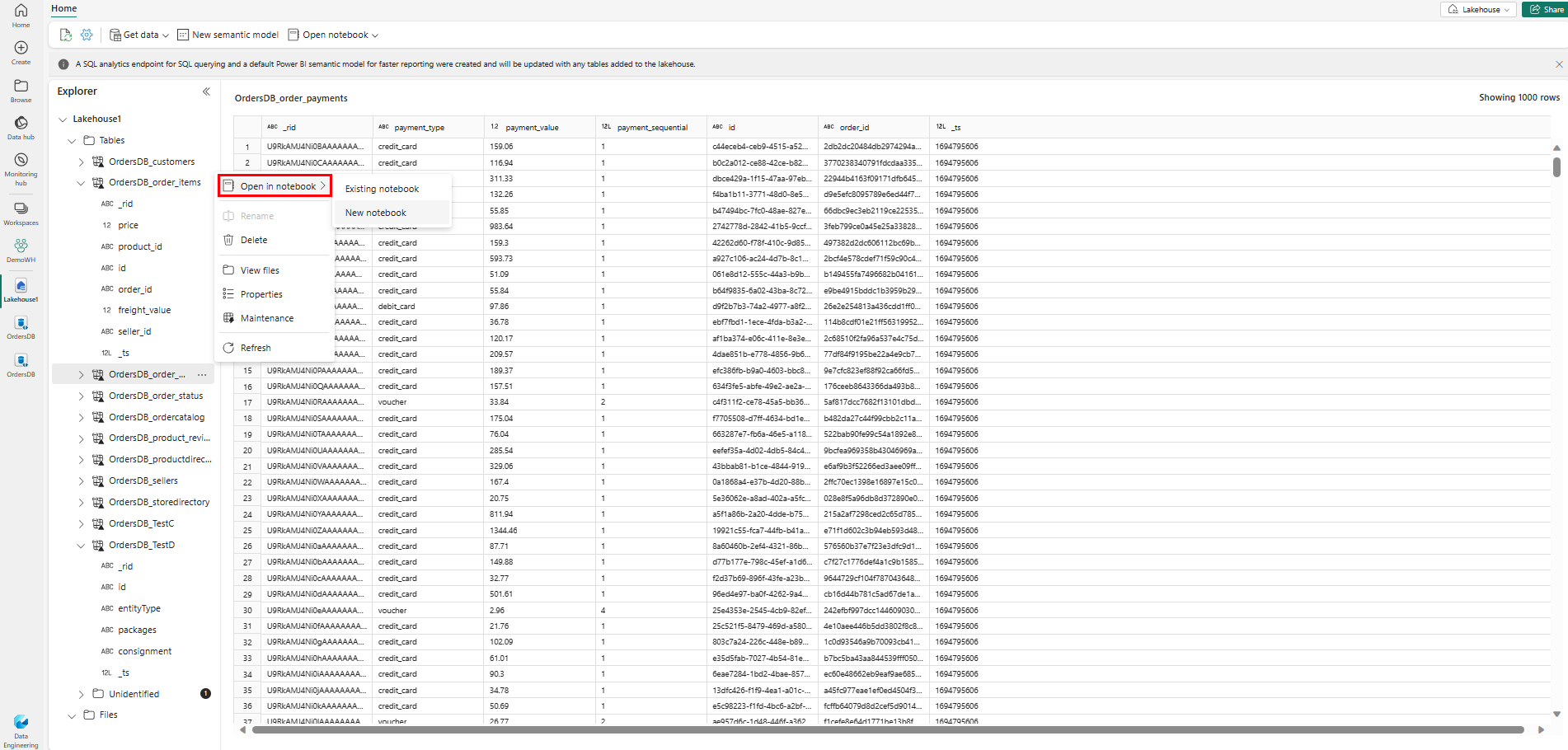
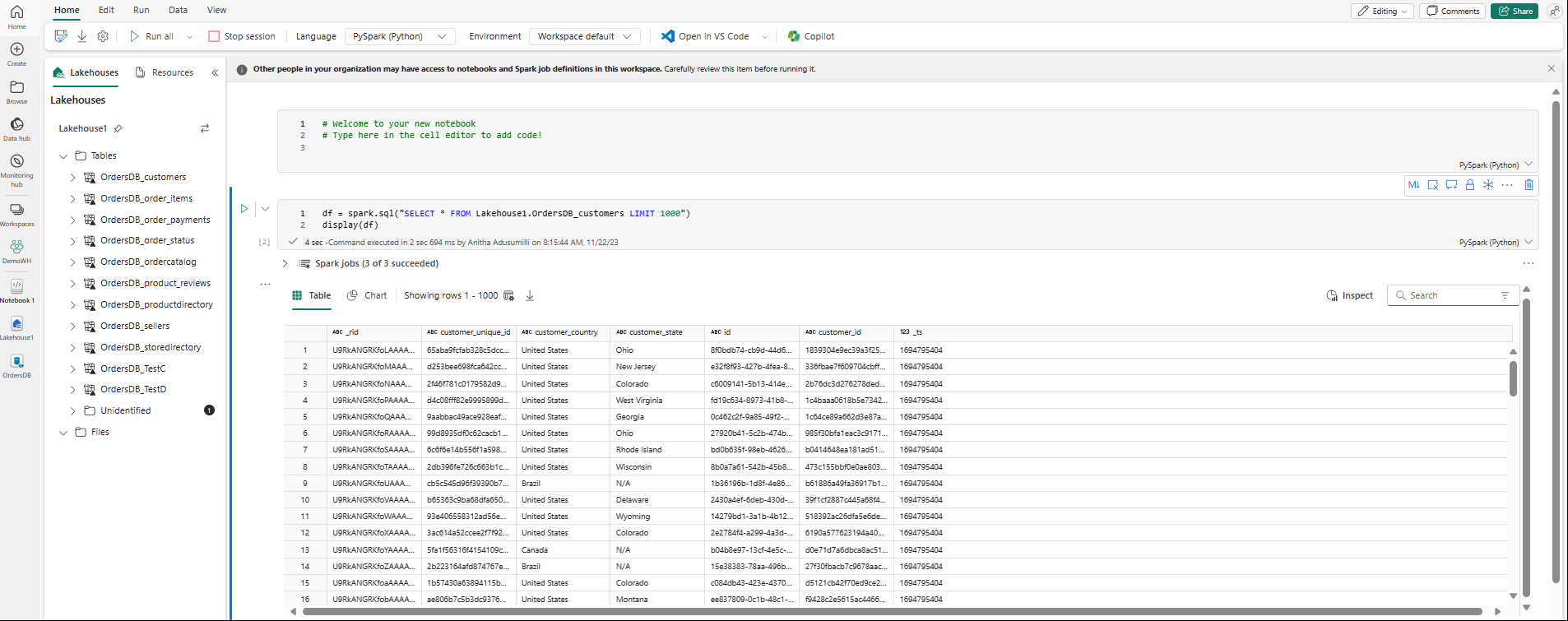
Le notebook s’ouvre automatiquement et charge le dataframe avec une requête SQL Spark
SELECT ... LIMIT 1000.- Les nouveaux notebooks peuvent prendre jusqu’à deux minutes pour charger complètement. Vous pouvez éviter ce délai à l’aide d’un notebook existant avec une session active.
- Les nouveaux notebooks peuvent prendre jusqu’à deux minutes pour charger complètement. Vous pouvez éviter ce délai à l’aide d’un notebook existant avec une session active.


