Tutoriel : Nettoyer les données avec des dépendances fonctionnelles
Dans ce tutoriel, vous utilisez des dépendances fonctionnelles pour le nettoyage des données. Une dépendance fonctionnelle existe lorsqu’une colonne d’un modèle sémantique (un jeu de données Power BI) est une fonction d’une autre colonne. Par exemple, un code postal colonne peut déterminer les valeurs d’une colonne ville. Une dépendance fonctionnelle se manifeste en tant que relation un-à-plusieurs entre les valeurs de deux colonnes ou plus dans un DataFrame. Ce tutoriel utilise le jeu de données Synthea pour montrer comment les relations fonctionnelles peuvent aider à détecter les problèmes de qualité des données.
Dans ce tutoriel, vous allez apprendre à :
- Appliquez des connaissances de domaine pour formuler des hypothèses sur les dépendances fonctionnelles dans un modèle sémantique.
- Familiarisez-vous avec les composants de la bibliothèque Python du lien sémantique (SemPy) qui permettent d’automatiser l’analyse de la qualité des données. Ces composants sont les suivants :
- FabricDataFrame : structure de type pandas améliorée avec des informations sémantiques supplémentaires.
- Fonctions utiles qui automatisent l’évaluation des hypothèses sur les dépendances fonctionnelles et qui identifient les violations des relations dans vos modèles sémantiques.
Conditions préalables
Obtenir un abonnement Microsoft Fabric. Vous pouvez également vous inscrire à une version d’évaluation gratuite de Microsoft Fabric .
Connectez-vous à Microsoft Fabric.
Utilisez le sélecteur d’expérience en bas à gauche de votre page d’accueil pour basculer vers Fabric.
- Sélectionnez espaces de travail dans le volet de navigation gauche pour rechercher et sélectionner votre espace de travail. Cet espace de travail devient votre espace de travail actuel.
Suivre le notebook
Le notebook data_cleaning_functional_dependencies_tutorial.ipynb accompagne ce tutoriel.
Pour ouvrir le bloc-notes associé pour ce didacticiel, suivez les instructions de Préparer votre système pour les didacticiels de science des données pour importer le bloc-notes dans votre espace de travail.
Si vous préférez copier et coller le code à partir de cette page, vous pouvez créer un bloc-notes.
Assurez-vous d'attacher un lakehouse au notebook avant de commencer à exécuter du code.
Configurer le notebook
Dans cette section, vous configurez un environnement de notebook avec les modules et données nécessaires.
- Pour Spark 3.4 et versions ultérieures, le lien sémantique est disponible dans le runtime par défaut lors de l’utilisation de Fabric et il n’est pas nécessaire de l’installer. Si vous utilisez Spark 3.3 ou ci-dessous, ou si vous souhaitez effectuer une mise à jour vers la version la plus récente du lien sémantique, vous pouvez exécuter la commande :
python %pip install -U semantic-link
Effectuez les importations nécessaires de modules dont vous aurez besoin ultérieurement :
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaExtrayez les exemples de données. Pour ce tutoriel, vous utilisez le jeu de données Synthea de dossiers médicaux synthétiques (petite version pour plus de simplicité) :
download_synthea(which='small')
Exploration des données
Initialisez un
FabricDataFrameavec le contenu du fichier providers.csv :providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Recherchez les problèmes de qualité des données avec la fonction
find_dependenciessemPy en tracéant un graphique des dépendances fonctionnelles détectées automatiquement :deps = providers.find_dependencies() plot_dependency_metadata(deps)capture d’écran
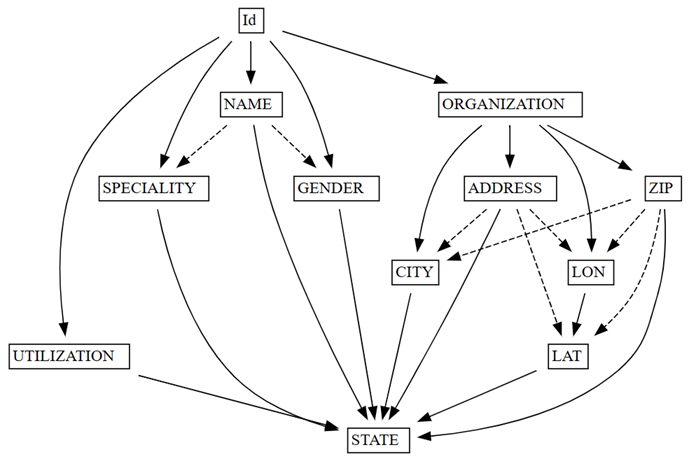
Le graphique des dépendances fonctionnelles montre que
IddétermineNAMEetORGANIZATION(indiqués par les flèches solides), ce qui est attendu, étant donné queIdest unique :Vérifiez que
Idest unique :providers.Id.is_uniqueLe code retourne
Truepour confirmer queIdest unique.

Analyser les dépendances fonctionnelles en profondeur
Le graphique des dépendances fonctionnelles montre également que ORGANIZATION détermine ADDRESS et ZIP, comme prévu. Toutefois, vous pouvez vous attendre à ce que ZIP détermine également CITY, mais la flèche en pointillés indique que la dépendance n’est que approximative, pointant vers un problème de qualité des données.
Il existe d’autres particularités dans le graphique. Par exemple, NAME ne détermine pas GENDER, Id, SPECIALITYou ORGANIZATION. Chacune de ces particularités pourrait mériter une enquête.
Examinez plus en détail la relation approximative entre
ZIPetCITY, à l’aide de la fonctionlist_dependency_violationssemPy pour afficher une liste tabulaire de violations :providers.list_dependency_violations('ZIP', 'CITY')Dessinez un graphique avec la fonction de visualisation
plot_dependency_violationsde SemPy. Ce graphique est utile si le nombre de violations est petit :providers.plot_dependency_violations('ZIP', 'CITY')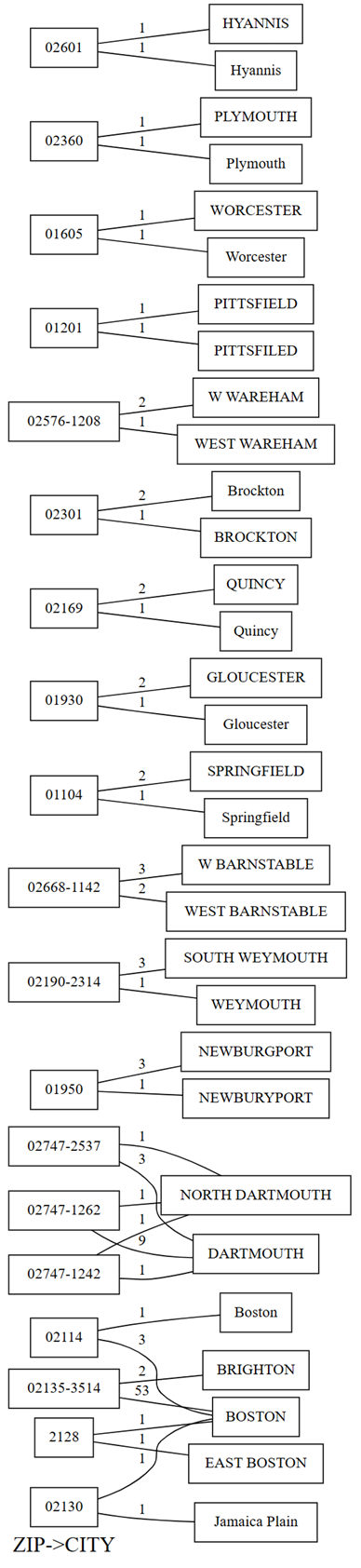
Le tracé des violations de dépendances affiche les valeurs de
ZIPsur le côté gauche et les valeurs deCITYsur le côté droit. Un bord connecte un code postal sur le côté gauche du tracé avec une ville sur le côté droit s’il existe une ligne qui contient ces deux valeurs. Les arêtes sont annotées avec le nombre de lignes de ce type. Par exemple, il existe deux lignes avec le code postal 02747-1242, une ligne avec la ville « NORTH DARTHMOUTH » et l’autre avec la ville « DARTHMOUTH », comme illustré dans le tracé précédent et le code suivant :Vérifiez les observations précédentes que vous avez faites avec le tracé des violations de dépendance en exécutant le code suivant :
providers[providers.ZIP == '02747-1242'].CITY.value_counts()Le tracé montre également que parmi les lignes qui ont
CITYcomme « DARTHMOUTH », neuf lignes ont uneZIPde 02747-1262 ; une ligne a uneZIPde 02747-1242 ; et une ligne a uneZIPde 02747-2537. Confirme ces observations avec le code suivant :providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()Il existe d’autres codes postaux associés à « DARTMOUTH », mais ces codes postal ne sont pas affichés dans le graphique des violations de dépendances, car ils n’indiquent pas les problèmes de qualité des données. Par exemple, le code postal « 02747-4302 » est associé de manière unique à « DARTMOUTH » et ne s’affiche pas dans le graphique des violations de dépendances. Confirmez en exécutant le code suivant :
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Résumer les problèmes de qualité des données détectés avec SemPy
Revenez au graphique des violations de dépendances, vous pouvez voir qu’il existe plusieurs problèmes de qualité des données intéressants présents dans ce modèle sémantique :
- Certains noms de ville sont tous en majuscules. Ce problème est facile à résoudre à l’aide de méthodes de chaîne.
- Certains noms de ville ont des qualificateurs (ou préfixes), tels que « Nord » et « Est ». Par exemple, le code postal « 2128 » correspond une fois à « EAST BOSTON » et une fois à « BOSTON ». Un problème similaire se produit entre « NORTH DARTHMOUTH » et « DARTHMOUTH ». Vous pouvez essayer de supprimer ces qualificateurs ou de relier les codes postaux à la ville la plus courante.
- Il existe des fautes de frappe dans certaines villes, telles que « PITTSFIELD » et « PITTSFILED » et « NEWBURGPORT vs. NEWBURYPORT ». Pour « NEWBURGPORT », cette faute de frappe peut être corrigée à l’aide de l’occurrence la plus courante. Pour « PITTSFIELD », il n’existe qu’une seule occurrence, ce qui rend beaucoup plus difficile la levée automatique de l’ambiguïté sans connaissance externe ou sans le recours à un modèle de langage.
- Parfois, les préfixes comme « Ouest » sont abrégés en une seule lettre « W ». Ce problème peut éventuellement être résolu avec un remplacement simple, si toutes les occurrences de « W » sont associées à « West ».
- Le code postal « 02130 » est mappé à « BOSTON » une fois et « Jamaïque Plain » une fois. Ce problème n’est pas facile à résoudre, mais s’il y avait plus de données, le mappage à l’occurrence la plus courante pourrait être une solution potentielle.
Nettoyer les données
Corrigez les problèmes de mise en majuscules en adoptant le format où la première lettre des mots est en majuscule :
providers['CITY'] = providers.CITY.str.title()Réexécutez la détection des violations pour voir que certaines ambiguïtés sont passées (le nombre de violations est plus petit) :
providers.list_dependency_violations('ZIP', 'CITY')À ce stade, vous pouvez affiner vos données plus manuellement, mais une tâche potentielle de nettoyage des données consiste à supprimer des lignes qui violent les contraintes fonctionnelles entre les colonnes des données, à l’aide de la fonction
drop_dependency_violationsde SemPy.Pour chaque valeur de la variable déterminante,
drop_dependency_violationsfonctionne en sélectionnant la valeur la plus courante de la variable dépendante et en supprimant toutes les lignes avec d’autres valeurs. Vous devez appliquer cette opération uniquement si vous êtes certain que cette heuristique statistique entraînerait les résultats corrects pour vos données. Sinon, vous devez écrire votre propre code pour gérer les violations détectées si nécessaire.Exécutez la fonction
drop_dependency_violationssur les colonnesZIPetCITY:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Répertoriez les violations de dépendance entre
ZIPetCITY:providers_clean.list_dependency_violations('ZIP', 'CITY')Le code retourne une liste vide pour indiquer qu’il n’y a plus de violations de la contrainte fonctionnelle CITY -> ZIP.
Contenu connexe
Consultez d’autres didacticiels pour le lien sémantique / SemPy :
- didacticiel : Analyser les dépendances fonctionnelles dans un exemple de modèle sémantique
- Tutoriel : Extraire et calculer des mesures Power BI à partir d’un notebook Jupyter
- Tutoriel : Découvrir les relations dans un modèle sémantique, à l’aide d’un lien sémantique
- Tutoriel : Découvrir les relations dans le jeu de données Synthea, en utilisant le lien sémantique
- tutoriel : Valider les données à l’aide de SemPy et de GX (Great Expectations)