Tutoriel : Utiliser R pour prédire le retard de vol
Ce tutoriel présente un exemple de bout en bout d’un workflow Synapse Data Science dans Microsoft Fabric. Il utilise les données nycflights13, et R, pour prédire si un avion arrive plus de 30 minutes en retard. Il utilise ensuite les résultats de prédiction pour créer un tableau de bord Power BI interactif.
Dans ce tutoriel, vous allez apprendre à :
- Utilisez les packages de tidymodels (recettes, parsnip , rsample , workflows ) pour traiter les données et entraîner un modèle d'apprentissage automatique.
- Écrire les données de sortie dans un lakehouse sous forme d’une table delta
- Générer un rapport visuel Power BI pour accéder directement aux données dans ce lakehouse
Conditions préalables
Procurez-vous un abonnement Microsoft Fabric . Vous pouvez également vous inscrire à une version d’évaluation gratuite de Microsoft Fabric .
Connectez-vous à Microsoft Fabric.
Utilisez le sélecteur d’expérience en bas à gauche de votre page d’accueil pour basculer vers Fabric.
Ouvrez ou créez un bloc-notes. Pour en savoir plus, consultez Comment utiliser des notebooks Microsoft Fabric.
Définissez l’option de langue sur SparkR (R) pour modifier la langue primaire.
Attachez votre notebook à un lakehouse. Sur le côté gauche, sélectionnez Ajouter pour ajouter un lakehouse existant ou pour créer un lakehouse.
Installer des packages
Installez le package nycflights13 pour utiliser le code de ce didacticiel.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Explorer les données
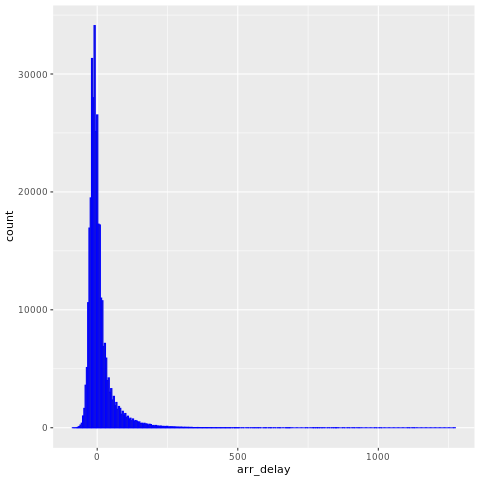
Les données nycflights13 ont des informations sur 325 819 vols arrivés près de New York en 2013. Tout d’abord, consultez la distribution des retards de vol. Ce graphique montre que la distribution des retards à l’arrivée est asymétrique à droite. Il représente une longue queue dans les valeurs élevées.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Chargez les données et apportez quelques modifications aux variables :
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Avant de générer le modèle, tenez compte de quelques variables spécifiques importantes pour le prétraitement et la modélisation.
La variable arr_delay est une variable de facteur. Pour l’entraînement du modèle de régression logistique, il est important que la variable de résultat soit une variable de facteur.
glimpse(flight_data)
Environ 16% des vols de ce jeu de données ont atterri avec plus de 30 minutes de retard.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
La fonctionnalité dest comporte 104 destinations de vol.
unique(flight_data$dest)
Il existe 16 transporteurs distincts.
unique(flight_data$carrier)
Fractionner les données
Fractionnez le jeu de données en deux jeux : un jeu d’entraînement et un jeu de test . Conservez la plupart des lignes du jeu de données d’origine (sous la forme d’un sous-ensemble choisi de manière aléatoire) dans le jeu de données d’apprentissage. Utilisez le jeu de données d’entraînement pour ajuster le modèle et utilisez le jeu de données de test pour mesurer les performances du modèle.
Utilisez le package rsample pour créer un objet qui contient des informations sur la façon de fractionner les données. Ensuite, utilisez deux fonctions rsample supplémentaires pour créer des DataFrames pour les jeux d’entraînement et de test :
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Créer une recette et des rôles
Créez une recette pour un modèle de régression logistique simple. Avant d’entraîner le modèle, utilisez une recette pour créer de nouveaux prédicteurs et effectuer le prétraitement requis par le modèle.
Utilisez la fonction update_role() pour que les recettes sachent que flight et time_hour sont des variables, avec un rôle personnalisé appelé ID. Un rôle peut avoir n’importe quelle valeur de caractère. La formule inclut toutes les variables du jeu d’entraînement autres que arr_delay en tant que variables prédictives. La recette conserve ces deux variables d’ID, mais ne les utilise pas comme résultats ou prédicteurs.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Pour afficher l’ensemble actuel de variables et de rôles, utilisez la fonction summary() :
summary(flights_rec)
Créer des fonctionnalités
Effectuez une ingénierie des fonctionnalités pour améliorer votre modèle. La date de vol peut avoir un effet raisonnable sur la probabilité d’une arrivée tardive.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Il peut aider à ajouter des termes de modèle dérivés de la date pouvant avoir une importance pour le modèle. Dérivez les fonctionnalités significatives suivantes de la variable de date unique :
- Jour de la semaine
- Mois
- Indique si la date correspond à un congé
Ajoutez les trois étapes à votre recette :
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Ajuster un modèle avec une recette
Utilisez la régression logistique pour modéliser les données de vol. Tout d’abord, générez une spécification de modèle avec le package parsnip :
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Utilisez le package workflows pour regrouper votre modèle de parsnip (lr_mod) avec votre recette (flights_rec) :
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Entraîner le modèle
Cette fonction peut préparer la recette et entraîner le modèle à partir des prédicteurs résultants :
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Utilisez les fonctions d’assistance xtract_fit_parsnip() et extract_recipe() pour extraire le modèle ou les objets de recette du flux de travail. Dans cet exemple, extrayez l’objet de modèle ajusté, puis utilisez la fonction broom::tidy() pour obtenir un tibble bien rangé des coefficients de modèle :
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Prédire les résultats
Un seul appel à predict() utilise le workflow entraîné (flights_fit) pour effectuer des prédictions avec les données de test invisibles. La méthode predict() applique la recette aux nouvelles données, puis transmet les résultats au modèle ajusté.
predict(flights_fit, test_data)
Obtenez la sortie de predict() pour retourner la classe prédite : late par rapport à on_time. Toutefois, pour les probabilités de classe prédites pour chaque vol, utilisez augment() avec le modèle, combinées avec les données de test, pour les enregistrer ensemble :
flights_aug <-
augment(flights_fit, test_data)
Passez en revue les données :
glimpse(flights_aug)
Évaluer le modèle
Nous avons désormais un tibble avec les probabilités de classe prédites. Dans les premières rangées, le modèle a prédit avec précision cinq vols à temps (les valeurs de .pred_on_time sont p > 0.50). Toutefois, nous avons 81 455 lignes totales à prédire.
Nous avons besoin d’une métrique qui indique comment le modèle prédit les arrivées tardives, par rapport au véritable état de votre variable de résultat, arr_delay.
Utilisez l'aire sous la courbe de la caractéristique de fonctionnement du récepteur (AUC-ROC) comme métrique. Calculez-le avec roc_curve() et roc_auc(), à partir du package yardstick :
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Créer un rapport Power BI
Le résultat du modèle semble bon. Utilisez les résultats de prédiction des retards de vol pour créer un tableau de bord Power BI interactif. Le tableau de bord affiche le nombre de vols par transporteur et le nombre de vols par destination. Le tableau de bord peut filtrer selon les résultats de prédiction de retard.
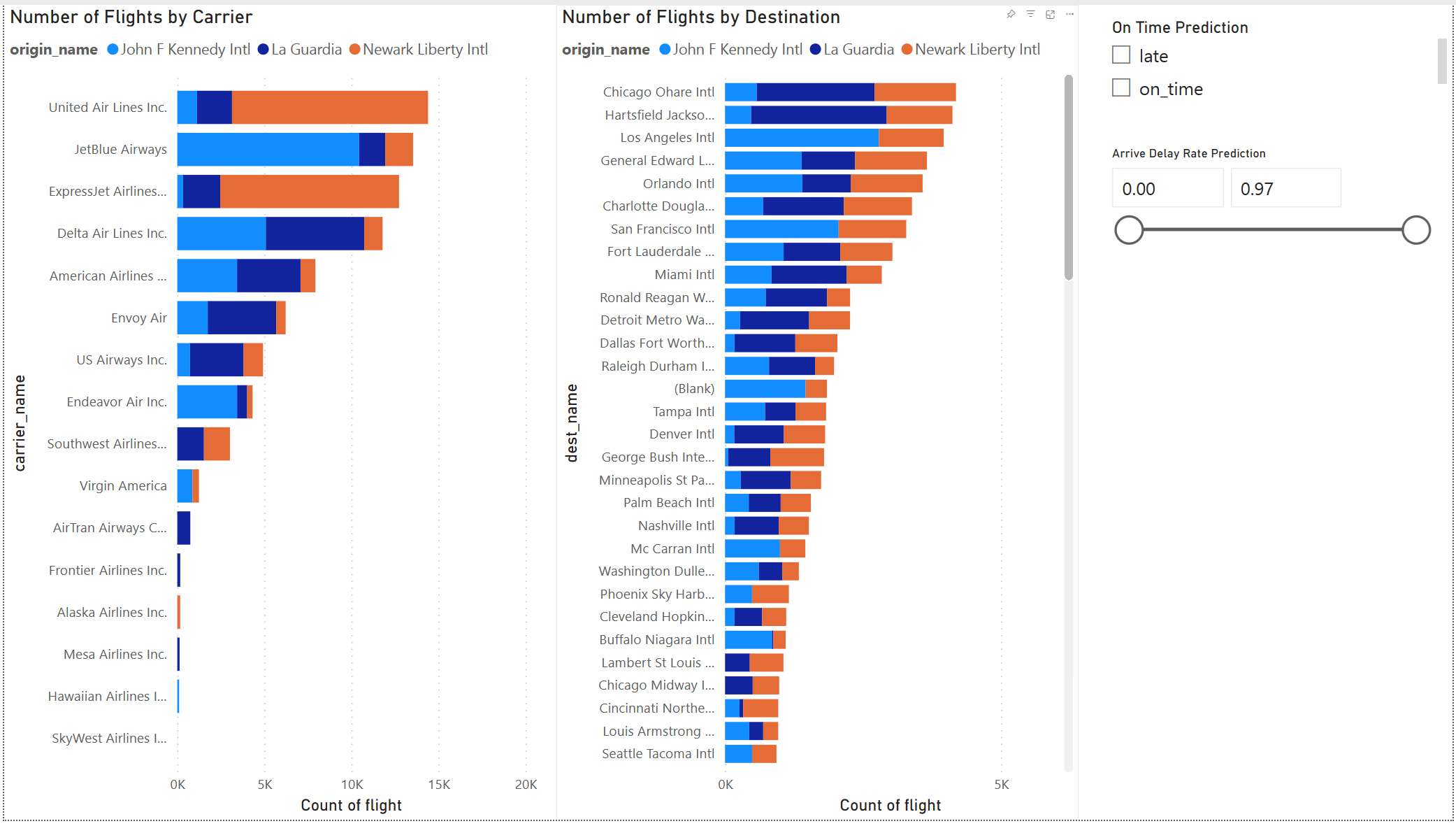
Incluez le nom du transporteur et le nom de l’aéroport dans le jeu de données de résultat de prédiction :
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Passez en revue les données :
glimpse(flights_clean)
Convertissez les données en DataFrame Spark :
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Écrivez les données dans une table delta dans votre lakehouse :
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Utilisez la table delta pour créer un modèle sémantique.
Sur la gauche, sélectionnez OneLake
Sélectionnez le Lakehouse que vous avez attaché à votre notebook
Sélectionnez Ouvrir
Sélectionnez nouveau modèle sémantique
Sélectionnez nycflight13 pour votre nouveau modèle sémantique, puis sélectionnez Confirmer
Votre modèle sémantique est créé. Sélectionnez Nouveau Rapport
Sélectionnez ou faites glisser des champs depuis les volets Données et Visualisations sur le canevas de rapport pour créer votre rapport
Pour créer le rapport affiché au début de cette section, utilisez ces visualisations et données :
 Graphique à barres empilées avec :
Graphique à barres empilées avec :- Axe Y : carrier_name
- Axe X : vol. Sélectionnez Nombre pour l’agrégation
- Légende : origin_name
- Graphique à barres empilées avec :
- Axe Y : dest_name
- Axe X : vol. Sélectionnez Nombre pour l’agrégation
- Légende : nom_origine
 Segment avec :
Segment avec :- Champ : _pred_class
- Segment avec :
- Champ : _pred_late