Gestion de bibliothèque R
Les bibliothèques fournissent du code réutilisable que vous souhaiterez peut-être inclure dans vos programmes ou projets pour Microsoft Fabric Spark.
Microsoft Fabric prend en charge un runtime R avec de nombreux packages R open source populaires, notamment TidyVerse, préinstallés. Lorsqu’une instance Spark démarre, ces bibliothèques sont incluses automatiquement et disponibles pour être utilisées immédiatement dans les notebooks ou les définitions de travaux Spark.
Vous devrez peut-être mettre à jour vos bibliothèques R pour différentes raisons. Par exemple, l’une de vos dépendances principales a publié une nouvelle version, ou votre équipe a créé un package personnalisé dont vous avez besoin dans vos clusters Spark.
Il existe deux types de bibliothèques que vous pouvez inclure en fonction de votre scénario :
Les bibliothèques de flux de données désignent celles qui résident dans des sources ou dépôts publics, tels que CRAN ou GitHub.
bibliothèques personnalisées sont le code créé par vous ou votre organisation, .tar.gz pouvez être géré via les portails gestion des bibliothèques.
Il existe deux niveaux de packages installés sur Microsoft Fabric :
Environnement: gérez les bibliothèques via un environnement pour réutiliser le même ensemble de bibliothèques sur plusieurs blocs-notes ou travaux.
session : une installation de session crée un environnement pour une session de bloc-notes spécifique. La modification des bibliothèques de niveau session n’est pas persistante entre les sessions.
Résumé des comportements actuels de gestion des bibliothèques R disponibles :
| Type de bibliothèque | Installation de l’environnement | Installation au niveau de la session |
|---|---|---|
| Flux R (CRAN) | Non pris en charge | Pris en charge |
| R Personnalisé | Pris en charge | Pris en charge |
Conditions préalables
Obtenez un abonnement Microsoft Fabric . Vous pouvez également vous inscrire à une version d’évaluation gratuite de Microsoft Fabric .
Connectez-vous à Microsoft Fabric.
Utilisez le sélecteur d’expérience en bas à gauche de votre page d’accueil pour basculer vers Fabric.
Bibliothèques R au niveau de la session
Lorsque vous effectuez une analyse interactive des données ou un Machine Learning, vous pouvez essayer des packages plus récents ou vous pouvez avoir besoin de packages actuellement indisponibles sur votre espace de travail. Au lieu de mettre à jour les paramètres de l’espace de travail, vous pouvez utiliser des packages délimités à la session pour ajouter, gérer et mettre à jour les dépendances de session.
- Lorsque vous installez des bibliothèques délimitées à la session, seul le notebook actuel a accès aux bibliothèques spécifiées.
- Ces bibliothèques n’affectent pas d’autres sessions ou travaux utilisant le même pool Spark.
- Ces bibliothèques sont installées en plus de l'environnement d'exécution de base et des bibliothèques du niveau de pool.
- Les bibliothèques de notebooks sont prioritaires.
- Les bibliothèques R délimitées à une session ne sont pas conservées entre les sessions. Ces bibliothèques sont installées au début de chaque session lorsque les commandes d’installation associées sont exécutées.
- Les bibliothèques R délimitées à la session sont automatiquement installées sur les nœuds worker et de pilote.
Remarque
Les commandes de gestion des bibliothèques R sont désactivées lors de l’exécution de travaux de pipeline. Si vous souhaitez installer un package dans un pipeline, vous devez utiliser les fonctionnalités de gestion des bibliothèques au niveau de l’espace de travail.
Installer des packages R à partir de CRAN
Vous pouvez facilement installer une bibliothèque R à partir de CRAN.
# install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Vous pouvez également utiliser des captures instantanées CRAN comme référentiel pour vous assurer de télécharger la même version du package à chaque fois.
# install a package from CRAN snapsho
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Installer des packages R à l’aide de devtools
La bibliothèque devtools simplifie le développement de packages pour accélérer les tâches courantes. Cette bibliothèque est installée dans le runtime Microsoft Fabric par défaut.
Vous pouvez utiliser devtools pour spécifier une version spécifique d’une bibliothèque à installer. Ces bibliothèques sont installées sur tous les nœuds du cluster.
# Install a specific version.
install_version("caesar", version = "1.0.0")
De même, vous pouvez installer une bibliothèque directement à partir de GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
Actuellement, les fonctions de devtools suivantes sont prises en charge dans Microsoft Fabric :
| Commande | Description |
|---|---|
| install_github() | Installe un package R à partir de GitHub |
| install_gitlab() | Installe un package R à partir de GitLab |
| install_bitbucket() | Installe un package R à partir de BitBucket |
| install_url() | Installe un package R à partir d’une URL arbitraire |
| install_git() | Installations à partir d’un référentiel Git arbitraire |
| install_local() | Installations à partir d’un fichier local sur le disque |
| install_version() | Installations à partir d’une version spécifique sur CRAN |
Installer des bibliothèques personnalisées R
Pour utiliser une bibliothèque personnalisée au niveau de la session, vous devez d’abord la charger dans un Lakehouse attaché.
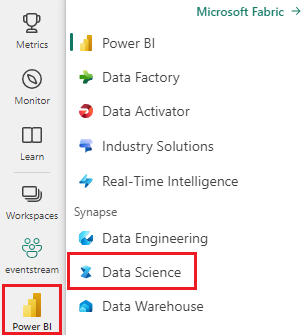
Ouvrez le bloc-notes dans lequel vous souhaitez utiliser la bibliothèque personnalisée.
Sur le côté gauche, sélectionnez Ajouter pour ajouter un lac existant ou créer un lac.
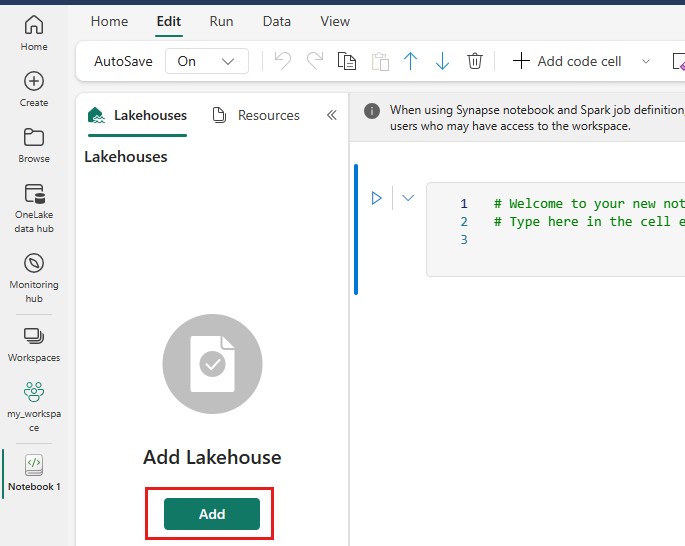
Cliquez avec le bouton droit ou sélectionnez « ... » en regard de Fichiers pour charger votre fichier .tar.gz.
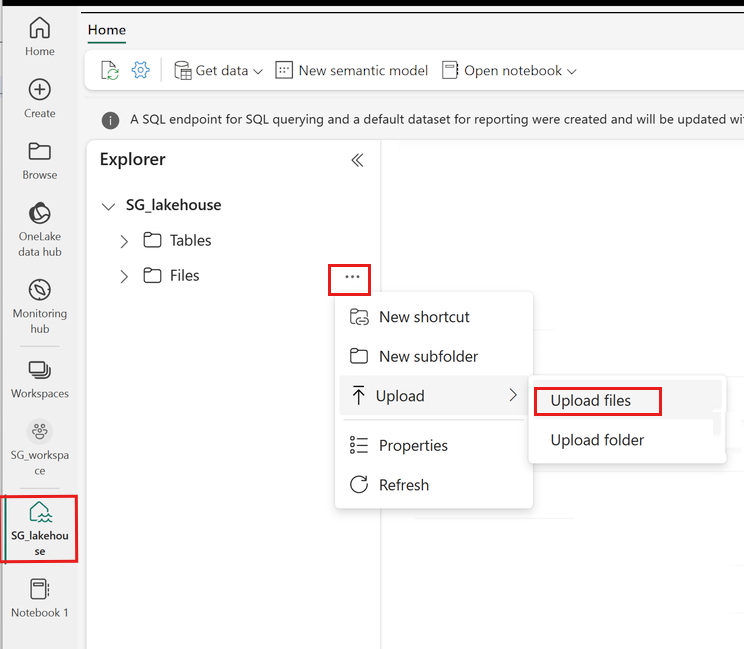
Après le chargement, revenez à votre bloc-notes. Utilisez la commande suivante pour installer la bibliothèque personnalisée dans votre session :
install.packages("filepath/filename.tar.gz", repos = NULL, type = "source")
Afficher les bibliothèques installées
Interrogez toutes les bibliothèques installées dans votre session à l’aide de la commande library.
# query all the libraries installed in current session
library()
Utilisez la fonction packageVersion pour vérifier la version de la bibliothèque :
# check the package version
packageVersion("caesar")
Supprimer un package R d’une session
Vous pouvez utiliser la fonction detach pour supprimer une bibliothèque de l’espace de noms. Ces bibliothèques restent sur le disque jusqu’à ce qu’elles soient à nouveau chargées.
# detach a library
detach("package: caesar")
Pour supprimer un package à l’étendue d’une session d’un notebook, utilisez la commande remove.packages(). Cette modification de bibliothèque n’a aucun impact sur d’autres sessions sur le même cluster. Les utilisateurs ne peuvent pas désinstaller ou supprimer des bibliothèques intégrées du runtime Microsoft Fabric par défaut.
Remarque
Vous ne pouvez pas supprimer de packages principaux tels que SparkR, SparklyR ou R.
remove.packages("caesar")
Bibliothèques R délimitées à une session et SparkR
Des bibliothèques à l’étendue du notebook sont disponibles sur les travailleurs SparkR.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Bibliothèques R délimitées à une session et sparklyr
Avec spark_apply() dans sparklyr, vous pouvez utiliser n’importe quel package R à l’intérieur de Spark. Par défaut, dans sparklyr::spark_apply(), l’argument packages est défini sur FALSE. Cela copie les bibliothèques dans les libPaths actuels vers les travailleurs, ce qui vous permet de les importer et de les utiliser sur les travailleurs. Par exemple, vous pouvez exécuter ce qui suit pour générer un message chiffré par césar avec sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- sparkR.version()
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Contenu connexe
En savoir plus sur les fonctionnalités R :