Transformer des données en exécutant une activité de définition du travail Spark
L’activité de définition du travail Spark dans Fabrique de données pour Microsoft Fabric vous permet de créer des connexions à vos définitions du travail Spark et de les exécuter à partir d’un pipeline de données.
Prérequis
Pour commencer, vous devez remplir les conditions préalables suivantes :
- Un compte locataire avec un abonnement actif. Créez un compte gratuitement.
- Un espace de travail est créé.
Ajoutez une activité de définition du travail Spark à un pipeline avec l’interface utilisateur (IU)
Créez un nouveau pipeline de données dans votre espace de travail.
Recherchez la définition du travail Spark dans la carte de l’écran d’accueil et sélectionnez-la ou sélectionnez l’activité dans la barre des activités pour l’ajouter à l’espace du pipeline.
Créez l’activité à partir de la carte de l’écran d’accueil :
Création de l’activité à partir de la barre Activités :
Sélectionnez la nouvelle activité de définition du travail Spark sur l’espace le cas échéant.
Consultez le guide des Paramètres généraux pour configurer les options de la tabulation Paramètres généraux.



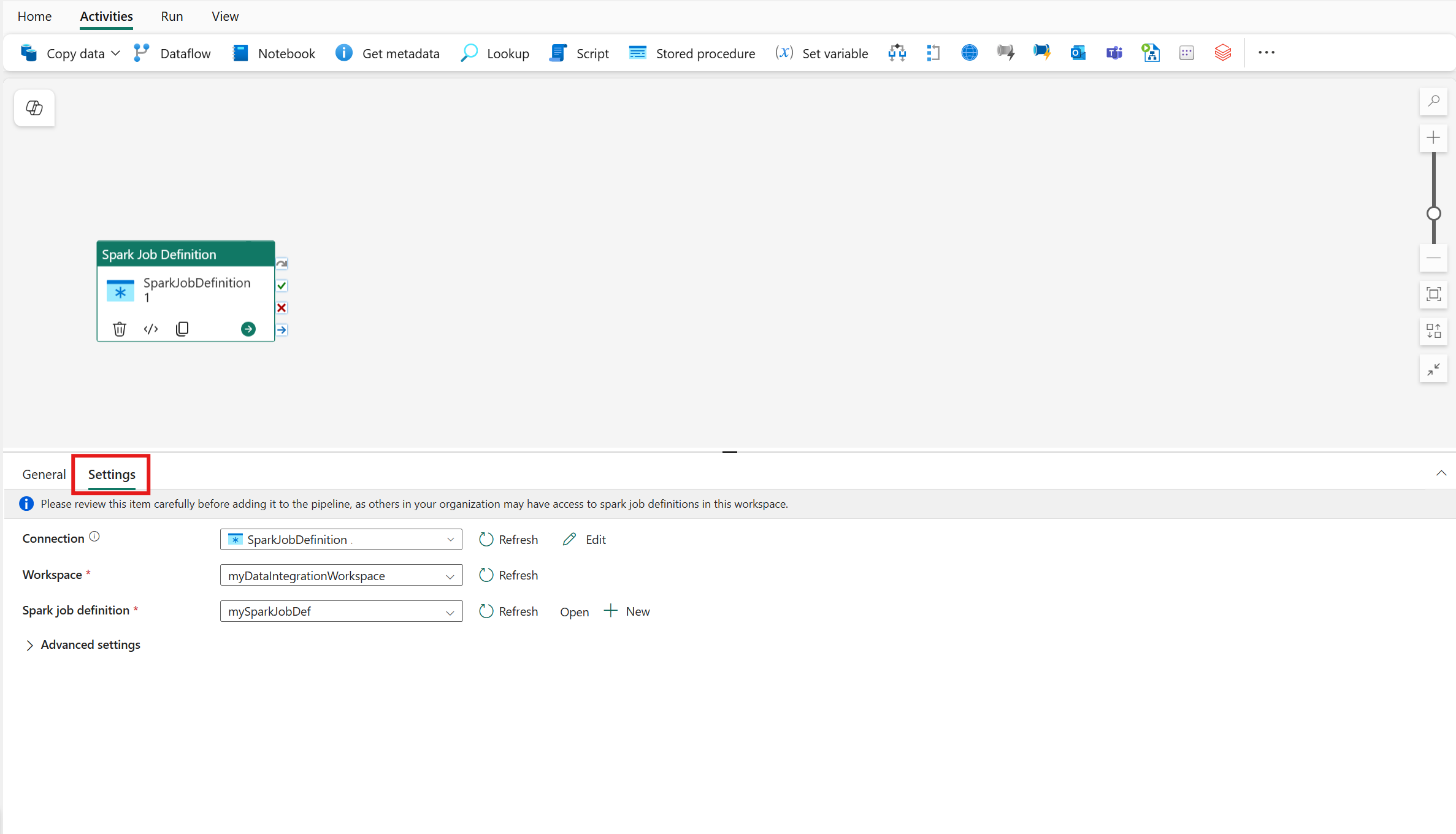
Paramètres de l’activité de définition du travail Spark
Sélectionnez l’onglet Paramètres dans le volet propriétés de l’activité, puis cliquez sur l’espace de travail Fabric qui contient la définition du travail Spark que vous souhaitez exécuter.
Limitations connues
Les limitations actuelles de l’activité de définition du travail Spark pour Fabrique de données Fabric sont répertoriées ici. Cette section peut être modifiée.
- Actuellement, nous ne prenons pas en charge la création d’une activité de définition du travail Spark dans l’activité (sous Paramètres)
- La prise en charge du paramétrage n’est pas disponible.
- Bien que nous prenions en charge la surveillance de l’activité via l’onglet sortie, vous ne pouvez pas encore surveiller la définition du travail Spark à un niveau plus précis. Par exemple, les liens vers la page de surveillance, l’état, la durée et les exécutions de définition du travail Spark précédentes ne sont pas disponibles directement dans Fabrique de données. Toutefois, vous pouvez voir des détails plus granulaires dans la page de surveillance de définition du travail Spark.
Enregistrer et exécuter ou planifier le pipeline
Après avoir configuré toutes les autres activités requises pour votre pipeline, basculez vers l’onglet Accueil en haut de l’éditeur de pipeline et sélectionnez le bouton Enregistrer pour enregistrer votre pipeline. Sélectionnez Exécuter pour l'exécuter directement ou Planifier pour le planifier. Vous pouvez également afficher l'historique d'exécution ici ou configurer d'autres paramètres.
