Actualisation incrémentielle dans Dataflow Gen2 (préversion)
Dans cet article, nous présentons l’actualisation incrémentielle des données dans Dataflow Gen2 pour la Data Factory de Microsoft Fabric. Quand vous utilisez des flux de données pour ingérer et transformer des données, il existe des scénarios dans lesquels vous devez uniquement actualiser des données nouvelles ou mises à jour, en particulier lorsque vos données continuent de croître. La fonctionnalité d’actualisation incrémentielle répond à ce besoin en vous permettant de réduire les temps d’actualisation, d’améliorer la fiabilité en évitant des opérations longues et en réduisant l’utilisation des ressources.
Prérequis
Pour utiliser l’actualisation incrémentielle dans Dataflow Gen2, vous devez respecter les prérequis suivants :
- Vous devez disposer d’une capacité Fabric.
- Votre source de données prend en charge le repli (recommandé) et doit contenir une colonne Date/DateTime qui peut être utilisée pour filtrer les données.
- Vous devez disposer d’une destination de données qui prend en charge l’actualisation incrémentielle. Pour plus d’informations, accédez à Prise en charge de la destination.
- Avant de démarrer, passez en revue les limitations de l’actualisation incrémentielle. Pour plus d’informations, accédez à Limitations.
Prise en charge des destinations
Les destinations de données suivantes sont prises en charge dans l’actualisation incrémentielle :
- Fabric Warehouse
- Azure SQL Database
- Azure Synapse Analytics
D’autres destinations comme Lakehouse peuvent être utilisées en combinaison avec l’actualisation incrémentielle en utilisant une seconde requête qui référence les données mises en lot pour mettre à jour la destination des données. De cette façon, vous pouvez continuer à utiliser l’actualisation incrémentielle pour réduire la quantité de données qui doivent être traitées et récupérées du système source. Mais vous devez effectuer une actualisation complète des données mises en lots vers la destination des données.
Comment utiliser l’actualisation incrémentielle
Créez un Dataflow Gen2 ou ouvrez un Dataflow Gen2 existant.
Dans l’éditeur de flux de données, créez une requête qui récupère les données que vous souhaitez actualiser de manière incrémentielle.
Vérifiez l’aperçu des données pour vous assurer que la requête retourne des données qui contiennent une colonne DateTime, Date ou DateTimeZone que vous pouvez utiliser pour filtrer les données.
Assurez-vous que la requête est entièrement repliée, ce qui signifie que la requête est entièrement envoyée (push) vers le système source. Si la requête n’est pas entièrement repliée, vous devez modifier la requête pour qu’elle le soit. Vous pouvez vérifier que la requête est entièrement repliée en contrôlant les étapes de la requête dans l’éditeur de requête.
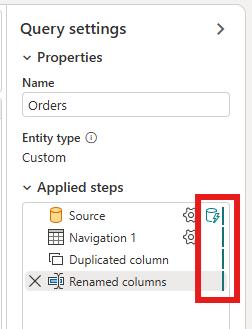
Cliquez avec le bouton droit sur la requête et sélectionnez Actualisation incrémentielle.
Fournissez les paramètres d’actualisation incrémentielle obligatoires.
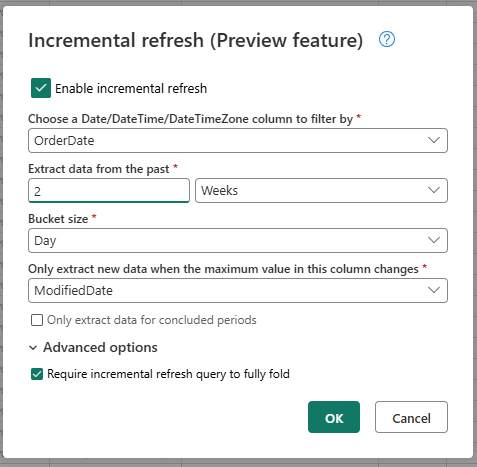
- Choisir une colonne DateTime avec laquelle filtrer.
- Extraire des données du passé.
- Taille du compartiment.
- Extraire uniquement les nouvelles données quand la valeur maximale de cette colonne sont modifiées.
Configurez les paramètres avancés, le cas échéant.
- Exiger une requête d’actualisation incrémentielle pour un repli complet.
Sélectionnez OK pour enregistrer les paramètres.
Si vous le souhaitez, vous pouvez maintenant configurer une destination de données pour la requête. Assurez-vous d’effectuer cette configuration avant la première actualisation incrémentielle, sinon votre destination de données ne contiendra que les données modifiées de manière incrémentielle depuis la dernière actualisation.
Publiez Dataflow Gen2.
Une fois l’actualisation incrémentielle configurée, le flux de données actualise automatiquement les données de manière incrémentielle en fonction des paramètres que vous avez fournis. Le flux de données récupère uniquement les données qui ont été modifiées depuis la dernière actualisation. Ainsi, le flux de données s’exécute plus rapidement et consomme moins de ressources.
Comment fonctionne l’actualisation incrémentielle en arrière-plan
L’actualisation incrémentielle fonctionne en divisant les données en compartiments en fonction de la colonne DateTime. Chaque compartiment contient les données qui ont été modifiées depuis la dernière actualisation. Le flux de données sait ce qui a été modifié en vérifiant la valeur maximale de la colonne que vous avez spécifiée. Si la valeur maximale de ce compartiment a été modifiée, le flux de données récupère l’ensemble du compartiment et remplace les données dans la destination. Si la valeur maximale n’a pas été modifiée, le flux de données ne récupère aucune donnée. Les sections suivantes contiennent une vue d’ensemble générale du fonctionnement pas à pas de l’actualisation incrémentielle.
Première étape : évaluer les modifications
Quand le flux de données s’exécute, il évalue d’abord les modifications apportées à la source de données. Il effectue cette évaluation en comparant la valeur maximale de la colonne DateTime à la valeur maximale de l’actualisation précédente. Si la valeur maximale a été modifiée ou s’il s’agit de la première actualisation, le flux de données marque le compartiment comme modifié et le répertorie pour traitement. Si la valeur maximale n’a pas été modifiée, le flux de données ignore le compartiment et ne le traite pas.
Deuxième étape : récupérer les données
Le flux de données est maintenant prêt à récupérer les données. Il récupère les données de chaque compartiment qui a été modifié. Le flux de données effectue cette récupération en parallèle pour améliorer le niveau de performance. Le flux de données récupère les données du système source et les charge dans la zone de mise en lots. Le flux de données récupère uniquement les données qui se trouvent dans la plage du compartiment. En d’autres termes, le flux de données récupère uniquement les données qui ont été modifiées depuis la dernière actualisation.
Dernière étape : remplacer les données dans la destination des données
Le flux de données remplace les données dans la destination par les nouvelles données. Le flux de données utilise la méthode replace pour remplacer les données dans la destination. Autrement dit, le flux de données supprime d’abord les données dans la destination pour ce compartiment, puis insère les nouvelles données. Le flux de données n’affecte pas les données qui sont en dehors de la plage du compartiment. Par conséquent, si, dans la destination, des données sont antérieures au premier compartiment, l’actualisation incrémentielle n’affecte aucunement ces données.
Explication des paramètres d'actualisation incrémentielle
Pour configurer une actualisation incrémentielle, vous devez spécifier les paramètres suivants.
Paramètres généraux :
Les paramètres généraux sont obligatoires et spécifient la configuration de base de l’actualisation incrémentielle.
Choisir une colonne DateTime avec laquelle filtrer
Ce paramètre est obligatoire et spécifie la colonne que les flux de données utilisent pour filtrer les données. Cette colonne doit être une colonne DateTime, Date ou DateTimeZone. Le flux de données utilise cette colonne pour filtrer les données et récupère uniquement les données qui ont été modifiées depuis la dernière actualisation.
Extraire des données du passé
Ce paramètre est obligatoire et spécifie jusqu’à quelle période du passé le flux de données doit extraire des données. Ce paramètre est utilisé pour récupérer le chargement de données initial. Le flux de données récupère toutes les données du système source qui se trouvent dans l’intervalle de temps spécifié. Les valeurs possibles sont les suivantes :
- x jours
- x semaines
- x mois
- x trimestres
- x années
Par exemple, si vous spécifiez 1 mois, le flux de données récupère toutes les nouvelles données du système source de moins d’un mois.
Taille du compartiment
Ce paramètre est obligatoire et spécifie la taille des compartiments que le flux de données utilise pour filtrer les données. Le flux de données divise les données en compartiments en fonction de la colonne DateTime. Chaque compartiment contient les données qui ont été modifiées depuis la dernière actualisation. La taille du compartiment détermine la quantité de données traitées dans chaque itération. Une taille de compartiment plus petite signifie que le flux de données traite moins de données dans chaque itération, mais cela signifie également qu’un nombre plus important d’itérations est nécessaire pour traiter toutes les données. Une taille de compartiment plus grande signifie que le flux de données traite plus de données dans chaque itération, mais cela signifie également qu’un nombre moins important d’itérations est nécessaire pour traiter toutes les données.
Extraire uniquement les nouvelles données quand la valeur maximale de cette colonne a été modifiée
Ce paramètre est obligatoire et spécifie la colonne que le flux de données utilise pour déterminer si les données ont été modifiées. Le flux de données compare la valeur maximale de cette colonne à la valeur maximale de l’actualisation précédente. Si la valeur maximale a été modifiée, le flux de données récupère les données qui ont été modifiées depuis la dernière actualisation. Si la valeur maximale n’a pas été modifiée, le flux de données ne récupère aucune donnée.
Extraire uniquement les données des périodes terminées
Ce paramètre est facultatif et spécifie si le flux de données doit uniquement extraire les données des périodes terminées. Si ce paramètre est activé, le flux de données extrait uniquement les données des périodes terminées. Ainsi, le flux de données extrait uniquement les données des périodes qui sont terminées et qui ne contiennent pas de données futures. Si ce paramètre est désactivé, le flux de données extrait les données de toutes les périodes, notamment des périodes qui ne sont pas terminées et qui contiennent des données futures.
Par exemple, si la colonne DateTime contient la date de la transaction et si vous souhaitez uniquement actualiser les mois complets, vous pouvez activer ce paramètre en combinaison avec la taille de compartiment de month. Par conséquent, le flux de données extrait uniquement les données des mois complets et n’extrait pas les données des mois incomplets.
Paramètres avancés
Certains paramètres sont considérés comme avancés et ne sont pas nécessaires dans la plupart des scénarios.
Exiger une requête d’actualisation incrémentielle pour un repli complet
Ce paramètre est facultatif et spécifie si la requête utilisée pour l’actualisation incrémentielle doit être entièrement repliée. Si ce paramètre est activé, la requête utilisée pour l’actualisation incrémentielle doit être entièrement repliée. Autrement dit, la requête doit être entièrement envoyée (push) vers le système source. Si ce paramètre est désactivé, la requête utilisée pour l’actualisation incrémentielle n’a pas besoin d’être entièrement repliée. Dans ce cas, la requête peut être partiellement envoyée (push) vers le système source. Nous recommandons fortement d’activer ce paramètre pour améliorer le niveau de performance et éviter de récupérer des données inutiles et non filtrées.
Limites
Seules les destinations de données SQL sont prises en charge
Actuellement, seules les destinations de données SQL sont prises en charge dans l’actualisation incrémentielle. Ainsi, vous pouvez uniquement utiliser Fabric Warehouse, la base de données Azure SQL ou Azure Synapse Analytics comme destination de données de l’actualisation incrémentielle. Cette limitation est due au fait que ces destinations de données prennent en charge les opérations SQL requises par l’actualisation incrémentielle. Nous utilisons des opérations Supprimer et Insérer pour remplacer les données dans la destination de données, ce qui ne peut pas être effectué en parallèle sur d’autres destinations de données.
La destination de données doit être définie sur un schéma fixe
La destination de données doit être définie sur un schéma fixe, ce qui signifie que le schéma de la table dans la destination de données doit être fixe et ne peut pas être modifiée. Si le schéma de la table dans la destination de données est défini sur un schéma dynamique, vous devez le modifier en un schéma fixe avant de configurer l’actualisation incrémentielle.
La seule méthode de mise à jour prise en charge dans la destination de données est replace
La seule méthode de mise à jour prise en charge dans la destination de données est replace, ce qui signifie que le flux de données remplace les données de chaque compartiment dans la destination de données par les nouvelles données. Toutefois, les données qui sont en dehors de la plage du compartiment ne sont pas affectées. Ainsi, si des données dans la destination de données sont antérieures au premier compartiment, l’actualisation incrémentielle n’affecte aucunement ces données.
Le nombre maximal de compartiments est de 50 pour une requête unique et de 150 pour l’ensemble du flux de données
Le nombre maximal de compartiments par requête que le flux de données prend charge est de 50. Si vous avez plus de 50 compartiments, vous devez augmenter la taille du compartiment ou réduire la plage du compartiment pour réduire le nombre de compartiments. Pour l’ensemble du flux de données, le nombre maximal de compartiments est de 150. Si vous avez plus de 150 compartiments dans le flux de données, vous devez réduire le nombre de requêtes d’actualisation incrémentielle ou augmenter la taille du compartiment pour réduire le nombre de compartiments.
Différences entre l’actualisation incrémentielle dans Dataflow Gen1 et dans Dataflow Gen2
Il existe des différences entre Dataflow Gen1 et Dataflow Gen2 dans le fonctionnement de l’actualisation incrémentielle. La liste suivante décrit les principales différences de l’actualisation incrémentielle entre Dataflow Gen1 et dans Dataflow Gen2.
- L’actualisation incrémentielle est désormais une fonctionnalité de première classe dans Dataflow Gen2. Dans Dataflow Gen1, vous deviez configurer l’actualisation incrémentielle une fois le flux de données publié. Dans Dataflow Gen2, l’actualisation incrémentielle est désormais une fonctionnalité de première classe que vous pouvez configurer directement dans l’éditeur de flux de données. Cette fonctionnalité facilite la configuration de l’actualisation incrémentielle et réduit le risque d’erreurs.
- Dans Dataflow Gen1, vous deviez spécifier la plage de données historiques quand vous configuriez l’actualisation incrémentielle. Dans Dataflow Gen2, vous n’avez pas besoin de spécifier la plage de données historiques. Le flux de données ne supprime aucune donnée de la destination qui se trouve en dehors de la plage du compartiment. Par conséquent, si des données dans la destination sont antérieures au premier compartiment, l’actualisation incrémentielle n’affecte aucunement ces données.
- Dans Dataflow Gen1, vous deviez spécifier les paramètres d’actualisation incrémentielle quand vous configuriez l’actualisation incrémentielle. Dans Dataflow Gen2, vous n’avez pas besoin de spécifier les paramètres d’actualisation incrémentielle. Le flux de données ajoute automatiquement les filtres et les paramètres à la dernière étape de la requête. Ainsi, vous n’avez pas besoin de spécifier les paramètres d’actualisation incrémentielle manuellement.
Questions fréquentes (FAQ)
J’ai reçu un avertissement indiquant que j’ai utilisé la même colonne pour la détection des modifications et pour le filtrage. Qu’est-ce que cela signifie ?
Si vous recevez un avertissement indiquant que vous avez utilisé la même colonne pour la détection des modifications et pour le filtrage, cela signifie que la colonne que vous avez spécifiée pour détecter les modifications est également utilisée pour filtrer les données. Nous vous déconseillons cette utilisation, car elle peut entraîner des résultats inattendus. Nous vous recommandons plutôt d’utiliser différentes colonnes pour détecter les modifications et filtrer les données. Si les données passent d’un compartiment à l’autre, le flux de données peut ne pas détecter correctement les modifications et créer des données dupliquées dans votre destination. Vous pouvez résoudre cet avertissement en utilisant différentes colonnes pour détecter les modifications et pour filtrer les données. Ou vous pouvez ignorer l’avertissement si vous êtes sûr que les données n’ont pas été modifiées entre les actualisations de la colonne que vous avez spécifiée.
Je souhaite utiliser l’actualisation incrémentielle avec une destination de données qui n’est pas prise en charge. Que puis-je faire ?
Si vous souhaitez utiliser l’actualisation incrémentielle avec une destination de données qui n’est pas prise en charge, vous pouvez activer l’actualisation incrémentielle sur votre requête et utiliser une seconde requête qui référence les données mises en lots pour mettre à jour la destination des données. De cette façon, vous pouvez continuer à utiliser l’actualisation incrémentielle pour réduire la quantité de données qui doivent être traitées et récupérées du système source, mais vous devez effectuer une actualisation complète des données mises en lots vers la destination de données. Assurez-vous de configurer correctement la taille de la fenêtre et du compartiment, car nous ne garantissons pas que les données mise en lots sont conservées en dehors de la plage du compartiment.
Comment savoir si l’actualisation incrémentielle est activée sur ma requête ?
Vous pouvez voir si l’actualisation incrémentielle est activée sur votre requête en vérifiant l’icône à côté de la requête dans l’éditeur de flux de données. Si l’icône contient un triangle bleu, l’actualisation incrémentielle est activée. Si l’icône ne contient pas de triangle bleu, l’actualisation incrémentielle n’est pas activée.
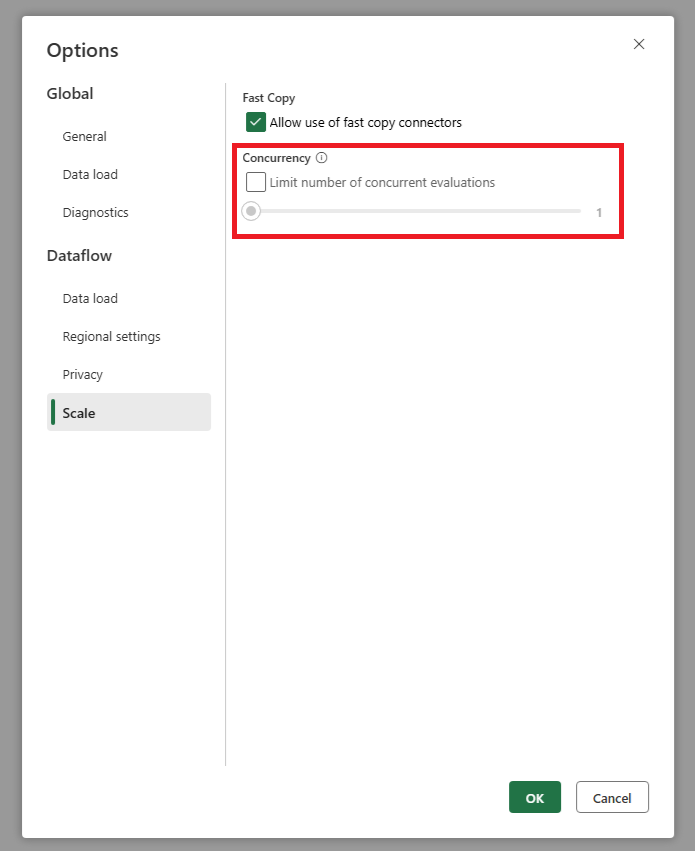
Ma source récupère trop de requêtes quand j’utilise l’actualisation incrémentielle. Que puis-je faire ?
Nous avons ajouté un paramètre qui vous permet de définir le nombre maximal d’évaluations de requêtes parallèles. Ce paramètre se trouve dans les paramètres globaux du flux de données. En définissant cette valeur sur un nombre moins élevé, vous pouvez réduire le nombre de requêtes envoyées au système source. Ce paramètre permet de réduire le nombre de requêtes simultanées et d’améliorer le niveau de performance du système source. Pour définir le nombre maximal d’exécutions de requêtes parallèles, accédez aux paramètres globaux du flux de données, puis à l’onglet Mettre à l’échelle et définissez le nombre maximal d’évaluations de requêtes parallèles. Nous recommandons de ne pas activer cette limite, sauf si vous rencontrez des problèmes avec le système source.