Passer de Dataflow Generation 1 à Dataflow Generation 2
Dataflow Gen2 est la nouvelle génération de dataflows. La nouvelle génération de dataflows réside en même temps que power BI Dataflow (Gen1) et apporte de nouvelles fonctionnalités et des expériences améliorées. La section suivante fournit une comparaison entre Dataflow Gen1 et Dataflow Gen2.
Vue d’ensemble des fonctionnalités
| Caractéristique | Dataflow Gen2 | Dataflow Gen1 |
|---|---|---|
| Créer des dataflows avec Power Query | ✓ | ✓ |
| Flux de création plus court | ✓ | |
| Enregistrement automatique et publication en arrière-plan | ✓ | |
| Destinations de données | ✓ | |
| Amélioration de la surveillance et de l'historique des actualisations | ✓ | |
| Intégration à des pipelines de données | ✓ | |
| Calcul à grande échelle | ✓ | |
| Obtenir des données via le connecteur Dataflows | ✓ | ✓ |
| Requête directe via le connecteur Dataflows | ✓ | |
| Actualisation incrémentielle | ✓ | |
| Support Insights IA | ✓ |
Expérience de création plus courte
L’utilisation de Dataflow Gen2 ressemble à rentrer à la maison. Nous avons conservé l’expérience Power Query complète que vous utilisez dans les dataflows Power BI. Lorsque vous entrez dans l’expérience, vous êtes guidé pas à pas pour obtenir les données dans votre dataflow. Nous raccourcissons également l’expérience de création pour réduire le nombre d’étapes requises pour créer des flux de données, et ajoutons quelques nouvelles fonctionnalités pour améliorer encore votre expérience.

Nouvelle expérience d’enregistrement de flux de données
Avec Dataflow Gen2, nous avons modifié la manière d'enregistrer un flux de données. Toutes les modifications apportées à un dataflow sont enregistrées automatiquement dans le cloud. Vous pouvez donc quitter l’expérience de création n’importe quand et continuer à partir de l’endroit où vous vous êtes arrêté plus tard. Une fois que vous avez terminé la création de votre dataflow, vous publiez vos modifications et ces modifications sont utilisées lors de l’actualisation du flux de données. En outre, la publication du flux de données enregistre vos modifications et exécute des validations qui doivent être effectuées en arrière-plan. Cette fonctionnalité vous permet d’enregistrer votre flux de données sans avoir à attendre la fin de la validation.
Pour en savoir plus sur la nouvelle expérience d’enregistrement, accédez à Enregistrer un brouillon de votre flux de données.
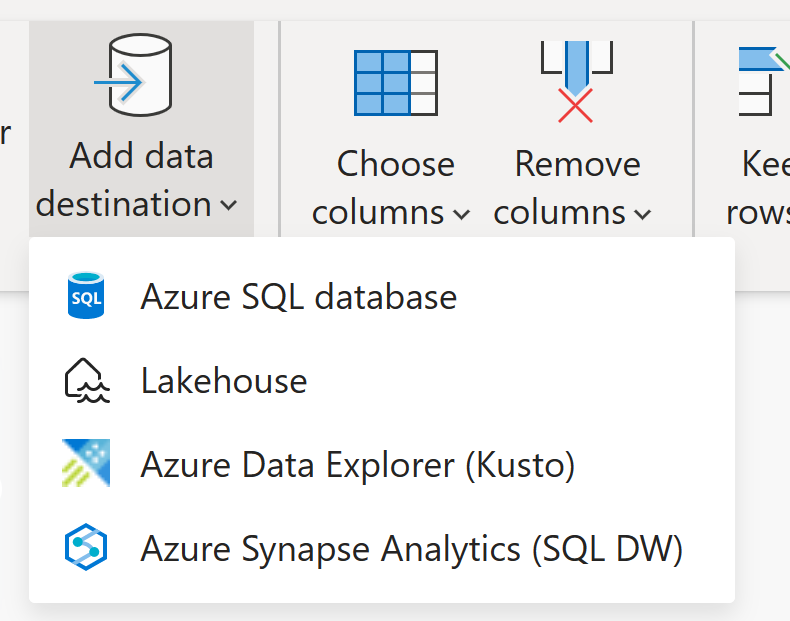
Destinations de données
À l’instar de Dataflow Gen1, Dataflow Gen2 vous permet de transformer vos données en stockage interne/intermédiaire du flux de données où il est accessible à l’aide du connecteur Dataflow. Dataflow Gen2 vous permet également de spécifier une destination de données pour vos données. À l’aide de cette fonctionnalité, vous pouvez désormais séparer votre logique ETL et votre stockage de destination. Cette fonctionnalité vous offre de nombreux avantages. Par exemple, vous pouvez maintenant utiliser un flux de données pour charger des données dans un lakehouse, puis utiliser un notebook pour analyser les données. Vous pouvez également utiliser un dataflow pour charger des données dans une base de données Azure SQL, puis utiliser un pipeline de données pour charger les données dans un entrepôt de données.
Dans Dataflow Gen2, nous avons ajouté la prise en charge des destinations suivantes et bien d’autres sont bientôt disponibles :
- Fabric Lakehouse
- Azure Data Explorer (Kusto)
- Azure Synapse Analytics (SQL DW)
- Azure SQL Database
Remarque
Pour charger vos données dans Fabric Warehouse, vous pouvez utiliser le connecteur Azure Synapse Analytics (SQL DW) en récupérant la chaîne de connexion SQL. Plus d’informations : Connectivité à l’entrepôt de données dans Microsoft Fabric
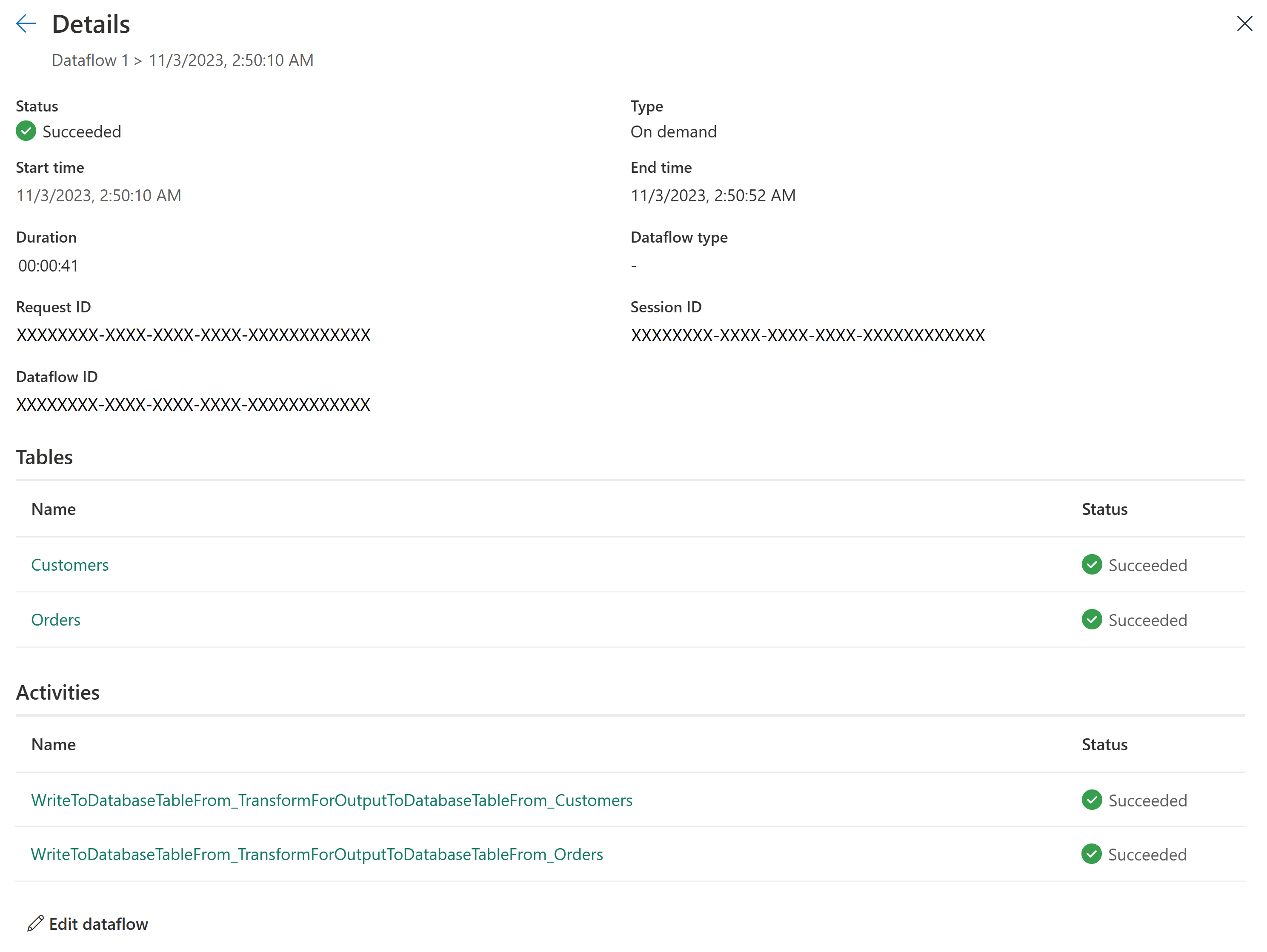
Nouvel historique d’actualisation et surveillance
Avec Dataflow Gen2, nous présentons une nouvelle façon de surveiller vos actualisations de flux de données. Nous intégrons la prise en charge de Monitoring Hub et donnons à notre expérience d’historique d’actualisation une mise à niveau majeure.
Intégration à des pipelines de données
Les pipelines de données vous permettent de regrouper des activités qui effectuent ensemble une tâche. Une activité est une unité de travail qui peut être exécutée. Par exemple, une activité peut copier des données d’un emplacement vers un autre, exécuter une requête SQL, exécuter une procédure stockée ou exécuter un notebook Python.
Un pipeline peut contenir une ou plusieurs activités connectées par des dépendances. Par exemple, vous pouvez utiliser un pipeline pour ingérer et nettoyer les données d'un blob Azure, puis lancer un Dataflow Gen2 pour analyser les données de journal. Vous pouvez également utiliser un pipeline pour copier des données d’un objet blob Azure vers une base de données Azure SQL, puis exécuter une procédure stockée sur la base de données.
Enregistrer sous forme de brouillon
Avec Dataflow Gen2, nous introduisons une expérience sans souci en supprimant la nécessité de publier pour enregistrer vos modifications. Avec la fonctionnalité d’enregistrement en brouillon, nous stockons une version brouillon de votre flux de données à chaque modification. Avez-vous perdu la connectivité Internet ? Avez-vous accidentellement fermé votre navigateur ? Aucun problème; on t’a ramenés. Une fois que vous revenez à votre dataflow, vos modifications récentes sont toujours là et vous pouvez continuer là où vous vous êtes arrêté. Il s’agit d’une expérience transparente et ne nécessite aucune entrée de votre part. Cela vous permet de travailler sur votre dataflow sans avoir à vous soucier de perdre vos modifications ou de devoir corriger toutes les erreurs de requête avant de pouvoir enregistrer vos modifications. Pour en savoir plus sur cette fonctionnalité, accédez à Enregistrer un brouillon de votre flux de données.
Calcul à grande échelle
Comme Dataflow Gen1, Dataflow Gen2 dispose également d’un moteur de calcul amélioré pour améliorer les performances des deux transformations de requêtes référencées et obtenir des scénarios de données. Pour ce faire, Dataflow Gen2 crée des éléments Lakehouse et Warehouse dans votre espace de travail et les utilise pour stocker et accéder aux données afin d’améliorer les performances de tous vos dataflows.
Licences Dataflow Gen1 et Gen2
Dataflow Gen2 est la nouvelle génération de dataflows qui réside en même temps que le dataflow Power BI (Gen1) et apporte de nouvelles fonctionnalités et des expériences améliorées. Elle nécessite une capacité Fabric ou une capacité de test Fabric. Pour mieux comprendre le fonctionnement des licences pour les flux de données, vous pouvez lire l’article suivant : concepts et licences Microsoft Fabric
Essayez Dataflow Gen2 en réutilisant vos requêtes à partir de Dataflow Gen1
Vous avez probablement de nombreuses requêtes Dataflow Gen1 et vous vous demandez comment les essayer dans Dataflow Gen2. Nous avons quelques options pour recréer vos dataflows Gen1 en tant que Dataflow Gen2.
Exporter vos requêtes Dataflow Gen1 et les importer dans Dataflow Gen2
Vous pouvez désormais exporter des requêtes dans les expériences de création Dataflow Gen1 et Gen2 et les enregistrer dans un fichier PQT, puis les importer dans Dataflow Gen2. Pour plus d’informations, accédez à Utiliser la fonctionnalité de modèle d’exportation.
Copier et coller dans Power Query
Si vous disposez d’un dataflow dans Power BI ou Power Apps, vous pouvez copier vos requêtes et les coller dans l’éditeur de votre Dataflow Gen2. Cette fonctionnalité vous permet de migrer votre dataflow vers Gen2 sans avoir à réécrire vos requêtes. Pour plus d’informations, accédez à pour copier et coller des requêtes existantes de Dataflow Gen1.