Transformer des données en exécutant une activité Azure HDInsight
L’activité Azure HDInsight dans Data Factory pour Microsoft Fabric vous permet d’orchestrer les types de tâches Azure HDInsight suivants :
- Exécuter des requêtes Hive
- Invoquer un programme MapReduce
- Exécuter des requêtes Pig
- Exécuter un programme Spark
- Exécuter un programme Hadoop Stream
Cet article décrit étape par étape comment créer une activité Azure HDInsight à l’aide de l’interface Data Factory.
Prérequis
Pour commencer, vous devez remplir les conditions préalables suivantes :
- Un compte locataire avec un abonnement actif. Créez un compte gratuitement.
- Un espace de travail est créé.
Ajouter une activité Azure HDInsight (HDI) à un pipeline avec l’interface utilisateur (IU)
Créez un nouveau pipeline de données dans votre espace de travail.
Recherchez Azure HDInsight dans la carte de l’écran d’accueil et sélectionnez-le ou sélectionnez l’activité dans la barre des activités pour l’ajouter à l’espace du pipeline.
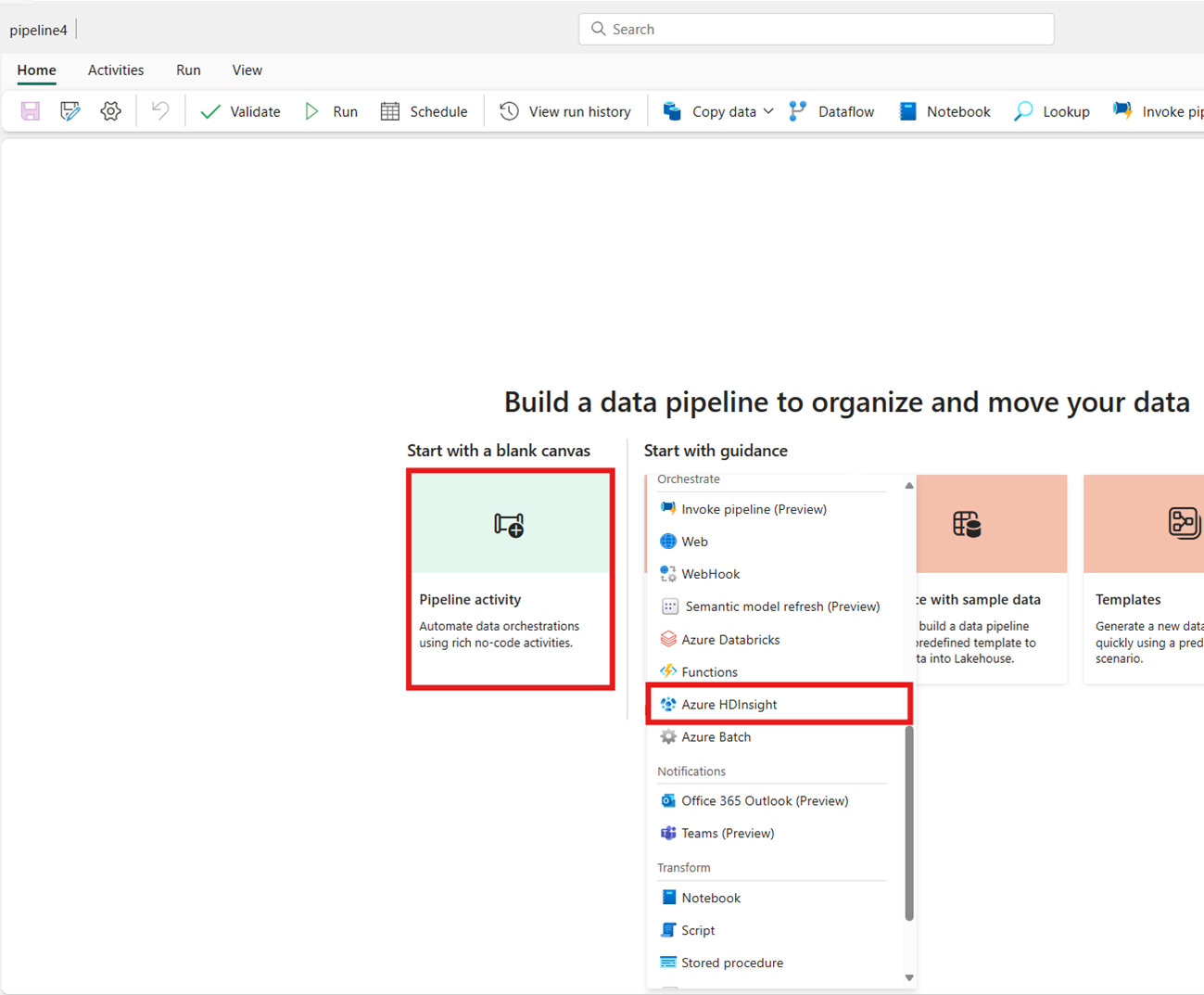
Créez l’activité à partir de la carte de l’écran d’accueil :
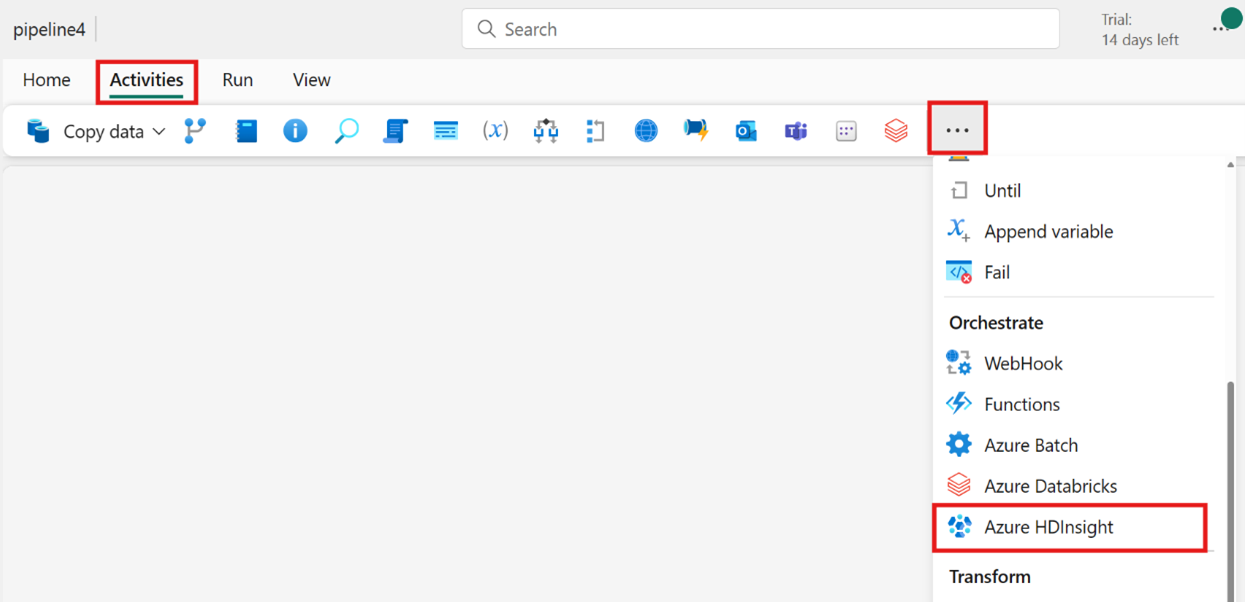
Création de l’activité à partir de la barre Activités :
Sélectionnez la nouvelle activité Azure HDInsight sur l’espace de l’éditeur de pipeline si elle n’est pas déjà sélectionnée.
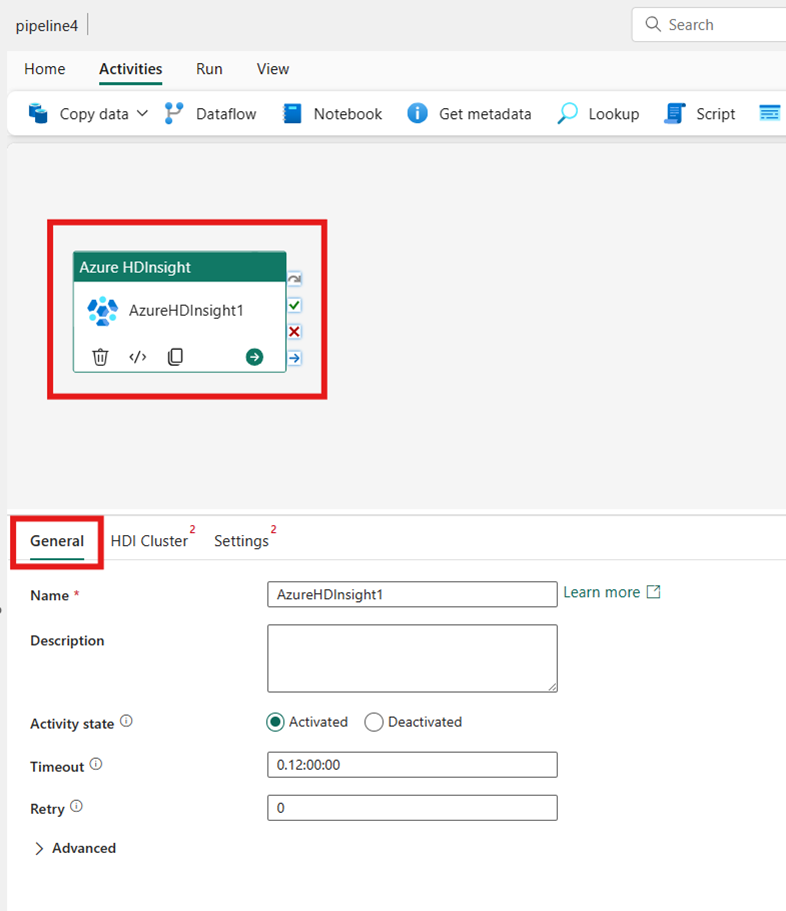
Consultez le guide des Paramètres généraux pour configurer les options de la tabulation Paramètres généraux.

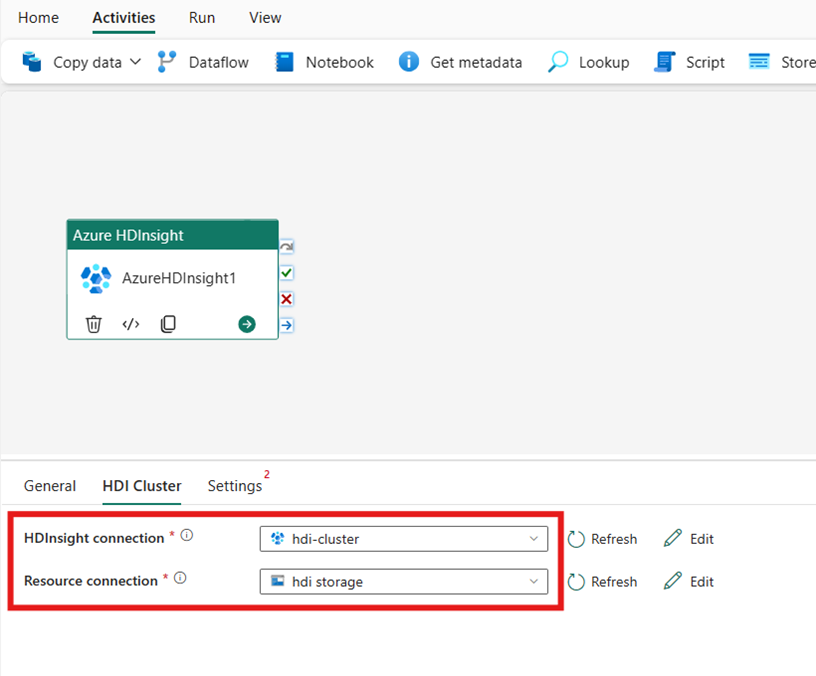
Configurer le groupement HDI
Sélectionnez la tabulation Groupement HDI. Vous pouvez ensuite choisir une connexion HDInsight existante ou en créer une.
Pour la Connexion à la ressource, choisissez le Stockage Blob Azure qui fait référence à votre groupement Azure HDInsight. Vous pouvez choisir un magasin d’objet blob existant ou en créer un.
Configurer les paramètres
Sélectionnez la tabulation Paramètres pour afficher les paramètres avancés de l’activité.
Toutes les propriétés de groupement avancées et les expressions dynamiques prises en charge dans Service lié Azure Data Factory et Synapse Analytics HDInsight sont désormais également prises en charge dans l’activité Azure HDInsight pour la fabrique de données dans Microsoft Fabric, dans la section Avancé de l’interface utilisateur (IU). Ces propriétés prennent toutes en charge des expressions paramétrables personnalisées faciles à utiliser avec du contenu dynamique.
Type de cluster
Pour configurer les paramètres de votre groupement HDInsight, choisissez d'abord son Type parmi les options disponibles, notamment Hive, Map Reduce, Pig, Spark et Streaming.
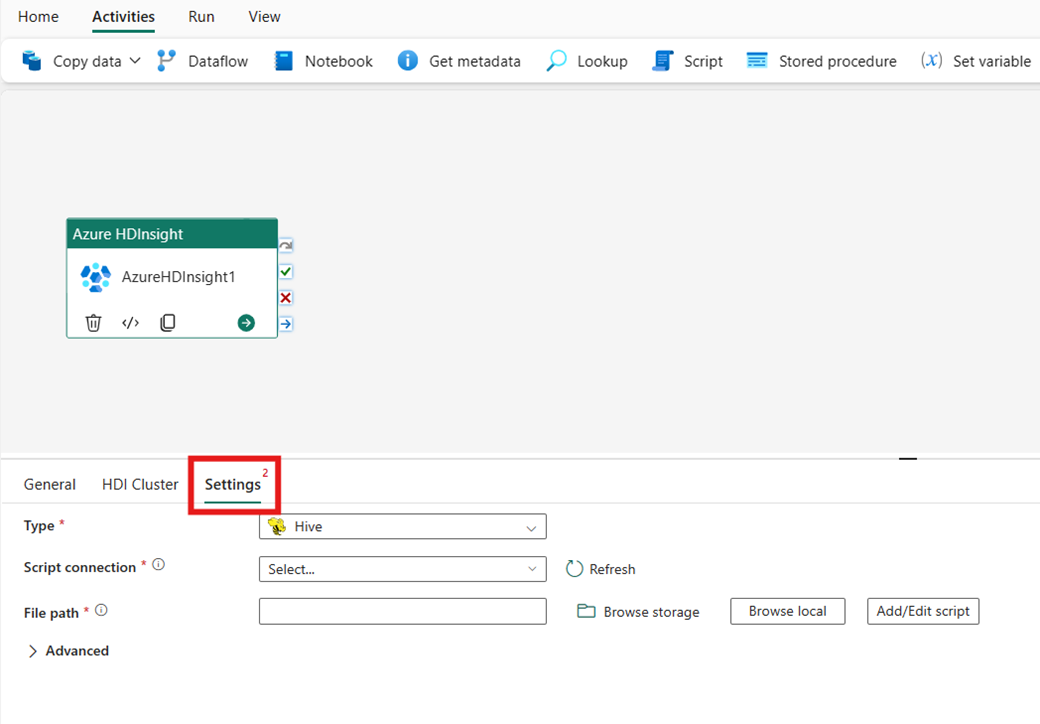
Hive
Si vous choisissez Hive pour Type, l’activité exécute une requête Hive. Vous pouvez éventuellement spécifier la Connexion Script référençant un compte de stockage qui contient le type Hive. La connexion de stockage que vous avez spécifiée dans la tabulation Groupement HDI est utilisée par défaut. Vous devez spécifier le Chemin d’accès au fichier à exécuter sur Azure HDInsight. Si vous le souhaitez, vous pouvez spécifier d’autres configurations dans la section Avancé, Informations de débogage, Délai d’expiration de la requête, Arguments, Paramètres et Variables.
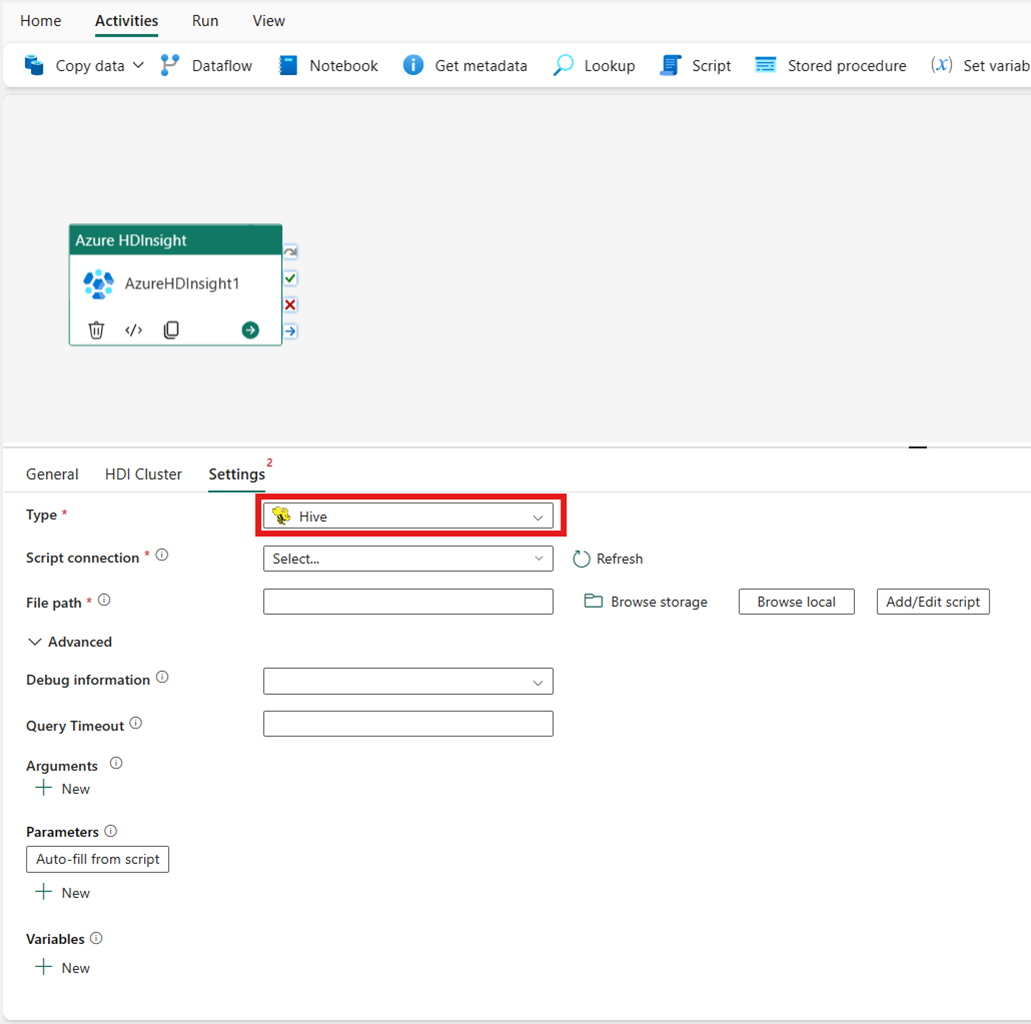
Map Reduce
Si vous choisissez Map Reduce comme Type, l’activité invoquera un programme Map Reduce. Vous pouvez éventuellement spécifier dans la connexion Jar le référencement d’un compte de stockage qui contient le type Map Reduce. La connexion de stockage que vous avez spécifiée dans la tabulation Groupement HDI est utilisée par défaut. Vous devez spécifier le Nom de la classe et le Chemin d’accès du fichier à exécuter sur Azure HDInsight. Si vous le souhaitez, vous pouvez spécifier plus de détails de configuration, comme l’importation de bibliothèques Jar, les informations de débogage, les arguments et les paramètres sous la section Avancé.
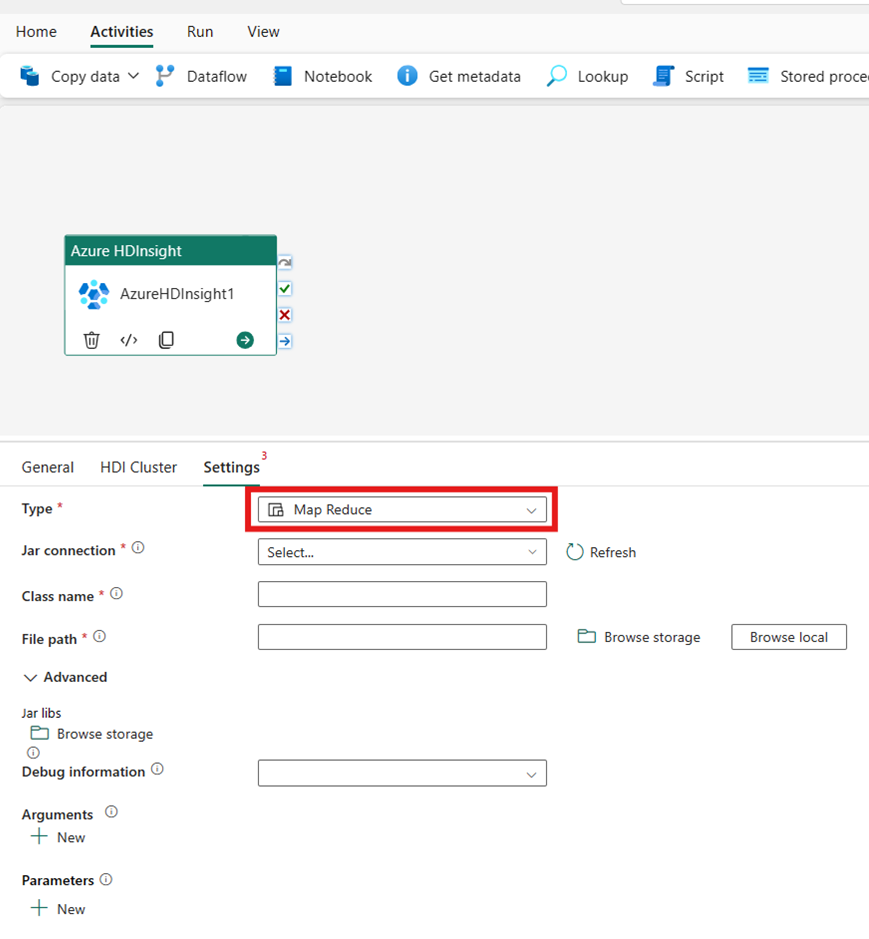
Pig
Si vous choisissez Pig comme Type, l’activité invoquera une requête Pig. Vous pouvez éventuellement spécifier le paramètre de Connexion Script qui référence le compte de stockage contenant le type Pig. La connexion de stockage que vous avez spécifiée dans la tabulation Groupement HDI est utilisée par défaut. Vous devez spécifier le Chemin d’accès au fichier à exécuter sur Azure HDInsight. Si vous le souhaitez, vous pouvez spécifier d’autres configurations, à l’instar des informations de débogage, des arguments, des paramètres et des variables dans la section Avancé.
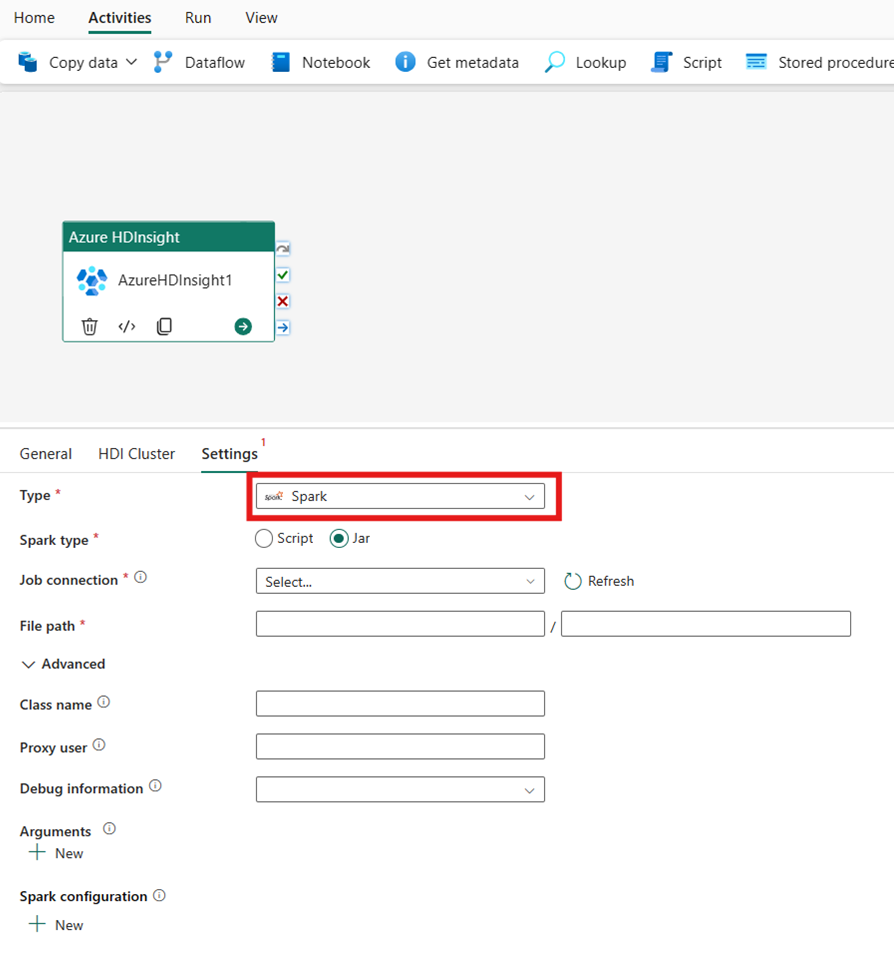
Spark
Si vous choisissez Spark comme Type, l’activité invoquera un programme Spark. Sélectionnez Script ou Jar pour le type Spark. Si vous le souhaitez, vous pouvez spécifier la Connexion Job référençant le compte de stockage qui contient le type Spark. La connexion de stockage que vous avez spécifiée dans la tabulation Groupement HDI est utilisée par défaut. Vous devez spécifier le Chemin d’accès au fichier à exécuter sur Azure HDInsight. Si vous le souhaitez, vous pouvez spécifier d’autres configurations, comme le nom de la classe, l’utilisateur du proxy, les informations de débogage, les arguments et la configuration de spark dans la section Avancé.
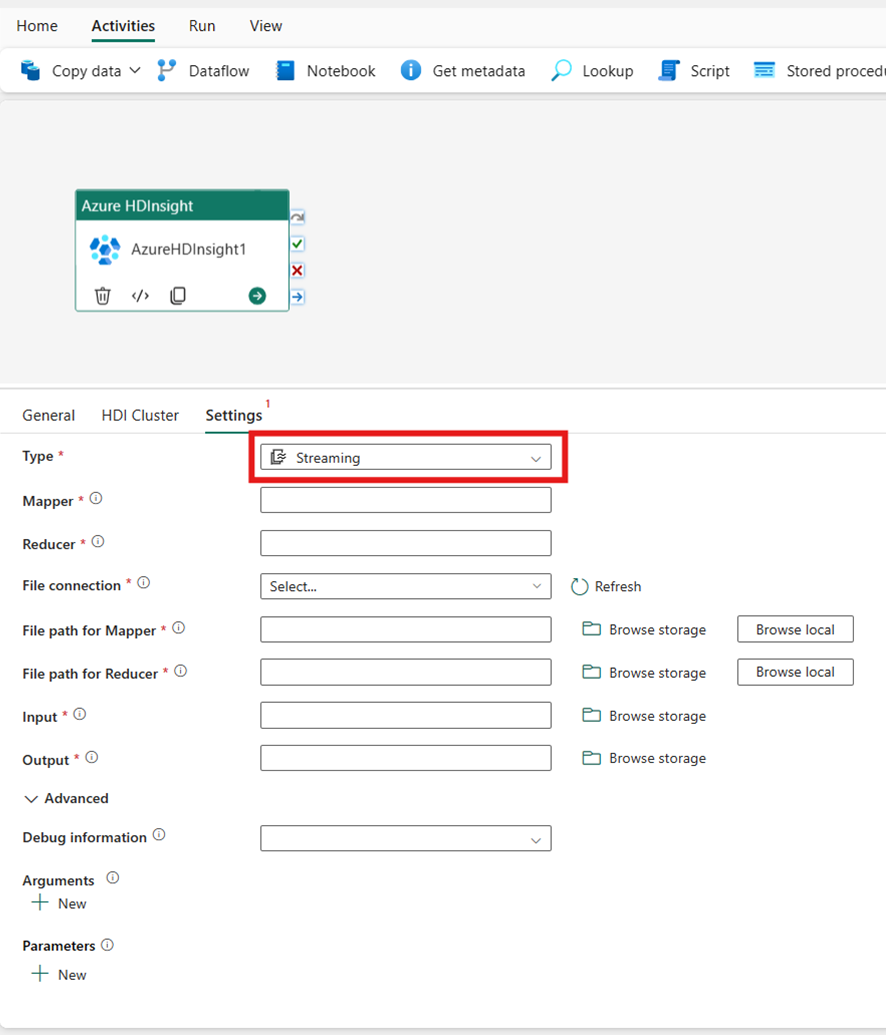
Streaming
Si vous choisissez Streaming comme Type, l’activité invoquera un programme de Streaming. Spécifiez les noms du Mappeur et du Réducteur. Vous pouvez éventuellement spécifier la Connexion File référençant le compte de stockage qui contient le type Streaming. La connexion de stockage que vous avez spécifiée dans la tabulation Groupement HDI est utilisée par défaut. Vous devez spécifier le Chemin d’accès au fichier pour le Mappeur et le Chemin d’accès au fichier pour le Réducteur à exécuter sur Azure HDInsight. Veuillez également inclure les options d’entrée et de sortie pour le chemin d’accès WASB. Si vous le souhaitez, vous pouvez spécifier d’autres configurations, comme des informations de débogage, des arguments et des paramètres dans la section Avancé.
Informations de référence sur les propriétés
| Propriété | Description | Obligatoire |
|---|---|---|
| type | Pour l’activité de diffusion en continu Hadoop, le type d’activité est HDInsightStreaming. | Oui |
| mappeur | Spécifie le nom de l’exécutable du mappeur. | Oui |
| raccord de réduction | Spécifie le nom de l’exécutable du raccord de réduction. | Oui |
| combinateur | Spécifie le nom de l’exécutable du combinateur. | Non |
| Connexion de fichiers | Référence à un service lié de stockage Azure utilisée pour stocker les programmes du mappeur, du combinateur et du raccord de réduction à exécuter. | Non |
| Seules les connexions de Stockage Blob Azure et ADLS Gen2 sont prises en charge ici. Si vous ne spécifiez pas cette connexion, la connexion de stockage définie dans la connexion HDInsight sera utilisée. | ||
| filePath | Fournissez un tableau de chemin d’accès aux programmes du Mappeur, du Combiner et du Réducteur stockés dans le stockage Azure auquel se réfère la connexion de fichier. | Oui |
| entrée | Spécifie le chemin WASB vers le fichier d’entrée du mappeur. | Oui |
| sortie | Spécifie le chemin WASB vers le fichier de sortie du raccord de réduction. | Oui |
| getDebugInfo | Spécifie quand les fichiers journaux sont copiés vers le stockage Azure utilisé par le cluster HDInsight (ou) spécifié par scriptLinkedService. | Non |
| Valeurs autorisées : None, Always ou Failure. Valeur par défaut : Aucun. | ||
| arguments | Spécifie un tableau d’arguments pour un travail Hadoop. Les arguments sont passés sous la forme d’arguments de ligne de commande à chaque tâche. | Non |
| defines | Spécifier les paramètres sous forme de paires clé/valeur pour le référencement au sein du script Hive. | Non |
Enregistrer et exécuter ou planifier le pipeline
Après avoir configuré toutes les autres activités requises pour votre pipeline, basculez vers l’onglet Accueil en haut de l’éditeur de pipeline et sélectionnez le bouton Enregistrer pour enregistrer votre pipeline. Sélectionnez Exécuter pour l'exécuter directement ou Planifier pour le planifier. Vous pouvez également afficher l'historique d'exécution ici ou configurer d'autres paramètres.
