Utiliser l’API Livy pour soumettre et exécuter des travaux Spark
Remarque
L’API Livy pour Ingénieurs de données Fabric est en préversion.
S’applique à :✅ l’engineering et la science des données dans Microsoft Fabric
Prise en main de l’API Livy pour les Ingénieurs de données Fabric en créant un Lakehouse ; authentification avec un jeton d’application Microsoft Entra ; soumission de travaux de traitement par lots ou de session à partir d’un client distant vers le calcul Fabric Spark. Vous découvrirez le point de terminaison de l’API Livy ; envoyer des travaux ; et surveillez les résultats.
Prérequis
Capacité Fabric Premium ou d’essai avec un Lakehouse
Activer le Paramètre administrateur client pour l’API Livy (préversion)
Un client distant tel que Visual Studio Code avec prise en charge de Jupyter Notebooks, de PySpark et de la bibliothèque d’authentification Microsoft (MSAL) pour Python
Un jeton d’app Microsoft Entra est nécessaire pour accéder à l’API REST Fabric. Inscrire une application avec la plateforme d’identités Microsoft
Choix d’un client d’API REST
Vous pouvez utiliser différents langages de programmation ou clients GUI pour interagir avec les points de terminaison d’API REST. Dans cet article, nous utilisons Visual Studio Code. Visual Studio Code doit être configuré avec Jupyter Notebooks, PySpark et la bibliothèque d’authentification Microsoft (MSAL) pour Python
Comment autoriser les demandes de l’API Livy
Pour utiliser des API Fabric, notamment l’API Livy, vous devez d’abord créer une application Microsoft Entra et obtenir un jeton. Votre application doit être inscrite et configurée de manière appropriée pour effectuer des appels d’API à partir de Fabric. Pour plus d’informations, consultez Inscrire une application auprès de la plateforme d’identités Microsoft.
De nombreuses autorisations d’étendue Microsoft Entra sont requises pour exécuter des travaux Livy. Cet exemple utilise du code Spark simple + accès au stockage + SQL :
- Code.AccessAzureDataExplorer.All
- Code.AccessAzureDataLake.All
- Code.AccessAzureKeyvault.All
- Code.AccessFabric.All
- Code.AccessStorage.All
- Item.ReadWrite.All
- Lakehouse.Execute.All
- Lakehouse.Read.All
- Workspace.ReadWrite.All

Remarque
Dans le cadre de la préversion publique, nous allons ajouter quelques étendues granulaires. Si vous utilisez cette approche, votre application Livy s’arrête lors de cet ajout. Vérifiez cette liste, car elle sera mise à jour et reprendra les étendues supplémentaires.
Certains clients souhaitent des autorisations plus granulaires que dans la liste précédente. Vous pouvez supprimer Item.ReadWrite.All et remplacer par ces autorisations d’étendue plus granulaires :
- Code.AccessAzureDataExplorer.All
- Code.AccessAzureDataLake.All
- Code.AccessAzureKeyvault.All
- Code.AccessFabric.All
- Code.AccessStorage.All
- Lakehouse.Execute.All
- Lakehouse.ReadWrite.All
- Workspace.ReadWrite.All
- Notebook.ReadWrite.All
- SparkJobDefinition.ReadWrite.All
- MLModel.ReadWrite.All
- MLExperiment.ReadWrite.All
- Dataset.ReadWrite.All
Une fois votre application enregistrée, vous aurez besoin de l’ID d’application (client) et de l’ID du répertoire (locataire).
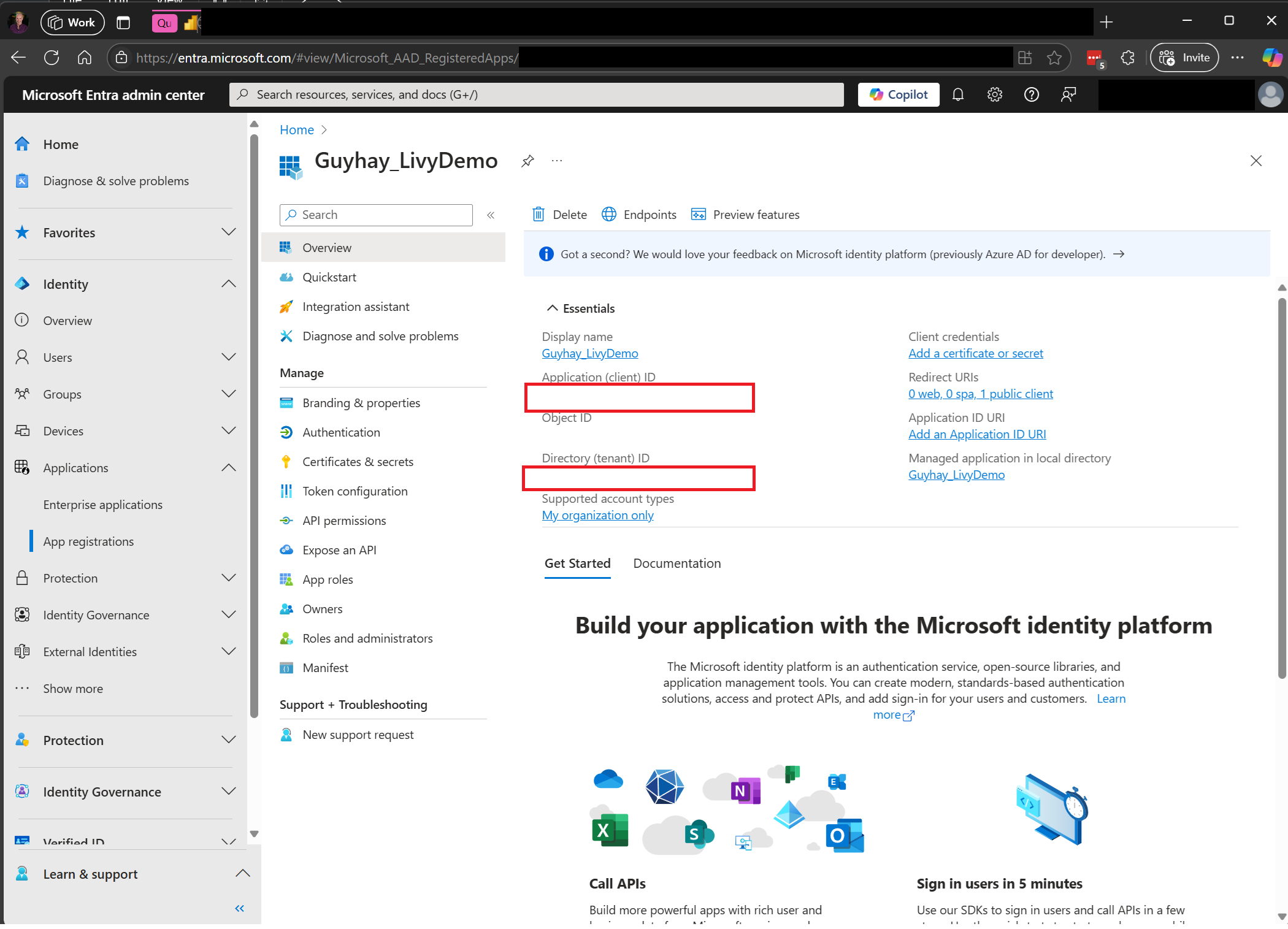
L’utilisateur authentifié appelant l’API Livy doit être membre de l’espace de travail où se trouvent à la fois l’API et les éléments de source de données avec un rôle Collaborateur. Pour plus d’informations, consultez Accorder aux utilisateurs l’accès aux espaces de travail.
Comment découvrir le point de terminaison de l’API Fabric Livy
Un artefact Lakehouse est requis pour accéder au point de terminaison Livy. Une fois le Lakehouse créé, le point de terminaison de l’API Livy peut se trouver dans le panneau des paramètres.

Le point de terminaison de l’API Livy suit ce modèle :
https://api.fabric.microsoft.com/v1/workspaces/<ws_id>/lakehouses/<lakehouse_id>/livyapi/versions/2023-12-01/
L’URL est ajoutée avec des <sessions> ou des <lots> en fonction de ce que vous choisissez.
Intégration à des environnements Fabric
Pour chaque espace de travail Fabric, un pool de démarrage par défaut est configuré. L’exécution de l’ensemble du code Spark utilise ce pool de démarrage par défaut. Vous pouvez utiliser des environnements Fabric pour personnaliser les travaux Spark de l’API Livy.
Télécharger les fichiers Swagger de l’API Livy
Les fichiers swagger complets de l’API Livy sont disponibles ici.
Soumettre des travaux de l’API Livy
Maintenant que la configuration de l’API Livy est terminée, vous pouvez choisir d’envoyer des tâches de traitement par lots ou de session.
- Soumettre des travaux par session en utilisant l’API Livy
- Soumettre des travaux par lot en utilisant l’API Livy
Comment surveiller l’historique des requêtes
Vous pouvez utiliser le hub de surveillance pour afficher vos soumissions précédentes de l’API Livy et déboguer les erreurs de soumission.

Contenu connexe
- Documentation de l’API REST Apache Livy
- Prise en main des paramètres d’administration pour votre capacité Fabric
- Paramètres d’administration de l’espace de travail Apache Spark dans Microsoft Fabric
- Inscrire une application avec la plateforme d’identités Microsoft
- Vue d’ensemble de l’autorisation et du consentement Microsoft Entra
- Étendues de l’API REST Fabric
- Vue d’ensemble de la supervision d'Apache Spark
- Détails sur les applications Apache Spark