Mettre à niveau et mettre à jour des clusters Azure Service Fabric
Un cluster Azure Service Fabric est une ressource que vous possédez mais qui est en partie gérée par Microsoft. Cet article décrit les options permettant de mettre à jour votre cluster Azure Service Fabric.
Mises à niveau automatiques et mises à niveau manuelles
Il est essentiel de vous assurer que votre cluster Service Fabric exécute toujours une version de runtime prise en charge. Chaque fois que Microsoft annonce le lancement d’une nouvelle version de Service Fabric, la fin de la prise en charge de la version précédente est signalée 60 jours minimum après la date de lancement. Les nouvelles versions sont annoncées sur le blog de l’équipe Service Fabric.
Un événement d’intégrité est généré quatorze jours avant la date d’expiration de la version qu’exécute votre cluster. Il place le cluster dans un état d’Avertissement. Ce dernier conserve cet état tant que vous n’avez pas effectué de mise à niveau vers une version de runtime prise en charge.
Vous pouvez définir votre cluster de façon à recevoir des mises à niveau automatiques de Service Fabric dès qu’elles sont publiées par Microsoft, ou vous pouvez choisir manuellement parmi une liste de versions actuellement prises en charge. Ces options sont disponibles dans la section Mises à niveau de Fabric de votre ressource de cluster Service Fabric.
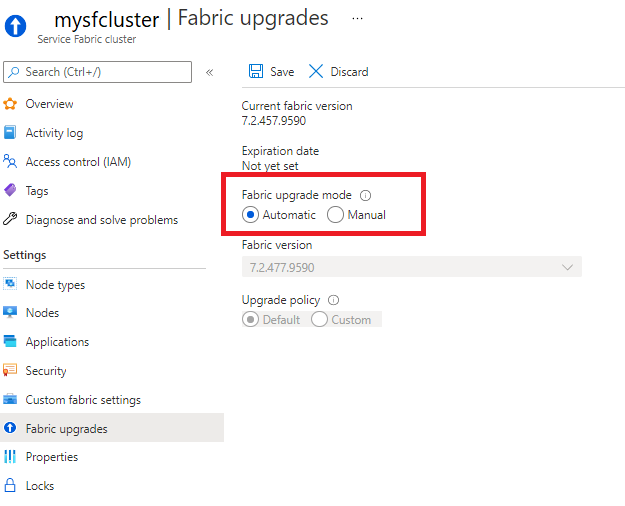
Vous pouvez également définir le mode de mise à niveau du cluster et sélectionner une version du runtime à l’aide d’un modèle Resource Manager.
Les mises à niveau automatiques sont le mode de mise à niveau recommandé, car cette option garantit que votre cluster reste dans un état pris en charge et bénéficie des derniers correctifs et fonctionnalités tout en vous permettant de planifier les mises à jour de manière moins perturbatrice pour vos charges de travail à l’aide d’une stratégie de déploiement Wave.
Notes
Si vous faites passer un cluster existant en mode automatique, le cluster sera inscrit pour la prochaine période de mise à niveau commençant avec une nouvelle version. Les nouvelles versions sont annoncées sur le blog de l’équipe Service Fabric. Par période de mise à niveau, le chemin de mise à niveau le plus élevé possible est choisi. Voir les versions prises en charge. Le mode de mise à niveau manuelle déclenche une mise à niveau immédiate.
Déploiement Wave pour les mises à niveau automatiques
Avec le déploiement Wave, vous pouvez réduire les perturbations d’une mise à niveau de votre cluster en sélectionnant le niveau de maturité d’une mise à niveau, en fonction de votre charge de travail. Par exemple, vous pouvez configurer un pipeline de déploiement Wave Test ->Intermédiaire ->Production pour vos différents clusters Service Fabric afin de tester la compatibilité d’une mise à niveau du runtime avant de l’appliquer à vos charges de travail de production.
Pour vous abonner au déploiement Wave, spécifiez l’une des valeurs Wave suivantes pour votre cluster (dans son modèle de déploiement) :
- Wave 0 : les clusters sont mis à jour dès qu’une nouvelle génération de Service Fabric est lancée. Destiné aux clusters de test/développement.
- Wave 1 : les clusters sont mis à jour une semaine (sept jours) après la publication d’une nouvelle build. Destiné aux clusters de pré-production et intermédiaires.
- Wave 2 : les clusters sont mis à jour deux semaines (14 jours) après la publication d’une nouvelle build. Destiné aux clusters de production.
Vous pouvez vous inscrire aux notifications par e-mail avec des liens pour obtenir de l’aide en cas d’échec d’une mise à niveau du cluster. Pour commencer, consultez Déploiement Wave pour les mises à niveau automatiques.
Phases de mise à niveau automatique
Microsoft tient à jour le code du runtime Service Fabric et la configuration exécutés dans un cluster Azure. Nous effectuons des mises à niveau surveillées automatiquement du logiciel en fonction des besoins. Ces mises à niveau peuvent concerner le code, la configuration ou les deux. Pour réduire l’impact de ces mises à niveau sur vos applications, elles sont exécutées dans les phases suivantes :
Phase 1 : Une mise à niveau est effectuée à l'aide de toutes les stratégies d'intégrité du cluster
Pendant cette phase, les mises à niveau traitent un domaine de mise à niveau à la fois et les applications qui étaient en cours d'exécution dans le cluster continuent à fonctionner sans interruption. Les stratégies d’intégrité du cluster (pour l’intégrité du nœud et l’intégrité de l’application) sont respectées pendant la mise à niveau.
Si les stratégies d’intégrité du cluster ne sont pas satisfaites, la mise à niveau est annulée et un e-mail est envoyé au propriétaire de l’abonnement. Le message électronique contient les informations suivantes :
- Une notification indiquant que nous avons dû annuler une mise à niveau du cluster.
- Des suggestions d'actions correctives, le cas échéant.
- Le nombre de jours (n) avant l’exécution de la Phase 2.
Nous essayons d'exécuter la même mise à niveau plusieurs fois dans le cas où les mises à niveau ont échoué pour des raisons d'infrastructure. Après le délai de n jours à partir de la date d’envoi de l’e-mail, nous passons à la Phase 2.
Si les stratégies d'intégrité du cluster sont respectées, la mise à niveau est considérée comme réussie et marquée comme terminée. Cette situation peut se produire pendant la première exécution ou l’une des exécutions de la mise à niveau suivantes dans cette phase. Il n’y a aucune confirmation par e-mail d’une exécution réussie, afin d’éviter d’envoyer un nombre excessif d’e-mails. La réception d’un e-mail indique une exception au fonctionnement normal. Nous pensons que la plupart des mises à niveau du cluster s'exécuteront sans affecter la disponibilité de votre application.
Phase 2 : Une mise à niveau est effectuée à l'aide des stratégies d'intégrité par défaut uniquement
Les stratégies d’intégrité de cette phase sont définies de telle sorte que le nombre d’applications intègres au début de la mise à niveau reste identique pendant la durée de la mise à niveau. Comme lors de la Phase 1, les mises à niveau de la Phase 2 traitent un domaine de mise à niveau à la fois et les applications qui étaient en cours d'exécution dans le cluster continuent à fonctionner sans interruption. Les stratégies de contrôle d’intégrité du cluster (combinaison de l’intégrité des nœuds et de l’intégrité de toutes les applications en cours d’exécution dans le cluster) sont respectées pendant la mise à niveau.
Si les stratégies d'intégrité de cluster en vigueur ne sont pas respectées, la mise à niveau est annulée. Un message électronique est envoyé au propriétaire de l’abonnement. Le message électronique contient les informations suivantes :
- Une notification indiquant que nous avons dû annuler une mise à niveau du cluster.
- Des suggestions d'actions correctives, le cas échéant.
- Le nombre de jours (n) avant l’exécution de la Phase 3.
Nous essayons d'exécuter la même mise à niveau plusieurs fois dans le cas où les mises à niveau ont échoué pour des raisons d'infrastructure. Un message électronique de rappel est envoyé deux jours avant que le délai de n jours ne soit écoulé. Après le délai de n jours à partir de la date d'envoi du message électronique, nous passons à la Phase 3. Les messages électroniques que nous vous envoyons lors de la Phase 2 doivent être pris au sérieux et des actions correctives doivent être prises.
Si les stratégies d'intégrité du cluster sont respectées, la mise à niveau est considérée comme réussie et marquée comme terminée. Cela peut se produire pendant la première exécution ou l'une des exécutions de la mise à niveau suivantes dans cette phase. Aucun message électronique de confirmation d'une exécution réussie n'est envoyé.
Phase 3 : Une mise à niveau est effectuée à l'aide de stratégies d'intégrité agressives
Les stratégies d'intégrité de cette phase visent à compléter la mise à niveau plutôt qu’à protéger l'intégrité des applications. Peu de mises à niveau de cluster se terminent par cette phase. Si votre cluster atteint cette phase, il est très probable que votre application devienne défectueuse et/ou ne soit plus disponible.
Comme pour les deux autres phases, les mises à niveau de la Phase 3 traitent un domaine de mise à niveau à la fois.
Si les stratégies d'intégrité du cluster ne sont pas respectées, la mise à niveau est annulée. Nous essayons d'exécuter la même mise à niveau plusieurs fois dans le cas où les mises à niveau ont échoué pour des raisons d'infrastructure. Après cela, le cluster est épinglé et il ne bénéficiera plus des mises à niveau et/ou du support.
Un message électronique contenant ces informations est envoyé au propriétaire de l’abonnement, ainsi que les actions correctives. Nous pensons qu'aucun cluster ne sera confronté à un échec de la Phase 3.
Si les stratégies d'intégrité du cluster sont respectées, la mise à niveau est considérée comme réussie et marquée comme terminée. Cela peut se produire pendant la première exécution ou l'une des exécutions de la mise à niveau suivantes dans cette phase. Aucun message électronique de confirmation d'une exécution réussie n'est envoyé.
Stratégies personnalisées pour les mises à niveau manuelles
Vous pouvez spécifier des stratégies personnalisées pour les mises à niveau manuelles de cluster. Ces stratégies sont appliquées chaque fois que vous sélectionnez une nouvelle version du runtime, ce qui déclenche le lancement de la mise à niveau de votre cluster par le système. Si vous ne remplacez pas les stratégies, les valeurs par défaut sont utilisées. Pour plus d’informations, consultez Définir des stratégies personnalisées pour les mises à niveau manuelles.
Autres mises à jour du cluster
En dehors de la mise à niveau du runtime, vous devrez peut-être effectuer un certain nombre d’autres actions pour maintenir votre cluster à jour, y compris les suivantes :
Gestion des certificats
Service Fabric utilise les certificats de serveur X.509 que vous spécifiez lorsque vous créez un cluster pour sécuriser les communications entre les nœuds du cluster et authentifier les clients. Vous pouvez ajouter, mettre à jour ou supprimer des certificats pour le cluster et le client dans le portail Azure ou à l’aide de l’interface de ligne de commande Azure ou PowerShell. Pour en savoir plus, consultez Ajouter ou supprimer des certificats.
Ouverture des ports d’application
Vous pouvez modifier les ports d'application en modifiant les propriétés de ressource d'équilibrage de charge associées au type de nœud. Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande Azure ou PowerShell. Pour plus d’informations, consultez Ouvrir des ports d’application pour un cluster.
Définition des propriétés d’un nœud
Parfois, vous voulez garantir que certaines charges de travail s’exécutent uniquement sur certains types de nœud du cluster. Par exemple, certaines charges de travail peuvent nécessiter des GPU ou des SSD, tandis que d’autres n’en ont pas besoin. Pour chacun de ces types de nœud d’un cluster, vous pouvez ajouter des propriétés de nœud personnalisées aux nœuds du cluster. Les contraintes de placement sont les instructions associées aux différents services que vous sélectionnez pour une ou plusieurs propriétés de nœud. Les contraintes de placement définissent là où les services doivent s’exécuter.
Pour plus de détails sur l’utilisation des contraintes de placement, les propriétés de nœud et la manière de les définir, consultez Propriétés de nœud et contraintes de placement.
Ajout de métriques de capacité
Pour chaque type de nœud, vous pouvez ajouter des mesures de capacité personnalisées que vous souhaitez utiliser dans vos applications pour créer un rapport sur la charge. Pour plus d’informations sur l’utilisation de métriques de capacité pour créer un rapport sur la charge, consultez les documents Gestionnaire de ressources de cluster Service Fabric sur la Description de votre cluster et les Métriques et charge.
Personnalisation des paramètres de votre cluster
De nombreux paramètres de configuration différents peuvent être personnalisés sur un cluster, tels que le niveau de fiabilité des propriétés du cluster et des nœuds. Pour plus d’informations, consultez Paramètres de structure du cluster Service Fabric.
Remarque
Pour les clusters utilisant des versions de runtime antérieures à 10.0CU6, 10.1CU5 et 9.1CU12, si vous avez modifié ou envisagez de modifier les paramètres NTLM pour FileStoreService, attendez-vous à un temps d’arrêt pendant le redémarrage des nœuds de votre cluster. Ce redémarrage est lié au nettoyage qui se produit pendant le cycle de mise à niveau.
Ce comportement change à partir de 10.0CU6, 10.1CU5 et 9.1CU12, et aucun redémarrage de nœud ne doit se produire sur les clusters exécutant ces versions ou les versions ultérieures.
Pour plus d’informations sur la gestion de versions de Service Fabric, consultez la page des versions.
Mise à niveau des images de système d’exploitation pour les nœuds de cluster
L’activation des mises à niveau automatiques des images de système d’exploitation pour vos nœuds de cluster Service Fabric est une bonne pratique. Pour ce faire, il existe plusieurs exigences en matière de cluster et étapes à suivre. Une autre option consiste à utiliser l’application d’orchestration des correctifs, une application Service Fabric qui automatise l’application de correctifs du système d’exploitation sur un cluster Service Fabric sans temps d’arrêt. Pour en savoir plus sur ces options, consultez Corriger le système d’exploitation Windows dans votre cluster Service Fabric.