Décrire un cluster Service Fabric à l’aide de Cluster Resource Manager
La fonctionnalité Cluster Resource Manager d’Azure Service Fabric fournit plusieurs mécanismes permettant de décrire un cluster :
- Domaines d’erreur
- Domaines de mise à niveau
- Propriétés du nœud
- Capacités du nœud
Pendant l’exécution, Cluster Resource Manager utilise ces informations pour garantir une haute disponibilité des services en cours d’exécution dans le cluster. Tout en appliquant ces règles importantes, il essaie aussi d’optimiser la consommation des ressources au sein du cluster.
Domaines d’erreur
Un domaine d’erreur est une zone d’échec coordonné. Une machine unique constitue un domaine d’erreur. Elle peut cesser de fonctionner de manière indépendante pour de nombreuses raisons : coupure électrique, défaillance de disque ou erreur de microprogramme de carte d’interface réseau.
Les machines connectées au même commutateur Ethernet se trouvent dans le même domaine d’erreur. C’est aussi le cas des machines qui partagent la même source d’alimentation ou qui se trouvent au même emplacement.
Dans la mesure où le chevauchement des défaillances matérielles est naturel, les domaines d’erreur sont hiérarchiques par nature. Ils sont représentés en tant qu’URI dans Service Fabric.
Il est important que les domaines d’erreur soient configurés correctement, car Service Fabric utilise ces informations pour placer les services en toute sécurité. Service Fabric ne souhaite pas placer les services de telle sorte que la perte d’un domaine d’erreur (provoquée par la défaillance d’un composant) entraîne l’arrêt d’un service.
Dans l’environnement Azure, Service Fabric utilise les informations de domaine d’erreur fournies par l’environnement pour configurer correctement les nœuds du cluster en votre nom. Pour les instances autonomes de Service Fabric, les domaines d’erreur sont définis au moment où le cluster est configuré.
Avertissement
Il est important que les informations de domaine d’erreur fournies à Service Fabric soient précises. Par exemple, supposez que les nœuds de votre cluster Service Fabric s’exécutent à l’intérieur de 10 machines virtuelles, s’exécutant sur cinq hôtes physiques. Dans ce cas, même s’il y a 10 ordinateurs virtuels, il y a seulement 5 domaines d’erreur (de niveau supérieur) différents. Le partage d’un même hôte physique amène les machines virtuelles à partager le même domaine d’erreur racine, car les machines virtuelles subissent une défaillance coordonnée si leur hôte physique subit une défaillance.
Service Fabric s’attend à ce que le domaine d’erreur d’un nœud ne change pas. D’autres mécanismes visant à garantir la haute disponibilité des machines virtuelles, tels que HA-VM, peuvent provoquer des conflits avec Service Fabric. Ces mécanismes utilisent une migration transparente des machines virtuelles d’un hôte vers un autre. Ils ne reconfigurent ni ne notifient le code s’exécutant dans la machine virtuelle. À ce titre, ils ne sont pas pris en charge en tant qu’environnements d’exécution de clusters Service Fabric.
Service Fabric doit être la seule technologie de haute disponibilité employée. Les mécanismes tels que la migration dynamique de machines virtuelles et les SAN ne sont pas nécessaires. Si ces mécanismes sont utilisés conjointement avec Service Fabric, ils réduisent la disponibilité et la fiabilité des applications. En effet, ils introduisent une complexité supplémentaire, ajoutent des sources de défaillance centralisées et utilisent des stratégies de fiabilité et de disponibilité qui sont en conflit avec celles de Service Fabric.
Dans le graphique suivant, nous avons indiqué en couleur toutes les entités qui contribuent aux domaines d’erreur et nous avons listé tous les domaines d’erreur différents qui en résultent. Dans cet exemple, nous avons des centres de données (« DC »), des racks (« R ») et des panneaux (« B »). Si chaque panneau contient plusieurs machines virtuelles, il peut exister une autre couche dans la hiérarchie de domaine d’erreur.
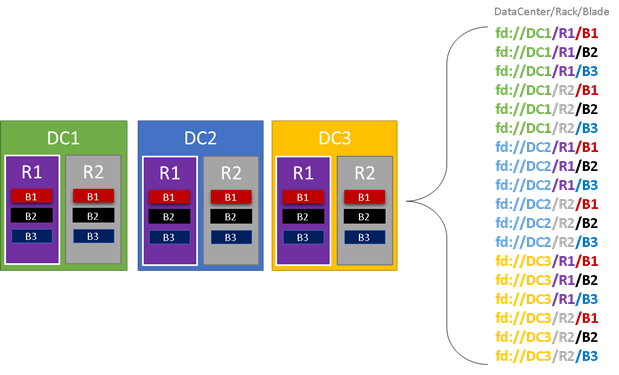
Pendant l’exécution, Service Fabric Cluster Resource Manager prend en compte les domaines d’erreur du cluster et planifie des dispositions. Les réplicas avec état ou les instances sans état d’un service sont répartis de sorte qu’ils se trouvent dans des domaines d’erreur distincts. La répartition du service entre les domaines d’erreur est l’assurance que la disponibilité du service n’est pas mise à mal quand un domaine d’erreur connaît une défaillance à n’importe quel niveau de la hiérarchie.
Cluster Resource Manager ne se soucie pas du nombre de couches dans la hiérarchie du domaine d’erreur. Il essaie de faire en sorte que la perte d’une partie de la hiérarchie n’affecte pas les services qui s’y exécutent.
Il est préférable d’avoir le même nombre de nœuds à chaque niveau de profondeur dans la hiérarchie du domaine d’erreur. Si « l’arborescence » des domaines d’erreur est déséquilibrée dans votre cluster, il est plus difficile pour Cluster Resource Manager de déterminer la meilleure allocation de services. Des dispositions déséquilibrées de domaines d’erreur signifient que la perte de certains domaines affecte la disponibilité des services davantage que d’autres domaines. Par conséquent, Cluster Resource Manager est partagé entre deux objectifs :
- Il souhaite utiliser les machines dans ce domaine « lourd » en y plaçant des services.
- Il souhaite placer des services dans d’autres domaines afin que la perte d’un domaine n’entraîne pas de problèmes.
À quoi ressemblent des domaines déséquilibrés ? Le diagramme suivant montre deux dispositions de cluster différentes. Dans le premier exemple, les nœuds sont répartis uniformément entre les domaines d’erreur. Dans le deuxième exemple, un domaine d’erreur contient beaucoup plus de nœuds que les autres domaines d’erreur.
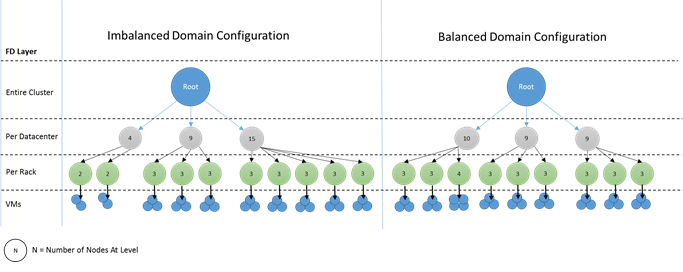
Dans Azure, le choix du domaine d’erreur qui contient un nœud est géré automatiquement. Mais en fonction du nombre de nœuds que vous configurez, vous pouvez malgré tout vous retrouver avec des domaines d’erreur contenant plus de nœuds que d’autres.
Supposez, par exemple, que vous avez cinq domaines d’erreur dans le cluster, mais que vous provisionnez sept nœuds pour un type de nœud (NodeType) donné. Dans ce cas, les deux premiers domaines d’erreur se retrouvent avec davantage de nœuds. Si vous continuez à déployer plus d’instances de NodeTypes avec seulement deux instances, le problème s’aggrave. C’est pourquoi le nombre de nœuds dans chaque type de nœud doit de préférence être un multiple du nombre de domaines d’erreur.
Domaines de mise à niveau
Les domaines de mise à niveau correspondent à une autre fonctionnalité qui permet à Service Fabric Cluster Resource Manager de comprendre la disposition du cluster. Les domaines de mise à niveau définissent des ensembles de nœuds qui sont mis à niveau en même temps. Les domaines de mise à niveau aident Cluster Resource Manager à comprendre et à orchestrer les opérations de gestion telles que les mises à niveau.
Les domaines de mise à niveau sont très semblables aux domaines d’erreur, avec cependant quelques différences clés. Tout d’abord, les zones de défaillances matérielles coordonnées définissent les domaines d’erreur. D’un autre côté, les domaines de mise à niveau sont définis par une stratégie. Vous décidez de la quantité souhaitée, au lieu de laisser l’environnement en déterminer le nombre. Vous pouvez disposer d’autant de domaines mise à niveau que de nœuds. Une autre différence entre les domaines d’erreur et les domaines de mise à niveau est que les domaines de mise à niveau ne sont pas hiérarchiques. En effet, ils s’apparentent plus à une balise simple.
Le diagramme suivant illustre trois domaines de mise à niveau répartis sur trois domaines d’erreur. Il montre également un emplacement possible pour trois réplicas différents d’un service avec état, où chaque réplica est attribué à des domaines d’erreur et de mise à niveau différents. Ce positionnement autorise la perte d’un domaine d’erreur au cours de la mise à niveau d’un service tout en conservant une copie du code et des données.
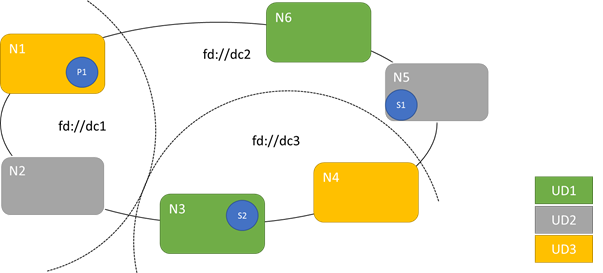
Il existe des avantages et des inconvénients au fait de disposer de nombreux domaines de mise à niveau. Davantage de domaines de mise à niveau signifie que chaque étape de la mise à niveau est plus précise et qu’elle affecte un plus petit nombre de nœuds ou de services. Il y a moins de services à déplacer simultanément, ce qui limite l’activité au sein du système. Cela tend à améliorer la fiabilité, car un pan moins important du service est affecté dans le cas de l’introduction d’un problème pendant la mise à niveau. Une quantité plus élevée de domaines de mise à niveau signifie aussi que vos besoins en mémoire tampon sur les autres nœuds sont moindres pour gérer l’impact de la mise à niveau.
Par exemple, si vous avez cinq domaines de mise à niveau, les nœuds présents dans chacun gèrent environ 20 pour cent du trafic. Si vous avez besoin d’arrêter un domaine de mise à niveau pour effectuer une mise à niveau, la charge doit en principe être affectée autre part. Comme il vous reste quatre domaines de mise à niveau, chacun d’eux doit pouvoir prendre en charge environ 25 pour cent du trafic total. Une quantité plus élevée de domaines de mise à niveau signifie moins de besoins en mémoire tampon sur les nœuds du cluster.
Imaginez que vous disposez de 10 domaines de mise à niveau. Dans ce cas, chaque domaine de mise à niveau ne gèrerait qu’environ 10 pour cent du trafic total. Quand une mise à jour parcourt le cluster, chaque domaine n’aurait besoin de prendre en charge qu’environ 11 pour cent du trafic total. Le fait de disposer d’un plus grand nombre de domaines de mise à niveau vous permet généralement d’exécuter vos nœuds à un taux d’utilisation plus élevé, car vous avez moins besoin de capacité réservée. Cela vaut aussi pour les domaines d’erreur.
L’inconvénient dans le fait d’avoir un grand nombre de domaines de mise à niveau est que les mises à niveau ont tendance à prendre plus de temps. À la fin de l’opération sur le domaine de mise à niveau, Service Fabric attend un bref instant et effectue des vérifications avant de commencer la mise à niveau du suivant. Ces laps de temps permettent de détecter les problèmes introduits par la mise à niveau avant son exécution. Le compromis est acceptable, car il empêche les modifications incorrectes d’affecter une trop grande partie du service à la fois.
La présence d’une quantité trop faible de domaines de mise à niveau a de nombreux effets secondaires négatifs. Quand chaque domaine de mise à niveau est arrêté et en cours de mise à niveau, une grande partie de votre capacité globale n’est pas disponible. Par exemple, si vous avez seulement trois domaines de mise à niveau, vous vous défaites d’environ un tiers de votre service global ou de votre capacité de cluster à la fois. Le fait qu’une grande partie de votre service soit arrêtée simultanément n’est pas souhaitable, car la capacité doit être suffisante dans le reste de votre cluster pour gérer la charge de travail. En conservant cette mémoire tampon, dans des conditions normales de fonctionnement ces nœuds subissent une moindre charge. Cela a pour effet d’augmenter le coût d’exécution de votre service.
Il n’existe aucune limite réelle au nombre total de domaines d’erreur ou de mise à niveau dans un environnement, ni de contraintes sur la façon dont ils se chevauchent. Mais il existe des modèles courants :
- Correspondance parfaite des domaines d’erreur et des domaines de mise à niveau
- Un domaine de mise à niveau par nœud (instance de système d’exploitation physique ou virtuel)
- Un modèle « agrégé par bandes » ou de « matrice » dans lequel les domaines d’erreur et les domaines de mise à niveau forment une matrice où les machines s’exécutent généralement en suivant la matrice diagonale
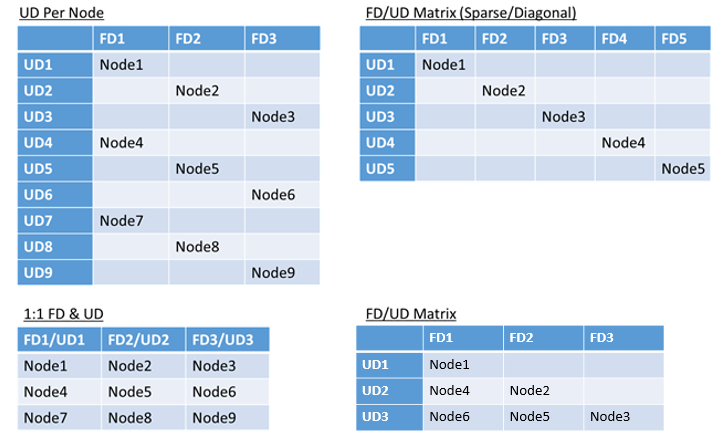
Il n’existe aucune meilleure réponse quant à la disposition. Chaque option a ses avantages et inconvénients. Par exemple, le modèle à un domaine d’erreur pour un domaine de mise à niveau est simple à mettre en place. Le modèle à un domaine de mise à niveau par nœud ressemble davantage au modèle généralement adopté. Lors des mises à niveau, chaque nœud est mis à jour indépendamment. Il s’agit d’un processus analogue à celui qui consistait par le passé à mettre à jour manuellement des petits groupes d’ordinateurs.
Le modèle le plus courant est la matrice Domaine d’erreur/Domaine de mise à niveau, où les domaines d’erreur et les domaines de mise à niveau forment une table et où les nœuds sont placés le long de la diagonale. Il s’agit du modèle utilisé par défaut dans les clusters Service Fabric dans Azure. Les clusters constitués d’un grand nombre de nœuds finissent par ressembler à un modèle de matrice dense.
Notes
Les clusters Service Fabric hébergés dans Azure ne prennent pas en charge la modification de la stratégie par défaut. Seuls les clusters autonomes offrent cette personnalisation.
Contraintes des domaines d’erreur et de mise à niveau, et comportement résultant
Approche par défaut
Par défaut, Cluster Resource Manager assure la répartition des services entre les domaines d’erreur et de mise à niveau. Cette opération est modélisée comme une contrainte. La contrainte des états de domaine d’erreur et de mise à niveau indique : « Pour une partition de service donnée, il ne doit jamais y avoir une différence supérieure à un dans le nombre d’objets de service (instances de service sans état ou réplicas de service avec état) entre deux domaines à un même niveau de hiérarchie. »
Disons que cette contrainte représente une garantie de « différence maximale ». La contrainte des domaines d’erreur et de mise à niveau empêche certains déplacements ou organisations qui enfreignent la règle.
Par exemple, supposez que vous avez un cluster avec six nœuds, configuré avec cinq domaines d’erreur et cinq domaines de mise à niveau.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N3 | ||||
| UD3 | N4 | ||||
| UD4 | N5 |
Maintenant, supposez que vous créez un service en attribuant à TargetReplicaSetSize (ou, pour un service sans état, à InstanceCount) la valeur 5. Les réplicas se trouvent sur N1-N5. En fait, N6 n’est jamais utilisé, quel que soit le nombre de services équivalents que vous créez. Mais pourquoi ? Examinons la différence entre la disposition actuelle et ce qui se passerait si N6 était choisi.
Voici la disposition que nous obtenons et le nombre total de réplicas par domaine d’erreur et de mise à niveau :
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | 1 | ||||
| UD3 | R4 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Cette disposition est équilibrée en termes de nœuds par domaine d’erreur et domaine de mise à niveau. Elle est également équilibrée en termes de nombre de réplicas par domaine d’erreur et domaine de mise à niveau. Chaque domaine possède le même nombre de nœuds et le même nombre de réplicas.
À présent, jetons un œil à ce qui se passerait si au lieu de N2, nous avions utilisé N6. Comment les réplicas auraient-ils été réparties ?
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R5 | 1 | ||||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 2 | 0 | 1 | 1 | 1 | - |
Cette disposition ne respecte pas notre définition de la garantie de « différence maximale » pour la contrainte de domaine d’erreur. FD0 a deux réplicas, alors que FD1 en a zéro. La différence entre FD0 et FD1 est donc égale à deux et supérieure à la différence maximale (un). Comme la contrainte est enfreinte, Cluster Resource Manager n’autorise pas cette organisation.
De même, si nous avions choisi N2 et N6 (au lieu de N1 et N2) nous aurions obtenu :
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | 0 | |||||
| UD1 | R5 | R1 | 2 | |||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Cette disposition est équilibrée du point de vue des domaines d’erreur. Mais elle enfreint à présent la contrainte de domaine de mise à niveau, car UD0 n’a aucun réplica et UD1 en a deux. Cette disposition n’est pas non plus valide et ne sera pas choisie par Cluster Resource Manager.
Cette approche de la répartition des réplicas avec état ou des instances sans état assure la meilleure tolérance de panne possible. En cas de panne d’un domaine, le nombre minimal de réplicas/d’instances est perdu.
En revanche, cette approche peut être trop stricte et ne pas autoriser le cluster à utiliser toutes les ressources. Pour quelques configurations de cluster, certains nœuds ne peuvent pas être utilisés. Cela peut empêcher Service Fabric de placer vos services et générer des messages d’avertissement. Dans l’exemple précédent, certains nœuds de cluster ne peuvent pas être utilisés (N6 dans l’exemple). Même si vous ajoutez des nœuds à ce cluster (N7-N10), les réplicas/instances ne sont placés que sur N1-N5 en raison des contraintes des domaines d’erreur et de mise à niveau.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | N10 | |||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N9 | N5 |
Autre approche
Cluster Resource Manager prend en charge une autre version de la contrainte pour les domaines d’erreur et de mise à niveau. Il autorise le placement tout en garantissant toujours un niveau minimal de sécurité. L’autre contrainte peut être énoncée comme suit : « Pour une partition de service donnée, la distribution des réplicas entre les domaines doit garantir que la partition ne subit pas une perte de quorum. » Disons que cette contrainte représente une garantie de « sécurité de quorum ».
Notes
Pour un service avec état, il est question de perte de quorum quand une majorité des réplicas de partition est arrêtée en même temps. Par exemple, si TargetReplicaSetSize a la valeur cinq, un ensemble de trois réplicas représente le quorum. De même, si TargetReplicaSetSize a la valeur 6, quatre réplicas sont nécessaires pour le quorum. Dans les deux cas, pas plus de deux réplicas ne peuvent être arrêtés en même temps si la partition doit continuer à fonctionner normalement.
Pour un service sans état, il n’existe pas de perte de quorum. Les services sans état continuent à fonctionner normalement même si une majorité des instances est arrêtée en même temps. Par conséquent, nous allons nous concentrer sur les services avec état dans le reste de cet article.
Revenons à l’exemple précédent. Avec la version « sécurité de quorum » de la contrainte, les trois dispositions sont toutes valides. Même si FD0 échouait dans la deuxième disposition ou si UD1 échouait dans la troisième disposition, la partition aurait toujours le quorum. (Une majorité des réplicas serait toujours actifs.) Avec cette version de la contrainte, N6 peut presque toujours être utilisé.
L’approche « sécurité de quorum » fournit plus de souplesse que l’approche « différence maximale ». En effet, il est plus facile de trouver des distributions de réplicas qui sont valides dans presque n’importe quelle topologie de cluster. Toutefois, cette approche ne permet pas de garantir les caractéristiques d’une tolérance de panne optimale, car certains échecs sont pires que d’autres.
Dans le pire des cas, la majorité des réplicas pourrait être perdue suite à l’échec d’un domaine et d’un réplica supplémentaire. Par exemple, au lieu de trois échecs nécessaires pour perdre le quorum avec cinq réplicas ou instances, vous risquez désormais de perdre une majorité avec deux échecs uniquement.
Approche adaptative
Dans la mesure où les deux approches présentent des avantages et des inconvénients, nous avons introduit une approche adaptative qui combine ces deux stratégies.
Notes
Il s’agit du comportement par défaut à compter de Service Fabric version 6.2.
L’approche adaptative utilise la logique de « différence maximale » par défaut et ne bascule vers la logique de « sécurité de quorum » que si nécessaire. Cluster Resource Manager détermine automatiquement quelle stratégie est nécessaire en examinant la façon dont le cluster et les services sont configurés.
Cluster Resource Manager doit utiliser la logique « basée sur le quorum » pour un service si ces deux conditions sont remplies :
- TargetReplicaSetSize pour le service est uniformément divisible par le nombre de domaines d’erreur et le nombre de domaines de mise à niveau.
- Le nombre de nœuds est inférieur ou égal au nombre de domaines d’erreur multiplié par le nombre de domaines de mise à niveau.
Gardez à l’esprit que Cluster Resource Manager utilise cette approche à la fois pour les services avec et sans état, même si la perte de quorum n’est pas pertinente pour les services sans état.
Revenons à l’exemple précédent et supposons qu’un cluster a maintenant huit nœuds. Le cluster est encore configuré avec cinq domaines d’erreur et cinq domaines de mise à niveau, et la valeur TargetReplicaSetSize d’un service hébergé sur ce cluster reste cinq.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N5 |
Comme toutes les conditions requises sont remplies, Cluster Resource Manager utilise la logique « basée sur le quorum » dans la distribution du service. Cela permet l’utilisation de N6-N8. Dans ce cas, une distribution de service possible peut se présenter comme suit :
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | 0 | |||||
| UD4 | R5 | 1 | ||||
| FDTotal | 2 | 1 | 1 | 0 | 1 | - |
Si la valeur TargetReplicaSetSize de votre service est réduite à quatre (par exemple), Cluster Resource Manager remarquera ce changement. Il reprendra avec la logique de « différence maximale », car TargetReplicaSetSize n’est plus divisible par le nombre de domaines d’erreur et de domaines de mise à niveau. Par conséquent, certains mouvements de réplicas auront lieu afin de distribuer les quatre réplicas restants sur les nœuds N1-N5. De cette façon, la version « différence maximale » de la logique de domaine de mise à niveau et de domaine d’erreur n’est pas enfreinte.
Dans la disposition précédente, si la valeur TargetReplicaSetSize est 5 et que N1 est supprimé du cluster, le nombre de domaines de mise à niveau devient égal à quatre. Là encore, Cluster Resource Manager commence à utiliser la logique de « différence maximale », car le nombre de domaines de mise à niveau ne divise plus uniformément la valeur TargetReplicaSetSize du service. Par conséquent, le réplica R1, quand il est de nouveau généré, doit se placer sur N4 afin de ne pas enfreindre la contrainte des domaines d’erreur et de mise à niveau.
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | N/A | N/A | N/A | N/A | N/A | N/A |
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | R1 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Configuration des domaines d’erreur et de mise à niveau
Dans les déploiements Service Fabric hébergés sur Azure, la définition des domaines d’erreur et de mise à niveau s’effectue automatiquement. Service Fabric récupère et utilise les informations d’environnement d’Azure.
Si vous créez votre propre cluster (ou si vous voulez exécuter une topologie particulière pendant son développement), vous pouvez vous-même fournir les informations de domaine d’erreur et de domaine de mise à niveau. Dans cet exemple, nous définissons un cluster de développement local à neuf nœuds qui s’étend sur trois centres de données (chacun avec trois racks). Ce cluster a également trois domaines de mise à niveau répartis sur ces trois centres de données. Voici un exemple de la configuration dans ClusterManifest.xml :
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
Cet exemple utilise ClusterConfig.json pour les déploiements autonomes :
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
Notes
Quand vous définissez des clusters par le biais d’Azure Resource Manager, Azure affecte les domaines d’erreur et les domaines de mise à niveau. Ainsi, la définition de vos types de nœuds et de vos groupes de machines virtuelles identiques dans votre modèle Azure Resource Manager n’inclut pas les informations sur les domaines d’erreur ou les domaines de mise à niveau.
Propriétés de nœud et contraintes de placement
Parfois (en réalité, la plupart du temps), vous voudrez faire en sorte que certaines charges de travail s’exécutent uniquement sur certains types de nœuds du cluster. Par exemple, certaines charges de travail peuvent nécessiter des GPU ou des disques SSD, et d’autres non.
Presque toutes les architectures multiniveau sont un bon exemple de ciblage du matériel sur des charges de travail spécifiques. Certaines machines font office de front-end ou remplissent le rôle de service d’API de l’application et sont exposées aux clients ou à Internet. D’autres machines, souvent dotées d’autres ressources matérielles, gèrent le travail des couches de calcul ou de stockage. Celles-ci ne sont généralement pas directement exposées aux clients ou à Internet.
Service Fabric s’attend dans certains cas à ce que des charges de travail particulières aient besoin de s’exécuter sur des configurations matérielles particulières. Par exemple :
- Une application multiniveau existante a subi un « lift-and-shift » dans un environnement Service Fabric
- Une charge de travail doit être exécutée sur un matériel spécifique pour des raisons d’isolation de sécurité, de performances ou de mise à l’échelle
- Une charge de travail doit être isolée des autres charges de travail pour des raisons de stratégie ou de consommation de ressources
Pour prendre en charge ces types de configurations, Service Fabric inclut des balises que vous pouvez appliquer aux nœuds. Ces balises sont appelés propriétés de nœud. Les contraintes de placement sont les instructions associées aux différents services que vous sélectionnez pour une ou plusieurs propriétés de nœud. Les contraintes de placement définissent là où les services doivent s’exécuter. L’ensemble de contraintes est extensible. N’importe quelle paire clé/valeur peut fonctionner.
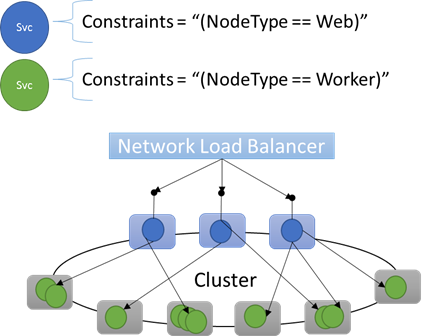
Propriétés de nœud intégrées
Service Fabric définit certaines propriétés de nœud par défaut qui peuvent être utilisées automatiquement afin que vous n’ayez pas à les définir. Les propriétés par défaut définies sur chaque nœud sont NodeType et NodeName.
Par exemple, vous pouvez écrire une contrainte de placement ainsi : "(NodeType == NodeType03)". NodeType est une propriété couramment utilisée. Elle est utile car elle correspond parfaitement à un type de machine. Chaque type de machine correspond à un type de charge de travail dans une application multicouche classique.
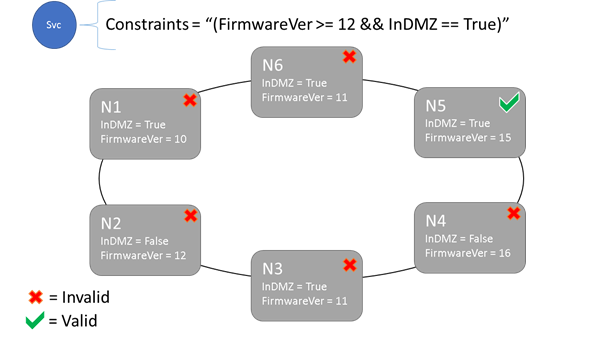
Syntaxe des contraintes de placement et des propriétés de nœud
La valeur spécifiée dans la propriété de nœud peut être une chaîne, une valeur booléenne ou une valeur signée longue. L’instruction au niveau du service est appelée contrainte de placement, car elle contraint l’exécution du service à un emplacement spécifique dans le cluster. La contrainte peut être toute déclaration booléenne qui opère sur les propriétés de nœud du cluster. Les sélecteurs valides dans ces déclarations booléennes sont :
Des vérifications conditionnelles pour la création d’instructions particulières :
. Syntaxe "égal à" "==" "non égal à" "!=" "supérieur à" ">" "supérieur ou égal à" ">=" "inférieur à" "<" "inférieur ou égal à" "<=" Des instructions booléennes pour les opérations logiques et de groupage :
. Syntaxe "et" "&&" "ou" "||" "non" "!" "regrouper en tant qu’instruction unique" "()"
Voici quelques exemples d’instructions de contrainte de base :
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
Le service peut être placé sur les nœuds dont l’instruction de contrainte de placement globale prend la valeur « True » uniquement. Les nœuds qui n’ont pas de propriété définie ne correspondent à aucune contrainte de placement contenant la propriété.
Supposez que les propriétés de nœud suivantes aient été définies pour un type de nœud dans ClusterManifest.xml :
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
L’exemple suivant montre les propriétés de nœud définies par le biais de ClusterConfig.json pour les déploiements autonomes ou Template.json pour les clusters hébergés sur Azure.
Notes
Dans votre modèle Azure Resource Manager, le type de nœud est généralement paramétré. Il ressemblerait à "[parameters('vmNodeType1Name')]" plutôt qu’à NodeType01.
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
Vous pouvez créer des contraintes de placement de service pour un service comme suit :
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
Si tous les nœuds de NodeType01 sont valides, vous pouvez aussi sélectionner ce type de nœud avec la contrainte "(NodeType == NodeType01)".
Les contraintes de placement d’un service peuvent être mise à jour de manière dynamique pendant l’exécution. Si vous le souhaitez, vous pouvez donc déplacer un service dans le cluster, ajouter et supprimer des exigences, et ainsi de suite. Service Fabric garantit que le service reste opérationnel et disponible, même quand ces types de modifications sont apportées.
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
Les contraintes de placement sont spécifiées pour chaque instance de service nommée. Les mises à jour prennent toujours la place de (remplacent) ce qui a été précédemment spécifié.
La définition du cluster définit les propriétés d’un nœud. La modification des propriétés d’un nœud nécessite une mise à niveau de la configuration du cluster. Après avoir mis à niveau les propriétés d’un nœud, chaque nœud affecté doit redémarrer pour faire état de ses nouvelles propriétés. Service Fabric gère ces mises à niveau propagées.
Description et gestion des ressources de cluster
L’une des principales tâches de n’importe quel orchestrateur consiste à vous aider à gérer la consommation de ressources du cluster. La gestion des ressources de cluster peut signifier plusieurs choses.
En premier lieu, il peut s’agir de veiller à ce que les machines ne soient pas en surcharge. Cela implique de vérifier que les machines n’exécutent pas plus de services qu’elles ne peuvent en gérer.
En second lieu, il peut s’agir d’équilibrer et d’optimiser, opérations qui sont essentielles au bon fonctionnement des services. Les offres de services sensibles aux coûts ou aux performances ne peuvent pas s’accommoder de la présence simultanée de nœuds à chaud et de nœuds à froid. Les nœuds à chaud entraînent des conflits de ressources et une dégradation des performances. Les nœuds à froid représentent un gaspillage de ressources et des coûts accrus.
Service Fabric représente les ressources en tant que métriques. Les métriques correspondent à n’importe quelle ressource logique ou physique que vous souhaitez décrire pour Service Fabric. Par exemple, « WorkQueueDepth » et « MemoryInMb » sont des métriques. Pour plus d’informations sur les ressources physiques que Service Fabric peut régir sur les nœuds, consultez Gouvernance des ressources. Pour plus d’informations sur les métriques par défaut qu’utilise le Gestionnaire des ressources clusters et leur personnalisation, voir cet article.
Les métriques sont différentes des contraintes de placement et des propriétés de nœud. Les propriétés de nœud sont des descripteurs statiques des nœuds proprement dits. Les métriques décrivent les ressources à la disposition des nœuds et que les services consomment quand ils s’exécutent sur un nœud. La propriété d’un nœud pourrait être HasSSD et avoir la valeur true ou false. La quantité d’espace disponible sur ce disque SSD et la quantité consommée par les services pourrait correspondre à une métrique nommée « DriveSpaceInMb ».
Comme pour les contraintes de placement et les propriétés de nœud, Service Fabric Cluster Resource Manager ne comprend pas ce que signifient les noms des métriques. Les noms des mesures ne sont que des chaînes. Nous vous recommandons de déclarer les unités dans le cadre des noms des métriques que vous créez quand elles peuvent être ambiguës.
Capacité
Si vous désactiviez toutes les fonctions d’équilibrage des ressources, Service Fabric Cluster Resource Manager serait tout de même en mesure de garantir qu’aucun nœud ne dépasse sa capacité. Il est possible de gérer les dépassements de capacité, sauf si le cluster est saturé ou si la charge de travail dépasse la capacité d’un nœud. La capacité est une autre contrainte que Cluster Resource Manager utilise pour comprendre la quantité d’une ressource dont un nœud dispose. La capacité restante est également suivie pour le cluster dans son ensemble.
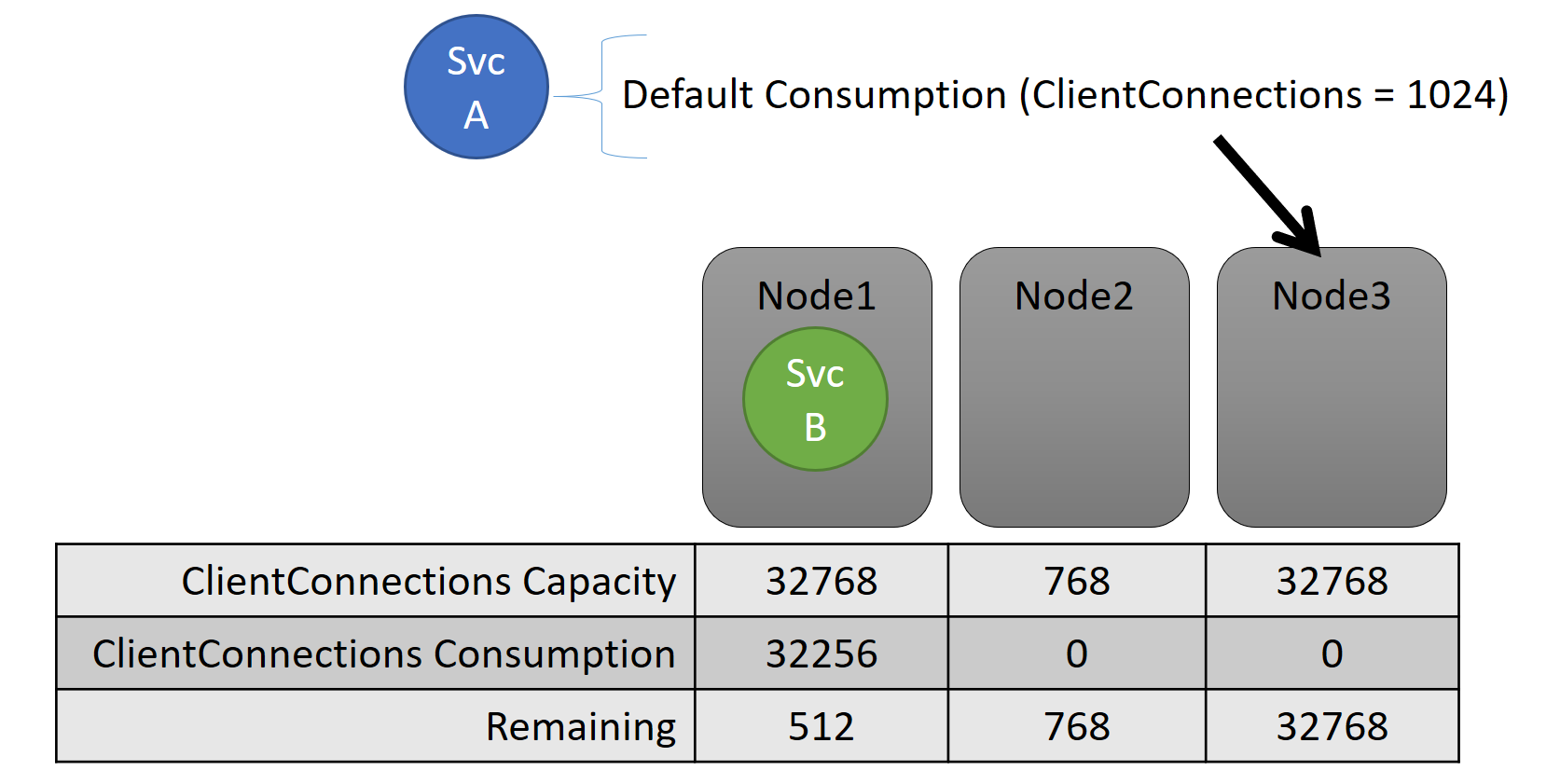
La capacité et la consommation au niveau du service sont toutes deux exprimées en termes de métriques. Par exemple, pour une métrique nommée « ClientConnections », un nœud peut avoir une capacité de 32 768. Les autres nœuds peuvent avoir d’autres limites. Un service s’exécutant sur ce nœud peut indiquer qu’il consomme actuellement 32 256 de la métrique « ClientConnections ».
Pendant l’exécution, Cluster Resource Manager assure le suivi de la capacité restante dans le cluster et sur les nœuds. Pour cela, il soustrait la consommation de chaque service de la capacité du nœud sur lequel le service s’exécute. Grâce à ces informations, Cluster Resource Manager peut déterminer où placer ou déplacer les réplicas afin que les nœuds ne dépassent pas la capacité.
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
Vous pouvez voir les capacités définies dans le manifeste de cluster. Voici un exemple pour ClusterManifest.xml :
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
Voici un exemple de capacités définies par le biais de ClusterConfig.json pour les déploiements autonomes ou Template.json pour les clusters hébergés sur Azure :
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
La charge d’un service évolue souvent de manière dynamique. Supposez que la charge d’un réplica « ClientConnections » soit passé de 1 024 à 2 048. Le nœud sur lequel il s’exécutait disposait d’une capacité restante de seulement 512 pour cette métrique. À présent, le placement de ce réplica ou de cette instance n’est pas valide, car il n’y a pas suffisamment d’espace sur ce nœud. Cluster Resource Manager doit ramener le nœud en dessous de la capacité. Il réduit la charge sur le nœud en surcapacité en déplaçant un ou plusieurs réplicas ou instances de ce nœud vers d’autres nœuds.
Cluster Resource Manager tente de réduire le coût du déplacement des réplicas. Apprenez-en davantage sur le coût du mouvement et sur les stratégies et règles de rééquilibrage.
Capacité de cluster
Comment Service Fabric Cluster Resource Manager fait-il pour éviter la saturation du cluster dans son ensemble ? Du fait du chargement dynamique, il ne peut pas faire grand chose. La charge des services peut augmenter indépendamment des actions entreprises par Cluster Resource Manager. Par conséquent, votre cluster qui dispose de suffisamment d’espace aujourd’hui pourrait ne pas être suffisamment puissant demain en cas de pic de charge.
Les contrôles dans Cluster Resource Manager aident à éviter les problèmes. La première chose que vous pouvez faire est d’empêcher la création de nouvelles charges de travail qui risquent de saturer le cluster.
Supposez que vous créez un service sans état et qu’il a une charge associée. Le service respecte la métrique « DiskSpaceInMb ». Il va consommer cinq unités de « DiskSpaceInMb » pour chaque instance du service. Vous souhaitez créer trois instances du service. Cela signifie que vous avez besoin de 15 unités « DiskSpaceInMb » dans le cluster pour pouvoir créer ces instances de service.
Cluster Resource Manager calcule en permanence la capacité et la consommation de chaque métrique pour déterminer la capacité restante au niveau du cluster. Si l’espace est insuffisant, Cluster Resource Manager rejette l’appel de création de service.
L’exigence étant seulement que 15 unités soient disponibles, vous pouvez allouer cet espace de différentes manières. Par exemple, il peut y avoir une unité restante de capacité sur 15 nœuds différents ou trois unités restantes de capacité sur cinq nœuds différents. Si Cluster Resource Manager peut changer l’organisation de façon à avoir cinq unités disponibles sur trois nœuds, il place le service. Il est généralement possible de réorganiser le cluster, à moins que le cluster soit proche de la saturation ou que les services existants ne puissent pas être consolidés pour une raison quelconque.
Capacité de mémoire tampon et de surréservation de nœud
Si la capacité d’un nœud est spécifiée pour une métrique, Gestionnaire des ressources clusters ne placera ni ne déplacera jamais de réplicas vers un nœud si la charge totale dépasse la capacité spécifiée du nœud. Cela peut parfois empêcher le placement de nouveaux réplicas ou le remplacement de réplicas défaillants si le cluster est proche de sa pleine capacité et qu’un réplica ayant une charge importante doit être placé, remplacé ou déplacé.
Pour plus de souplesse, vous pouvez spécifier une capacité de mémoire tampon ou de surréservation de nœud. Lorsque la capacité de mémoire tampon ou de surréservation d’un nœud est spécifiée pour une métrique, Gestionnaire des ressources clusters tente de placer ou déplacer les réplicas de sorte que la capacité de mémoire tampon ou de surréservation reste inutilisée, mais permet l’utilisation de la capacité de mémoire tampon ou de surréservation le cas échéant pour les actions qui augmentent la disponibilité du service, par exemple :
- Placement de nouveaux réplicas ou remplacement de réplicas défaillants
- Placement lors de mises à niveau
- Correction des violations de contrainte figée et souple
- Défragmentation
La capacité de mémoire tampon du nœud désigne une partie réservée de la capacité en dessous de la capacité spécifiée du nœud, et la capacité de surréservation désigne une partie de capacité supplémentaire au-dessus de la capacité spécifiée du nœud. Dans les deux cas, Gestionnaire des ressources clusters s’efforcera de garder cette capacité libre.
Par exemple, si un nœud a une capacité spécifiée de 100 pour la métrique CpuUtilization et que le pourcentage de mémoire tampon du nœud pour cette métrique est fixé à 20 %, les capacités totales et non mises en mémoire tampon seront respectivement de 100 et 80, et Gestionnaire des ressources clusters ne placera pas plus de 80 unités de charge sur le nœud dans des circonstances normales.

La mémoire tampon du nœud doit être utilisée lorsque vous souhaitez réserver une partie de la capacité du nœud qui sera utilisée uniquement pour les actions qui augmentent la disponibilité du service mentionnées ci-dessus.
En revanche, si le pourcentage de surréservation du nœud est utilisé et fixé à 20 %, les capacités totales et non mises en mémoire tampon seront respectivement de 120 et 100.
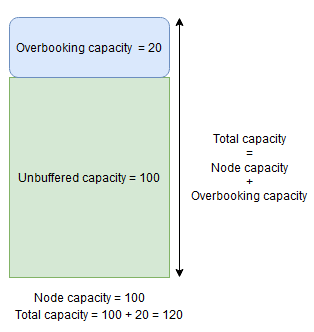
La capacité de surréservation doit être utilisée lorsque vous souhaitez permettre à Gestionnaire des ressources clusters de placer des réplicas sur un nœud même si leur utilisation totale des ressources dépasse la capacité. Cela peut être utilisé pour fournir une disponibilité supplémentaire aux services aux dépens des performances. Si la surréservation est utilisée, la logique d’application de l’utilisateur doit être en mesure de fonctionner avec moins de ressources physiques qu’il ne lui en faut.
Si des capacités de mémoire tampon ou de surréservation du nœud sont spécifiées, Gestionnaire des ressources clusters ne déplacera ni ne placera de réplicas si la charge totale sur le nœud cible dépasse la capacité totale (capacité du nœud en cas de mémoire tampon de nœud, et capacité de nœud + capacité de surréservation en cas de surréservation).
Il est également possible de spécifier une capacité de surréservation infinie. Dans ce cas, Gestionnaire des ressources clusters tentera de maintenir la charge totale du nœud en dessous de la capacité spécifiée, mais il est autorisé à placer une charge beaucoup plus importante sur le nœud, ce qui peut entraîner une dégradation importante des performances.
La capacité de mémoire tampon et la capacité de surréservation d’un nœud ne peuvent pas être spécifiées en même temps pour une métrique.
Voici un exemple montrant comment spécifier les capacités de mémoire tampon de nœud ou de surréservation dans ClusterManifest.xml :
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
Voici un exemple montrant comment spécifier les capacités de mémoire tampon de nœud ou de surréservation par le biais de ClusterConfig.json pour les déploiements autonomes ou Template.json pour les clusters hébergés sur Azure :
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
Étapes suivantes
- Pour plus d’informations sur l’architecture et le flux d’informations dans Cluster Resource Manager, consultez Vue d’ensemble de l’architecture Cluster Resource Manager.
- La définition des métriques de défragmentation est une façon de consolider la charge sur les nœuds au lieu de la répartir. Pour découvrir comment configurer la défragmentation, consultez Défragmentation des mesures et de la charge dans Service Fabric.
- Commencez au début pour obtenir une présentation de Service Fabric Cluster Resource Manager.
- Pour découvrir comment Cluster Resource Manager gère et équilibre la charge du cluster, consultez Équilibrage de votre cluster Service Fabric.