Tutoriel : Indexer des données Azure SQL à l’aide du SDK .NET
Configurez un indexeur pour extraire des données interrogeables d’Azure SQL Database, en les envoyant à un index de recherche dans la Recherche Azure AI.
Ce tutoriel utilise C# et Azure SDK pour .NET pour effectuer les tâches suivantes :
- Créer une source de données qui se connecte à une base de données Azure SQL
- Créer un indexeur
- Exécuter un indexeur pour charger des données dans un index
- Interroger un index dans le cadre d’une étape de vérification
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
- Azure SQL Database avec l’authentification SQL Server
- Visual Studio
- Recherche Azure AI. Créer ou rechercher un service de recherche existant
Remarque
Vous pouvez utiliser un service de recherche gratuit pour ce tutoriel. Le niveau gratuit vous limite à trois index, trois indexeurs et trois sources de données. Ce didacticiel crée une occurrence de chaque élément. Avant de commencer, veillez à disposer de l’espace suffisant sur votre service pour accepter les nouvelles ressources.
Télécharger les fichiers
Le code source pour ce tutoriel se trouve dans le dossier DotNetHowToIndexer du dépôt GitHub Azure-Samples/search-dotnet-getting-started.
1 - Créer les services
Ce tutoriel utilise la Recherche Azure AI pour l’indexation et les requêtes, et Azure SQL Database comme source de données externe. Si possible, créez les deux services dans la même région et le même groupe de ressources pour des raisons de proximité et de facilité de gestion. En pratique, Azure SQL Database peut se trouver dans n’importe quelle région.
Démarrer avec Azure SQL Database
Ce tutoriel fournit le fichier hotels.sql dans l’exemple de téléchargement pour remplir la base de données. La Recherche Azure AI consomme des ensembles de lignes aplatis, comme celui généré à partir d’une vue ou d’une requête. Le fichier SQL de l’exemple de solution crée et remplit une table unique.
Si vous avez une ressource Azure SQL Database, vous pouvez y ajouter la table hotels en commençant à l’étape Ouvrir la requête.
Créez une base de données Azure SQL en suivant les instructions de Démarrage rapide : Créer une base de données unique.
La configuration du serveur pour la base de données est importante.
Choisissez l’option d’authentification SQL Server qui vous invite à spécifier un nom d’utilisateur et un mot de passe. Vous en avez besoin pour la chaîne de connexion ADO.NET utilisée par l’indexeur.
Choisissez une connexion publique. Cela simplifie l’exécution de ce tutoriel. L’option publique n’est pas recommandée pour la production et nous vous recommandons de supprimer cette ressource à la fin du tutoriel.
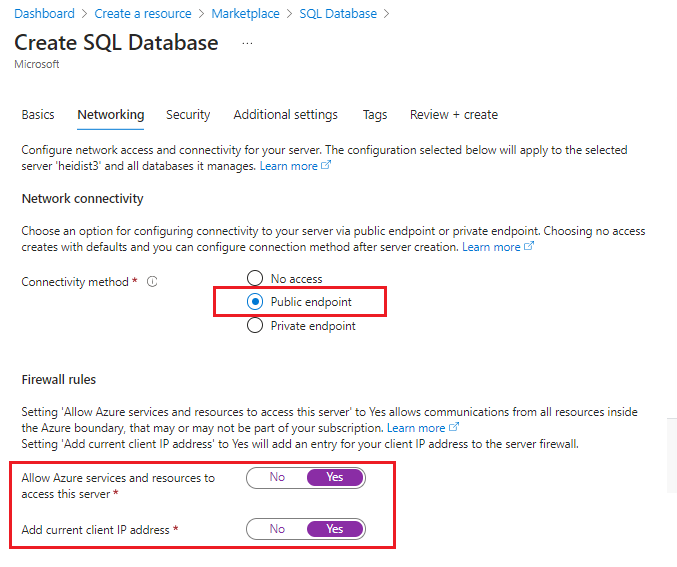
Dans le portail Azure, accédez à la nouvelle ressource.
Ajoutez une règle de pare-feu pour autoriser l’accès à partir de votre client, en suivant les instructions de Démarrage rapide : Créer une règle de pare-feu au niveau du serveur dans le portail Azure. Vous pouvez exécuter
ipconfigà partir d’une invite de commandes pour obtenir votre adresse IP.Utilisez l’Éditeur de requêtes pour charger les exemples de données. Dans le volet de navigation, sélectionnez Éditeur de requêtes (préversion) et entrez le nom d’utilisateur et le mot de passe de l’administrateur du serveur.
Si vous recevez une erreur d’accès refusé, copiez l’adresse IP du client à partir du message d’erreur, ouvrez la page de sécurité réseau du serveur et ajoutez une règle de trafic entrant qui autorise l’accès à partir de votre client.
Dans l’Éditeur de requête, sélectionnez Ouvrir la requête et accédez à l’emplacement du fichier hotels.sql sur votre ordinateur local.
Sélectionnez le fichier, puis le bouton Ouvrir. Le script doit ressembler à la capture d’écran suivante :
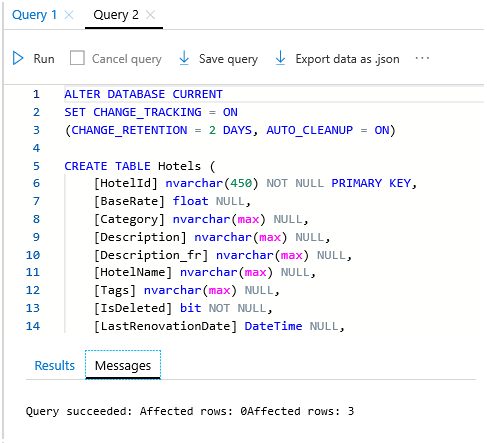
Sélectionnez Exécuter pour exécuter la requête. Le volet Résultats affiche normalement un message de réussite de la requête, pour 3 lignes.
Pour renvoyer un ensemble de lignes de cette table, vous pouvez exécuter la requête suivante comme étape de vérification :
SELECT * FROM HotelsCopiez la chaîne de connexion ADO.NET pour la base de données. Sous Paramètres>Chaînes de connexion, copiez la chaîne de connexion ADO.NET, similaire à celle présentée dans l’exemple ci-dessous.
Server=tcp:<YOUR-DATABASE-NAME>.database.windows.net,1433;Initial Catalog=hotels-db;Persist Security Info=False;User ID=<YOUR-USER-NAME>;Password=<YOUR-PASSWORD>;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;
Vous aurez besoin de cette chaîne de connexion dans l’exercice suivant, lors de la configuration de votre environnement.
Recherche Azure AI
Le composant suivant est la Recherche Azure AI, que vous pouvez créer dans le portail Azure. Vous pouvez utiliser le niveau gratuit pour effectuer cette procédure pas à pas.
Obtenir une clé API d’administration et une URL pour la Recherche Azure AI
Les appels d’API nécessitent l’URL du service et une clé d’accès. Comme la création d’un service de recherche utilise les deux, si vous avez ajouté la Recherche Azure AI à votre abonnement, suivez ces étapes pour obtenir les informations nécessaires :
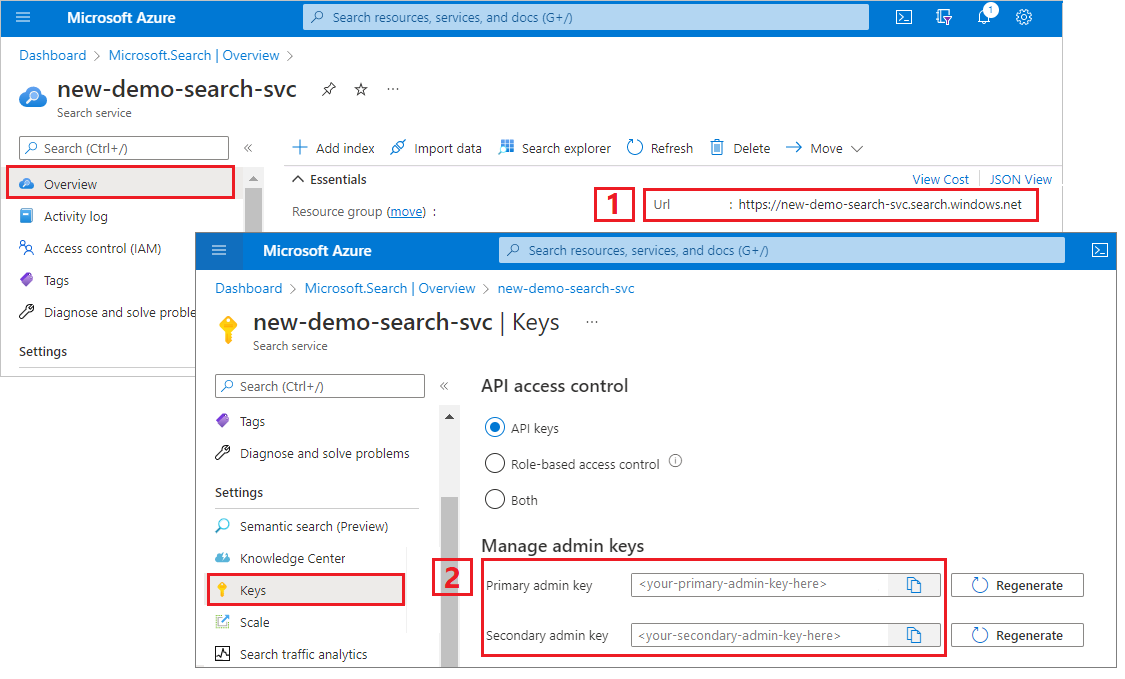
Connectez-vous au portail Azure, puis dans la page Vue d’ensemble du service de recherche, récupérez l’URL. Voici un exemple de point de terminaison :
https://mydemo.search.windows.net.Dans Paramètres>Clés, obtenez une clé d’administration pour avoir des droits d’accès complets sur le service. Il existe deux clés d’administration interchangeables, fournies pour assurer la continuité de l’activité au cas où vous deviez en remplacer une. Vous pouvez utiliser la clé primaire ou secondaire sur les demandes d’ajout, de modification et de suppression d’objets.
2 - Configurer votre environnement
Démarrez Visual Studio et ouvrez le fichier DotNetHowToIndexers.sln.
Dans l’Explorateur de solutions, ouvrez appsettings.json pour fournir les informations de connexion.
Pour
SearchServiceEndPoint, si l’URL complète de la page de présentation du service est « https://my-demo-service.search.windows.net" », la valeur à fournir est l’URL complète.Pour
AzureSqlConnectionString, le format de la chaîne est similaire à celui-ci :"Server=tcp:<your-database-name>.database.windows.net,1433;Initial Catalog=hotels-db;Persist Security Info=False;User ID=<your-user-name>;Password=<your-password>;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;"{ "SearchServiceEndPoint": "<placeholder-search-full-url>", "SearchServiceAdminApiKey": "<placeholder-admin-key-for-search-service>", "AzureSqlConnectionString": "<placeholder-ADO.NET-connection-string", }Dans la chaîne de connexion SQL, remplacez le mot de passe de l’utilisateur par un mot de passe valide. Le nom de l’utilisateur et celui de la base de données sont copiés dans votre chaîne de connexion, mais le mot de passe doit être entré manuellement.
3 - Créer le pipeline
Les indexeurs nécessitent un objet de source de données et un index. Le code approprié se trouve dans deux fichiers :
hotel.cs, contenant un schéma qui définit l’index
Program.cs, contenant les fonctions permettant de créer et de gérer des structures dans votre service
Dans Hotel.cs
Le schéma d’index définit la collection de champs, y compris les attributs spécifiant les opérations autorisées, pour savoir, par exemple, si un champ peut faire l’objet d’une interrogation en texte intégral, d’un filtrage ou d’un tri comme indiqué dans la définition de champ suivante pour HotelName. Un SearchableField est une recherche en texte intégral par définition. Les autres attributs sont assignés explicitement.
. . .
[SearchableField(IsFilterable = true, IsSortable = true)]
[JsonPropertyName("hotelName")]
public string HotelName { get; set; }
. . .
Un schéma peut également inclure d’autres éléments, y compris des profils de notation pour améliorer un score de recherche, des analyseurs personnalisés et d’autres constructions. Toutefois, en ce qui nous concerne, le schéma est peu défini et comporte uniquement des champs trouvés dans les exemples de jeux de données.
Dans Program.cs
Le programme principal inclut une logique pour la création d’un client d’indexeur, d’un index, d’une source de données et d’un indexeur. Le code recherche et supprime les ressources existantes du même nom, en supposant que vous pouvez exécuter ce programme plusieurs fois.
L’objet source de données est configuré avec des paramètres propres aux ressources Azure SQL Database, notamment l’indexation partielle ou incrémentielle, pour utiliser les fonctionnalités intégrées de détection des modifications d’Azure SQL. La base de données source des hôtels de démonstration dans Azure SQL a une colonne « suppression réversible » nommée IsDeleted. Quand cette colonne est définie sur true dans la base de données, l’indexeur supprime le document correspondant dans l’index de Recherche Azure AI.
Console.WriteLine("Creating data source...");
var dataSource =
new SearchIndexerDataSourceConnection(
"hotels-sql-ds",
SearchIndexerDataSourceType.AzureSql,
configuration["AzureSQLConnectionString"],
new SearchIndexerDataContainer("hotels"));
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
Un objet de l’indexeur est indépendant de la plateforme, où la configuration, la planification et l’appel sont les mêmes quelle que soit la source. Cet exemple d’indexeur inclut une planification, une option de réinitialisation qui efface l’historique de l’indexeur, et appelle une méthode pour créer et exécuter immédiatement l’indexeur. Pour créer ou mettre à jour un indexeur, utilisez CreateOrUpdateIndexerAsync.
Console.WriteLine("Creating Azure SQL indexer...");
var schedule = new IndexingSchedule(TimeSpan.FromDays(1))
{
StartTime = DateTimeOffset.Now
};
var parameters = new IndexingParameters()
{
BatchSize = 100,
MaxFailedItems = 0,
MaxFailedItemsPerBatch = 0
};
// Indexer declarations require a data source and search index.
// Common optional properties include a schedule, parameters, and field mappings
// The field mappings below are redundant due to how the Hotel class is defined, but
// we included them anyway to show the syntax
var indexer = new SearchIndexer("hotels-sql-idxr", dataSource.Name, searchIndex.Name)
{
Description = "Data indexer",
Schedule = schedule,
Parameters = parameters,
FieldMappings =
{
new FieldMapping("_id") {TargetFieldName = "HotelId"},
new FieldMapping("Amenities") {TargetFieldName = "Tags"}
}
};
await indexerClient.CreateOrUpdateIndexerAsync(indexer);
Les exécutions de l’indexeur sont généralement planifiées, mais pendant le développement, vous souhaiterez peut-être exécuter l’indexeur immédiatement à l’aide de RunIndexerAsync.
Console.WriteLine("Running Azure SQL indexer...");
try
{
await indexerClient.RunIndexerAsync(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
4 - Générer la solution
Appuyez sur F5 pour générer et exécuter la solution. Le programme s’exécute en mode débogage. Une fenêtre de console signale l’état de chaque opération.
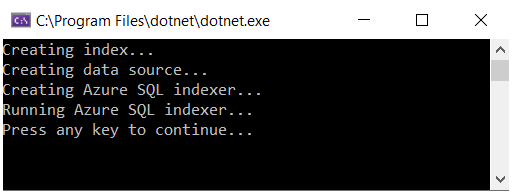
Votre code s’exécute localement dans Visual Studio en se connectant à votre service de recherche sur Azure qui, à son tour, se connecte à Azure SQL Database et récupère le jeu de données. Étant donné le grand nombre d’opérations, il existe plusieurs points de défaillance potentiels. Si une erreur survient, commencez par vérifier les conditions suivantes :
Les informations de connexion au service de recherche que vous fournissez sont l’URL complète. Si vous n’avez entré que le nom du service, les opérations s’arrêtent à la création d’index avec une erreur signalant un échec de connexion.
Informations de connexion à la base de données dans appsettings.json. Il doit s’agir de la chaîne de connexion ADO.NET obtenue à partir du portail Azure et modifiée pour inclure un nom d’utilisateur et un mot de passe valides pour votre base de données. Le compte d’utilisateur doit avoir l’autorisation de récupérer des données. L’accès entrant via le pare-feu doit être autorisé pour l’adresse IP de votre client local.
Limites des ressources. N’oubliez pas que le niveau Gratuit est limité à trois index, indexeurs et sources de données. Un service ayant atteint la limite maximale ne peut pas créer de nouveaux objets.
5 - Recherche
Utilisez le portail Azure pour vérifier la création des objets, puis utilisez l’Explorateur de recherche pour interroger l’index.
Connectez-vous au portail Azure et, dans le volet de navigation gauche de votre service de recherche, ouvrez chaque liste successivement pour vérifier que l’objet est créé. Sous Index, Indexeurs et Sources de données, vous devez voir « hotels-sql-idx », « hotels-sql-indexer » et « hotels-sql-ds », respectivement.
Sous l’onglet Index, sélectionnez l’index hotels.sql-idx. Dans la page hotels, le premier onglet est celui de l’Explorateur de recherche.
Sélectionnez Rechercher pour émettre une requête vide.
Les trois entrées de votre index sont renvoyées en tant que documents JSON. L’explorateur de recherche renvoie des documents au format JSON afin que vous puissiez afficher l’ensemble de la structure.
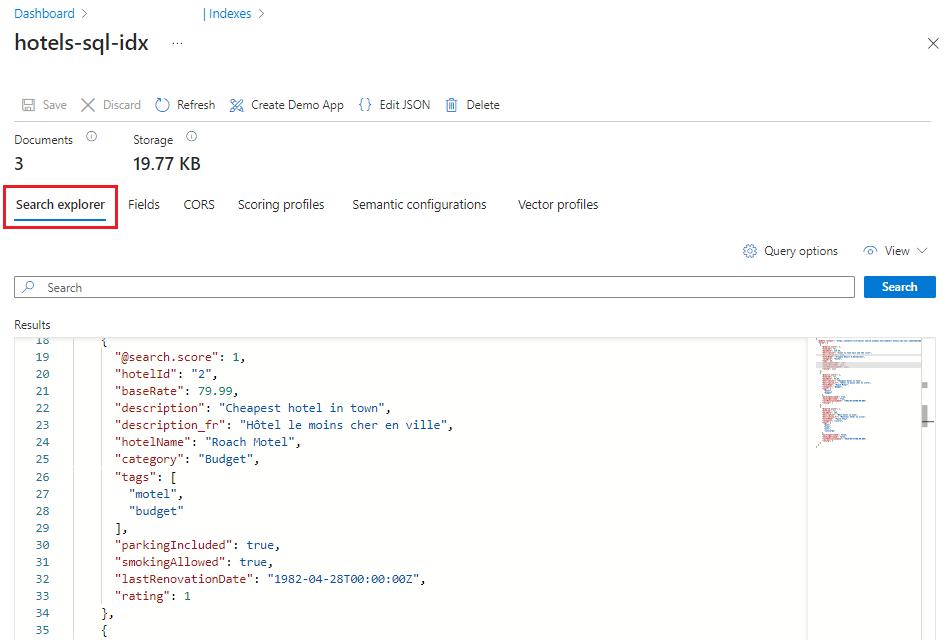
Ensuite, basculez vers Vue JSON afin de pouvoir entrer les paramètres de requête :
{ "search": "river", "count": true }Cette requête appelle la recherche en texte intégral sur le terme
riveret le résultat inclut le nombre de documents correspondants. Connaître le nombre de documents correspondants est utile dans les scénarios de test lorsque vous avez un index de grande taille comportant des milliers, voire des millions de documents. Dans ce cas, un seul document correspond à la requête.Enfin, entrez des paramètres qui limitent les résultats de recherche aux champs d’intérêt :
{ "search": "river", "select": "hotelId, hotelName, baseRate, description", "count": true }La réponse à la requête se réduit aux champs sélectionnés, ce qui entraîne une sortie plus concise.
Réinitialiser et réexécuter
Dans les premières étapes expérimentales de développement, l’approche la plus pratique pour les itérations de conception consiste à supprimer les objets d’Azure AI Search et à autoriser votre code à les reconstruire. Les noms des ressources sont uniques. La suppression d’un objet vous permet de le recréer en utilisant le même nom.
L’exemple de code pour ce tutoriel recherche les objets existants et les supprime pour vous permettre de réexécuter votre code.
Vous pouvez également utiliser le Portail Azure pour supprimer les index, les indexeurs et les sources de données.
Nettoyer les ressources
Lorsque vous travaillez dans votre propre abonnement, il est judicieux à la fin d’un projet de supprimer les ressources dont vous n’avez plus besoin. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources individuellement, ou supprimer le groupe de ressources pour supprimer l’ensemble des ressources.
Vous pouvez rechercher et gérer des ressources dans le Portail Azure dans le volet de navigation de gauche, en cliquant sur le lien Toutes les ressources ou Groupes de ressources.
Étapes suivantes
Maintenant que vous êtes familiarisé avec les principes fondamentaux de l’indexation de SQL Database, examinons de plus près la configuration de l’indexeur.