Tutoriel C# : Utiliser des ensembles de compétences pour générer du contenu pouvant faire l’objet d’une recherche dans Recherche Azure AI
Dans ce tutoriel, découvrez comment utiliser le Kit de développement logiciel (SDK) Azure pour .NET afin de créer un pipeline d’enrichissement par IA pour l’extraction de contenu et les transformations lors de l’indexation.
Les ensembles de compétences ajoutent un traitement IA au contenu brut, ce qui rend ce contenu plus uniforme et le rendant disponible pour faire l’objet d’une recherche. Une fois que vous savez comment fonctionnent les ensembles de compétences, vous pouvez prendre en charge un large éventail de transformations : de l’analyse d’images, au traitement en langage naturel, au traitement personnalisé que vous fournissez en externe.
Dans ce tutoriel, vous allez voir comment :
- Définissez des objets dans un pipeline d’enrichissement.
- Créez un ensemble de compétences. Appeler la reconnaissance optique de caractères (OCR), la détection de langage, la reconnaissance d’entités et l’extraction de phrases clés.
- Exécutez le pipeline. Créez et chargez un index de recherche.
- Vérifiez les résultats en utilisant la recherche en texte intégral.
Si vous n’avez pas d’abonnement Azure, ouvrez un compte gratuit avant de commencer.
Vue d’ensemble
Ce tutoriel utilise C# et la bibliothèque de client Azure.Search.Documents pour créer une source de données, un index, un indexeur et des compétences.
L’indexeur pilote chaque étape du pipeline, en commençant par l’extraction de contenu d’exemples de données (texte non structuré et images) dans un conteneur d’objets blob sur Stockage Azure.
Une fois le contenu extrait, l’ensemble de compétences exécute des compétences intégrées de Microsoft pour rechercher et extraire des informations. Ces compétences incluent la reconnaissance optique de caractères (OCR) sur des images, la détection de la langue d’un texte, l’extraction des expressions clés et la reconnaissance d’entités (organisations). Les nouvelles informations créées par l’ensemble de compétences sont envoyées aux champs d’un index. Une fois l’index rempli, vous pouvez utiliser les champs dans des requêtes, des facettes et des filtres.
Prérequis
Remarque
Vous pouvez utiliser un service de recherche gratuit pour ce tutoriel. Le niveau gratuit vous limite à trois index, trois indexeurs et trois sources de données. Ce didacticiel crée une occurrence de chaque élément. Avant de commencer, veillez à disposer de l’espace suffisant sur votre service pour accepter les nouvelles ressources.
Télécharger les fichiers
Téléchargez un fichier zip du référentiel des exemples de données et extrayez le contenu. Découvrez comment.
Charger des exemples de données dans Stockage Azure
Dans Stockage Azure, créez un conteneur et nommez-le cog-search-demo.
Obtenez une chaîne de connexion de stockage pour pouvoir formuler une connexion dans Recherche Azure AI.
À gauche, sélectionnez Clés d’accès.
Copiez la chaîne de connexion pour la clé un ou la clé deux. La chaîne de connexion est similaire à l’exemple suivant :
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure AI services
L’enrichissement par IA intégré s’appuie sur Azure AI services, notamment le service de langage et Azure AI Vision pour le traitement des images et du langage naturel. Pour les petites charges de travail comme ce tutoriel, vous pouvez utiliser l’allocation gratuite de 20 transactions par indexeur. Pour les charges de travail plus volumineuses, attachez une ressource multirégion Azure AI Services à un ensemble de compétences pour la tarification de paiement à l’utilisation.
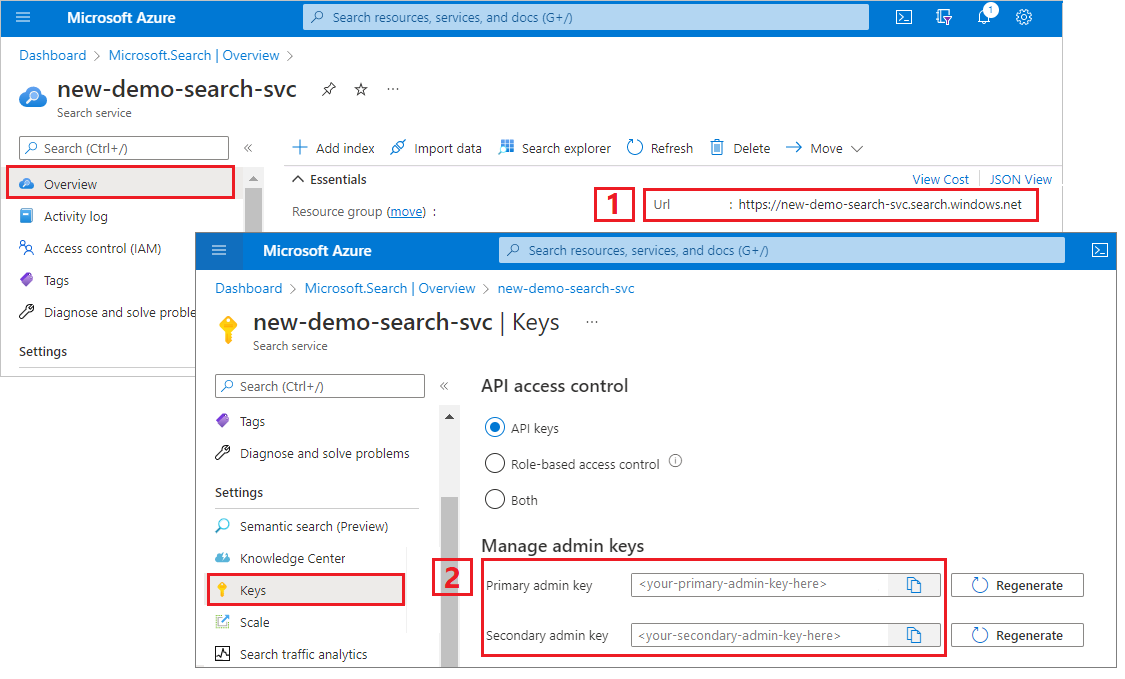
Copier l’URL et la clé API d’un service de recherche
Pour ce tutoriel, les connexions à Recherche Azure AI nécessitent un point de terminaison et une clé API. Vous pouvez obtenir ces valeurs à partir du Portail Azure.
Connectez-vous au Portail Azure, accédez à la page Vue d’ensemble du service de recherche et copiez l’URL. Voici un exemple de point de terminaison :
https://mydemo.search.windows.net.Sous Paramètres>Clés, copiez une clé d’administration. Les clés d’administration sont utilisées pour ajouter, modifier et supprimer des objets. Il existe deux clés d’administration interchangeables. Copiez l’une ou l’autre.
Paramétrer votre environnement
Commencez par ouvrir Visual Studio et créer un nouveau projet d’application console pouvant s’exécuter sur .NET Core.
Installer Azure.Search.Documents
Le SDK .NET d’Azure AI Search comprend une bibliothèque de client qui vous permet de gérer vos index, sources de données, indexeurs et compétences ainsi que de charger et gérer des documents et d’exécuter des requêtes, sans avoir à gérer les détails de HTTP et de JSON. Cette bibliothèque de client est distribuée en tant que package NuGet.
Pour ce projet, installez la version 11 ou ultérieure de la bibliothèque Azure.Search.Documents et la dernière version de Microsoft.Extensions.Configuration.
Dans Visual Studio, sélectionnez Outils>Gestionnaire de package NuGet>Gérer les packages NuGet pour la solution...
Recherchez Azure.Search.Document.
Sélectionnez la version la plus récente, puis sélectionnez Installer.
Répétez les étapes précédentes pour installer Microsoft.Extensions.Configuration et Microsoft.Extensions.Configuration.Json.
Ajouter les informations de connexion au service
Cliquez avec le bouton droit sur votre projet dans l’Explorateur de solutions et sélectionnez Ajouter>Nouvel élément... .
Nommez le fichier
appsettings.jsonet sélectionnez Ajouter.Incluez ce fichier dans votre répertoire de sortie.
- Cliquez avec le bouton droit sur
appsettings.json, puis sélectionnez Propriétés. - Remplacez la valeur Copier dans le répertoire de sortie par Copie du plus récent.
- Cliquez avec le bouton droit sur
Copiez le code JSON ci-dessous dans votre nouveau fichier JSON.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
Ajoutez les informations relatives à votre service de recherche, ainsi qu'à votre compte de stockage d'objets blob. Rappelez-vous que vous pouvez récupérer ces informations à partir des étapes de configuration du service indiquées dans la section précédente.
Pour SearchServiceUri, entrez l’URL complète.
Ajouter des espaces de noms
Dans Program.cs, ajoutez les espaces de noms suivants.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
Créer un client
Créez une instance d’un SearchIndexClient et d’un SearchIndexerClient sous Main.
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Notes
Les clients se connectent à votre service de recherche. Pour éviter l’ouverture d’un trop grand nombre de connexions, essayez de partager une seule instance dans votre application, si possible. Les méthodes sont thread-safe pour activer le partage.
Ajouter une fonction pour quitter le programme pendant des événements d’échec
Ce tutoriel est destiné à vous aider à comprendre chaque étape du pipeline d’indexation. En cas de problème critique empêchant le programme de créer la source de données, l’ensemble de compétences, l’index ou l’indexeur, le programme génère le message d’erreur et se ferme afin que le problème puisse être compris et résolu.
Ajoutez ExitProgram à Main pour gérer les scénarios qui nécessitent la fermeture du programme.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
Créer le pipeline
Dans Azure AI Search, le traitement de l’IA se produit pendant l’indexation (ou l’ingestion de données). Cette partie de la procédure pas à pas crée quatre objets : source de données, définition d’index, ensemble de compétences, indexeur.
Étape 1 : Création d'une source de données
SearchIndexerClient a une propriété DataSourceName que vous pouvez définir sur un objet SearchIndexerDataSourceConnection. Cet objet fournit toutes les méthodes dont vous avez besoin pour créer, afficher, mettre à jour ou supprimer des sources de données d’Azure AI Search.
Créer une nouvelle instance SearchIndexerDataSourceConnection en appelant indexerClient.CreateOrUpdateDataSourceConnection(dataSource). Le code suivant crée une source de données de type AzureBlob.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("cog-search-demo"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
Pour une requête réussie, la méthode renvoie la source de données créée. En cas de problème lié à la requête, comme un paramètre non valide, la méthode lève une exception.
Ajoutez maintenant une ligne dans Main pour appeler la fonction CreateOrUpdateDataSource que vous venez d’ajouter.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
Créez et exécutez la solution. Dans la mesure où il s’agit de votre première demande, vérifiez le portail Microsoft Azure pour confirmer que la source de données a été créée dans Azure AI Search. Dans la page de présentation du service de recherche, vérifiez que la liste Sources de données comporte un nouvel élément. Vous devrez peut-être attendre quelques minutes que la page du portail soit actualisée.

Étape 2 : Créer un ensemble de compétences
Dans cette section, vous définissez un ensemble d’étapes d’enrichissement que vous souhaitez appliquer à vos données. Chaque étape d’enrichissement est appelée compétence et l’ensemble des étapes d’enrichissement, ensemble de compétences. Ce tutoriel utilise des compétences prédéfinies pour l’ensemble de compétences :
Reconnaissance optique de caractères pour reconnaître le texte imprimé et manuscrit dans des fichiers image.
Fusion de texte pour consolider le texte issu d’une collection de champs en un seul champ de « contenu fusionné ».
Détection de la langue pour identifier la langue du contenu.
Reconnaissance d’entité pour extraire les noms d’organisations du contenu dans le conteneur d’objets blob.
Fractionnement de texte pour découper un texte long en plus petits morceaux avant d’appeler les compétences d’extraction de phrases clés et de reconnaissance d’entités. Les compétences d’extraction de phrases clés et de reconnaissance d’entités acceptent les entrées de 50 000 caractères maximum. Certains fichiers d’exemple doivent être fractionnés pour satisfaire cette limite.
Extraction de phrases clés pour extraire les principales expressions clés.
Lors du traitement initial, Azure AI Search interprète chaque document pour extraire le contenu de fichiers de différents formats. Le texte originaire du fichier source est placé dans un champ content généré, un pour chaque document. Par conséquent, définissez l’entrée en tant que "/document/content" de manière à utiliser ce texte. Le contenu de l’image est placé dans un champ normalized_images généré, spécifié dans un ensemble de compétences en tant que /document/normalized_images/*.
Les sorties peuvent être mappées à un index, utilisées comme entrée d’une compétence en aval, ou les deux, comme c’est le cas avec le code de langue. Dans l’index, un code de langue est utile pour le filtrage. En tant qu’entrée, le code de langue est utilisé par les compétences d’analyse de texte pour informer les règles linguistiques en matière de césure de mots.
Pour plus d’informations sur les principes de base des ensembles de compétences, consultez Guide pratique pour définir un ensemble de compétences.
Compétence de reconnaissance optique des caractères
OcrSkill extrait le texte des images. Cette compétence suppose l’existence d’un champ normalized_images. Pour générer ce champ, plus loin dans ce tutoriel, nous définissons la configuration "imageAction" dans la définition de l’indexeur sur "generateNormalizedImages".
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
Compétence de fusion de texte
Dans cette section, vous créez MergeSkill qui fusionne le champ de contenu de document avec le texte généré par la compétence de reconnaissance optique de caractères.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
Compétence Détection de langue
LanguageDetectionSkill détecte la langue du texte d’entrée et retourne un code de langue unique pour chaque document soumis dans la requête. Nous utilisons la sortie de la compétence Détection de langue en tant qu'entrée pour la compétence Fractionnement de texte.
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
Compétence Fractionnement de texte
SplitSkill ci-dessous fractionne le texte par pages et limite la longueur de la page à 4 000 caractères comme indiqué par String.Length. L’algorithme tente de fractionner le texte en blocs dont la taille n'excède pas maximumPageLength. Dans ce cas, l’algorithme fait de son mieux pour arrêter la phrase sur une limite de phrase, de sorte que la taille du bloc puisse être légèrement inférieure à maximumPageLength.
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
Compétence de reconnaissance d’entités
Cette instance EntityRecognitionSkill est configurée pour reconnaître le type de catégorie organization. EntityRecognitionSkill peut également reconnaître les types de catégories person et location.
Notez que le champ « contexte » contient la valeur "/document/pages/*" avec un astérisque, ce qui signifie que l’étape d’enrichissement est appelée pour chaque page sous "/document/pages".
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
EntityRecognitionSkill entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
Compétence Extraction de phrases clés
Comme l’instance EntityRecognitionSkill qui vient d’être créée, le KeyPhraseExtractionSkill est appelé pour chaque page du document.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
Générer et créer l'ensemble de compétences
Générez l'SearchIndexerSkillset en utilisant les compétences que vous avez créées.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Azure AI services was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
Ajoutez les lignes suivantes à Main.
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
Étape 3 : Création d'un index
Dans cette section, vous définissez le schéma d’index en spécifiant les champs à inclure dans l’index de recherche et les attributs de recherche pour chaque champ. Les champs ont un type et peuvent prendre des attributs qui déterminent la façon dont le champ est utilisé (pour la recherche, le tri, etc.). Les noms des champs dans un index ne sont pas tenus de correspondre exactement aux noms des champs dans la source. Dans une étape ultérieure, vous ajoutez des mappages de champs dans un indexeur pour connecter les champs sources et de destination. Pour cette étape, définissez l’index à l’aide de conventions d’affectation de noms de champs appropriées à votre application de recherche.
Cet exercice utilise les champs et les types de champ suivants :
| Noms de champs | Types de champ |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
List<Edm.String> |
organizations |
List<Edm.String> |
Créer la classe DemoIndex
Les champs de cet index sont définis à l’aide d’une classe de modèle. Chaque propriété de la classe de modèle comporte des attributs qui déterminent les comportements liés à la recherche du champ d’index correspondant.
Nous allons ajouter la classe de modèle à un nouveau fichier C#. Sélectionnez avec un clic droit sur votre projet et sélectionnez Ajouter>Nouvel élément..., sélectionnez « Classe » et nommez le fichier DemoIndex.cs, puis sélectionnez Ajouter.
Veillez à indiquer que vous souhaitez utiliser des types à partir des espaces de noms Azure.Search.Documents.Indexes et System.Text.Json.Serialization.
Ajoutez la définition de classe de modèle ci-dessous à DemoIndex.cs et incluez-la dans le même espace de noms que celui où vous créez l’index.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
Maintenant que vous avez défini une classe de modèle, de retour dans Program.cs, vous pouvez créer facilement une définition d’index. Le nom de cet index sera demoindex. Si un index portant ce nom existe déjà, il est supprimé.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
Pendant le test, vous serez peut-être amené à tenter de créer l’index plusieurs fois. Dès lors, vérifiez si l’index que vous vous apprêtez à créer existe avant de tenter de le créer.
Ajoutez les lignes suivantes à Main.
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
Ajoutez l’instruction using suivante pour résoudre la référence ambiguë.
using Index = Azure.Search.Documents.Indexes.Models;
Pour en savoir plus sur les concepts d’index, consultez Créer un index (API REST).
Étape 4 : Créer et exécuter un indexeur
À ce stade, vous avez créé une source de données, un ensemble de compétences et un index. Ces trois composants deviennent partie intégrante d’un indexeur qui extrait chaque élément pour l’insérer dans une opération unique à plusieurs phases. Pour lier ces éléments en un indexeur, vous devez définir des mappages de champs.
Les fieldMappings sont traités avant l’ensemble de compétences, en mappant les champs sources de la source de données sur des champs cibles dans un index. Si les noms et types de champ sont identiques aux deux extrémités, aucun mappage n’est nécessaire.
Les outputFieldMappings sont traités après l’ensemble de compétences, en référençant les sourceFieldNames qui n’existent pas tant que le décodage de document ou l’enrichissement ne les ont pas créés. targetFieldName est un champ dans un index.
En plus de lier des entrées à des sorties, vous pouvez également utiliser les mappages de champs pour aplatir les structures de données. Pour plus d’informations, consultez Guide pratique pour mapper des champs enrichis sur un index pouvant faire l’objet d’une recherche.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
Ajoutez les lignes suivantes à Main.
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
Le traitement de l’indexeur peut prendre un certain temps. Même si le jeu de données est petit, les compétences analytiques exigent des calculs intensifs. Certaines compétences, telles que l’analyse d’image, sont des opérations longues.
Conseil
La création d’un indexeur appelle le pipeline. En cas de problèmes pour atteindre les données, mapper les entrées et les sorties, ou ordonner les opérations, ceux-ci apparaissent à ce stade.
Explorer la création de l’indexeur
Le code affecte à "maxFailedItems" la valeur -1, ce qui indique au moteur d’indexation d’ignorer les erreurs au cours de l’importation des données. Cela est utile car très peu de documents figurent dans la source de données de démonstration. Pour une source de données plus volumineuse, vous définiriez une valeur supérieure à 0.
Notez également la définition de "dataToExtract" sur "contentAndMetadata". Cette instruction indique à l’indexeur d’extraire automatiquement le contenu de fichiers de différents formats, ainsi que les métadonnées associées à chaque fichier.
Lorsque le contenu est extrait, vous pouvez définir imageAction pour extraire le texte des images trouvées dans la source de données. La configuration "imageAction" définie sur "generateNormalizedImages", associée à la compétence de reconnaissance optique des caractères et à la compétence de fusion de texte, indique à l’indexeur d’extraire le texte des images (par exemple, le mot « stop » d’un panneau de signalisation Stop) et de l’incorporer dans le champ de contenu. Ce comportement s’applique aux images intégrées dans les documents (pensez à une image dans un fichier PDF), ainsi qu’aux images trouvées dans la source de données, par exemple un fichier JPG.
Surveiller l’indexation
Une fois l’indexeur défini, il s’exécute automatiquement lorsque vous envoyez la demande. Selon les compétences que vous avez définies, l’indexation peut prendre plus de temps que prévu. Pour savoir si l’indexeur est toujours en cours d’exécution, utilisez la méthode GetStatus.
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure Portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo correspond à l'historique actuel d'état et d'exécution d'un indexeur.
Les avertissements sont courants avec certaines combinaisons de fichiers sources et de compétences, et n’indiquent pas toujours un problème. Dans ce tutoriel, les avertissements sont sans gravité (par exemple, aucune entrée de texte à partir des fichiers JPEG).
Ajoutez les lignes suivantes à Main.
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Recherche
Dans les applications console des tutoriels Azure AI Search, nous ajoutons généralement un délai de 2 secondes avant l’exécution des requêtes qui retournent des résultats, mais comme l’enrichissement prend plusieurs minutes, nous allons fermer l’application console et utiliser une autre approche.
L’option la plus simple consiste à utiliser l’Explorateur de recherche dans le portail. Vous pouvez d’abord exécuter une requête vide qui retourne tous les documents ou une recherche plus ciblée qui retourne un contenu de champ créé par le pipeline.
Dans le portail Azure, dans la page de présentation de la recherche, sélectionnez index.
Recherchez
demoindexdans la liste. Il doit comporter 14 documents. Si le nombre de documents est égal à zéro, l’indexeur est toujours en cours d’exécution ou la page n’a pas encore été actualisée.Sélectionnez
demoindex. L’Explorateur de recherche est le premier onglet.Le contenu peut faire l’objet d’une recherche dès que le premier document est chargé. Pour vérifier que le contenu existe, exécutez une requête non spécifiée en cliquant sur Rechercher. Cette requête retourne tous les documents indexés, ce qui vous donne une idée du contenu de l’index.
Collez ensuite la chaîne suivante pour obtenir des résultats plus faciles à gérer :
search=*&$select=id, languageCode, organizations
Réinitialiser et réexécuter
Dans les premières étapes expérimentales de développement, l’approche la plus pratique pour les itérations de conception consiste à supprimer les objets d’Azure AI Search et à autoriser votre code à les reconstruire. Les noms des ressources sont uniques. La suppression d’un objet vous permet de le recréer en utilisant le même nom.
L’exemple de code pour ce tutoriel recherche les objets existants et les supprime pour vous permettre de réexécuter votre code. Vous pouvez aussi utiliser le portail pour supprimer les index, les indexeurs et les ensembles de compétences.
Éléments importants à retenir
Ce tutoriel présente les étapes de base pour générer un pipeline d’indexation enrichie via la création de composants : une source de données, un ensemble de compétences, un index et un indexeur.
Les compétences intégrées ont été introduites, ainsi que la définition d’un ensemble de compétences et les mécanismes de chaînage de compétences via des entrées et des sorties. Vous avez également appris que outputFieldMappings est requis dans la définition de l’indexeur pour acheminer les valeurs enrichies du pipeline dans un index de recherche, sur un service d’Azure AI Search.
Enfin, vous avez appris à tester les résultats et réinitialiser le système pour des itérations ultérieures. Vous avez appris qu’émettre des requêtes par rapport à l’index retourne la sortie créée par le pipeline d’indexation enrichie. Vous avez également appris à vérifier l’état de l’indexeur et quels objets supprimer avant de réexécuter un pipeline.
Nettoyer les ressources
Lorsque vous travaillez dans votre propre abonnement, il est judicieux à la fin d’un projet de supprimer les ressources dont vous n’avez plus besoin. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources une par une, ou choisir de supprimer le groupe de ressources afin de supprimer l’ensemble des ressources.
Vous pouvez rechercher et gérer les ressources dans le portail à l’aide des liens Toutes les ressources ou Groupes de ressources situés dans le volet de navigation de gauche.
Étapes suivantes
Maintenant que vous êtes familiarisé avec tous les objets d’un pipeline d’enrichissement par IA, examinons de plus près les définitions des ensembles de compétences et les compétences individuelles.