Extraire du texte et des informations d’images en utilisant l’enrichissement par IA
Grâce à l’enrichissement par IA, Azure AI Search offre plusieurs options pour créer et extraire du texte pouvant faire l’objet de recherches à partir d’images, y compris :
- OCR pour la reconnaissance optique de caractères du texte et des chiffres
- Analyse d’images qui décrit les images via des caractéristiques visuelles
- Compétences personnalisées pour appeler n’importe quel traitement d’images externe que vous voulez fournir
En utilisant l’OCR, vous pouvez extraire du texte à partir de photos ou d’images contenant du texte alphanumérique, comme le mot STOP sur un panneau stop. Via l’analyse d’images, vous pouvez générer une représentation textuelle d’une image, comme pissenlit pour une photo de pissenlit ou la couleur jaune. Vous pouvez également extraire des métadonnées de l’image, telles que sa taille.
Cet article couvre les bases du travail avec des images et décrit également plusieurs scénarios courants, comme l’utilisation d’images incorporées, les compétences personnalisées et la superposition de visualisations sur les images d’origine.
Pour travailler avec du contenu d’image dans un ensemble de compétences, vous avez besoin des éléments suivants :
- Les fichiers sources qui incluent des images
- Un indexeur de recherche, configuré pour les actions d’image
- Un ensemble de compétences avec des compétences intégrées ou personnalisées qui appellent la reconnaissance optique de caractères ou l’analyse d’image
- Un index de recherche avec des champs pour recevoir la sortie texte analysée, ainsi que des mappages de champs de sortie dans l’indexeur qui établissent l’association
Si vous le souhaitez, vous pouvez définir des projections pour accepter la sortie analysée des images dans une base de connaissances pour des scénarios d’exploration de données.
Configurer les fichiers sources
Le traitement d’image est piloté par un indexeur, ce qui signifie que les entrées brutes doivent provenir d’une source de données prise en charge.
- Analyse d’image prend en charge JPEG, PNG, GIF et BMP
- OCR prend en charge JPEG, PNG, BMP et TIF
Les images peuvent être des fichiers binaires autonomes ou incorporées dans des documents tels que des fichiers PDF, RTF ou d’application Microsoft. Un maximum de 1 000 images peuvent être extraites d’un document donné. Si un document contient plus de 1 000 images, les 1 000 premières sont extraites, puis un avertissement est généré.
Azure Blob Storage est le stockage le plus fréquemment utilisé pour le traitement d’images dans Azure AI Search. Trois tâches principales sont liées à la récupération d’images à partir d’un conteneur d’objets blob :
Activez l’accès au contenu du conteneur. Si vous utilisez une chaîne de connexion à accès complet qui comprend une clé, cette dernière vous donne l’autorisation d’accéder au contenu. Vous pouvez également vous authentifier à l’aide de Microsoft Entra ID ou vous connecter en tant que service approuvé.
Créez une source de données de type azureblob qui se connecte au conteneur de blobs stockant vos fichiers.
Passez en revue les limites du niveau de service pour vous assurer que vos données sources ne dépassent pas les limites de taille et de quantité pour les indexeurs et l’enrichissement.
Configurer des indexeurs pour le traitement d’image
Une fois les fichiers sources configurés, activez la normalisation des images en définissant le paramètre imageAction dans la configuration de l’indexeur. La normalisation des images permet de rendre les images plus uniformes pour le traitement en aval. La normalisation des images comprend les opérations suivantes :
- Les images de grande taille sont redimensionnées à une hauteur et une largeur maximales afin de les rendre uniformes.
- Pour les images qui ont des métadonnées qui spécifient l’orientation, la rotation est ajustée pour un chargement vertical.
Les ajustements de métadonnées sont capturés dans un type complexe créé pour chaque image. Vous ne pouvez pas refuser l’exigence de normalisation de l’image. Les compétences qui effectuent des itérations sur les images, comme la reconnaissance optique de caractères et l’analyse des images, attendent des images normalisées.
Créez ou mettez à jour un indexeur pour définir les propriétés de configuration :
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Définissez
dataToExtractsurcontentAndMetadata(obligatoire).Vérifiez que
parsingModeest défini avec la valeur par défaut (obligatoire).Ce paramètre détermine la précision des documents de recherche créés dans l’index. Le mode par défaut configure une correspondance un-à-un, de façon à ce qu’un objet blob génère un seul document de recherche. Si les documents sont grands ou si les compétences nécessitent des segments de texte plus petits, vous pouvez ajouter une compétence Découpage du texte, qui subdivise un document en pages pour le traitement. Cependant, pour les scénarios de recherche, un seul objet blob par document est obligatoire si l’enrichissement comprend le traitement de l’image.
Définissez
imageActionde façon à activer le nœudnormalized_imagesdans une arborescence d’enrichissement (obligatoire) :generateNormalizedImagespour générer un tableau d’images normalisées dans le cadre de la décomposition des documents.generateNormalizedImagePerPage(s’applique aux PDF uniquement) pour générer un tableau d’images normalisées où chaque page du document PDF est rendue dans une image de sortie. Pour les fichiers non-PDF, le comportement de ce paramètre est le même que si vous définissezgenerateNormalizedImages. Toutefois, notez que la définition degenerateNormalizedImagePerPagepeut rendre l’opération d’indexation moins performante par défaut (en particulier pour les grands documents), car plusieurs images doivent être générées.
Si vous le souhaitez, ajustez la largeur ou la hauteur des images normalisées générées :
normalizedImageMaxWidthen pixels. La valeur par défaut est de 2 000. La valeur maximale est de 10 000.normalizedImageMaxHeighten pixels. La valeur par défaut est de 2 000. La valeur maximale est de 10 000.
La valeur par défaut de 2 000 pixels pour la hauteur et la largeur maximales des images normalisées est basée sur les tailles maximales prises en charge par la compétence OCR et la compétence Analyse d’image. La compétence OCR prend en charge une largeur et une hauteur maximales de 4 200 pour les langues autres que l’anglais et de 10 000 pour l’anglais. Si vous augmentez les limites maximales, le traitement des images plus volumineuses peut échouer en fonction de la définition de vos compétences et de la langue des documents.
Si vous le souhaitez, définissez des critères de type de fichier si la charge de travail cible un type de fichier spécifique. La configuration de l’indexeur d’objets blob comprend des paramètres d’inclusion et d’exclusion de fichiers. Vous pouvez filtrer les fichiers dont vous ne voulez pas.
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
À propos des images normalisées
Lorsque imageAction a une valeur autre que none, le nouveau champ normalized_images contient un tableau d’images. Chaque image est un type complexe qui a les membres suivants :
| Membre de l’image | Description |
|---|---|
| data | Chaîne codée en Base64 de l’image normalisée au format JPEG. |
| width | Largeur de l’image normalisée en pixels. |
| height | Hauteur de l’image normalisée en pixels. |
| originalWidth | Largeur d’origine de l’image avant la normalisation. |
| originalHeight | Hauteur d’origine de l’image avant la normalisation. |
| rotationFromOriginal | Rotation dans le sens inverse des aiguilles d’une montre exprimée en degrés pour créer l’image normalisée. Valeur comprise entre 0 et 360 degrés. Cette étape lit les métadonnées de l’image générée par un appareil photo ou un scanneur. La valeur est généralement un multiple de 90 degrés. |
| contentOffset | Offset de caractère à l’intérieur du champ de contenu dont l’image a été extraite. Ce champ est applicable uniquement aux fichiers contenant des images incorporées. Le contentOffset pour les images extraites de documents PDF est toujours à la fin du texte de la page à partir de laquelle il a été extrait dans le document. Cela signifie que les images apparaissent après tout le texte de cette page, quel que soit l’emplacement d’origine de l’image dans la page. |
| pageNumber | Si l'image a été extraite ou rendue à partir d'un PDF, ce champ contient le numéro de page du PDF à partir de laquelle elle a été extraite ou rendue, à partir de 1. Si l’image ne provient pas d’un fichier PDF, ce champ est 0. |
Exemple de valeur de normalized_images :
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
Définir des ensembles de compétences pour le traitement d’image
Cette section complète les articles d’informations de référence sur les compétences en fournissant un contexte pour le travail avec des entrées, des sorties et des modèles de compétences, car elles sont liées au traitement d’image.
Créez ou mettez à jour un ensemble de compétences pour ajouter des compétences.
Ajoutez des modèles pour OCR et Analyse d’images à partir du portail, ou copiez les définitions à partir de la documentation Informations de référence sur les compétences. Insérez-les dans le tableau de compétences de votre définition d’ensemble de compétences.
Si nécessaire, incluez une clé multiservice dans la propriété Azure AI services de l’ensemble de compétences. Azure AI Search effectue des appels à une ressource Azure AI Services facturable pour l’OCR et l’analyse d’images pour les transactions qui dépassent la limite gratuite (20 par indexeur par jour). Les services Azure AI doivent se trouver dans la même région que votre service de recherche.
Si les images d’origine sont incorporées dans des fichiers PDF ou d’application de type PPTX ou DOCX, vous devez ajouter une compétence Fusion de texte pour que la sortie contienne à la fois les images et le texte. L’utilisation d’images incorporées est abordée plus loin dans cet article.
Une fois que l’infrastructure de base de votre ensemble de compétences est créée et que les services Azure AI sont configurés, vous pouvez vous concentrer sur chaque compétence d’image individuelle, définir les entrées et le contexte source et mapper les sorties aux champs d’un index ou d’une base de connaissances.
Remarque
Pour obtenir un exemple d’ensemble de compétences qui combine le traitement d’images avec le traitement du langage naturel en aval, consultez Tutoriel REST : Utiliser REST et l’IA pour générer du contenu pouvant faire l’objet de recherche à partir d’objets blob Azure. Il montre comment alimenter la sortie d’image d’une compétence en reconnaissance d’entités et en extraction d’expressions clés.
Entrées pour le traitement d’images
Comme nous l’avons vu, les images sont extraites lors de la décomposition des documents, puis elles sont normalisées à titre d’étape préliminaire. Les images normalisées sont les entrées de n’importe quelle compétence de traitement d’image et elles sont toujours représentées dans une arborescence de documents enrichie de l’une des deux façons suivantes :
/document/normalized_images/*est pour les documents traités comme un tout./document/normalized_images/*/pagesest pour les documents traités en segments (pages).
Que vous utilisiez l’OCR et l’analyse des images, les entrées ont pratiquement la même construction :
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Mapper des sorties à des champs de recherche
Dans un ensemble de compétences, la sortie de la compétence OCR et Analyse d’image est toujours du texte. Le texte en sortie est représenté sous forme de nœuds dans une arborescence interne de documents enrichis, et chaque nœud doit être mappé à des champs dans un index de recherche, ou à des projections dans une base de connaissances, afin de rendre le contenu disponible dans votre application.
Dans l’ensemble de compétences, passez en revue la section
outputsde chaque compétence pour déterminer les nœuds qui existent dans le document enrichi :{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Créez ou mettez à jour un index de recherche pour ajouter des champs afin d’accepter les sorties des compétences.
Dans l’exemple de collection de champs suivant, content est un contenu de blob. Metadata_storage_name comprend le nom du fichier (définissez
retrievablesur true). Metadata_storage_path est le chemin unique du blob et la clé de document par défaut. Merged_content est la sortie de Fusion de texte (utile quand les images sont incorporées).Text et layoutText sont des sorties de compétences OCR qui doivent être une collection de chaînes afin de capturer toute la sortie générée par OCR de l’ensemble du document.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Mettez à jour l’indexeur pour mapper la sortie de l’ensemble de compétences (les nœuds dans une arborescence d’enrichissement) aux champs d’index.
Les documents enrichis sont internes. Pour externaliser les nœuds dans une arborescence de documents enrichie, configurez un mappage de champs de sortie qui spécifie le champ d’index qui reçoit le contenu du nœud. Les données enrichies sont accessibles par votre application via un champ d’index. L’exemple suivant montre un nœud text (sortie OCR) dans un document enrichi mappé à un champ text dans un index de recherche.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Exécutez l’indexeur pour appeler la récupération des documents sources, le traitement d’image et l’indexation.
Vérifier les résultats
Exécutez une requête sur l’index pour vérifier les résultats du traitement d’image. Utilisez l’Explorateur de recherche en tant que client de recherche, ou tout outil qui envoie des requêtes HTTP. La requête suivante sélectionne les champs qui contiennent la sortie du traitement d’image.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
L’OCR reconnaît le texte dans les fichiers image. Cela signifie que les champs OCR (text et layoutText) sont vides si les documents sources sont du texte pur ou des images pures. De même, les champs d’analyse d’images (imageCaption et imageTags) sont vides si les entrées des documents sources sont exclusivement du texte. L’exécution de l’indexeur émet des avertissements si les entrées d’imagerie sont vides. Ces avertissements sont attendus quand les nœuds ne sont pas remplis dans le document enrichi. Rappelez-vous que l’indexation d’objets blob vous permet d’inclure ou d’exclure des types de fichiers si vous voulez travailler avec des types de contenu spécifiques. Vous pouvez utiliser ces paramètres pour réduire le bruit pendant les exécutions de l’indexeur.
Une autre requête de vérification des résultats peut inclure les champs content et merged_content. Notez que ces champs incluent du contenu pour n’importe quel fichier blob, même ceux où aucun traitement d’image n’a été effectué.
À propos des sorties des compétences
Les sorties de compétence incluent text (OCR), layoutText (OCR), merged_content, captions (analyse d’images), tags (analyse d’images) :
textstocke la sortie générée par OCR. Ce nœud doit être mappé à un champ de typeCollection(Edm.String). Il y a un seul champtextpar document de recherche, constitué de chaînes délimitées par des virgules pour les documents qui contiennent plusieurs images. L’illustration suivante montre la sortie OCR pour trois documents. Le premier est un document contenant un fichier sans images. Le deuxième est un document (fichier image) contenant un seul mot, Microsoft. Le troisième est un document contenant plusieurs images, certaines sans aucun texte ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]layoutTextstocke les informations générées par OCR sur l’emplacement du texte dans la page, décrites en termes de cadres englobants et de coordonnées de l’image normalisée. Ce nœud doit être mappé à un champ de typeCollection(Edm.String). Il y a un seul champlayoutTextpar document de recherche, constitué de chaînes délimitées par des virgules.merged_contentstocke la sortie d’une compétence Fusion de texte. Ce doit être un grand champ de typeEdm.Stringqui contient le texte brut du document source, avec letextincorporé à la place d’une image. Si les fichiers contiennent seulement du texte, l’OCR et l’analyse d’images n’ont rien à faire, etmerged_contentest identique àcontent(une propriété de blob qui contient le contenu du blob).imageCaptioncapture une description d’une image sous forme d’étiquettes individuelles et une description texte plus longue.imageTagsstocke les étiquettes concernant une image sous la forme d’une collection de mots clés. Il y a une seule collection pour toutes les images du document source.
La capture d’écran suivante est une illustration d’un PDF qui inclut du texte et des images incorporées. Le craquage de document a détecté trois images incorporées : groupe de mouettes, carte, aigle. D’autres texte de l’exemple (y compris les titres, les titres et le texte du corps) ont été extraits en tant que texte et exclus du traitement d’images.
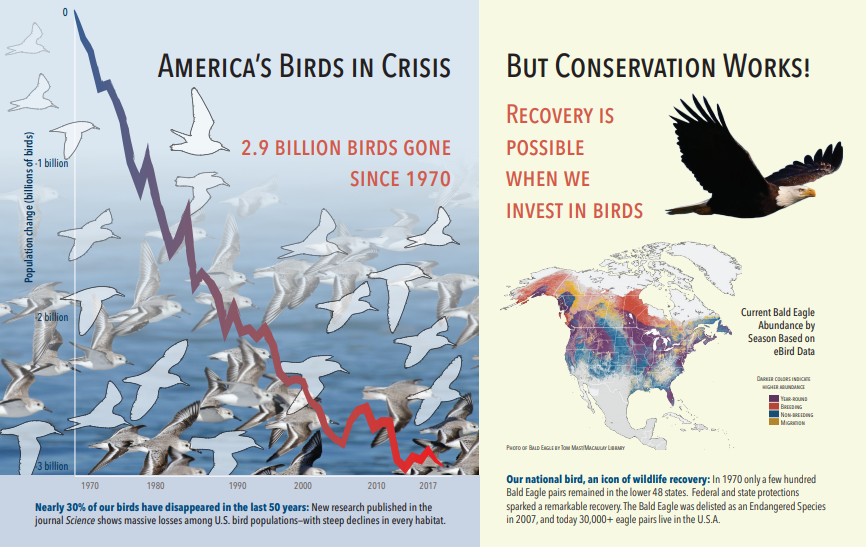
La sortie de l’analyse d’images est illustrée dans le JSON suivant (résultat de la recherche). La définition de compétence vous permet de spécifier les fonctionnalités visuelles qui sont intéressantes. Pour cet exemple, les balises et les descriptions ont été produites, mais il existe plus de sorties à choisir.
La sortie
imageCaptionest un tableau de descriptions, un par image, avec destagscomposés de mots seuls et d’expressions plus longues qui décrivent l’image. Remarquez les étiquettes a flock of seagulls are swimming in the water ou a close up of a bird.Une sortie
imageTagsest un tableau d’étiquettes seules, listées dans l’ordre de création. Notez que les étiquettes se répètent. Il n’y a pas d’agrégation ou de regroupement.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Scénario : Images incorporées dans des PDF
Quand les images que vous voulez traiter sont incorporées dans d’autres fichiers, comme des fichiers PDF ou DOCX, le pipeline d’enrichissement extrait seulement les images, puis les passe à l’OCR ou à l’analyse d’images pour traitement. L’extraction d’images se produit pendant la phase de craquage de document, et une fois que les images sont séparées, elles le restent, sauf si vous refusionnez explicitement la sortie traitée dans le texte source.
Fusion de texte est utilisée pour replacer la sortie du traitement d’image dans le document. Bien que Fusion de texte ne soit pas une exigence stricte, elle est souvent appelée pour que la sortie d’image (texte OCR, layoutText OCR, étiquettes d’image, légendes d’image) puisse être réintroduite dans le document. Selon la compétence, la sortie d’image remplace une image binaire incorporée par un équivalent de texte en place. La sortie de l’analyse d’image peut être fusionnée à l’emplacement de l’image. La sortie OCR apparaît toujours à la fin de chaque page.
Le workflow suivant décrit le processus d’extraction, d’analyse et de fusion des images, et comment étendre le pipeline pour envoyer la sortie traitée par image dans d’autres compétences texte, comme Reconnaissance d’entités ou Traduction de texte.
Après la connexion à la source de données, l’indexeur charge et décompose les documents sources, en extrayant les images et le texte, et met en file d’attente chaque type de contenu pour traitement. Un document enrichi constitué uniquement d’un nœud racine (document) est créé.
Les images de la file d’attente sont normalisées et passées à des documents enrichis en tant que nœud document/normalized_images.
Les enrichissements d’image s’exécutent, en
"/document/normalized_images"comme entrée.Les sorties d’image sont passées à l’arborescence de documents enrichie, chaque sortie étant un nœud distinct. Les sorties varient en fonction de la compétence (text et layoutText pour OCR, étiquettes et légendes pour Analyse d’images).
Facultatif mais recommandé : si vous voulez que les documents de recherche incluent à la fois le texte et le texte d’origine de l’image, exécutez Fusion de texte, qui va combiner la représentation textuelle de ces images avec le texte brut extrait du fichier. Les blocs de texte sont consolidés dans une seule chaîne volumineuse, où le texte est inséré en premier dans la chaîne, puis les balises et légendes de texte OCR.
La sortie de Fusion de texte est maintenant le texte définitif à analyser pour les compétences en aval qui vont effectuer le traitement du texte. Par exemple, si votre ensemble de compétences inclut à la fois OCR et Reconnaissance d’entités, l’entrée de Reconnaissance d’entités doit être
"document/merged_text"(targetName dans la sortie de la compétence Fusion de texte).Une fois que toutes les compétences ont été exécutées, le document enrichi est terminé. Dans la dernière étape, les indexeurs font référence aux mappages des champs de sortie pour envoyer le contenu enrichi à des champs individuels de l’index de recherche.
L’exemple de compétences suivant crée un champ merged_text contenant le texte d’origine de votre document avec du texte reconnu par OCR incorporé à la place des images incorporées. Il comprend également une compétence Reconnaissance d’entités qui utilise merged_text comme entrée.
Syntaxe du corps de la demande
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
À présent que vous avez un champ merged_text, vous pouvez le mapper en tant que champ pouvant faire l’objet d’une recherche dans la définition de votre indexeur. Tout le contenu de vos fichiers, y compris le texte des images, sera disponible pour une recherche.
Scénario : Visualiser les cadres englobants
Un autre scénario courant est la visualisation des informations de disposition des résultats de recherche. Par exemple, dans le cadre de vos résultats de recherche, vous pouvez vouloir mettre en évidence l’endroit où un élément de texte a été trouvé dans une image.
Étant donné que l’étape OCR est effectuée sur les images normalisées, les coordonnées de disposition sont dans l’espace d’image normalisée. Si vous devez afficher l’image d’origine, convertissez les points de coordonnées dans la disposition vers le système de coordonnées d’image d’origine.
L’algorithme suivant illustre le modèle :
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Scénario : Ensemble de compétences d’images personnalisées
Des images peuvent également être transmises et retournées dans des compétences personnalisées. Un ensemble de compétences encode en base64 l’image transmise dans la compétence personnalisée. Pour utiliser l’image dans la compétence personnalisée, définissez "/document/normalized_images/*/data" comme entrée dans la compétence personnalisée. Dans votre code de compétence personnalisée, décodez en base64 la chaîne avant de la convertir en image. Pour retourner une image à l’ensemble de compétences, encodez-la en base64 au préalable.
L’image est retournée en tant qu’objet avec les propriétés suivantes.
{
"$type": "file",
"data": "base64String"
}
Le référentiel d’exemples Python pour Recherche Azure présente un exemple complet implémenté en Python d’une compétence personnalisée qui enrichit les images.
Passage d’images aux compétences personnalisées
Pour les scénarios où vous avez besoin d’une compétence personnalisée pour travailler sur les images, vous pouvez faire passer des images à la compétence personnalisée et faire en sorte qu’elle retourne du texte ou des images. L’ensemble de compétences suivant provient d’un exemple.
L’ensemble de compétences suivant prend l’image normalisée (obtenue lors du craquage de document) et génère des tranches de l’image.
Exemple d’ensemble de compétences
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Exemple de compétence personnalisée
La compétence personnalisée elle-même est externe à l’ensemble de compétences. Ici, il s’agit de code Python qui effectue une boucle sur le lot d’enregistrements de requêtes dans le format de la compétence personnalisée, puis convertit la chaîne encodée en Base64 en image.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Comme pour le retour d’une image, une chaîne encodée en Base64 est retournée dans un objet JSON avec une propriété $type de fichier.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}