Configurations et opérations de l’infrastructure SAP HANA sur Azure
Ce document fournit des instructions pour la configuration des infrastructures Azure et le fonctionnement des systèmes SAP HANA qui sont déployés sur des machines virtuelles Azure natives. Le document inclut également des informations de configuration pour le scale-out de SAP HANA sur la référence SKU de machine virtuelle M128s. Ce document n’a pas pour but de remplacer la documentation SAP standard, qui propose le contenu suivant :
- SAP Administration Guide (Guide d’administration de SAP)
- SAP Installation Guide (Guide d’installation de SAP)
- Notes SAP
Prérequis
Pour utiliser ce guide, vous devez disposer des connaissances de base quant aux différents composants Azure suivants :
Pour en savoir plus sur SAP NetWeaver et d’autres composants SAP sur Azure, consultez la section SAP sur Azure de la documentation Azure.
Considérations de base relatives à la configuration
Les sections suivantes décrivent les considérations de base relatives à la configuration pour le déploiement de systèmes SAP HANA sur des machines virtuelles Azure.
Se connecter à des machines virtuelles Azure
Comme décrit dans le guide de planification des machines virtuelles Azure, il existe deux méthodes de base pour se connecter à des machines virtuelles Azure :
- Connexion par le biais de points de terminaison publics et Internet sur une machine virtuelle Jump ou la machine virtuelle qui exécute SAP HANA.
- Connexion par le biais d’un VPN ou d’Azure ExpressRoute.
Pour les scénarios de production, vous devez avoir une connectivité de site à site par le biais d’un VPN ou d’ExpressRoute. Ce type de connexion est également nécessaire pour les scénarios hors production qui alimentent des scénarios de production où des logiciels SAP sont utilisés. L’image suivante représente un exemple de connectivité intersite :
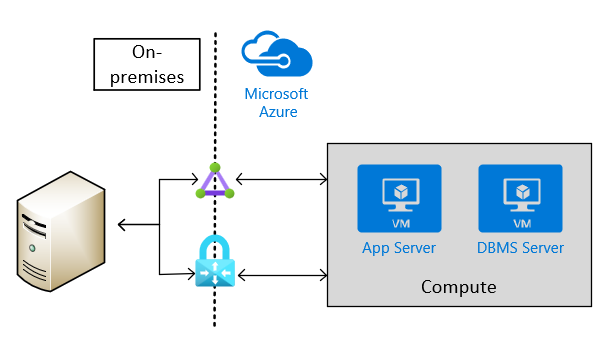
Choisir des types de machines virtuelles Azure
SAP liste les types de machines virtuelles Azure que vous pouvez utiliser pour les scénarios de production. Pour les scénarios hors production, une plus large gamme de types de machines virtuelles Azure natives est disponible.
Notes
Pour les scénarios hors production, utilisez les types de machines virtuelles qui sont répertoriés dans la note SAP #1928533. Pour les scénarios de production, utilisez les machines virtuelles Azure certifiées SAP HANA qui sont répertoriées dans la liste des plateformes IaaS certifiées publiée par SAP.
Déployez les machines virtuelles sur Azure en utilisant :
- le portail Azure ;
- les applets de commande Azure PowerShell ;
- l’interface de ligne de commande Azure.
Important
Pour pouvoir utiliser des machines virtuelles M208xx_v2, vous devez sélectionner avec soin votre image Linux. Pour plus d’informations, voir Tailles de machine virtuelle à mémoire optimisée.
Configuration du stockage pour SAP HANA
Pour les configurations de stockage et les types de stockage à utiliser avec SAP HANA dans Azure, consultez le document Configurations du stockage des machines virtuelles SAP HANA Azure
Configurer les réseaux virtuels Azure
Quand vous disposez d’une connectivité de site à site dans Azure via un VPN ou ExpressRoute, vous avez au minimum un réseau virtuel Azure connecté par le biais d’une passerelle virtuelle au circuit ExpressRoute ou VPN. Dans des déploiements simples, la passerelle virtuelle peut être déployée dans un sous-réseau du réseau virtuel (VNet) Azure qui héberge également les instances SAP HANA. Pour installer SAP HANA, vous devez créer deux sous-réseaux supplémentaires dans le réseau virtuel Azure. Un sous-réseau héberge les machines virtuelles pour exécuter les instances de SAP HANA. L’autre sous-réseau exécute des machines virtuelles Jumpbox ou de gestion pour héberger SAP HANA Studio, d’autres logiciels de gestion ou votre logiciel d’application.
Important
Par manque de fonctionnalités, mais surtout pour des raisons de performances, il n’est pas prévu de configurer Azure Network Virtual Appliances dans le chemin d’accès de communication entre l’application SAP et la couche SGBD d’un système SAP NetWeaver, Hybris ou S/4HANA basé sur SAP. La communication entre la couche application SAP et la couche SGBD doit être directe. La restriction n’inclut pas les règles Azure ASG et NSG tant que ces règles ASG et NSG permettent une communication directe. D’autres scénarios qui ne prennent pas en charge les appliances virtuelles réseau résident dans les chemins de communication entre les machines virtuelles Azure qui représentent les nœuds de cluster Linux Pacemaker et les appareils SBD comme décrit dans Haute disponibilité pour SAP NetWeaver sur les machines virtuelles Azure sur SUSE Linux Enterprise Server pour les applications SAP. Ou bien, dans les chemins de communication entre les machines virtuelles Azure et les systèmes SOFS Windows Server configurés comme décrit dans Mettre en cluster une instance SAP ASCS/SCS sur un cluster de basculement Windows à l’aide du partage de fichiers dans Azure. Les appliances virtuelles réseau dans les chemins de communication peuvent facilement doubler la latence du réseau entre deux partenaires de communication et limiter le débit dans les chemins d’accès critiques entre la couche application SAP et la couche SGBD. Dans certains scénarios observés avec les clients, les machines virtuelles Azure peuvent provoquer des défaillances de clusters Pacemaker Linux dans les cas où les communications entre les nœuds du cluster Linux Pacemaker doivent communiquer avec leur appareil SBD via un machine virtuelle Azure.
Important
Une autre conception qui n’est PAS prise en charge est la séparation de la couche application SAP et de la couche SGBD sur des réseaux virtuels Azure distincts qui ne sont pas appairés l’un avec l’autre. Nous vous recommandons de séparer la couche application SAP et la couche SGBD à l’aide de sous-réseaux au sein d’un réseau virtuel Azure, plutôt que d’utiliser différents réseaux virtuels Azure. Si vous décidez de ne pas suivre cette suggetsion et de séparer les deux couches sur des réseaux virtuels distincts, les deux réseaux virtuels doivent être appairés. N’oubliez pas que le trafic réseau entre deux réseaux virtuels Azure appairés est sujet à des coûts de transfert. Le volume de données échangé entre la couche application SAP et la couche SGBD étant énorme (plusieurs téraoctets), des coûts substantiels peuvent s’accumuler si la couche application SAP et la couche SGBD sont isolées sur deux réseaux virtuels Azure appairés.
Si vous avez déployé des machines virtuelles de serveur de rebond (jumbox) ou d’administration dans un sous-réseau distinct, vous pouvez définir plusieurs cartes d’interface réseau virtuelles (vNIC) pour la machine virtuelle HANA, chaque carte réseau virtuelle étant affectée à un sous-réseau différent. Avec la possibilité de disposer de plusieurs cartes réseau virtuelles, vous pouvez configurer si nécessaire une séparation du trafic réseau. Par exemple, le trafic client peut être routé via la carte réseau virtuelle principale et le trafic d’administration routé via une deuxième carte réseau virtuelle.
Vous pouvez aussi affecter des adresses IP privées statiques déployées pour les deux cartes réseau virtuelles.
Remarque
Vous devez attribuer des adresses IP statiques aux cartes réseau virtuelles individuelles à l’aide des outils Azure. Vous ne devez pas attribuer d’adresses IP statiques au sein du système d’exploitation invité à une carte réseau virtuelle. Certains services Azure, comme le service de Sauvegarde Azure, s’appuient sur le fait que la carte réseau virtuelle principale est définie sur la DHCP et non sur des adresses IP statiques. Consultez également le document Dépannage de la sauvegarde de machine virtuelle Azure. Si vous avez besoin d’attribuer plusieurs adresses IP statiques à une machine virtuelle, vous devez attribuer plusieurs cartes réseau virtuelles à une machine virtuelle.
Toutefois, pour les déploiements viables sur le long terme, vous devez créer une architecture réseau de centre de données virtuel dans Azure. Cette architecture recommande la séparation de la passerelle de réseau virtuel Azure qui établit une connexion en local dans un réseau virtuel Azure distinct. Celui-ci doit héberger tout le trafic sortant vers les destinations en local ou sur Internet. Cette approche vous permet de déployer un logiciel d’audit et de journalisation du trafic qui entre par ce hub de réseau virtuel distinct dans le centre de données virtuel dans Azure. Ainsi, un seul réseau virtuel héberge tous les logiciels et les configurations liés au trafic entrant et sortant vers votre déploiement Azure.
Les articles Centre de données virtuel Azure : une perspective réseau et Le Centre de données virtuel Azure et le plan de contrôle d’entreprise donnent plus d’informations sur l’approche du Centre de données virtuel et la conception des réseaux virtuels Azure associée.
Notes
Le trafic qui transite entre un réseau virtuel hub et un réseau virtuel spoke à l’aide du peering de réseau virtuel Azure fait l’objet de coûts supplémentaires. En fonction de ces coûts, vous devrez peut-être envisager des compromis entre l’exécution d’une conception de réseau hub and spoke stricte et la mise en place de plusieurs passerelles Azure ExpressRoute que vous vous connectez aux « spokes » afin de contourner le peering de réseau virtuel. Toutefois, les passerelles Azure ExpressRoute entraînent des coûts supplémentaires également. Les logiciels tiers que vous utilisez pour la journalisation, l’audit et la surveillance du trafic réseau peuvent aussi engendrer des coûts supplémentaires. Selon les coûts induits par l’échange de données via le peering de réseau virtuel d’un côté et les coûts engendrés par les passerelles Azure ExpressRoute et les licences logicielles supplémentaires, vous pouvez opter pour la micro-segmentation au sein d’un réseau virtuel en utilisant les sous-réseaux en tant qu’unité d’isolation à la place des réseaux virtuels.
Pour obtenir une vue d’ensemble des différentes méthodes d’attribution des adresses IP, consultez Types d’adresses IP et méthodes d’allocation dans Azure.
Pour les machines virtuelles qui exécutent SAP HANA, vous devez utiliser les adresses IP statiques attribuées. En effet, certains attributs de configuration pour HANA référencent des adresses IP.
Les groupes de sécurité réseau Azure permettent de diriger le trafic qui est acheminé vers l’instance de SAP HANA ou la machine virtuelle Jumpbox. Les groupes de sécurité réseau ainsi que les groupes de sécurité d’application sont associés au sous-réseau SAP HANA et au sous-réseau de gestion.
Pour déployer SAP HANA dans Azure sans une connexion de site à site, vous voulez protéger l’instance SAP HANA de l’internet public et le masquer derrière un proxy. Dans ce scénario de base, le déploiement s’appuie sur les services DNS intégrés à Azure pour résoudre les noms d’hôte. Dans un déploiement plus complexe où des adresses IP publiques sont utilisées, les services DNS intégrés à Azure sont particulièrement importants. Utilisez des groupes de sécurité réseau et appliances virtuelles réseau Azure pour contrôler et surveiller le routage à partir d’internet dans votre architecture de réseau virtuel Azure dans Azure. L’image suivante représente un schéma approximatif pour le déploiement de SAP HANA sans connexion de site à site dans une architecture de réseau virtuel hub and spoke :
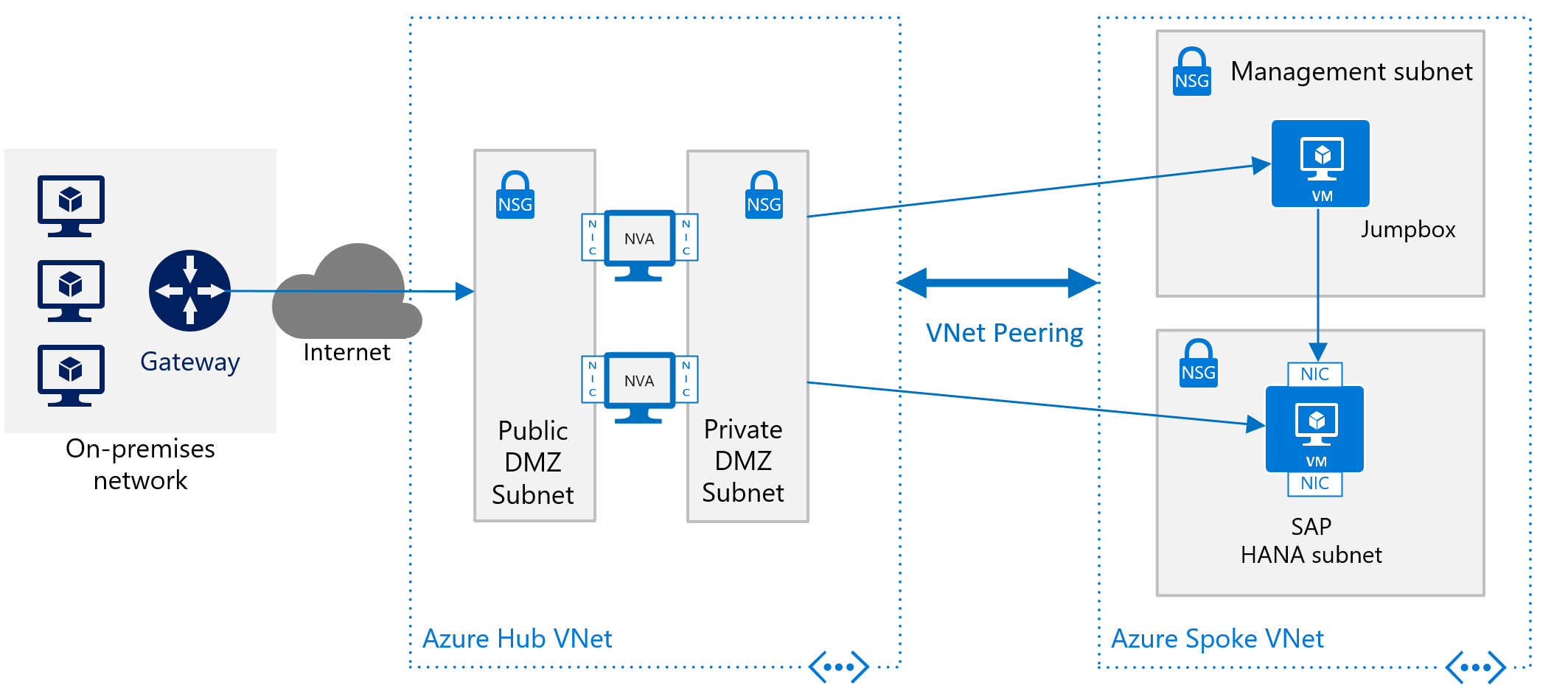
Vous trouverez une autre description sur l’utilisation des appliances virtuelles réseau Azure pour contrôler et surveiller l’accès à partir d’Internet sans l’architecture de réseau virtuel hub et spoke dans l’article Déployer des appliances virtuelles réseau hautement disponibles.
Options de source de l’horloge dans les machines virtuelles Azure
SAP HANA nécessite des informations de minutage fiables et précises pour fonctionner de façon optimale. Traditionnellement, les machines virtuelles Azure s’exécutant sur l’hyperviseur Azure utilisaient seulement la page TSC d’Hyper-V comme source de l’horloge par défaut. Les avancées technologiques dans le matériel, le système d’exploitation hôte et les noyaux du système d’exploitation invité Linux ont permis de fournir « TSC invariant » comme choix de la source de l’horloge sur certaines références SKU de machine virtuelle Azure.
La page TSC d’Hyper-V (hyperv_clocksource_tsc_page) est prise en charge sur toutes les machines virtuelles Azure en tant que source de l’horloge.
Si le matériel sous-jacent, l’hyperviseur et le noyau Linux du système d’exploitation invité prennent en charge TSC invariant, tsc sera proposé comme source de l’horloge disponible et prise en charge dans le système d’exploitation invité sur les machines virtuelles Azure.
Configuration de l’infrastructure Azure pour le scale-out de SAP HANA
Pour connaître les types de machines virtuelles Azure certifiés pour le scale-out OLAP ou le scale-out S/4HANA, consultez le répertoire matériel SAP HANA. La présence d'une coche dans la colonne « Clustering » indique que le scale-out est pris en charge. Le type d'application indique si le scale-out OLAP ou le scale-out S/4HANA est pris en charge. Pour plus d’informations sur les nœuds certifiés dans le scale-out, passez en revue l’entrée pour une référence SKU de machine virtuelle spécifique répertoriée dans l’annuaire matériel SAP HANA.
Concernant les versions minimales du système d'exploitation pour le déploiement de configurations scale-out dans les machines virtuelles Azure, consultez les entrées de la référence SKU de machine virtuelle appropriée dans le répertoire matériel SAP HANA. Dans une configuration scale-out OLAP à n nœuds, un nœud fait office de nœud principal. Les autres nœuds, jusqu'à la limite de la certification, font office de nœud Worker. Les nœuds de secours supplémentaires ne sont pas pris en compte dans le nombre de nœuds certifiés
Notes
Les déploiements scale-out de machines virtuelles Azure de SAP HANA avec nœud de secours ne sont possibles qu'avec le stockage Azure NetApp Files. Aucun autre stockage Azure certifié SAP HANA ne permet la configuration de nœuds de secours SAP HANA
Pour /hana/shared, nous recommandons l’utilisation d’Azure NetApp Files ou d’Azure Files.
Une conception de base classique pour un nœud unique dans une configuration de scale-out, avec /hana/shared déployé sur Azure NetApp Files, se présente comme ceci :
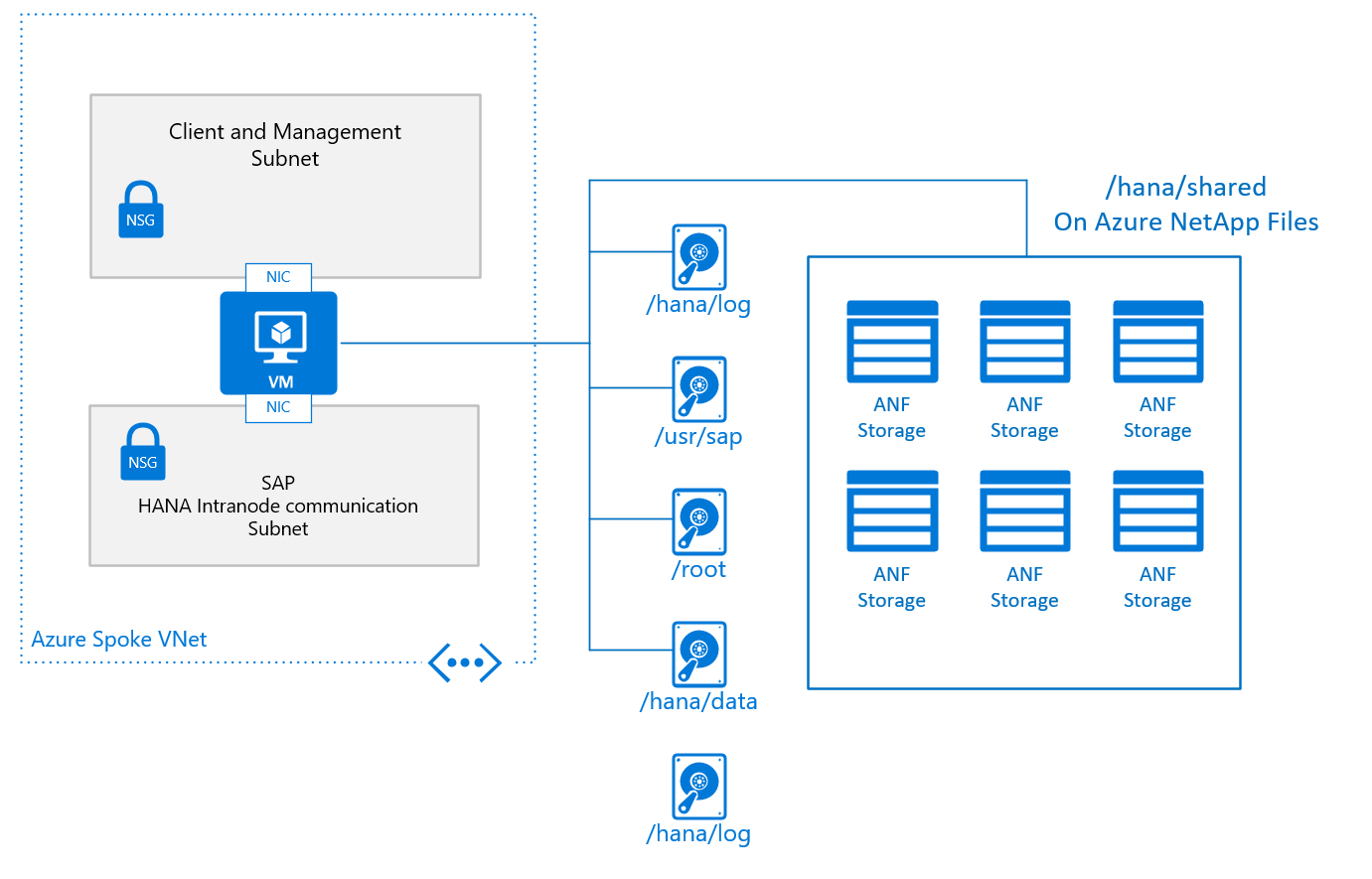
La configuration de base d’un nœud de machine virtuelle pour le scale-out de SAP HANA ressemble à ceci :
- Pour /hana/shared, vous utilisez le service NFS natif fourni via Azure NetApp Files ou Azure Files.
- Les autres volumes de disque ne sont pas partagés entre les différents nœuds et ne sont pas basés sur NFS. Les configurations d'installation et les étapes relatives aux installations de scale-out HANA avec /hana/data et /hana/log non partagés sont fournies plus loin dans ce document. Pour savoir si un stockage certifié HANA peut être utilisé, consultez l'article Configurations du stockage des machines virtuelles SAP HANA Azure.
Pour le dimensionnement des volumes ou des disques, vous devez vérifier la taille requise en fonction du nombre de nœuds Worker en consultant le document Exigences de stockage TDI SAP HANA. Le document contient une formule que vous devez appliquer pour obtenir la capacité requise du volume
L'autre critère de conception illustré dans le graphique de la configuration de nœud unique pour un scale-out de machine virtuelle SAP HANA est le réseau virtuel, plus précisément la configuration du sous-réseau. SAP recommande fortement de séparer le trafic client/application des communications entre les nœuds HANA. Comme indiqué dans les graphiques, cet objectif est réalisé en attachant deux cartes réseau virtuelles différentes à la machine virtuelle. Chacune des cartes réseau virtuelles est dans un sous-réseau différent et dispose d’un adresse IP distincte. Vous contrôlez le trafic avec les règles de routage à l’aide de groupes de sécurité réseau ou d’itinéraires définis par l’utilisateur.
En particulier dans Azure, il n’existe aucun moyen ni de méthode pour appliquer la qualité de service et les quotas sur des cartes réseau virtuelles spécifiques. Par conséquent, la séparation de la communication client/application et intra-nœud n’ouvre pas d’opportunité pour prioriser un flux plutôt que l’autre. Au lieu de cela, la séparation reste une mesure de sécurité pour la protection des communications intra-nœud dans les configurations de scale-out.
Notes
SAP recommande de séparer le trafic réseau vers le côté client/application et le trafic intra-nœud, comme décrit dans ce document. Il est par conséquent recommandé de mettre une architecture en place, comme indiqué dans les derniers graphiques. Consultez également votre équipe de sécurité et de conformité pour plus d'informations sur les exigences qui s'écartent de la recommandation
Du point de vue du réseau, l’architecture réseau minimale requise serait la suivante :
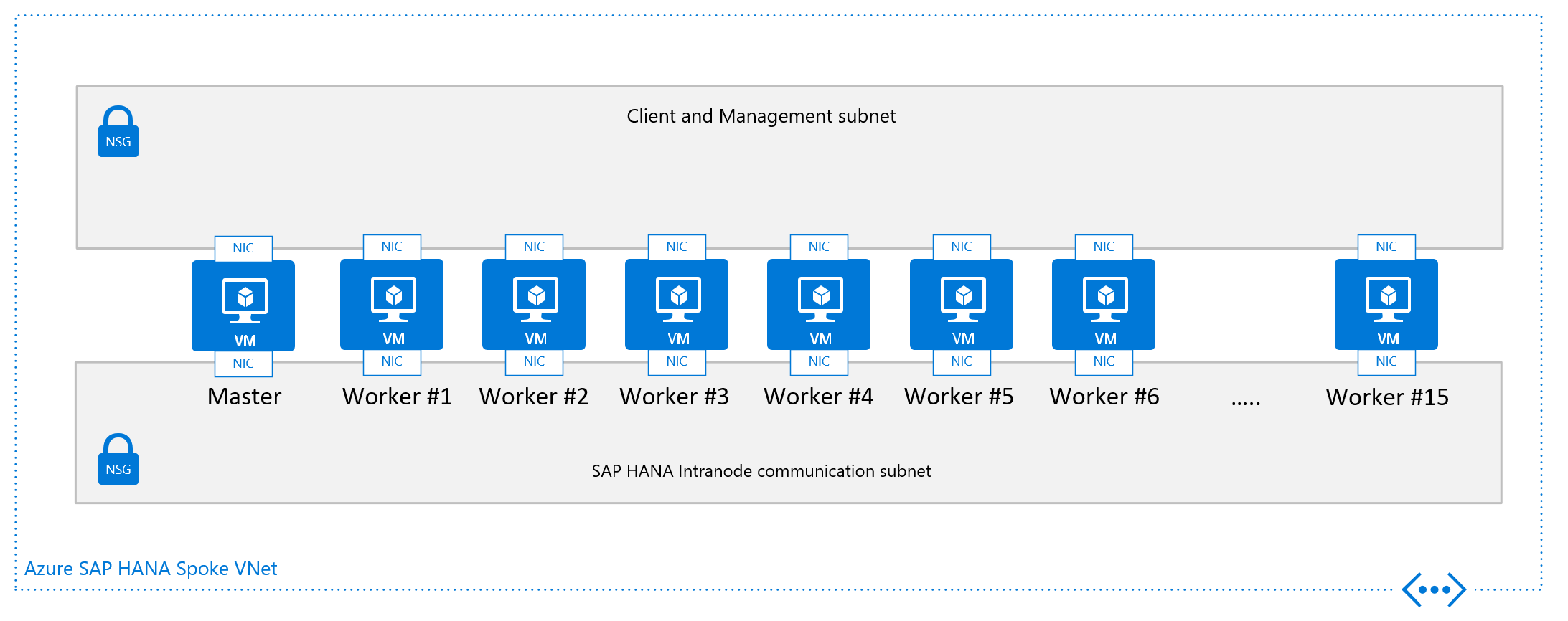
Installation du scale-out SAP HANA dans Azure
Lors de l’installation d’une configuration de scale-out SAP, vous devez procéder :
- Au déploiement d’une nouvelle infrastructure de réseau virtuel Azure ou à l’adaptation d’une existante
- Déployer les nouvelles machines virtuelles à l'aide du Stockage Premium géré par Azure, de volumes de disques Ultra et/ou de volumes NFS basés sur ANF
-
- À l’adaptation d’un routage réseau pour vous assurer que, par exemple, les communications intra-nœud entre les machines virtuelles ne sont pas acheminées via un NVA.
- Installez le nœud principal SAP HANA.
- À l’adaptation des paramètres de configuration du nœud principal SAP HANA
- Continuez avec l’installation des nœuds de travail SAP HANA
Installation de SAP HANA dans une configuration scale-out
Votre infrastructure de machine virtuelle Azure est déployée, et toutes les autres tâches de préparation sont terminées. Vous devez installer les configurations de scale-out SAP HANA en suivant ces étapes :
- Installer le nœud principal SAP HANA selon la documentation de SAP
- Lorsque vous utilisez le Stockage Premium Azure ou le Stockage sur disque Ultra avec des disques non partagés de
/hana/dataet/hana/log, ajoutez le paramètrebasepath_shared = noau fichierglobal.ini. Ce paramètre permet à SAP HANA de s’exécuter avec un scale-out sans les volumes « shared »/hana/dataet/hana/logentre les nœuds. Pour plus de détails à ce sujet, voir le document SAP Note #2080991. Si vous utilisez des volumes NFS basés sur ANF pour /hana/data et /hana/log, cette modification n’est pas nécessaire - Après la modification éventuelle du paramètre global.ini, redémarrez l'instance SAP HANA
- Ajoutez des nœuds Worker supplémentaires. Pour plus d’informations, consultez Ajouter des hôtes à l’aide de l’interface de ligne de commande. Spécifiez le réseau interne pour la communication inter-nœuds de SAP HANA lors de l’installation ou ultérieurement, avec par exemple l’outil hdblcm local. Pour plus de détails à ce sujet, consultez le document SAP Note #2183363.
Pour configurer un système de scale-out SAP HANA avec un nœud de secours, consultez les Instructions de déploiement de SUSE Linux ou les Instructions de déploiement de Red Hat.
SAP HANA Dynamic Tiering 2.0 pour les machines virtuelles Azure
Outre les certifications SAP HANA sur les machines virtuelles Azure de série M, SAP HANA Dynamic Tiering 2.0 est également pris en charge sur Microsoft Azure. Pour plus d’informations, consultez les Liens vers la documentation de DT 2.0. Il n’existe aucune différence dans l’installation ou l’exploitation du produit. Par exemple, vous pouvez installer SAP HANA Cockpit à l’intérieur d’une machine virtuelle Azure. Toutefois, il existe certaines exigences obligatoires, comme décrit dans la section suivante, pour la prise en charge officielle sur Azure. Tout au long de l’article, l’abréviation « DT 2.0 » sera utilisée au lieu du nom complet « Dynamic Tiering 2.0 ».
SAP HANA Dynamic Tiering 2.0 n’est pas pris en charge par SAP BW ou S4HANA. Les cas d’utilisation principaux sont actuellement des applications HANA natives.
Vue d’ensemble
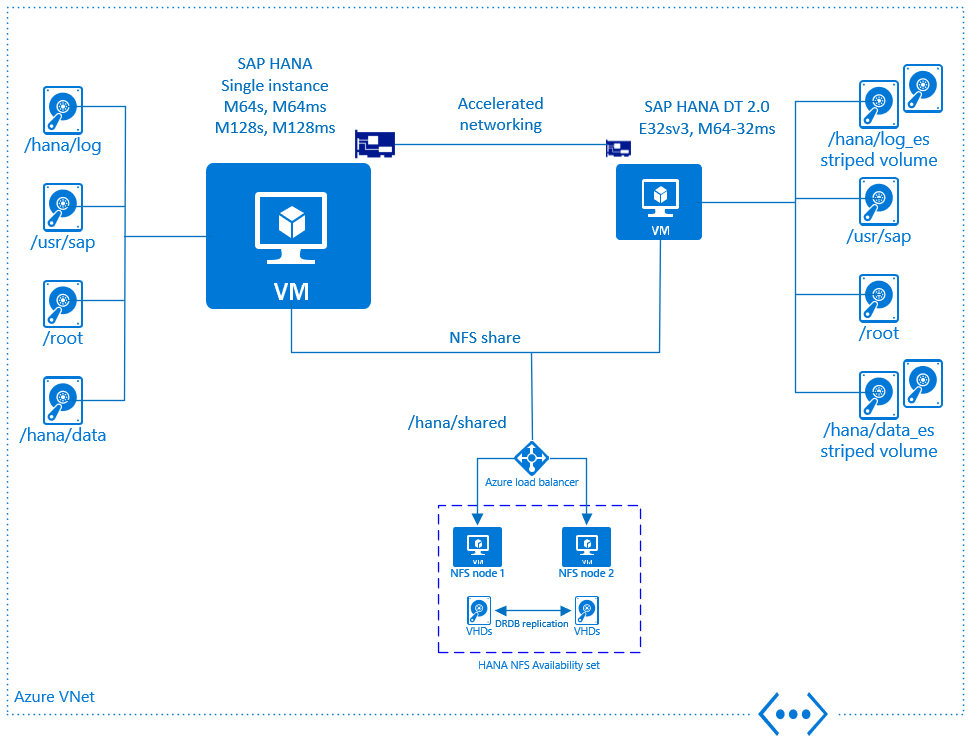
L’image ci-dessous donne une vue d’ensemble de la prise en charge de DT 2.0 sur Microsoft Azure. Il existe un ensemble de conditions obligatoires, qui doivent être suivies pour être conforme à la certification officielle :
- DT 2.0 doit être installé sur une machine virtuelle Azure dédiée. Il peut ne pas s’exécuter sur la même machine virtuelle que celle où SAP HANA s’exécute
- SAP HANA et les machines virtuelles DT 2.0 doivent être déployées dans le même réseau virtuel Azure
- Les machines virtuelles SAP HANA et DT 2.0 doivent être déployées avec la mise en réseau accélérée Azure activée
- Le type de stockage pour les machines virtuelles DT 2.0 doit être Stockage Premium Azure
- Plusieurs disques Azure doivent être attachés à la machine virtuelle DT 2.0
- Il est nécessaire de créer un volume Raid / agrégé par bandes (via lvm ou mdadm) en utilisant l’agrégation entre les disques Azure
La section suivante contient plus de détails à ce sujet.
Machine virtuelle Azure dédiée pour SAP HANA DT 2.0
Sur Azure IaaS, DT 2.0 est pris en charge seulement sur une machine virtuelle dédiée. Il est interdit d’exécuter DT 2.0 sur la même machine virtuelle Azure que celle où l’instance HANA s’exécute. Initialement, deux types de machine virtuelle peuvent être utilisés pour exécuter SAP HANA DT 2.0 :
- M64-32ms
- E32sv3
Pour plus d’informations sur la description du type de machine virtuelle, consultez Tailles de machine virtuelle Azure - Mémoire
Étant donné le principe fondamental de DT 2.0, qui est de décharger les données « chaudes » afin de réduire les coûts, il est judicieux d’utiliser des tailles de machine virtuelle correspondantes. Il n’existe cependant pas de règle stricte concernant les combinaisons possibles. Cela dépend de la charge de travail spécifique du client.
Voici les configurations recommandées :
| Type de machine virtuelle SAP HANA | Type de machine virtuelle DT 2.0 |
|---|---|
| M128ms | M64-32ms |
| M128s | M64-32ms |
| M64ms | E32sv3 |
| M64s | E32sv3 |
Toutes les combinaisons de machines virtuelles de la série M certifiées pour SAP HANA avec les machines virtuelles DT 2.0 prises en charge (M64-32ms et E32sv3) sont possibles.
Mise en réseau Azure et SAP HANA DT 2.0
L’installation de DT 2.0 sur une machine virtuelle dédiée nécessite un débit minimal de 10 Gbits entre la machine virtuelle DT 2.0 et la machine virtuelle SAP HANA. Par conséquent, il est obligatoire de placer toutes les machines virtuelles dans le même réseau virtuel Azure et d’activer la mise en réseau accélérée Azure.
Pour plus d’informations sur la mise en réseau accélérée Azure, consultez Créer une machine virtuelle Azure avec mise en réseau accélérée à l’aide d’Azure CLI.
Stockage des machines virtuelles pour SAP HANA DT 2.0
Conformément au guide des bonnes pratiques pour DT 2.0, le débit d’E/S des disques doit être au minimum de 50 Mo/s par cœur physique.
D’après les spécifications pour les deux types de machine virtuelle Azure qui sont pris en charge pour DT 2.0, vous voyez que la limite maximale du débit d’E/S pour la machine virtuelle se présente comme suit :
- E32sv3 : 768 Mo/s (sans mise en cache), ce qui signifie un ratio de 48 Mo/s par cœur physique
- M64-32ms : 1000 Mo/s (sans mise en cache), ce qui signifie un ratio de 62,5 Mo/s par cœur physique
Il est obligatoire d’attacher plusieurs disques Azure à la machine virtuelle DT 2.0 et de créer un RAID logiciel (agrégation) sur le niveau du système d’exploitation pour atteindre la limite maximale de débit des disques par machine virtuelle. Un seul disque Azure ne peut pas fournir le débit nécessaire pour atteindre la limite maximale de la machine virtuelle à cet égard. Un stockage Premium Azure est obligatoire pour exécuter DT 2.0.
- Vous trouverez des détails sur les types de disques Azure disponibles sur la page Sélectionner un type de disque pour les machines virtuelles Azure IaaS - disques managés.
- Les détails sur la création d’un raid logiciel via mdadm se trouvent sur la page Configuration logicielle de RAID sur une machine virtuelle Linuxux.
- Vous trouverez des détails sur la configuration de LVM pour créer un volume agrégé par bandes pour un débit maximal sur Configurer LVM sur une machine virtuelle utilisant Linux.
Selon les exigences de taille, il existe différentes options pour atteindre le débit maximal d’une machine virtuelle. Voici les configurations des disques de volume de données possibles permettant à chaque type de machine virtuelle DT 2.0 d’atteindre la limite supérieure de débit. La machine virtuelle E32sv3 doit être considérée comme un niveau d’entrée pour les charges de travail plus petites. Dans le cas où elle ne s’avère pas suffisamment rapide, il peut être nécessaire de redimensionner la machine virtuelle en M64-32ms. Comme la machine virtuelle M64-32ms a beaucoup de mémoire, la charge d’E/S peut ne pas atteindre la limite, en particulier pour les charges de travail qui font des lectures de façon intensive. Ainsi, il est possible que moins de disques dans l’ensemble agrégé par bandes soient suffisants, en fonction de la charge de travail spécifique du client. Cependant, par prudence, les configurations de disques ci-dessous ont été choisies pour garantir le débit maximal :
| Référence de la machine virtuelle | Configuration de disque 1 | Configuration de disque 2 | Configuration de disque 3 | Configuration de disque 4 | Configuration de disque 5 |
|---|---|---|---|---|---|
| M64-32ms | 4 x P50 -> 16 To | 4 x P40 -> 8 To | 5 x P30 -> 5 To | 7 x P20 -> 3,5 To | 8 x P15 -> 2 To |
| E32sv3 | 3 x P50 -> 12 To | 3 x P40 -> 6 To | 4 x P30 -> 4 To | 5 x P20 -> 2,5 To | 6 x P15 -> 1,5 To |
En particulier au cas où la charge de travail implique des lectures intensives, vous pouvez accélérer les performances des E/S en activant le cache d’hôte Azure « en lecture seule », comme c’est recommandé pour les volumes de données des logiciels de base de données. Pour le journal des transactions, le cache disque d’hôte Azure doit par contre être défini sur « aucun ».
Concernant la taille du volume des journaux, un point de départ recommandé est une heuristique de 15 % de la taille des données. Vous pouvez créer le volume des journaux en utilisant des types de disque Azure différents, en fonction des exigences quant au débit et aux coûts. Pour le volume du fichier journal, un débit d'E-S élevé est nécessaire.
Quand vous utilisez la machine virtuelle de type M64-32ms, l’Accélérateur d’écriture doit obligatoirement être activé. L’accélérateur d’écriture Azure permet une latence optimale des écritures sur disque pour le journal des transactions (disponible seulement pour la série M). Vous devez néanmoins prendre en compte certains éléments, comme le nombre maximal de disques par type de machine virtuelle. Vous trouverez des détails sur l’Accélérateur d’écriture sur la page Accélérateur d’écriture Azure.
Voici quelques exemples de dimensionnement du volume des journaux :
| taille et type de disque du volume de données | volume des journaux et type de disque - Configuration 1 | volume des journaux et type de disque - Configuration 2 |
|---|---|---|
| 4 x P50 -> 16 To | 5 x P20 -> 2,5 To | 3 x P30 -> 3 To |
| 6 x P15 -> 1,5 To | 4 x P6 -> 256 Go | 1 x P15 -> 256 Go |
Comme pour la montée en puissance parallèle de SAP HANA, le répertoire /Hana/shared doit être partagé entre la machine virtuelle SAP HANA et la machine virtuelle DT 2.0. La même architecture que pour la montée en puissance parallèle de SAP HANA avec des machines virtuelles dédiées qui agissent comme un serveur NFS à haute disponibilité est recommandée. Pour fournir un volume de sauvegarde partagé, vous pouvez utiliser la même conception. Le fait que la haute disponibilité soit nécessaire ou qu’il soit suffisant d’utiliser une machine virtuelle dédiée avec une capacité de stockage suffisante pour agir comme serveur de sauvegarde dépend du client.
Liens vers la documentation de DT 2.0
- SAP HANA Dynamic Tiering installation and update guide (Guide d’installation et de mise à jour de SAP HANA Dynamic Tiering)
- SAP HANA Dynamic Tiering tutorials and resources (Tutoriels et ressources pour SAP HANA Dynamic Tiering)
- SAP HANA Dynamic Tiering PoC
- SAP HANA 2.0 SPS 02 dynamic tiering enhancements
Opérations pour le déploiement de SAP HANA sur des machines virtuelles Azure
Les sections suivantes décrivent certaines des opérations liées au déploiement de systèmes SAP HANA sur des machines virtuelles Azure.
Opérations de sauvegarde et restauration sur des machines virtuelles Azure
Les documents suivants décrivent comment sauvegarder et restaurer votre déploiement de SAP HANA :
- Vue d’ensemble de la sauvegarde SAP HANA
- Sauvegarde SAP HANA au niveau des fichiers
- Sauvegarde SAP HANA à partir de captures instantanées de stockage
Démarrer et redémarrer des machines virtuelles contenant SAP HANA
L’une des caractéristiques importantes du cloud public Azure est que vous êtes facturé uniquement pour les minutes de calcul que vous dépensez. Par exemple, quand vous arrêtez une machine virtuelle exécutant SAP HANA, seuls les coûts de stockage pendant cette durée vous sont facturés. Une autre fonctionnalité est disponible quand vous spécifiez des adresses IP statiques pour vos machines virtuelles dans votre déploiement initial. Quand vous redémarrez une machine virtuelle avec SAP HANA, la machine virtuelle redémarre avec ses adresses IP antérieures.
Utiliser SAProuter pour la prise en charge à distance de SAP
Si vous avez une connexion de site à site entre vos emplacements locaux et Azure, et que vous exécutez des composants SAP, il est très probable que vous exécutez déjà SAProuter. Dans ce cas, effectuez les opérations suivantes pour la prise en charge à distance :
- Mettre à jour l’adresse IP privée et statique de la machine virtuelle qui héberge SAP HANA dans la configuration de SAProuter.
- Configurer le groupe de sécurité réseau du sous-réseau qui héberge la machine virtuelle HANA pour autoriser le trafic via le port TCP/IP 3299.
Si vous vous connectez à Azure par le biais d’Internet et que vous n’avez pas installé de routeur SAP pour la machine virtuelle avec SAP HANA, vous devez installer le composant. Installez SAProuter sur une machine virtuelle distincte dans le sous-réseau de gestion. L’image suivante représente un schéma approximatif pour le déploiement de SAP HANA sans une connexion de site à site et avec SAProuter :
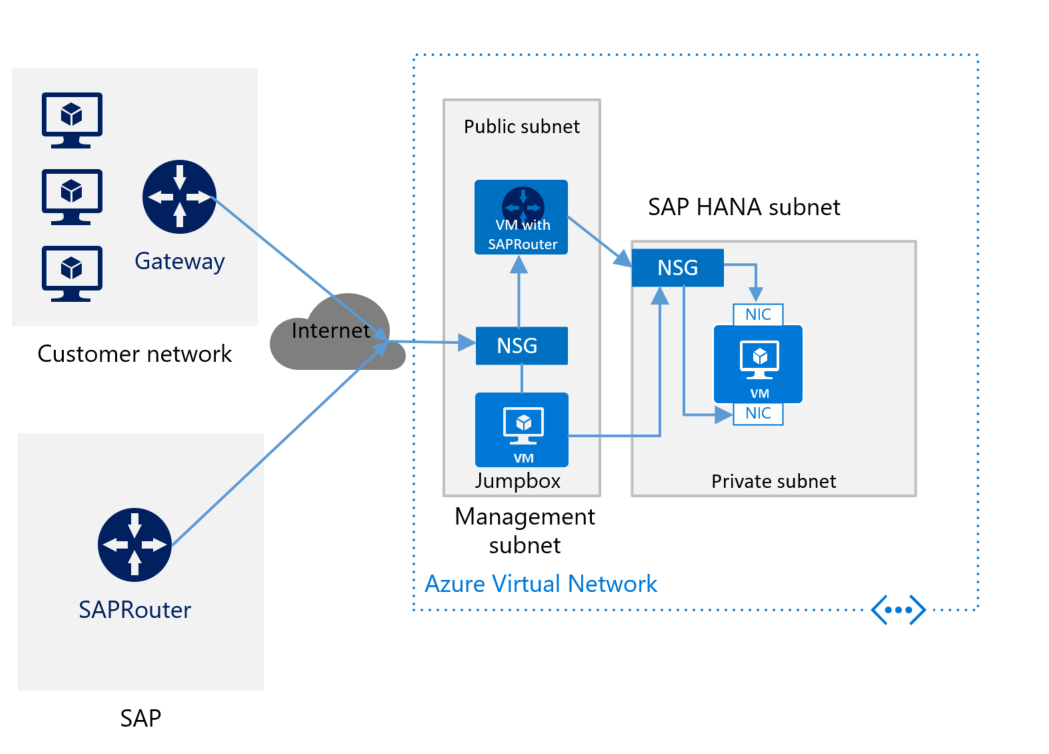
Veillez à installer SAProuter sur une machine virtuelle distincte, et non sur votre machine virtuelle Jumpbox. La machine virtuelle distincte doit avoir une adresse IP statique. Pour connecter votre SAProuter au SAProuter hébergé par SAP, contactez SAP pour obtenir une adresse IP. (Le SAProuter qui est hébergé par SAP est l’équivalent de l’instance de SAProuter que vous installez sur la machine virtuelle.) Utilisez l’adresse IP de SAP pour configurer votre instance de SAProuter. Dans les paramètres de configuration, le seul port nécessaire est le port TCP 3299.
Pour plus d’informations sur la façon de configurer et de gérer des connexions de prise en charge à distance par le biais de SAProuter, consultez la documentation SAP.
Haute disponibilité avec SAP HANA sur les machines virtuelles Azure natives
Si vous exécutez SUSE Linux Enterprise Server ou Red Hat, vous pouvez établir un cluster Pacemaker avec des appareils d’isolation. Vous pouvez utiliser les appareils afin de définir une configuration SAP HANA qui utilise la réplication synchrone avec la réplication de système HANA et le basculement automatique. Pour plus d'informations, reportez-vous à la section Étapes suivantes.
Étapes suivantes
Familiarisez-vous avec les articles répertoriés
- Configurations du stockage des machines virtuelles SAP HANA Azure
- Déployer un système scale-out SAP HANA avec nœud de secours sur des machines virtuelles Azure à l’aide d’Azure NetApp Files sur SUSE Linux Enterprise Server
- Déployer un système scale-out SAP HANA avec nœud de secours sur des machines virtuelles Azure à l’aide d’Azure NetApp Files sur Red Hat Enterprise Linux
- Déployer un système de scale-out SAP HANA avec HSR et Pacemaker sur des machines virtuelles Azure sur SUSE Linux Enterprise Server
- Déployer un système de scale-out SAP HANA avec HSR et Pacemaker sur des machines virtuelles Azure sur Red Hat Enterprise Linux
- Haute disponibilité de SAP HANA sur les machines virtuelles Azure sur SUSE Linux Enterprise Server
- Haute disponibilité de SAP HANA sur les machines virtuelles Azure sur Red Hat Enterprise Linux