Haute disponibilité de SAP HANA sur les machines virtuelles Azure dans le système Red Hat Enterprise Linux
En développement local, vous pouvez utiliser soit la réplication du système HANA soit un stockage partagé pour établir la haute disponibilité (HA) pour SAP HANA. Sur les machines virtuelles Azure, la réplication du système HANA dans Azure est la seule fonction HA actuellement prise en charge.
La réplication SAP HANA se compose d’un nœud principal et d’au moins un nœud secondaire. Les modifications apportées aux données sur le nœud principal sont répliquées vers les nœuds secondaires de manière synchrone ou asynchrone.
Cet article explique comment déployer et configurer des machines virtuelles, installer l’infrastructure de cluster, et installer et configurer la réplication du système SAP HANA.
Les exemples de configuration et les commandes d’installation utilisent le numéro d’instance 03 et l’ID système HANA HN1.
Prérequis
Commencez par lire les notes et publications SAP suivantes :
- Note SAP 1928533, qui contient :
- La liste des tailles de machines virtuelles Azure prises en charge pour le déploiement de logiciels SAP.
- Des informations importantes sur la capacité en fonction de la taille des machines virtuelles Azure.
- Les combinaisons prises en charge de logiciels SAP, de systèmes d’exploitation et de bases de données.
- La version du noyau SAP requise pour Windows et Linux sur Microsoft Azure.
- La note SAP 2015553 répertorie les conditions préalables au déploiement de logiciels SAP pris en charge par SAP sur Azure.
- La note SAP 2002167 recommande des paramètres de système d’exploitation pour Red Hat Enterprise Linux.
- La note SAP 2009879 conseille sur SAP HANA pour Red Hat Enterprise Linux.
- La note SAP 3108302 contient des recommandations SAP HANA pour Red Hat Enterprise Linux 9.x.
- La note SAP 2178632 contient des informations détaillées sur toutes les métriques de surveillance rapportées pour SAP sur Azure.
- La note SAP 2191498 contient la version requise de l’agent hôte SAP pour Linux sur Azure.
- La note SAP 2243692 contient des informations sur les licences SAP sur Linux dans Azure.
- La note SAP 1999351 contient des informations supplémentaires sur le dépannage de l’extension Azure Enhanced Monitoring pour SAP.
- Le WIKI de la communauté SAP contient toutes les notes SAP requises pour Linux.
- Planification et implémentation de machines virtuelles Azure pour SAP sur Linux
- Déploiement de machines virtuelles Azure pour SAP sur Linux (cet article)
- Déploiement SGBD de machines virtuelles Azure pour SAP sur Linux
- Réplication du système SAP HANA dans un cluster Pacemaker
- Documentation RHEL générale :
- Documentation RHEL spécifique à Azure :
- Stratégies de prise en charge des clusters à haute disponibilité RHEL - Machines virtuelles Microsoft Azure en tant que membres du cluster
- Installation et configuration d’un cluster à haute disponibilité Red Hat Enterprise Linux 7.4 (et versions ultérieures) sur Microsoft Azure
- Installation de SAP HANA sur Red Hat Enterprise Linux pour une utilisation dans Microsoft Azure
Vue d’ensemble
Pour les besoins de la haute disponibilité, SAP HANA est installé sur deux machines virtuelles. Les données sont répliquées à l’aide de la réplication de système HANA.
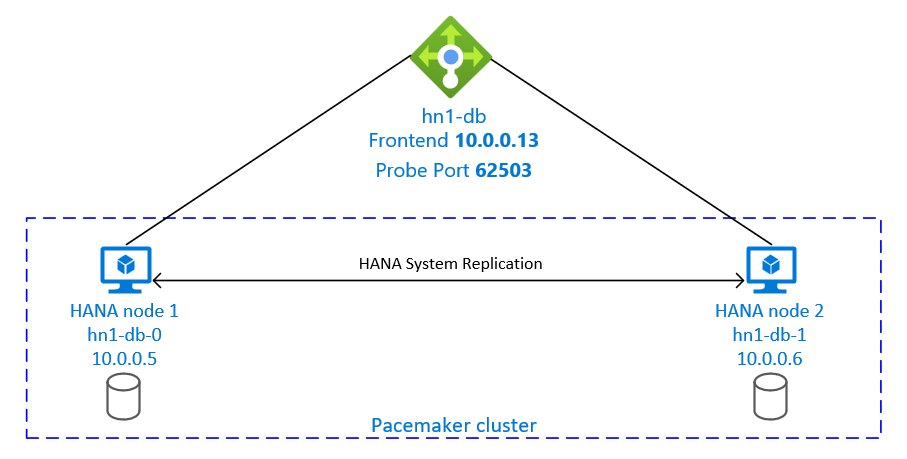
La configuration de la réplication du système SAP HANA utilise un nom d’hôte virtuel dédié et des adresses IP virtuelles. Sur Azure, un équilibreur de charge est nécessaire pour utiliser une adresse IP virtuelle. La configuration présentée montre un équilibreur de charge avec :
- Adresse IP frontale : 10.0.0.13 pour hn1-db
- Port de la sonde : 62503
Préparer l’infrastructure
La Place de marché Azure contient des images qualifiées pour SAP HANA avec le module complémentaire de haute disponibilité, que vous pouvez utiliser pour déployer de nouvelles machines virtuelles en utilisant différentes versions de Red Hat.
Déployer des machines virtuelles Linux manuellement via le portail Azure
Ce document part du principe que vous avez déjà déployé un groupe de ressources, un réseau virtuel Azure et un sous-réseau.
Déployez des machines virtuelles pour SAP HANA. Choisissez une image RHEL appropriée et prise en charge pour le système HANA. Vous pouvez déployer une machine virtuelle dans l’une des options de disponibilité : groupe de machines virtuelles identiques, zone de disponibilité ou groupe à haute disponibilité.
Important
Assurez-vous que le système d’exploitation que vous sélectionnez est certifié SAP pour SAP HANA sur les types de machines virtuelles spécifiques que vous envisagez d’utiliser dans votre déploiement. Vous pouvez rechercher les types de machines virtuelles certifiées SAP HANA et leurs versions de système d’exploitation sur la page Plateformes IaaS certifiées SAP HANA. Veillez à consulter les détails du type de machine virtuelle pour obtenir la liste complète des versions de système d’exploitation prises en charge par SAP HANA pour le type de machine virtuelle spécifique.
Configurer l’équilibrage de charge Azure
Pendant la configuration de la machine virtuelle, vous avez la possibilité de créer ou de sélectionner un équilibreur de charge existant dans la section réseau. Suivez les étapes ci-dessous pour configurer l’équilibreur de charge standard pour la configuration de la haute disponibilité de la base de données HANA.
Suivez les étapes dans Créer un équilibreur de charge pour configurer un équilibreur de charge standard pour un système SAP à haute disponibilité à l’aide du portail Azure. Pendant la configuration de l’équilibreur de charge, tenez compte des points suivants :
- Configuration d’une adresse IP front-end : créez une adresse IP front-end. Sélectionnez le même nom de réseau virtuel et de sous-réseau que vos machines virtuelles de base de données.
- Pool back-end : créez un pool back-end et ajoutez des machines virtuelles de base de données.
- Règles de trafic entrant : créez une règle d’équilibrage de charge. Suivez les mêmes étapes pour les deux règles d’équilibrage de charge.
- Adresse IP front-end : sélectionnez une adresse IP front-end.
- Pool back-end : sélectionnez un pool back-end.
- Ports haute disponibilité : sélectionnez cette option.
- Protocole : sélectionnez TCP.
- Sonde d’intégrité : créez une sonde d’intégrité avec les détails suivants :
- Protocole : sélectionnez TCP.
- Port : par exemple, 625<numéro-instance>.
- Intervalle : entrez 5.
- Seuil de sonde : entrez 2.
- Délai d'inactivité (minutes) : entrez 30.
- Activer l’adresse IP flottante : sélectionnez cette option.
Remarque
La propriété de configuration de la sonde d’intégrité numberOfProbes, également appelée Seuil de défaillance sur le plan de l’intégrité dans le portail, n’est pas respectée. Pour contrôler le nombre de sondes consécutives qui aboutissent ou qui échouent, définissez la propriété probeThreshold sur 2. Il n’est actuellement pas possible de définir cette propriété à l’aide du portail Azure. Utilisez donc l’interface Azure CLI ou la commande PowerShell.
Pour plus d’informations sur les ports requis pour SAP HANA, consultez le chapitre Connections to Tenant Databases (Connexions aux bases de données locataires) dans le guide SAP HANA Tenant Databases (Bases de données locataires SAP HANA) ou la Note SAP 2388694.
Remarque
Lorsque des machines virtuelles sans adresse IP publique sont placées dans le pool back-end d’une instance interne d’Azure Load Balancer Standard (sans adresse IP publique), il n’y a pas de connectivité Internet sortante à moins qu’une configuration supplémentaire soit effectuée pour permettre le routage vers des points de terminaison publics. Pour plus d’informations sur la façon de bénéficier d’une connectivité sortante, consultez Connectivité de point de terminaison public pour les machines virtuelles avec Azure Standard Load Balancer dans les scénarios de haute disponibilité SAP.
Important
N’activez pas les horodateurs TCP sur les machines virtuelles Azure placées derrière l’Équilibreur de charge Azure. L’activation de timestamps TCP peut entraîner l’échec des sondes d’intégrité. Affectez au paramètre net.ipv4.tcp_timestampsla valeur 0. Pour plus d’informations, consultez Sondes d’intégrité Load Balancer et la note SAP 2382421.
Installer SAP HANA
Les étapes de cette section utilisent les préfixes suivants :
- [A] : l’étape s’applique à tous les nœuds.
- [1] : l’étape ne s’applique qu’au nœud 1.
- [2] : l’étape s’applique uniquement au nœud 2 du cluster Pacemaker.
[A] Configurez la disposition du disque : Logical Volume Manager (LVM) .
Nous recommandons d’utiliser LVM pour les volumes qui stockent des données et des fichiers journaux. L’exemple suivant suppose que quatre disques de données sont attachés aux machines virtuelles et utilisés pour créer deux volumes.
Répertoriez tous les disques disponibles :
ls /dev/disk/azure/scsi1/lun*Exemple de sortie :
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Créez des volumes physiques pour tous les disques que vous souhaitez utiliser :
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Créez un groupe de volume pour les fichiers de données. Utilisez un groupe de volume pour les fichiers journaux et un autre pour le répertoire partagé de SAP HANA :
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_HN1 /dev/disk/azure/scsi1/lun3Créez les volumes logiques. Un volume linéaire est créé lorsque vous utilisez
lvcreatesans le commutateur-i. Nous vous suggérons de créer un volume agrégé par bandes pour améliorer les performances d’E/S. Alignez les tailles des bandes sur les valeurs documentées dans les configurations de stockage de machine virtuelle SAP HANA. L’argument-idoit correspondre au nombre de volumes physiques sous-jacents, et l’argument-Ireprésente la taille de bande.Dans ce document, deux volumes physiques sont utilisés pour le volume de données. Par conséquent, l’argument de commutateur
-iest défini sur 2. La taille de bande pour le volume de données est de 256 Kio. Un volume physique étant utilisé pour le volume du fichier journal, aucun commutateur-iou-In’est utilisé explicitement pour les commandes de volume du fichier journal.Important
Utilisez le commutateur
-iet définissez sa valeur sur le nombre de volumes physiques sous-jacents lorsque vous utilisez plusieurs volumes physiques pour chaque volume de données, volume de journal ou volume partagé. Utilisez le commutateur-Ipour spécifier la taille de bande lors de la création d’un volume agrégé par bandes. Pour connaître les configurations de stockage recommandées, notamment les tailles de bande et le nombre de disques, consultez Configurations de stockage de machines virtuelles SAP HANA. Les exemples de disposition suivants ne répondent pas nécessairement aux recommandations en matière de performances pour une taille de système déterminée. Ils sont fournis à titre d’illustration uniquement.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log sudo mkfs.xfs /dev/vg_hana_shared_HN1/hana_sharedNe montez pas les répertoires en émettant des commandes mount. Au lieu de cela, entrez les configurations dans le fichier
fstabet émettez une commandemount -afinale pour valider la syntaxe. Commencez par créer les répertoires de montage pour chaque volume :sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/sharedEnsuite, créez des entrées
fstabpour les trois volumes logiques en insérant les lignes suivantes dans le fichier/etc/fstab:/dev/mapper/vg_hana_data_HN1-hana_data /hana/data xfs defaults,nofail 0 2 /dev/mapper/vg_hana_log_HN1-hana_log /hana/log xfs defaults,nofail 0 2 /dev/mapper/vg_hana_shared_HN1-hana_shared /hana/shared xfs defaults,nofail 0 2
Enfin, montez tous les nouveaux volumes à la fois :
sudo mount -a[A] Configurez la résolution de nom d’hôte pour tous les hôtes.
Vous pouvez utiliser un serveur DNS ou modifier le fichier
/etc/hostssur tous les nœuds en créant des entrées pour tous les nœuds comme ceci dans/etc/hosts:10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Procédez à la configuration de RHEL pour HANA.
Configurez RHEL tel que décrit dans les notes suivantes :
- 2447641 - Packages supplémentaires requis pour installer SAP HANA SPS 12 sur RHEL 7.X
- 2292690 - SAP HANA DB: Recommended OS settings for RHEL 7 (SAP HANA DB : Paramètres de système d’exploitation recommandés pour RHEL 7)
- 2777782 – Base de données SAP HANA : paramètres de système d’exploitation recommandés pour RHEL 8
- 2455582 – Linux : Exécution d’applications SAP compilées avec GCC 6.x
- 2593824 – Linux : Exécution d’applications SAP compilées avec GCC 7.x
- 2886607 – Linux : Exécution d’applications SAP compilées avec GCC 9.x
[A] Installez SAP HANA, en suivant la documentation de SAP.
[A] Configurez le pare-feu.
Créez la règle de pare-feu pour le port de la sonde Azure Load Balancer.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp --permanent
Configurer la réplication de système SAP HANA 2.0
Les étapes de cette section utilisent les préfixes suivants :
- [A] : l’étape s’applique à tous les nœuds.
- [1] : l’étape ne s’applique qu’au nœud 1.
- [2] : l’étape s’applique uniquement au nœud 2 du cluster Pacemaker.
[A] Configurez le pare-feu.
Créez des règles de pare-feu pour autoriser le trafic de réplication de système HANA et client. Les ports indispensables sont répertoriés ici : Ports TCP/IP de tous les produits SAP. Les commandes suivantes sont simplement un exemple pour autoriser la réplication du système HANA 2.0 et le trafic client vers la base de données SYSTEMDB, HN1 et NW1.
sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp --permanent sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp[1] Créer une base de données locataire.
Exécutez la commande suivante en tant que <hanasid>adm :
hdbsql -u SYSTEM -p "[passwd]" -i 03 -d SYSTEMDB 'CREATE DATABASE NW1 SYSTEM USER PASSWORD "<passwd>"'[1] Configurez la réplication du système sur le premier nœud.
Sauvegardez les bases de données en tant que <hanasid>adm :
hdbsql -d SYSTEMDB -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')" hdbsql -d NW1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupNW1')"Copiez les fichiers d’infrastructure à clé publique du système sur le site secondaire :
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Créez le site principal :
hdbnsutil -sr_enable --name=SITE1[2] Configurez la réplication du système sur le deuxième nœud.
Inscrivez le second nœud pour démarrer la réplication de système. Exécutez la commande suivante en tant que <hanasid>adm :
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2[2] Démarrez HANA.
Exécutez la commande suivante en tant que <hanasid>adm pour démarrer HANA :
sapcontrol -nr 03 -function StartSystem[1] Vérifiez l’état de la réplication.
Vérifiez l’état de la réplication et attendez que toutes les bases de données soient synchronisées. Si l’état demeure INCONNU, vérifiez vos paramètres de pare-feu.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | -------- | ----- | ------------ | --------- | ------- | --------- | --------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | SYSTEMDB | hn1-db-0 | 30301 | nameserver | 1 | 1 | SITE1 | hn1-db-1 | 30301 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30307 | xsengine | 2 | 1 | SITE1 | hn1-db-1 | 30307 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | NW1 | hn1-db-0 | 30340 | indexserver | 2 | 1 | SITE1 | hn1-db-1 | 30340 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30303 | indexserver | 3 | 1 | SITE1 | hn1-db-1 | 30303 | 2 | SITE2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # # mode: PRIMARY # site id: 1 # site name: SITE1
Créez un cluster Pacemaker
Suivez les étapes décrites sur la page Configurer Pacemaker sur Red Hat Enterprise Linux dans Azure pour créer un cluster Pacemaker de base pour ce serveur HANA.
Important
Avec SAP Startup Framework basé sur systemd, les instances SAP HANA peuvent désormais être gérées par systemd. La version minimale requise de Red Hat Enterprise Linux (RHEL) est RHEL 8 pour SAP. Comme indiqué dans la note SAP 3189534, pour les nouvelles installations de SAP HANA SPS07 révision 70 ou ultérieure, ou les mises à jour des systèmes HANA vers HANA 2.0 SPS07 révision 70 ou ultérieure, SAP Startup Framework est automatiquement inscrit auprès de systemd.
Lorsque des solutions HA sont utilisées pour gérer la réplication du système SAP HANA en combinaison avec des instances SAP HANA compatibles avec systemd (consultez la note SAP 3189534), des étapes supplémentaires sont nécessaires pour que le cluster HA puisse gérer l’instance SAP sans interférence avec systemd. Par conséquent, pour le système SAP HANA intégré à systemd, il convient de suivre les étapes supplémentaires décrites dans l’article KBA Red Hat 7029705 sur tous les nœuds de cluster.
Implémentez les hooks de réplication du système SAP HANA
Cette étape importante permet d’optimiser l’intégration au cluster et de mieux détecter le moment où un basculement s’avère nécessaire. Il est obligatoire pour le bon fonctionnement du cluster d'activer le hook SAPHanaSR. Nous vous recommandons fortement de configurer les hooks Python SAPHanaSR et ChkSrv.
[A] Installez les agents de la ressource SAP HANA sur tous les nœuds. N’oubliez pas d’activer un référentiel qui contient le package. Vous n’avez pas besoin d’activer davantage de référentiels si vous utilisez une image RHEL 8.x ou supérieure compatible HA.
# Enable repository that contains SAP HANA resource agents sudo subscription-manager repos --enable="rhel-sap-hana-for-rhel-7-server-rpms" sudo dnf install -y resource-agents-sap-hanaRemarque
Pour RHEL 8.x et RHEL 9.x, vérifiez que le package resource-agents-sap-hana installé est la version 0.162.3-5 ou ultérieure.
[A] Installez
system replication hooksHANA. La configuration des hooks de réplication doit être installée sur les deux nœuds HANA DB.Arrêter HANA sur les deux nœuds. Exécutez en tant que <sid>adm.
sapcontrol -nr 03 -function StopSystemRéglez
global.inisur chaque nœud du cluster.[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR/srHook execution_order = 1 [ha_dr_provider_chksrv] provider = ChkSrv path = /usr/share/SAPHanaSR/srHook execution_order = 2 action_on_lost = kill [trace] ha_dr_saphanasr = info ha_dr_chksrv = info
Si vous pointez le paramètre
pathvers l'emplacement/usr/share/SAPHanaSR/srHookpar défaut, le code du hook Python est mis à jour automatiquement via les mises à jour du système d'exploitation ou les mises à jour du package. HANA utilise les mises à jour du code de hook lors du redémarrage suivant. Avec un chemin propre facultatif comme/hana/shared/myHooks, vous pouvez découpler les mises à jour du système d'exploitation de la version du hook que HANA utilisera.Vous pouvez ajuster le comportement du hook
ChkSrven utilisant le paramètreaction_on_lost. Les valeurs valides sont [ignore|stop|kill].[A] Le cluster nécessite une configuration de
sudoerssur chaque nœud de cluster pour <sid>adm. Dans cet exemple, cela est accompli en créant un fichier. Utilisez la commandevisudopour modifier le fichier déposé20-saphanaen tant queroot.sudo visudo -f /etc/sudoers.d/20-saphanaInsérez les lignes suivantes, puis enregistrez :
Cmnd_Alias SITE1_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE1_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL Defaults!SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL !requiretty[A] Démarrez SAP HANA sur les deux nœuds. Exécutez en tant que <sid>adm.
sapcontrol -nr 03 -function StartSystem[1] Vérifiez l’installation du hook SRHanaSR. Exécutez en tant que <sid>adm sur le site de réplication du système HANA actif.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_*# 2021-04-12 21:36:16.911343 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:36:29.147808 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:37:04.898680 ha_dr_SAPHanaSR SOK[1] Vérifiez l’installation du hook ChkSrv. Exécutez en tant que <sid>adm sur le site de réplication du système HANA actif.
cdtrace tail -20 nameserver_chksrv.trc
Pour plus d'informations sur l'implémentation des hooks SAP HANA, voir Activation du hook SAP HANA srConnectionChanged() et Activation du hook SAP HANA srServiceStateChanged() pour l'action d'échec du processus hdbindexserver (facultatif).
Créer les ressources de cluster SAP HANA
Créez la topologie HANA. Exécutez les commandes suivantes sur l’un des nœuds du cluster Pacemaker. Tout au long de ces instructions, veillez à remplacer votre numéro d’instance, l’ID du système HANA, les adresses IP et les noms de système, le cas échéant.
sudo pcs property set maintenance-mode=true
sudo pcs resource create SAPHanaTopology_HN1_03 SAPHanaTopology SID=HN1 InstanceNumber=03 \
op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 \
clone clone-max=2 clone-node-max=1 interleave=true
Ensuite, créez les ressources HANA.
Remarque
Cet article contient des références à un terme qui n’est plus utilisé par Microsoft. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
Si vous créez un cluster sur RHEL 7.x, utilisez les commandes suivantes :
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
master notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-master symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-master 4000
sudo pcs resource defaults resource-stickiness=1000
sudo pcs resource defaults migration-threshold=5000
sudo pcs property set maintenance-mode=false
Si vous créez un cluster sur RHEL 8.x/9.x, utilisez les commandes suivantes :
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
promotable notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-clone symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-clone 4000
sudo pcs resource defaults update resource-stickiness=1000
sudo pcs resource defaults update migration-threshold=5000
sudo pcs property set maintenance-mode=false
Pour configurer priority-fencing-delay pour SAP HANA (valable uniquement à partir de pacemaker-2.0.4-6.el8 ou version ultérieure), les commandes suivantes doivent être exécutées.
Remarque
Si vous disposez d’un cluster à deux nœuds, vous pouvez configurer la propriété de cluster priority-fencing-delay. Cette propriété introduit un délai de clôturage pour un nœud dont la priorité totale sur les ressources est supérieure lorsqu’un scénario « split-brain » se déroule. Pour plus d’informations, consultez Pacemaker peut-il clôturer le nœud de cluster avec le moins de ressources en cours d’exécution ?.
La propriété priority-fencing-delay s’applique à la version pacemaker-2.0.4-6.el8 ou ultérieure. Si vous configurez priority-fencing-delay sur un cluster existant, veillez à annuler l’option pcmk_delay_max dans l’appareil faisant l’objet du clôturage.
sudo pcs property set maintenance-mode=true
sudo pcs resource defaults update priority=1
sudo pcs resource update SAPHana_HN1_03-clone meta priority=10
sudo pcs property set priority-fencing-delay=15s
sudo pcs property set maintenance-mode=false
Important
Il est judicieux de définir AUTOMATED_REGISTER sur false, pendant que vous effectuez des tests de basculement, afin d’éviter qu’une instance principale défaillante ne s’inscrive automatiquement comme secondaire. Après le test, la meilleure pratique consiste à définir AUTOMATED_REGISTER sur true de sorte qu’après la prise de contrôle, la réplication du système puisse reprendre automatiquement.
Vérifiez que l’état du cluster est convenable et que toutes les ressources sont démarrées. Le nœud sur lequel les ressources s’exécutent n’est pas important.
Remarque
Les délais d’expiration dans la configuration précédente sont simplement des exemples et devront éventuellement être adaptés à la configuration HANA spécifique. Par exemple, vous devrez peut-être augmenter le délai de démarrage, si le démarrage de la base de données SAP HANA prend plus de temps.
Utilisez la commande sudo pcs status pour vérifier l’état des ressources de cluster créées :
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# azure_fence (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Configurer la réplication du système active/accessible en lecture HANA dans le cluster Pacemaker
À compter de SAP HANA 2.0 SPS 01, SAP autorise les configurations actives/accessibles en lecture pour la réplication du système SAP HANA, où les systèmes secondaires de réplication du système SAP HANA peuvent être utilisés activement pour les charges de travail à forte intensité de lecture.
Pour prendre en charge une telle configuration dans un cluster, une deuxième adresse IP virtuelle est nécessaire, ce qui permet aux clients d’accéder à la base de données SAP HANA secondaire accessible en lecture. Pour que le site de réplication secondaire reste accessible après une prise de contrôle, le cluster doit faire suivre l’adresse IP virtuelle avec la ressource SAPHana secondaire.
Cette section décrit les autres étapes nécessaires pour gérer la réplication du système active/accessible en lecture HANA dans un cluster HA Red Hat avec une deuxième adresse IP virtuelle.
Avant d’aller plus loin, vérifiez que vous avez entièrement configuré le cluster HA Red Hat gérant une base de données SAP HANA, comme décrit dans les sections précédentes de la documentation.
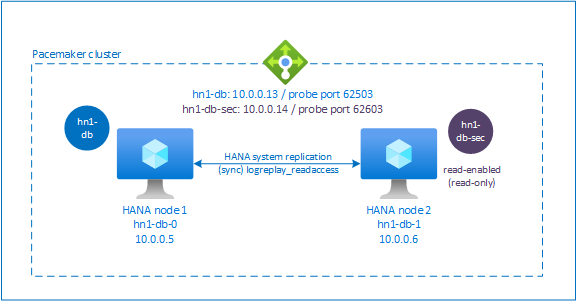
Configuration supplémentaire dans l’Équilibreur de charge Azure pour une installation active/en lecture activée
Pour passer à des étapes supplémentaires en vue d’approvisionner une deuxième adresse IP virtuelle, vérifiez que vous avez configuré Azure Load Balancer comme décrit dans la section Déployer manuellement des machines virtuelles Linux via le portail Azure.
Pour un équilibreur de charge standard, suivez ces étapes sur l’équilibreur de charge que vous avez créé dans une section précédente.
a. Créez un deuxième pool d’adresses IP frontales :
- Ouvrez l’équilibrage de charge, sélectionnez le Pool d’adresses IP frontales, puis cliquez sur Ajouter.
- Entrez le nom du deuxième pool d’adresses IP frontales (par exemple hana-secondaryIP).
- Définissez Affectation sur Statique et entrez l’adresse IP (par exemple, 10.0.0.14).
- Cliquez sur OK.
- Une fois le pool d’adresses IP frontal créé, notez son adresse IP.
b. Créez une sonde d’intégrité :
- Ouvrez l’équilibrage de charge, sélectionnez les sondes d’intégrité, puis cliquez sur Ajouter.
- Entrez le nom de la nouvelle sonde d’intégrité (par exemple, hana-secondaryhp).
- Sélectionnez TCP comme protocole et le port 62603. Conservez la valeur du paramètre Intervalle définie sur 5 et celle du Seuil de défaillance sur le plan de l’intégrité sur 2.
- Cliquez sur OK.
c. Créez les règles d’équilibrage de charge :
- Ouvrez l’équilibrage de charge, sélectionnez Règles d’équilibrage de charge, puis cliquez sur Ajouter.
- Entrez le nom de la nouvelle règle d’équilibrage de charge (par exemple, hana-secondarylb).
- Sélectionnez l’adresse IP frontale, le pool principal et la sonde d’intégrité que vous avez créés (par exemple,hana-secondaryIP, hana-backend et hana-secondaryhp).
- Sélectionnez Ports HA.
- Veillez à activer l’IP flottante .
- Sélectionnez OK.
Configurez la réplication du système HANA actif/en lecture activée
La procédure de configuration de la réplication du système HANA est décrite dans la section Configurer la réplication du système SAP HANA 2.0. Si vous déployez un scénario secondaire avec accès en lecture pendant que vous configurez la réplication du système sur le deuxième nœud, exécutez la commande suivante en tant que hanasidadm :
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2 --operationMode=logreplay_readaccess
Ajoutez une ressource d’adresse IP virtuelle secondaire pour une installation active/en lecture activée
La deuxième adresse IP virtuelle et la contrainte de colocation appropriée peuvent être configurées avec les commandes suivantes :
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.40.0.16"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
pcs constraint location g_secip_HN1_03 rule score=INFINITY hana_hn1_sync_state eq SOK and hana_hn1_roles eq 4:S:master1:master:worker:master
pcs constraint location g_secip_HN1_03 rule score=4000 hana_hn1_sync_state eq PRIM and hana_hn1_roles eq 4:P:master1:master:worker:master
# Set the priority to primary IPaddr2 and azure-lb resource if priority-fencing-delay is configured
sudo pcs resource update vip_HN1_03 meta priority=5
sudo pcs resource update nc_HN1_03 meta priority=5
pcs property set maintenance-mode=false
Vérifiez que l’état du cluster convient et que toutes les ressources sont démarrées. La deuxième adresse IP virtuelle s’exécute sur le site secondaire avec la ressource secondaire SAPHana.
sudo pcs status
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full List of Resources:
# rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]:
# Started: [ hn1-db-0 hn1-db-1 ]
# Clone Set: SAPHana_HN1_03-clone [SAPHana_HN1_03] (promotable):
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03:
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# Resource Group: g_secip_HN1_03:
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Dans la section suivante, vous trouverez l’ensemble typique de tests de basculement à exécuter.
Soyez attentif au comportement de la deuxième adresse IP virtuelle pendant que vous testez un cluster HANA configuré avec le secondaire accessible en lecture :
Lorsque vous migrez la ressource de cluster SAPHana_HN1_03 vers le site secondaire hn1-db-1, la deuxième adresse IP virtuelle continue de s’exécuter sur le même site hn1-db-1. Si vous avez défini
AUTOMATED_REGISTER="true"pour la ressource et que la réplication du système HANA est inscrite automatiquement sur hn1-db-0, votre deuxième adresse IP virtuelle se déplace également vers hn1-db-0.Lorsque vous testez une panne de serveur, les ressources de la deuxième adresse IP virtuelle (secvip_HN1_03) et les ressources de port Azure Load Balancer (secnc_HN1_03) s’exécutent sur le serveur principal en même temps que les ressources IP virtuelles principales. Ainsi, tant que le serveur secondaire n’est pas hors service, les applications connectées à la base de données HANA accessible en lecture se connectent à la base de données HANA primaire. Ce comportement est attendu, car il n’est pas souhaitable que les applications connectées à la base de données HANA accessible en lecture soient inaccessibles tant que le serveur secondaire n’est pas indisponible.
Pendant le basculement et la restauration de la deuxième adresse IP virtuelle, il peut arriver que les connexions existantes sur des applications qui utilisent la deuxième adresse IP virtuelle pour se connecter à la base de données HANA soient interrompues.
La configuration maximise le temps d’affectation de la deuxième ressource d’adresse IP virtuelle à un nœud sur lequel une instance SAP HANA saine s’exécute.
Tester la configuration du cluster
Cette section explique comment vous pouvez tester votre configuration. Avant de lancer un test, vérifiez que Pacemaker ne présente pas d’action en échec (via psc status), qu’il n’existe pas de contraintes d’emplacement inattendues (par exemple, les restes d’un test de migration) et que HANA est en état de synchronisation, par exemple avec systemReplicationStatus.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"
Tester la migration
État des ressources avant le début du test :
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Vous pouvez migrer le nœud maître SAP HANA en exécutant la commande suivante en tant que racine :
# On RHEL 7.x
pcs resource move SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource move SAPHana_HN1_03-clone --master
Le cluster ferait migrer le nœud principal SAP HANA et le groupe qui contient l’adresse IP virtuelle vers hn1-db-1.
Une fois la migration terminée, la sortie sudo pcs status se présente comme suit :
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Avec AUTOMATED_REGISTER="false", le cluster ne redémarre pas la base de données HANA ayant échoué et ne l’inscrit pas auprès du nouveau serveur principal sur hn1-db-0. Dans ce cas, configurez l’instance HANA comme étant secondaire en exécutant ces commandes en tant que hh1adm :
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
La migration crée des contraintes d’emplacement qui doivent être de nouveau supprimées. Exécutez la commande suivante en tant que racine ou via sudo :
pcs resource clear SAPHana_HN1_03-master
Surveillez l’état de la ressource HANA à l’aide de pcs status. Une fois que HANA est lancé sur hn1-db-0, la sortie doit se présenter comme suit :
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Bloquer la communication réseau
État des ressources avant le début du test :
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Exécutez la règle de pare-feu pour bloquer la communication sur l’un des nœuds.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Lorsque les nœuds de cluster ne peuvent pas communiquer entre eux, il y a un risque de scénario « split-brain ». En pareil cas, les nœuds de cluster essaient de se clôturer les uns les autres, ce qui entraîne une course au clôturage. Pour éviter une telle situation, nous vous recommandons de définir la propriété priority-fencing-delay dans la configuration du cluster (valable uniquement pour pacemaker-2.0.4-6.el8 ou version supérieure).
En activant la propriété priority-fencing-delay, le cluster introduit un délai dans l’action de clôturage précisément sur le nœud hébergeant la ressource principale HANA, ce qui permet au nœud de gagner la course au clôturage.
Exécutez la commande suivante pour supprimer la règle de pare-feu :
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Tester l’agent de délimitation Azure
Remarque
Cet article contient des références à un terme qui n’est plus utilisé par Microsoft. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
État des ressources avant le début du test :
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Vous pouvez tester l’installation de l’agent de délimitation Azure en désactivant l’interface réseau sur le nœud sur lequel SAP HANA s’exécute en tant que nœud principal. Pour savoir comment simuler une défaillance réseau, consultez l’article de la base de connaissances Red Hat 79523.
Dans cet exemple, nous utilisons le script net_breaker en tant que racine pour bloquer tout accès au réseau :
sh ./net_breaker.sh BreakCommCmd 10.0.0.6
La machine virtuelle doit maintenant redémarrer ou s’arrêter en fonction de la configuration de votre cluster.
Si vous définissez le paramètre stonith-action sur off, la machine virtuelle s’arrête et les ressources sont migrées vers la machine virtuelle en cours d’exécution.
Après avoir redémarré la machine virtuelle, la ressource SAP HANA ne peut pas démarrer en tant que ressource secondaire si vous définissez AUTOMATED_REGISTER="false". Dans ce cas, configurez l’instance HANA comme étant secondaire en exécutant cette commande en tant qu’utilisateur hn1adm :
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
Revenez à la racine et nettoyez l’état en échec :
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
État des ressources après le test :
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Tester un basculement manuel
État des ressources avant le début du test :
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Vous pouvez tester un basculement manuel en arrêtant le cluster sur le nœud hn1-db-0, en tant que racine :
pcs cluster stop
Après le basculement, redémarrez le cluster. Si vous définissez AUTOMATED_REGISTER="false", la ressource SAP HANA sur le nœud hn1-db-0 ne parvient pas à démarrer en tant que ressource secondaire. Dans ce cas, configurez l’instance HANA comme étant secondaire en exécutant cette commande en tant que racine :
pcs cluster start
Exécutez ce qui suit en tant que hn1adm :
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
Puis en tant que racine :
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
État des ressources après le test :
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1