Déploiement SGBD de machines virtuelles SQL Server Azure pour SAP NetWeaver
Ce document décrit les différents domaines à prendre en compte lors du déploiement de SQL Server pour une charge de travail SAP dans Azure IaaS. Comme condition préalable à ce document, veuillez lire le document Facteurs à prendre en compte pour le déploiement SGBD des machines virtuelles Azure pour la charge de travail SAP et d’autres guides de la documentation sur la charge de travail SAP sur Azure.
Important
Ce document est consacré à la version de Windows sur SQL Server. Le protocole SAP ne prend en charge la version Linux de SQL Server avec aucun logiciel SAP. Le document ne traite pas ici de Microsoft Azure SQL Database, qui est une offre Platform as a Service (PaaS) de la plateforme Microsoft Azure. Ce document porte sur l’exécution du produit SQL Server tel qu’il existe pour les déploiements locaux dans Machines Virtuelles Azure, en tirant profit de la capacité IaaS (infrastructure as a service) d’Azure. Les capacités et fonctionnalités de base de données de ces deux offres sont différentes et ne doivent pas être confondues. Pour plus d’informations, consultez Azure SQL Database.
En général, vous devez penser à utiliser les versions de SQL Server les plus récentes pour exécuter une charge de travail SAP dans Azure IaaS. Les dernières versions de SQL Server offrent une meilleure intégration à certains des services et fonctionnalités Azure. Et elles comportent des modifications qui optimisent les opérations dans une infrastructure Azure IaaS.
La documentation générale sur SQL Server exécuté dans des machines virtuelles Azure est disponible dans les articles suivants :
- SQL Server sur les machines virtuelles Azure (Windows)
- Automatiser la gestion avec l’extension Windows SQL Server IaaS Agent
- Configurer l’intégration d’Azure Key Vault pour SQL Server sur des machines virtuelles (Resource Manager)
- Liste de vérification : Meilleures pratiques relatives à SQL Server sur les machines virtuelles Azure
- Stockage : Meilleures pratiques sur les performances de SQL Server sur les machines virtuelles Azure
- Bonnes pratiques de configuration de la HADR (SQL Server sur des machines virtuelles Azure)
Le contenu et les instructions de la documentation générale sur SQL Server dans les machines virtuelles Azure ne concernent pas seulement la charge de travail SAP. Toutefois, la documentation donne un bon aperçu des principes. L’une des fonctionnalités non prises en charge pour la charge de travail SAP est, par exemple, l’utilisation du clustering FCI.
Avant de continuer, il y a certaines informations spécifiques sur SQL Server dans IaaS que vous devez connaître :
- Prise en charge des versions SQL : même avec la note SAP #1928533 indiquant que la version minimale de SQL Server prise en charge est SQL Server 2008 R2, la fenêtre des versions SQL Server prises en charge sur Azure est également dictée par le cycle de vie de SQL Server. La maintenance étendue de SQL Server 2012 a pris fin vers le milieu de l’année 2022. Par conséquent, la version minimale actuelle des systèmes nouvellement déployés doit être SQL Server 2014. Plus la version est récente, mieux c’est. Les dernières versions de SQL Server offrent une meilleure intégration à certains des services et fonctionnalités Azure. Et elles comportent des modifications qui optimisent les opérations dans une infrastructure Azure IaaS.
- Utilisation d’images de la Place de marché Azure : La méthode la plus rapide pour déployer une nouvelle machine virtuelle Microsoft Azure est d’utiliser une image de la Place de marché Microsoft Azure. En effet, cette plateforme propose des images qui contiennent les versions les plus récentes de SQL Server. Les images hébergeant déjà SQL Server ne peuvent pas être directement utilisées pour les applications SAP NetWeaver. En effet, le classement par défaut installé au sein de ces images correspond à celui de SQL Server, et non au classement requis pour les systèmes SAP NetWeaver. Pour pouvoir utiliser ces images, suivez la procédure décrite dans le chapitre Utilisation d'images SQL Server issues de la Place de marché Microsoft Azure.
- Prise en charge de plusieurs instances SQL Server dans une seule machine virtuelle Azure : cette méthode de déploiement est prise en charge. Cependant, soyez conscient des limitations de ressources, en particulier en matière de bande passante de réseau et de stockage du type de machine virtuelle que vous utilisez. Des informations détaillées sont disponibles dans l’articleTailles pour les machines virtuelles dans Azure. Ces limitations de quota peuvent vous empêcher d’implémenter la même architecture multi-instance que vous pouvez implémenter localement. À partir de la configuration et de l’interférence du partage des ressources disponibles dans une seule machine virtuelle, les mêmes considérations qu’à l’échelle locale doivent être prises en compte.
- Plusieurs bases de données SAP dans une instance SQL Server sur une machine virtuelle : ce type de configuration est pris en charge. Les considérations relatives à plusieurs bases de données SAP qui partagent les ressources partagées d’une instance de SQL Server unique sont les mêmes que pour les déploiements locaux. Tenez compte des autres limites, comme le nombre de disques qui peuvent être attachés à un type VM spécifique. Ou les limites de quota de réseau et de stockage de types de machines virtuelles spécifiques Tailles pour les machines virtuelles dans Azure.
Nouvelles machines virtuelles de la série M et SQL Server
Azure a publié quelques nouvelles familles de références SKU de série M sous la famille de Mv3. Certains types de machines virtuelles de cette famille ne doivent pas être utilisés pour SQL Server, y compris SQL Server 2022, sans désactiver SMT (Hyperthreading) dans le système d’exploitation invité Windows Server. La raison est le nombre de nœuds NUMA présentés dans le système d’exploitation invité Windows Server, qui, avec plus de 64 processeurs virtuels, est trop grand pour être pris en charge par SQL Server. En désactivant SMT dans le système d’exploitation invité Windows Server, le nombre de processeurs virtuels est réduit. Ainsi, le nombre de processeurs virtuels est inférieur à 64 dans chaque nœud NUMA. La méthode pour désactiver SMT est décrite ici. Les types de machines virtuelles spécifiques sont les suivants :
- M176(d)s_3_v3 : désactiver SMT ou utiliser M176bds_4_v3 ou M176bds_4_v3 comme alternative
- M176(d)s_4_v3 : désactiver SMT ou utiliser M176bds_4_v3 comme alternative
- M624(d)s_12_v3 : désactiver SMT ou utiliser M416ms_v2 comme alternative
- M832(d)s_12_v3 : désactivez SMT ou utilisez M416ms_v2 comme alternative
- M832i(d)s_16_v3 : désactivez SMT ou utilisez M416ms_v2 comme alternative
Remarque
Pour certains des nouveaux types de machines virtuelles M(b)v3, l’utilisation du stockage SSD Premium v1 en lecture mise en cache peut entraîner un débit et des taux d’E/S par seconde de lecture et d’écriture inférieurs à ceux que vous obtiendriez si vous n’utilisez pas le cache de lecture.
Recommandations portant sur la structure des machines virtuelles/disques VHD pour les déploiements de SQL Server associés à SAP
Conformément à la description générale, le système d’exploitation, les exécutables SQL Server et les exécutables SAP doivent se situer ou être installés sur des disques Azure distincts. Bien souvent, la plupart des bases de données système SQL Server ne sont pas pleinement exploitées avec les charges de travail SAP NetWeaver. Néanmoins, les bases de données système de SQL Server doivent être, avec les autres répertoires SQL Server, sur un disque Azure distinct. La base de données tempdb de SQL Server doit se trouver sur le lecteur D:\ non persistant ou sur un disque distinct.
- Avec tous les types de machines virtuelles certifiés SAP (voir la note SAP #1928533), les données tempdb et les fichiers journaux peuvent être placés sur le lecteur D:\ non persistant.
- Avec des versions de SQL Server où tempdb est installé avec un seul fichier de données, il est recommandé d’utiliser plusieurs fichiers de données tempdb. Pour rappel, les volumes de lecteur D:\ n’ont pas la même taille et la même capacité selon le type VM. Pour connaître les tailles exactes du lecteur D:\ des différentes machines virtuelles, consultez l’article Tailles des machines virtuelles Windows dans Azure.
Ces configurations permettent à la base de données tempdb de consommer davantage d’espace et, plus important, davantage d’IOPS (opérations d’entrée/sortie par seconde) et de bande passante de stockage que ce que peut proposer le lecteur système. Le lecteur D:\ non persistant offre également une meilleure latence d’E/S et un meilleur débit. Pour déterminer la taille de base de données tempdb appropriée, vous pouvez consulter les tailles des bases de données tempdb sur les systèmes existants.
Notes
Si vous placez un fichier journal et les fichiers de données tempdb dans un dossier sur le lecteur D:\ que vous avez créé, vous devez vous assurer que le dossier existe après un redémarrage de la machine virtuelle. Comme le lecteur D:\ peut être réinitialisé après le redémarrage d’une machine virtuelle, toutes les structures de répertoires et de fichiers peuvent être effacées. La possibilité de recréer des structures de répertoires sur le lecteur D:\ avant le démarrage du service SQL Server est documentée dans cet article.
Voici un exemple de configuration VM qui exécute SQL Server avec une base de données SAP, et où les données et le fichier journal tempdb sont placés sur le lecteur D:\ et un stockage Premium Azure v1 ou v2 :
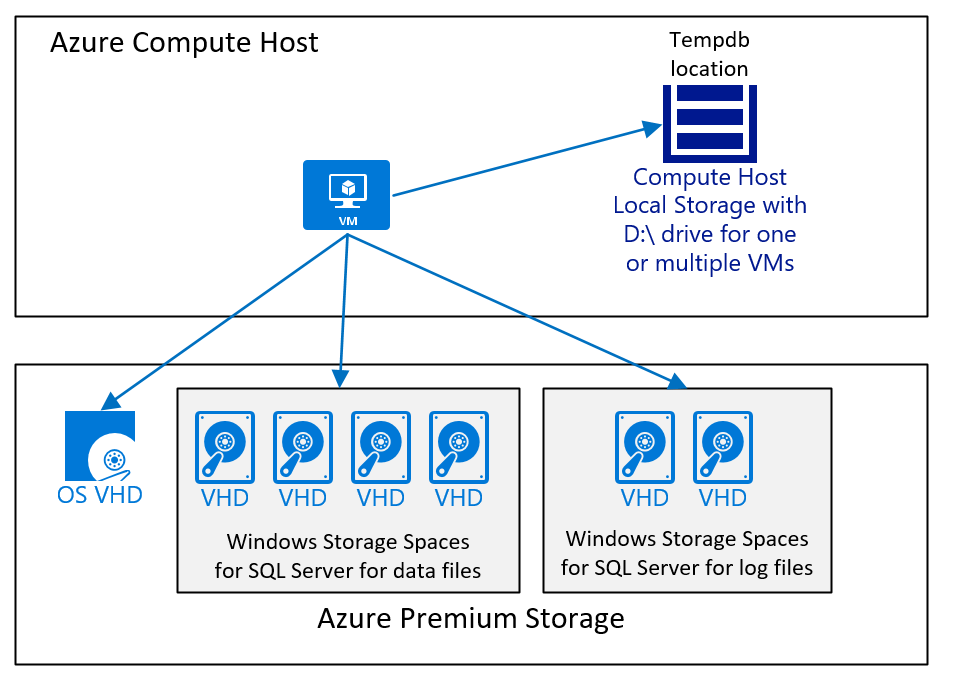
Le diagramme affiche un cas simple. Comme l’évoque l’article Facteurs à prendre en compte pour le déploiement SGBD des machines virtuelles Azure pour la charge de travail SAP, le type, le nombre et la taille des disques du stockage Azure dépendent de différents facteurs. Cependant, en général, nous recommandons :
- Pour les déploiements plus petits et intermédiaires, utilisez un grand volume qui contient les fichiers de données SQL Server. La raison de cette configuration est qu’il est plus facile de gérer différentes charges de travail d’E/S quand les fichiers de données SQL Server n’ont pas le même espace libre. Alors que dans les grands déploiements, en particulier les déploiements où le client a effectué une migration de base de données hétérogène vers SQL Server dans Azure, nous avons utilisé des disques distincts pour distribuer les fichiers de données. Ce type d’architecture fonctionne seulement quand chaque disque a le même nombre de fichiers de données, que tous les fichiers de données ont la même taille et ont à peu près le même espace libre.
- D’utiliser le lecteur D:\ pour tempdb tant que les performances sont suffisantes. Si la charge de travail générale est limitée en performances par tempdb qui se trouve sur le lecteur D:\, vous devez déplacer tempdb sur un disque de stockage Premium Azure v1 ou v2 ou un disque Ultra, comme recommandé dans cet article.
Le mécanisme de remplissage proportionnel de SQL Server distribue les lectures et les écritures entre tous les fichiers de données de manière égale, à condition que tous les fichiers de données SQL Server aient la même taille et le même espace libre. SAP sur SQL Server offre les meilleures performances lorsque les lectures et les écritures sont distribuées de manière égale entre tous les fichiers de données disponibles. Si une base de données a trop peu de fichiers de données ou si les fichiers de données existants sont fortement déséquilibrés, la meilleure méthode est de faire une exportation et une importation R3load. Une exportation et une importation R3load impliquent un temps d’arrêt et doivent être effectuées uniquement si un problème de performance évident a besoin d’être résolu. Si les tailles des fichiers de données sont modérément différentes, augmentez toutes les tailles des fichiers de données pour qu’elles soient identiques. De cette façon, SQL Server rééquilibre les données au fil du temps. SQL Server augmente automatiquement la taille des fichiers de données de manière égale si l’indicateur de trace 1117 est défini, ou si SQL Server 2016 ou version ultérieure est utilisé indicateur de trace.
Remarque relative aux machines virtuelles de la série M
Pour une machine virtuelle Azure de la série M, la latence d’écriture dans le journal de transactions peut être réduite, par rapport aux performances du stockage Premium Azure v1, avec l’utilisation de l’accélérateur d’écriture Azure. Si la latence fournie par le stockage Premium v1 limite la scalabilité de la charge de travail SAP, vous pouvez activer l’accélérateur d’écriture sur le disque qui stocke le fichier journal des transactions SQL Server. Les détails peuvent être consultés dans le document Accélérateur des écritures. L’accélérateur d’écriture Azure ne fonctionne pas avec le stockage Premium Azure v2 et les disques Ultra. Dans les deux cas, la latence est meilleure que celle du stockage Premium Azure v1. L’accélérateur d’écriture ne prend pas en charge SSD Premium v2.
Remarque
Pour certains des nouveaux types de machines virtuelles M(b)v3, l’utilisation du stockage SSD Premium v1 en lecture mise en cache peut entraîner un débit et des taux d’E/S par seconde de lecture et d’écriture inférieurs à ceux que vous obtiendriez si vous n’utilisez pas le cache de lecture.
Formatage des disques
Dans le cas de SQL Server, la taille du bloc NTFS des disques contenant des données et des fichiers journaux SQL Server doit être de 64 ko. Il est inutile de formater le lecteur D:\. Ce lecteur est préformaté.
Pour que la restauration ou la création de bases de données n’initialise pas les fichiers de données en supprimant le contenu des fichiers, vérifiez que le contexte utilisateur dans lequel s’exécute le service SQL Server a le droit d’utilisateur Effectuer des tâches de maintenance de volume. Pour plus d’informations, consultez Initialisation instantanée des fichiers de base de données.
SQL Server 2014 et versions plu récentes : Stockage des fichiers de base de données directement dans le Stockage Blob Azure
Les versions SQL Server 2014 et ultérieures permettent de stocker les fichiers de base de données directement dans le stockage d’objets blob Azure, sans qu’il soit nécessaire d’utiliser un disque VHD pour « envelopper » ces fichiers. Cette fonctionnalité avait pour but de résoudre les lacunes du stockage de bloc Azure il y a des années. De nos jours, il n’est pas recommandé d’utiliser cette méthode de déploiement. Il vaut mieux choisir le stockage Premium Azure v1, le stockage Premium v2 ou un disque Ultra. Dépendant des exigences.
Considérations relatives à la sauvegarde/restauration pour SQL Server
Quand vous déployez SQL Server sur Azure, vous devez passer en revue votre architecture de sauvegarde. Même si le système n’est pas un système de production, la base de données SAP SQL Server doit être sauvegardée régulièrement. Comme Azure Storage conserve trois images, la sauvegarde joue désormais un rôle moins important en matière de compensation des pannes du stockage. La raison principale du maintien d’un plan de sauvegarde et de récupération approprié réside davantage dans le fait que vous pouvez compenser les erreurs logiques/manuelles en fournissant des fonctionnalités de récupération jusqu’à une date et heure. Le but est d’utiliser les sauvegardes pour restaurer la base de données à un certain point dans le temps Ou vous pouvez utiliser les sauvegardes dans Azure pour amorcer un autre système en copiant la base de données existante.
Il existe plusieurs façons de sauvegarder et de restaurer des bases de données SQL Server dans Azure. Pour plus d’informations, lisez le document Sauvegarde et restauration de SQL Server sur des machines virtuelles Azure. Cet article présente plusieurs possibilités.
Utilisation d’une image SQL Server issue de la Place de marché Microsoft Azure
Dans la Place de marché Azure, Microsoft propose des machines virtuelles qui contiennent déjà des versions de SQL Server. Pour les clients SAP qui requièrent des licences pour SQL Server et Windows, l’utilisation de ces images peut être l’occasion de répondre aux besoins en termes de licences, en configurant des machines virtuelles déjà dotées de SQL Server. Pour pouvoir utiliser ces images pour SAP, vous devez tenir compte des considérations suivantes :
- Les versions de SQL Server autres que les versions d’évaluation nécessitent des frais d’acquisition plus élevés que les machines virtuelles « Windows uniquement » qui sont déployées à partir de la Place de marché Azure. Pour comparer les prix, consultez Tarification Machines virtuelles Windows et Tarification Machines virtuelles SQL Server Entreprise.
- Vous pouvez uniquement utiliser les versions de SQL Server qui sont prises en charge par SAP pour leur logiciel.
- Le classement de l’instance SQL Server qui est installée dans les machines virtuelles proposées par la Place de marché ne correspond pas à celui que nécessite SAP NetWeaver pour l’instance SQL Server. Toutefois, vous pouvez modifier ce classement, en suivant les instructions de la section suivante.
Modification du classement SQL Server d’une machine virtuelle Microsoft Windows/SQL Server
Étant donné que les images SQL Server disponibles sur la Place de marché Microsoft Azure ne sont pas configurées pour utiliser le classement, ce qui est exigé pour les applications SAP NetWeaver, elles doivent être modifiées immédiatement après le déploiement. Pour SQL Server, cette modification de classement peut être exécutée en suivant la procédure ci-après dès que la machine virtuelle est déployée et qu’un administrateur peut se connecter à cette dernière :
- Ouvrez une fenêtre de commande Windows en tant qu’administrateur.
- Remplacez le répertoire par celui-ci : C:\Program Files\Microsoft SQL Server\110\Setup Bootstrap\SQLServer2012.
- Exécutez la commande suivante : Setup.exe /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=MSSQLSERVER /SQLSYSADMINACCOUNTS=
<local_admin_account_name> /SQLCOLLATION=SQL_Latin1_General_Cp850_BIN2-
<local_admin_account_name> correspond au compte qui a été défini en tant que compte d’administrateur lors du déploiement de la machine virtuelle pour la première fois, via la galerie.
-
Le processus doit prendre quelques minutes seulement. Pour vérifier que le résultat attendu a été obtenu, effectuez les étapes suivantes :
- Ouvrez SQL Server Management Studio.
- Ouvrez une fenêtre Requête.
- Exécutez la commande sp_helpsort dans la base de données MASTER de SQL Server.
Le résultat doit être similaire à ce qui suit :
Latin1-General, binary code point comparison sort for Unicode Data, SQL Server Sort Order 40 on Code Page 850 for non-Unicode Data
Si le résultat est différent, ARRÊTEZ immédiatement le déploiement et investiguez la raison pour laquelle la commande n’a pas fonctionné comme prévu. Le déploiement d’applications SAP NetWeaver sur une instance SQL Server avec des pages de codes SQL Server autres que celle indiquée n’est PAS pris en charge dans les déploiements NetWeaver.
Solutions SQL Server haute disponibilité pour SAP dans Azure
En utilisant SQL Server dans les déploiements IaaS Azure pour SAP, plusieurs méthodes sont à votre disposition pour déployer la couche de base de données à haute disponibilité. Azure fournit différents contrats SLA de disponibilité pour chaque machine virtuelle en utilisant différents stockages de bloc Azure, une paire de machines virtuelles déployées dans un groupe à haute disponibilité Azure ou une paire de machines virtuelles déployées dans des zones de disponibilité Azure. Pour les systèmes de production, vous devez déployer une paire de machines virtuelles au sein d’un groupe de machines virtuelles identiques avec une orchestration flexible dans deux zones de disponibilité. Pour plus d’informations, consultez Comparaison de différents types de déploiement pour la charge de travail SAP. Une machine virtuelle exécute l’instance SQL Server active. L’autre machine virtuelle exécute l’instance passive.
Clustering de SQL Server à l’aide du serveur de fichiers avec Scale-out de Windows ou d’un disque partagé Azure
Avec Windows Server 2016, Microsoft a introduit les espaces de stockage direct. La prise en charge du clustering FCI de SQL Server dépend du déploiement des espaces de stockage direct. Azure propose également des disques partagés Azure qui peuvent être utilisés pour le clustering Windows. Pour la charge de travail SAP, nous ne prenons pas en charge ces options de haute disponibilité.
Copie des journaux de transaction SQL Server
La copie des journaux de transaction SQL Server est une des fonctionnalités de haute disponibilité. Si la résolution de noms des machines virtuelles participant à la configuration HA fonctionne normalement, il n’y a aucun problème. La configuration dans Azure ne diffère pas de la configuration locale concernant la copie des journaux de transaction et les principes qui l’entourent. Pour plus d’informations sur la copie des journaux de transaction SQL Server, consultez l’article À propos de la copie des journaux de transaction (SQL Server).
La fonctionnalité de copie des journaux de transaction de SQL Server a été rarement utilisée dans Azure pour atteindre la haute disponibilité dans une région Azure. Toutefois, dans les scénarios suivants, les clients SAP utilisaient la copie des journaux de transaction avec succès avec Azure :
- Scénarios de récupération d’urgence d’une région Azure dans une autre région Azure.
- Configuration de la reprise d’activité après sinistre à partir d’un environnement local dans une région Azure.
- Scénarios de basculement à partir d’un environnement local vers Azure. Dans ces cas-là, la copie des journaux de transaction est utilisée pour synchroniser le nouveau déploiement de base de données dans Azure avec le système de production en cours en local. Au moment du basculement, la production est arrêtée, et il convient de vérifier que les dernières sauvegardes des journaux de transactions ont été transférées vers le déploiement de base de données Azure. Le déploiement de base de données Azure est ouvert pour la production.
SQL Server AlwaysOn
Comme Always On est pris en charge pour les systèmes SAP locaux (voir la note SAP #1772688), il est pris en charge en association avec SAP dans Azure. Vous devez être particulièrement attentif quand vous déployez l’écouteur de groupe de disponibilité SQL Server (à ne pas confondre avec le groupe à haute disponibilité Azure). Certaines étapes d’installation différentes sont nécessaires.
Lors de l’utilisation de l’écouteur de groupe de disponibilité, tenez compte des considérations suivantes :
- L’utilisation de l’écouteur de groupe de disponibilité n’est possible que sur un système Windows Server 2012 ou version ultérieure, utilisé en tant que SE invité de la machine virtuelle. Pour Windows Server 2012, vérifiez que la mise à jour permettant d’activer les écouteurs de groupe de disponibilité SQL Server sur Windows Server 2008 R2 et les machines virtuelles Microsoft Azure basées sur Windows Server 2012 a été appliquée.
- Pour Windows Server 2008 R2, ce correctif n’existe pas. Dans ce cas, Always On doit être utilisé de la même manière que la mise en miroir de bases de données. En spécifiant un partenaire de basculement dans la chaîne de connexion (avec le paramètre SAP default.pfl dbs/mss/server - voir la note SAP #965908).
- Quand vous utilisez un écouteur de groupe de disponibilité, vous devez connecter les machines virtuelles de base de données à un équilibreur de charge dédié. Vous devez attribuer des adresses IP statiques aux interfaces réseau des machines au sein de la configuration Always On (la définition d’une adresse IP statique est décrite dans cet article). Les adresses IP statiques comparées à DHCP empêchent l’attribution de nouvelles adresses IP si les deux machines virtuelles sont arrêtées.
- La création d’une configuration de cluster WSFC requiert certaines étapes spécifiques lorsque ce cluster doit se voir affecter une adresse IP spécifique, car la fonctionnalité actuelle d’Azure affecte au nom du cluster la même adresse IP que celle du nœud sur lequel le cluster est créé. Ce comportement signifie que l’attribution d’une adresse IP différente au cluster doit faire l’objet d’une étape manuelle.
- L’écouteur de groupe de disponibilité va être créé dans Azure avec les points de terminaison TCP/IP qui sont affectés aux machines virtuelles exécutant les réplicas principaux et secondaires du groupe de disponibilité.
- Il peut être nécessaire de sécuriser ces points de terminaison avec des ACL.
Documentation détaillée sur le déploiement de la solution Always On avec SQL Server sur des machines virtuelles Azure :
- Présentation des groupes de disponibilité SQL Server Always On sur des machines virtuelles Azure
- Configurer un groupe de disponibilité Always On sur des machines virtuelles Azure dans des régions différentes
- Configurer un équilibreur de charge pour un groupe de disponibilité Always On dans Azure
- Bonnes pratiques de configuration de la HADR (SQL Server sur des machines virtuelles Azure)
Notes
En lisant la présentation des groupes de disponibilité SQL Server Always On sur des machines virtuelles Azure, vous allez découvrir l’écouteur DNN (Direct Network Name) de SQL Server. Cette nouvelle fonctionnalité a été introduite avec SQL Server 2019 CU8. Cette nouvelle fonctionnalité permet d’utiliser un équilibreur de charge Azure qui gère l’adresse IP virtuelle de l’écouteur de groupe de disponibilité obsolète.
SQL Server Always On est la fonctionnalité de récupération d’urgence et haute disponibilité la plus couramment utilisée dans Azure pour les déploiements de charge de travail SAP. La plupart des clients utilisent Always On pour la haute disponibilité au sein d’une seule région Azure. Si le déploiement est limité à deux nœuds uniquement, vous avez deux possibilités pour la connectivité :
- Utilisation de l’écouteur de groupe de disponibilité. Avec l’écouteur de groupe de disponibilité, vous devez déployer un équilibreur de charge Azure.
- Avec SQL Server 2016 SP3, SQL Server 2017 CU 25 ou SQL Server 2019 CU8, ou des versions plus récentes de SQL Server sur Windows Server 2016 ou version ultérieure, vous pouvez utiliser l’écouteur DNN (Direct Network Name) à la place d’un équilibreur de charge Azure. Un DNN élimine la nécessité d’utiliser un équilibreur de charge Azure.
L’utilisation des paramètres de connectivité de la mise en miroir de bases de données SQL Server doit être envisagée seulement pour investiguer les problèmes liés aux deux autres méthodes. Dans ce cas, vous devez configurer la connectivité des applications SAP d’une manière où les deux noms de nœud sont désignés. Les détails précis de cette configuration côté SAP sont documentés dans la note SAP n°965908. Si vous utilisez cette option, vous n’avez pas besoin de configurer un écouteur de groupe de disponibilité Sans équilibreur de charge Azure, vous pouvez investiguer les problèmes de ces composants. Cependant, souvenez-vous que cette option fonctionne uniquement si vous limitez votre groupe de disponibilité pour couvrir deux instances.
Certains clients utilisent la fonctionnalité SQL Server Always On pour la reprise d’activité entre régions Azure. Plusieurs clients utilisent également la possibilité d’effectuer des sauvegardes à partir d’un réplica secondaire.
SQL Server Transparent Data Encryption
De nombreux clients utilisent Transparent Data Encryption (TDE) sur SQL Server quand ils déploient leurs bases de données SQL Server SAP sur Azure. La fonctionnalité SQL Server TDE est entièrement prise en charge par SAP (voir la note SAP n°1380493).
Application de SQL Server TDE
Dans les cas où vous effectuez une migration hétérogène à partir d’un autre système de base de données, qui s’exécute localement, vers Windows/SQL Server exécuté dans Azure, vous devez créer votre base de données cible vide dans SQL Server à l’avance. Ensuite, vous appliquez la fonctionnalité SQL Server TDE sur cette base de données vide. La raison pour laquelle vous souhaitez effectuer cette procédure dans cette séquence est que le processus de chiffrement de la base de données vide peut prendre beaucoup de temps. Les processus d’importation SAP importent ensuite les données dans la base de données chiffrée pendant la phase de temps d’arrêt. Le traitement de l’importation dans une base de données chiffrée a un impact sur le temps plus faible que le chiffrement de la base de données après la phase d’exportation au cours du temps d’arrêt. Des expériences ont été négatives lors de la tentative d’application du chiffrement TDE avec charge de travail SAP exécutée sur la base de données. Nous vous recommandons donc de traiter le déploiement de TDE comme une activité devant être effectuée avec une charge de travail SAP faible ou nulle sur la base de données particulière. À partir de SQL Server 2016, vous pouvez arrêter et reprendre l’analyse TDE qui effectue le chiffrement initial. Le document Transparent Data Encryption (TDE) décrit la commande et les détails.
Dans les cas où vous déplacez des bases de données SQL Server SAP d’un environnement local vers Azure, il est recommandé de vérifier sur quelle infrastructure vous pouvez obtenir le plus rapidement le chiffrement appliqué. Dans ce cas, gardez ces faits à l’esprit :
- Vous ne pouvez pas définir le nombre de threads utilisés pour appliquer le chiffrement de données à la base de données. Le nombre de threads dépend principalement du nombre de volumes de disque sur lesquels les fichiers journaux et les fichiers de données SQL Server sont distribués. Cela signifie que plus les volumes sont distincts (lettres de lecteur), plus les threads sont engagés en parallèle pour effectuer le chiffrement. Une telle configuration est en légère contradiction avec la suggestion de configuration de disque indiquée plus haut, préconisant la création d’un ou de quelques espaces de stockage pour les fichiers de base de données SQL Server sur des machines virtuelles Azure. Une configuration avec peu de volumes entraînerait l’exécution du chiffrement par peu de threads. Un chiffrement à un seul thread lit les étendues de 64 ko, les chiffre, puis écrit un enregistrement dans le fichier journal de transactions, ce qui indique que l’étendue a été chiffrée. Par conséquent, la charge sur le journal des transactions est modérée.
- Dans les versions antérieures de SQL Server, la compression de sauvegarde n’était plus efficace lorsque vous aviez chiffré votre base de données SQL Server. Ce comportement pouvait se transformer en problème si vous envisagiez de chiffrer votre base de données SQL Server en local, puis de copier une sauvegarde dans Azure pour restaurer la base de données dans Azure. La compression de sauvegarde SQL Server permet d’obtenir un taux de compression de facteur 4.
- SQL Server 2016 introduit de nouvelles fonctionnalités qui permettent de compresser la sauvegarde des bases de données chiffrées de manière efficace. Pour plus d’informations, consultez ce blog.
Utilisation d’Azure Key Vault
Azure propose le service Key Vault pour stocker les clés de chiffrement. Parallèlement, SQL Server propose un connecteur pour utiliser Azure Key Vault comme magasin pour les certificats TDE.
Vous trouverez plus d’informations sur l’utilisation d’Azure Key Vault pour SQL Server TDE dans les articles suivants :
- Configurer l’intégration d’Azure Key Vault pour SQL Server sur des machines virtuelles (Resource Manager).
- More Questions From Customers About SQL Server Transparent Data Encryption – TDE + Azure Key Vault (Autres questions de clients sur SQL Server TDE et Azure Key Vault)
Important
Quand vous utilisez SQL Server TDE, notamment avec Azure Key Vault, nous vous recommandons d’utiliser les derniers correctifs de SQL Server 2014, SQL Server 2016 et SQL Server 2017. En effet, des optimisations et correctifs ont été appliqués au code suite aux commentaires de clients. À titre d’exemple, consultez l’article de la Base de connaissances KBA n°4058175.
Configurations de déploiement minimales
Dans cette section, nous vous suggérons un ensemble de configurations minimales pour différentes tailles de bases de données sous la charge de travail SAP. Il est trop difficile d’évaluer si ces tailles correspondent à votre charge de travail spécifique. Dans certains cas, nous pouvons être généreux en mémoire par rapport à la taille de la base de données. De l’autre côté, le dimensionnement du disque peut être trop faible pour certaines charges de travail. Par conséquent, ces configurations doivent être traitées pour ce qu’elles sont. Ce sont des configurations qui doivent vous donner un point de départ. Configurations à ajuster selon votre charge de travail spécifique et vos exigences de rentabilité.
Voici un exemple de configuration pour une petite instance SQL Server avec une taille de base de données entre 50 Go et 250 Go :
| Configuration | Machine virtuelle de base de données | Commentaires |
|---|---|---|
| Type de machine virtuelle | E4s_v3/v4/v5 (4 vCPU/32 Gio RAM) | |
| Mise en réseau accélérée | Activer | |
| Version de SQL Server | SQL Server 2019 ou plus récent | |
| Nb de fichiers de données | 4 | |
| Nb de fichiers journaux | 1 | |
| Nb de fichiers de données temp | 4 ou valeur par défaut à partir de SQL Server 2016 | |
| Système d’exploitation | Windows Server 2019 ou plus récent | |
| Agrégation de disques | Espaces de stockage si vous le souhaitez | |
| Système de fichiers | NTFS | |
| Taille de bloc de format | 64 Ko | |
| Nombre et type de disques de données | Stockage Premium v1 : 2 x P10 (RAID0) Stockage Premium v2 : 2 x 150 Gio (RAID0) – IOPS et débit par défaut ou SSD Premium v2 équivalent |
Cache = Lecture seule pour le stockage Premium v1 |
| Nombre et type de disques de données | Stockage Premium v1 : 1 x P20 Stockage Premium v2 : 1 x 128 Gio – IOPS et débit par défaut ou SSD Premium v2 équivalent |
Cache = AUCUN |
| Paramètre de mémoire maximale SQL Server | 90 % de RAM physique | En supposant une instance unique |
Voici un exemple de configuration pour une petite instance SQL Server avec une taille de base de données entre 250 Go et 750 Go, comme un petit système SAP Business Suite :
| Configuration | Machine virtuelle de base de données | Commentaires |
|---|---|---|
| Type de machine virtuelle | E16s_v3/v4/v5 (16 vCPU/128 Gio RAM) | |
| Mise en réseau accélérée | Activer | |
| Version de SQL Server | SQL Server 2019 ou plus récent | |
| Nb de fichiers de données | 8 | |
| Nb de fichiers journaux | 1 | |
| Nb de fichiers de données temp | 8 ou valeur par défaut à partir de SQL Server 2016 | |
| Système d’exploitation | Windows Server 2019 ou plus récent | |
| Agrégation de disques | Espaces de stockage si vous le souhaitez | |
| Système de fichiers | NTFS | |
| Taille de bloc de format | 64 Ko | |
| Nombre et type de disques de données | Stockage Premium v1 : 4 x P20 (RAID0) Stockage Premium v2 : 4 x 100 Gio – 200 Gio (RAID0) – IOPS par défaut et débit supplémentaire de 25 Mo/s par disque ou SSD Premium v2 équivalent |
Cache = Lecture seule pour le stockage Premium v1 |
| Nombre et type de disques de données | Stockage Premium v1 : 1 x P20 Stockage Premium v2 : 1 x 200 Gio – IOPS et débit par défaut ou SSD Premium v2 équivalent |
Cache = AUCUN |
| Paramètre de mémoire maximale SQL Server | 90 % de RAM physique | En supposant une instance unique |
Voici un exemple de configuration pour une instance SQL Server moyenne avec une taille de base de données entre 750 Go et 2 000 Go, comme un système SAP Business Suite moyen :
| Configuration | Machine virtuelle de base de données | Commentaires |
|---|---|---|
| Type de machine virtuelle | E64s_v3/v4/v5 (64 vCPU/432 Gio RAM) | |
| Mise en réseau accélérée | Activer | |
| Version de SQL Server | SQL Server 2019 ou plus récent | |
| Nombre d’unités de données | 16 | |
| Nombre d’unités de journaux | 1 | |
| Nb de fichiers de données temp | 8 ou valeur par défaut à partir de SQL Server 2016 | |
| Système d’exploitation | Windows Server 2019 ou plus récent | |
| Agrégation de disques | Espaces de stockage si vous le souhaitez | |
| Système de fichiers | NTFS | |
| Taille de bloc de format | 64 Ko | |
| Nombre et type de disques de données | Stockage Premium v1 : 4 x P30 (RAID0) Stockage Premium v2 : 4 x 250 Gio – 500 Gio – plus 2 000 IOPS et 75 Mo/sec de débit par disque ou SSD Premium v2 équivalent |
Cache = Lecture seule pour le stockage Premium v1 |
| Nombre et type de disques de données | Stockage Premium v1 : 1 x P20 Stockage Premium v2 : 1 x 400 Gio – IOPS par défaut et 75 Mo/sec de débit supplémentaire ou SSD Premium v2 équivalent |
Cache = AUCUN |
| Paramètre de mémoire maximale SQL Server | 90 % de RAM physique | En supposant une instance unique |
Voici un exemple de configuration pour une grande instance SQL Server avec une taille de base de données entre 2 000 Go et 4 000 Go, comme un système SAP Business Suite plus grand :
| Configuration | Machine virtuelle de base de données | Commentaires |
|---|---|---|
| Type de machine virtuelle | E96(d)s_v5 (96 vCPU/672 Gio RAM) | |
| Mise en réseau accélérée | Activer | |
| Version de SQL Server | SQL Server 2019 ou plus récent | |
| Nombre d’unités de données | 24 | |
| Nombre d’unités de journaux | 1 | |
| Nb de fichiers de données temp | 8 ou valeur par défaut à partir de SQL Server 2016 | |
| Système d’exploitation | Windows Server 2019 ou plus récent | |
| Agrégation de disques | Espaces de stockage si vous le souhaitez | |
| Système de fichiers | NTFS | |
| Taille de bloc de format | 64 Ko | |
| Nombre et type de disques de données | Stockage Premium v1 : 4 x P30 (RAID0) Stockage Premium v2 : 4 x 500 Gio – 800 Gio – plus 2500 IOPS et 100 Mo/sec de débit par disque ou SSD Premium v2 équivalent |
Cache = Lecture seule pour le stockage Premium v1 |
| Nombre et type de disques de données | Stockage Premium v1 : 1 x P20 Stockage Premium v2 : 1 x 400 Gio – plus 1000 IOPS et 75 Mo/sec de débit supplémentaire ou SSD Premium v2 équivalent |
Cache = AUCUN |
| Paramètre de mémoire maximale SQL Server | 90 % de RAM physique | En supposant une instance unique |
Voici un exemple de configuration pour une grande instance SQL Server avec une taille de base de données de plus de 4 To, comme un grand système SAP Business Suite utilisé de manière globale :
| Configuration | Machine virtuelle de base de données | Commentaires |
|---|---|---|
| Type de machine virtuelle | Série M (1,0 à 4,0 To de RAM) | |
| Mise en réseau accélérée | Activer | |
| Version de SQL Server | SQL Server 2019 ou plus récent | |
| Nombre d’unités de données | 32 | |
| Nombre d’unités de journaux | 1 | |
| Nb de fichiers de données temp | 8 ou valeur par défaut à partir de SQL Server 2016 | |
| Système d’exploitation | Windows Server 2019 ou plus récent | |
| Agrégation de disques | Espaces de stockage si vous le souhaitez | |
| Système de fichiers | NTFS | |
| Taille de bloc de format | 64 Ko | |
| Nombre et type de disques de données | Stockage Premium v1 : 4+ x P40 (RAID0) Stockage Premium v2 : 4 x 1000 Gio – 4000 Gio – plus 4500 IOPS et 125 Mo/sec de débit par disque ou SSD Premium v2 équivalent |
Cache = Lecture seule pour le stockage Premium v1 |
| Nombre et type de disques de données | Stockage Premium v1 : 1 x P30 Stockage Premium v2 : 1 x 500 Gio – plus 2000 IOPS et 125 Mo/sec de débit ou SSD Premium v2 équivalent |
Cache = AUCUN |
| Paramètre de mémoire maximale SQL Server | 90 % de RAM physique | En supposant une instance unique |
Par exemple, cette configuration est celle de la machine virtuelle de base de données d’une instance SAP Business Suite sur SQL Server. Cette machine virtuelle héberge la base de données de 30 To de la seule instance SAP Business Suite globale d’une entreprise internationale avec un chiffre d’affaires annuel de plus de 200 milliards de dollars et plus de 200 000 employés à temps plein. Le système exécute tous les processus de traitement financier, de vente et de distribution, ainsi que bien d’autres processus métier dans différents domaines, notamment les fiches de paie de la zone Amérique du Nord. Le système s’exécute dans Azure depuis début 2018 avec des machines virtuelles Azure de la série M comme machines virtuelles de base de données. Pour la haute disponibilité, le système utilise Always On avec un réplica synchrone dans une autre zone de disponibilité de la même région Azure. Et un autre réplica asynchrone dans une autre région Azure. La couche d’application NetWeaver est déployée sur les dernières familles de machines virtuelles D(a)/E(a).
| Configuration | Machine virtuelle de base de données | Commentaires |
|---|---|---|
| Type de machine virtuelle | M192dms_v2 (192 vCPU/4 196 Gio RAM) | |
| Mise en réseau accélérée | activé | |
| Version de SQL Server | SQL Server 2019 | |
| Nb de fichiers de données | 32 | |
| Nb de fichiers journaux | 1 | |
| Nb de fichiers de données temp | 8 | |
| Système d’exploitation | Windows Server 2019 | |
| Agrégation de disques | Espaces de stockage | |
| Système de fichiers | NTFS | |
| Taille de bloc de format | 64 Ko | |
| Nombre et type de disques de données | Stockage Premium v1 : 16 x P40 ou SSD Premium v2 équivalent | Cache = Lecture seule |
| Nombre et type de disques de données | Stockage Premium v1 : 1 x P60 ou SSD Premium v2 équivalent | Utilisation de l’accélérateur d’écriture |
| Nb et type de disques tempdb | Stockage Premium v1 : 1 x P30 ou SSD Premium v2 équivalent | Aucune mise en cache |
| Paramètre de mémoire maximale SQL Server | 90 % de RAM physique |
Résumé général : SQL Server pour SAP dans Azure
Ce guide offre de nombreuses recommandations. Nous vous invitons à les parcourir plusieurs fois avant de planifier votre déploiement Azure. Cependant, de manière générale, vous devez suivre les principales recommandations générales propres à SQL Server sur Azure :
- Utilisez la dernière version de SQLServer, comme SQL Server 2022, qui présente les avantages les plus intéressants dans Azure.
- Planifiez avec soin votre paysage de système SAP dans Azure, afin de trouver l’équilibre entre la disposition des fichiers de données et les restrictions d’Azure :
- Évitez d’utiliser un trop grand nombre de disques. Cependant, vous devez en configurer suffisamment pour atteindre le nombre d’E/S par seconde nécessaire.
- N’effectuez une agrégation par bandes que si vous devez obtenir un débit supérieur.
- Évitez d’utiliser un trop grand nombre de disques. Cependant, vous devez en configurer suffisamment pour atteindre le nombre d’E/S par seconde nécessaire.
- N’installez jamais de logiciels et ne placez jamais de fichiers nécessitant une persistance sur le lecteur D:\, car il n’est pas permanent. Tout ce qui se trouve sur ce lecteur risque d’être perdu lors d’un redémarrage de Windows ou de la machine virtuelle.
- Utilisez votre solution Always On SQL Server pour répliquer les données de base de données.
- Utilisez toujours la fonction de résolution de noms ; ne vous fiez pas aux adresses IP.
- À l’aide de SQL Server TDE, appliquez les derniers correctifs de SQL Server.
- Veillez à recourir à des images SQL Server de Microsoft Azure Marketplace. Si vous utilisez le serveur SQL numéro un, vous devez modifier le classement de l’instance avant d’installer un système SAP NetWeaver sur ce serveur.
- Installez et configurez la surveillance d'hôte SAP pour Azure comme décrit dans le Guide de déploiement.
Étapes suivantes
Lire l’article