Publier des pipelines de Machine Learning
S’APPLIQUE À :  SDK Python azureml v1
SDK Python azureml v1
Cet article vous explique comment partager un pipeline Machine Learning avec vos collègues ou vos clients.
Les pipelines Machine Learning sont des flux de travail réutilisables pour les tâches de Machine Learning. L’un des avantages des pipelines est une collaboration accrue. Vous pouvez également créer des versions du pipeline, ce qui permet aux clients d’utiliser le modèle actuel pendant que vous travaillez sur une nouvelle version.
Prérequis
Créer un espace de travail Azure Machine Learning afin de contenir toutes les ressources de votre pipeline
Configurer votre environnement de développement pour installer le SDK Azure Machine Learning ou utilisez une instance de calcul Azure Machine Learning avec le SDK déjà installé
Créez et exécutez un pipeline Machine Learning, par exemple en suivant le Tutoriel : Créer un pipeline Azure Machine Learning pour le scoring par lots. Pour d’autres options, consultez Créer et exécuter des pipelines Machine Learning avec le kit SDK Azure Machine Learning
Publier un pipeline
Une fois que vous disposez d’un pipeline opérationnel, vous pouvez publier un pipeline pour qu’il s’exécute avec des entrées différentes. Pour que le point de terminaison REST d’un pipeline déjà publié accepte des paramètres, vous devez configurer votre pipeline afin d’utiliser des objets PipelineParameter pour les arguments qui varient.
Pour créer un paramètre de pipeline, utilisez un objet PipelineParameter avec une valeur par défaut.
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Ajoutez cet objet
PipelineParameteren tant que paramètre de l’une des étapes du pipeline comme suit :compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Publiez ce pipeline. Il acceptera un paramètre en cas d’appel.
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")Après avoir publié votre pipeline, vous pouvez l’archiver dans l’interface utilisateur. L’ID de pipeline est l’unique identifié du pipeline publié.


Exécuter un pipeline publié
Tous les pipelines publiés disposent d’un point de terminaison REST. Avec le point de terminaison de pipeline, vous pouvez déclencher une exécution du pipeline à partir de n’importe quel système externe, notamment des clients autres que Python. Ce point de terminaison active la « répétabilité managée » dans les scénarios de scoring et de nouvel apprentissage.
Important
Si vous utilisez le contrôle d’accès en fonction du rôle Azure (RBAC Azure) pour gérer l’accès à votre pipeline, définissez les autorisations de votre scénario de pipeline (entraînement ou scoring).
Pour appeler l’exécution du pipeline précédent, vous avez besoin d’un jeton d’en-tête d’authentification Microsoft Entra. L’obtention de ce jeton est décrite dans les informations de référence sur la classe AzureCliAuthentication et dans le notebook Authentification dans Azure Machine Learning.
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
L’argument json de la requête POST doit contenir, pour la clé ParameterAssignments, un dictionnaire contenant les paramètres de pipeline et leurs valeurs. En outre, l’argument json peut contenir les clés suivantes :
| Clé | Description |
|---|---|
ExperimentName |
Nom de l’expérience associée à ce point de terminaison |
Description |
Texte libre décrivant le point de terminaison |
Tags |
Paires clé-valeur de forme libre utilisables pour étiqueter et annoter des demandes |
DataSetDefinitionValueAssignments |
Dictionnaire utilisé pour modifier des jeux de données sans nouvel apprentissage (voir la discussion ci-dessous) |
DataPathAssignments |
Dictionnaire utilisé pour modifier des chemins de données sans nouvel apprentissage (voir la discussion ci-dessous) |
Exécuter un pipeline publié à l’aide de C#
Le code suivant montre comment appeler un pipeline de manière asynchrone à partir de C#. L’extrait de code partiel montre simplement la structure d’appel et ne fait pas partie d’un exemple Microsoft. Il n’affiche pas les classes complètes ou la gestion des erreurs.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Exécuter un pipeline publié à l’aide de Java
Le code suivant illustre un appel à un pipeline qui requiert une authentification (consultez Configurer l’authentification pour des ressources et workflows Azure Machine Learning). Si votre pipeline est déployé publiquement, vous n’avez pas besoin des appels qui produisent authKey. L’extrait de code partiel n’indique pas la classe Java et le texte de gestion des exceptions. Le code utilise Optional.flatMap pour le chaînage des fonctions qui peuvent retourner une valeur Optionalvide. L’utilisation de flatMap raccourcit et clarifie le code, mais notez que getRequestBody() ingère les exceptions.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token);;
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Modification de jeux de données et de chemins de données sans nouvel apprentissage
Vous pouvez effectuer l’apprentissage et l’inférence sur différents jeux de données et chemins de données. Par exemple, vous pouvez effectuer l’apprentissage sur un jeu de données plus petit, mais l’inférence sur le jeu de données complet. Vous basculez les jeux de données avec la clé DataSetDefinitionValueAssignments dans l’argument json de la demande. Vous basculez les chemins de données avec DataPathAssignments. La technique pour les deux est similaire :
Dans le script de définition de votre pipeline, créez un
PipelineParameterpour le jeu de données. Créez uneDatasetConsumptionConfigou unDataPathà partir duPipelineParameter:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)Dans votre script ML, accédez au jeu de données spécifié dynamiquement en utilisant
Run.get_context().input_datasets:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc ...Notez que le script ML accède à la valeur spécifiée pour la
DatasetConsumptionConfig(tabular_dataset), non à la valeur duPipelineParameter(tabular_ds_param).Dans le script de définition de votre pipeline, définissez la
DatasetConsumptionConfigen tant que paramètre pourPipelineScriptStep:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])Pour basculer des jeux de données de façon dynamique dans votre appel REST d’inférence, utilisez
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
Les blocs-notes Présentation de jeu de données et PipelineParameter et Présentation de chemin de données et PipelineParameter contiennent des exemples complets de cette technique.
Créer un point de terminaison de pipeline en versions gérées
Vous pouvez créer un point de terminaison de pipeline avec plusieurs pipelines publiés derrière. Cette technique vous procure un point de terminaison REST au moment de l’itération et de la mise à jour de vos pipelines Machine Learning.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Soumettre un travail à un point de terminaison de pipeline
Vous pouvez soumettre un travail à la version par défaut d’un point de terminaison de pipeline :
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
Vous pouvez également envoyer un travail à une version spécifique :
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
La restauration peut être effectuée à l’aide de l’API REST :
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Utiliser des pipelines publiés dans le studio
Vous pouvez également exécuter un pipeline publié à partir du studio :
Connectez-vous à Azure Machine Learning Studio.
Sur la gauche, sélectionnez Points de terminaison.
En haut, sélectionnez Points de terminaison de pipeline.
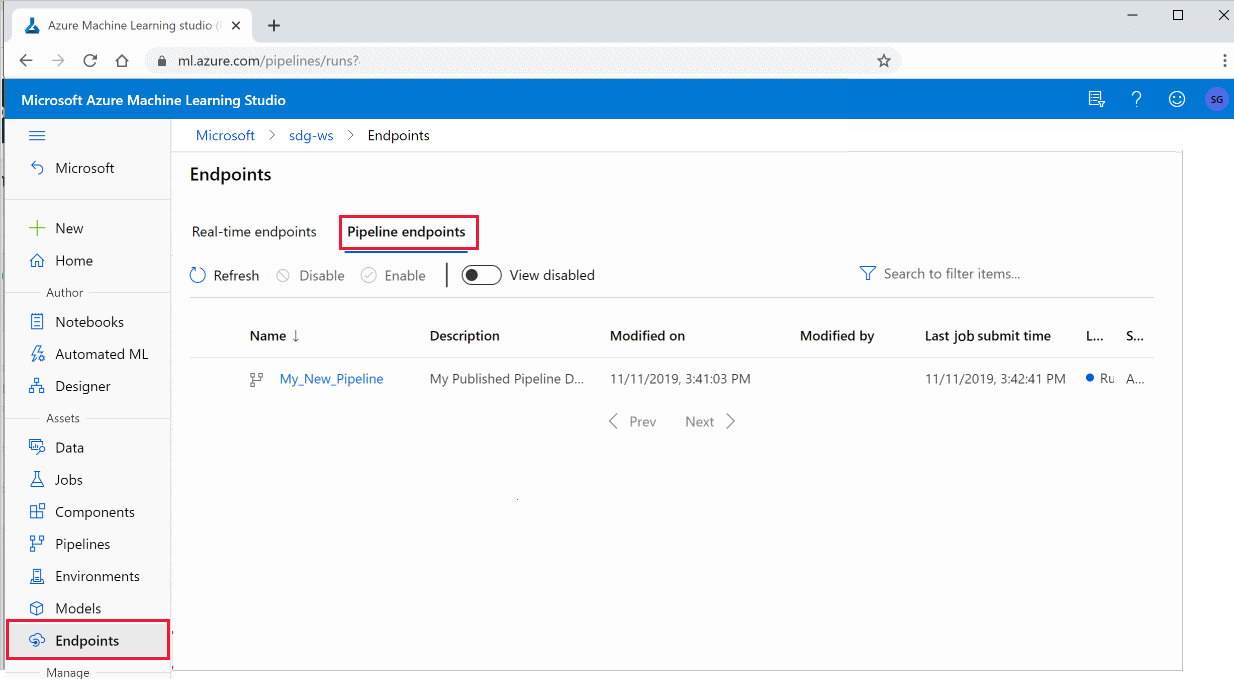
Sélectionnez un pipeline spécifique pour exécuter, utiliser ou examiner les résultats des exécutions précédentes du point de terminaison du pipeline.
Désactiver un pipeline publié
Pour masquer un pipeline de votre liste de pipelines publiés, vous le désactivez soit dans le studio, soit à partir du SDK :
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
Vous pouvez le réactiver avec p.enable(). Pour plus d’informations, consultez la référence de la classe PublishedPipeline.
Étapes suivantes
- Utilisez ces blocs-notes Jupyter sur GitHub pour explorer plus en détail les pipelines Machine Learning.
- Consultez l’aide relative à la référence SDK des packages azureml-pipelines-core et azureml-pipelines-steps.
- Consultez le guide pratique pour obtenir des conseils sur le débogage et la résolution des problèmes de pipelines.