Résolution des problèmes de pipeline Machine Learning
S’APPLIQUE À :  SDK Python azureml v1
SDK Python azureml v1
Dans cet article, vous allez apprendre à résoudre les problèmes lorsque vous obtenez des erreurs lors de l’exécution d’un pipeline Machine Learning dans Azure Machine Learning SDK et Azure machine learning designer.
Conseils de dépannage
Le tableau suivant présente les problèmes courants qui se produisent pendant le développement de pipelines ainsi que les solutions possibles.
| Problème | Solution possible |
|---|---|
Impossible de transmettre les données au répertoire PipelineData |
Vérifiez que vous avez créé un répertoire dans le script qui correspond à l’emplacement où votre pipeline attend les données de sortie de l’étape. Dans la plupart des cas, un argument d’entrée définit le répertoire de sortie, puis vous créez le répertoire explicitement. Utilisez os.makedirs(args.output_dir, exist_ok=True) pour créer le répertoire de sortie. Pour obtenir un exemple de script de scoring qui illustre ce modèle de conception, consultez ce tutoriel. |
| Bogues de dépendance | Si vous constatez dans votre pipeline distant des erreurs de dépendance qui ne se sont pas produites lors des tests en local, vérifiez que vos dépendances d’environnement distant et les versions correspondent à celles de votre environnement de test. (Voir Création, mise en cache et réutilisation d’environnement) |
| Erreurs ambiguës liées aux cibles de calcul | Essayez de supprimer et recréer les cibles de calcul. La recréation de cibles de calcul est rapide et peut résoudre certains problèmes temporaires. |
| Le pipeline ne réutilise pas les étapes | La réutilisation d’étape est activée par défaut, mais vérifiez que vous ne l’avez pas désactivée dans une étape du pipeline. Si la réutilisation est désactivée, le paramètre allow_reuse de l’étape est défini sur False. |
| Le pipeline se réexécute inutilement | Pour faire en sorte que les étapes ne se réexécutent que lorsque leurs données ou scripts sous-jacents changent, découplez les répertoires de votre code source pour chaque étape. Si vous utilisez le même répertoire source pour plusieurs étapes, des réexécutions inutiles peuvent se produire. Utilisez le paramètre source_directory sur un objet d’étape de pipeline pour pointer vers votre répertoire isolé pour cette étape, et vérifiez que vous n’utilisez pas le même chemin source_directory pour plusieurs étapes. |
| Étape ralentissant les époques d’apprentissage ou tout autre comportement de bouclage | Essayez de faire basculer les écritures de fichier, notamment a journalisation, de as_mount() à as_upload(). Le mode montage utilise un système de fichiers virtualisé distant et charge l’intégralité du fichier chaque fois qu’il y est ajouté. |
| Le démarrage de la cible de calcul prend beaucoup de temps | Les images Docker pour les cibles de calcul sont chargées à partir d’Azure Container Registry (ACR). Par défaut, Azure Machine Learning crée un ACR qui utilise le niveau de service De base. Un passage au niveau Standard ou Premium du registre ACR de l’espace de travail est susceptible de réduire le temps nécessaire à la génération et au chargement des images. Pour plus d’informations, consultez Niveaux de service pour Azure Container Registry. |
Erreurs d’authentification
Si vous effectuez une opération de gestion sur une cible de calcul à partir d'un travail distant, vous recevez l'une des erreurs suivantes :
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
Par exemple, vous recevez une erreur si vous essayez de créer ou de joindre une cible de calcul à partir d'un pipeline ML soumis en vue d'une exécution à distance.
Résolution des problèmes ParallelRunStep
Le script d'une étape ParallelRunStep doit contenir deux fonctions :
init(): utilisez cette fonction pour toute préparation coûteuse ou courante à une prochaine inférence. Par exemple, utilisez-la pour charger le modèle dans un objet global. Cette fonction est appelée une seule fois au début du processus.run(mini_batch): Cette fonction s’exécute pour chaque instance demini_batch.mini_batch:ParallelRunStepappelle une méthode d’exécution, et passe à la méthode une liste ou un pandasDataFrameen tant qu’argument. Chaque entrée dans mini_batch est un chemin de fichier si l’entrée est unFileDataset, ou un pandasDataFramesi l’entrée est unTabularDataset.response: la méthode run() doit retourner unDataFramePandas ou un tableau. Pour append_row output_action, les éléments retournés sont ajoutés au fichier de sortie commun. Pour summary_only, le contenu des éléments est ignoré. Pour toutes les actions de sortie, chaque élément de sortie retourné indique la réussite de l’exécution d’une entrée dans le mini-lot d’entrée. Vérifiez que suffisamment de données sont incluses dans le résultat de l’exécution pour mapper l’entrée au résultat de la sortie de l’exécution. La sortie de l’exécution est écrite dans un fichier de sortie, mais pas nécessairement dans l’ordre. Vous devez utiliser une clé dans la sortie pour la mapper à l’entrée.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Si vous avez un autre fichier ou dossier dans le même répertoire que votre script d’inférence, vous pouvez le référencer en recherchant le répertoire de travail actuel.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
Paramètres de ParallelRunConfig
ParallelRunConfig est la configuration principale de l’instance ParallelRunStep dans le pipeline Azure Machine Learning. Elle permet de wrapper votre script et de configurer les paramètres nécessaires, dont toutes les entrées suivantes :
entry_script: Script utilisateur utilisé comme un chemin de fichier local qui est exécuté en parallèle sur plusieurs nœuds. Sisource_directoryest présent, utilisez un chemin relatif. Dans le cas contraire, utilisez un chemin accessible sur la machine.mini_batch_size: taille du mini-lot passé à un appelrun()unique (Facultatif ; la valeur par défaut est10fichiers pourFileDatasetet1MBpourTabularDataset.)- Pour
FileDataset, il s’agit du nombre de fichiers avec une valeur minimale de1. Vous pouvez combiner plusieurs fichiers dans un mini-lot. - Pour
TabularDataset, il s’agit de la taille des données. Par exemple, il peut s’agir des valeurs1024,1024KB,10MBou1GB.1MBest la valeur recommandée. Le mini-lot deTabularDatasetne franchira jamais les limites du fichier. Par exemple, si vous avez des fichiers .csv de différentes tailles, le plus petit fichier aura une taille de 100 Ko et le plus grand une taille de 10 Mo. Si vous définissezmini_batch_size = 1MB, les fichiers dont la taille est inférieure à 1 Mo sont traités ensemble en un mini-lot. Les fichiers dont la taille est supérieure à 1 Mo sont fractionnés en plusieurs mini-lots.
- Pour
error_threshold: nombre d’échecs d’enregistrement pourTabularDatasetet d’échecs de fichiers pourFileDatasetqui doivent être ignorés pendant le traitement. Si le nombre d’erreurs de la totalité de l’entrée dépasse cette valeur, le travail est abandonné. Le seuil d’erreur concerne la totalité de l’entrée et non le mini-lot envoyé à la méthoderun(). La plage est la suivante :[-1, int.max]. La partie-1indique qu’il faut ignorer tous les échecs au cours du traitement.output_action: L’une des valeurs suivantes indique comment la sortie est organisée :summary_only: Le script utilisateur stocke la sortie.ParallelRunSteputilise la sortie uniquement pour le calcul du seuil d’erreurs.append_row: Pour toutes les entrées, un seul fichier est créé dans le dossier de sortie dans lequel sont ajoutées toutes les sorties séparées par une ligne.
append_row_file_name: permet de personnaliser le nom du fichier de sortie pour append_row output_action (facultatif ; la valeur par défaut estparallel_run_step.txt).source_directory: chemins des dossiers qui contiennent tous les fichiers à exécuter sur la cible de calcul (facultatif).compute_target: SeulAmlComputeest pris en charge.node_count: nombre de nœuds de calcul à utiliser pour l’exécution du script utilisateur.process_count_per_node: nombre de processus par nœud. La bonne pratique consiste à définir la valeur sur le nombre de GPU ou d’UC dont dispose un nœud (facultatif ; la valeur par défaut est1).environment: définition de l’environnement Python. Vous pouvez la configurer de manière à utiliser un environnement Python existant ou un environnement temporaire. La définition est également chargée de définir les dépendances d’application nécessaires (facultatif).logging_level: Verbosité du journal. Les valeurs permettant d’augmenter le niveau de verbosité sont les suivantes :WARNING,INFOetDEBUG. (Facultatif ; la valeur par défaut estINFO.)run_invocation_timeout: délai d’attente de l’appel de la méthoderun(), en secondes. (Facultatif ; la valeur par défaut est60.)run_max_try: nombre maximal de tentatives derun()pour un mini-lot.run()a échoué si une exception est levée, ou si rien n’est retourné lorsquerun_invocation_timeoutest atteint (facultatif ; la valeur par défaut est3).
Vous pouvez spécifier mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout et run_max_try en tant que PipelineParameter ; ainsi, lorsque vous soumettez à nouveau une exécution de pipeline, vous pouvez ajuster les valeurs des paramètres. Dans cet exemple, vous utilisez PipelineParameter pour mini_batch_size et Process_count_per_node, et vous changez ces valeurs quand vous soumettez à nouveau une exécution ultérieurement.
Paramètres de création de l'étape ParallelRunStep
Créez ParallelRunStep à l’aide du script, de la configuration de l’environnement et des paramètres. Spécifiez la cible de calcul que vous avez déjà jointe à votre espace de travail en tant que cible d’exécution de votre script d’inférence. Utilisez ParallelRunStep pour créer l’étape de pipeline d’inférence par lots, qui accepte tous les paramètres suivants :
name: nom de l’étape, avec les restrictions de nommage suivantes : unique, de 3 à 32 caractères et expression régulière ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_config: objetParallelRunConfig, comme défini précédemment.inputs: un ou plusieurs jeux de données Azure Machine Learning à un seul type, à partitionner pour un traitement parallèle.side_inputs: une ou plusieurs données, ou jeux de données de référence utilisés comme entrées supplémentaires sans avoir besoin d’être partitionnés.output: ObjetOutputFileDatasetConfigqui correspond au répertoire de sortie.arguments: liste d’arguments passés au script utilisateur. Utilisez unknown_args pour les récupérer dans votre script d’entrée (facultatif).allow_reuse: indique si l’étape doit réutiliser les résultats précédents lorsqu’elle est exécutée avec les mêmes paramètres ou entrées. Si la valeur de ce paramètre estFalse, une nouvelle exécution est générée pour cette étape pendant l’exécution du pipeline. (Facultatif ; la valeur par défaut estTrue.)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Techniques de débogage
Il existe trois techniques principales pour déboguer les pipelines :
- Déboguer des étapes de pipeline individuelles sur votre ordinateur local
- Utiliser une journalisation et Application Insights pour isoler et diagnostiquer la source du problème
- Attacher un débogueur distant à un pipeline en cours d’exécution dans Azure
Déboguer les scripts localement
Le fait que le script de domaine ne s’exécute pas comme prévu, ou contient des erreurs de runtime dans le contexte de calcul distant difficiles à déboguer est l’une des erreurs les plus courantes dans un pipeline.
Les pipelines eux-mêmes ne peuvent pas être exécutés localement. Mais l’exécution des scripts en isolation sur votre ordinateur local vous permet de déboguer plus rapidement dans la mesure où vous n’avez pas besoin d’attendre le processus de génération de calcul et d’environnement. Cela demande un peu de travail de développement :
- Si vos données se trouvent dans un magasin de données cloud, vous devez les télécharger et les rendre accessibles à votre script. Utiliser un petit échantillon de données est un bon moyen de réduire la durée d’exécution et d’être rapidement renseigné sur le comportement du script.
- Si vous tentez de simuler une étape de pipeline intermédiaire, vous devrez peut-être créer manuellement les types d’objet que le script particulier attend de l’étape précédente
- Vous devez aussi définir votre propre environnement et répliquer les dépendances définies dans votre environnement de calcul distant
Une fois que vous avez configuré un script pour qu’il s’exécute dans un environnement local, il est plus facile d’effectuer certaines tâches de débogage, notamment :
- Attacher une configuration de débogage personnalisée
- Suspendre l’exécution et inspecter l’état des objets
- Intercepter les erreurs de type ou les erreurs logiques qui n’apparaîtront pas avant l’exécution
Conseil
Une fois que vous pouvez vérifier que votre script s’exécute comme prévu, nous vous recommandons d’exécuter le script dans un pipeline à une seule étape avant de tenter de l’exécuter dans un pipeline à plusieurs étapes.
Configurer, écrire et consulter des journaux de pipeline
Le test de scripts localement est un excellent moyen de déboguer des fragments de code majeurs et une logique complexe avant de commencer à générer un pipeline. À un moment donné, vous devez déboguer les scripts pendant l’exécution du pipeline lui-même, en particulier lors du diagnostic du comportement qui se produit pendant l’interaction entre les étapes du pipeline. Nous vous recommandons d’utiliser à loisir les instructions print() dans les scripts d’étapes pour voir l’état des objets et les valeurs attendues pendant l’exécution distante, comme vous le feriez pour déboguer du code JavaScript.
Options et comportement de journalisation
Le tableau suivant fournit des informations sur les différentes options de débogage des pipelines. Cette liste n’est pas exhaustive, car il existe d’autres options que les solutions Azure Machine Learning et Python présentées ici.
| Bibliothèque | Type | Exemple | Destination | Ressources |
|---|---|---|---|---|
| Kit de développement logiciel (SDK) Azure Machine Learning | Métrique | run.log(name, val) |
Interface utilisateur du portail Azure Machine Learning | Comment suivre les expériences azureml.core.Run class |
| Impression/Journalisation pour Python | Journal | print(val)logging.info(message) |
Journaux du pilote, concepteur Azure Machine Learning | Comment suivre les expériences Journalisation pour Python |
Exemple d’options du journalisation
import logging
from azureml.core.run import Run
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
Concepteur Azure Machine Learning
Pour les pipelines créés dans le concepteur, vous trouverez le fichier 70_driver_log dans la page de création ou dans la page des détails d’exécutions de pipeline.
Activer la journalisation pour les points de terminaison en temps réel
Pour dépanner et déboguer des points de terminaison en temps réel dans le concepteur, vous devez activer la journalisation Application Insights à l’aide du Kit de développement logiciel (SDK). La journalisation vous permet de déboguer et dépanner les problèmes de déploiement et d’utilisation du modèle. Pour plus d’informations, consultez Journalisation pour les modèles déployés.
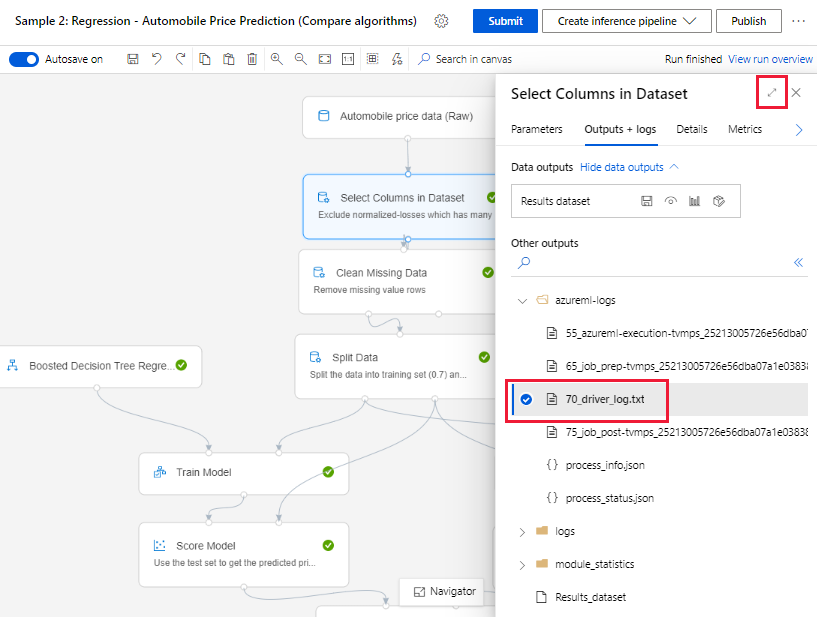
Obtenir des journaux à partir de la page de création
Quand vous publiez une exécution de pipeline en restant dans la page de création, vous voyez les fichiers journaux générés pour chaque composant à mesure que chaque composant termine son exécution.
Sélectionnez un composant dont l’exécution est terminée dans le canevas de création.
Dans le volet droit du composant, accédez à l’onglet Sorties + journaux.
Développez le volet droit, puis sélectionnez le fichier 70_driver_log.txt pour afficher le fichier dans le navigateur. Vous pouvez également télécharger les journaux localement.
Obtenir des journaux à partir des exécutions de pipeline
Vous pouvez également trouver les fichiers journaux d’exécutions spécifiques dans la page des détails d’exécutions de pipeline, qui est disponible dans la section Pipelines ou la section Expériences du studio.
Sélectionnez une exécution de pipeline créée dans le concepteur.
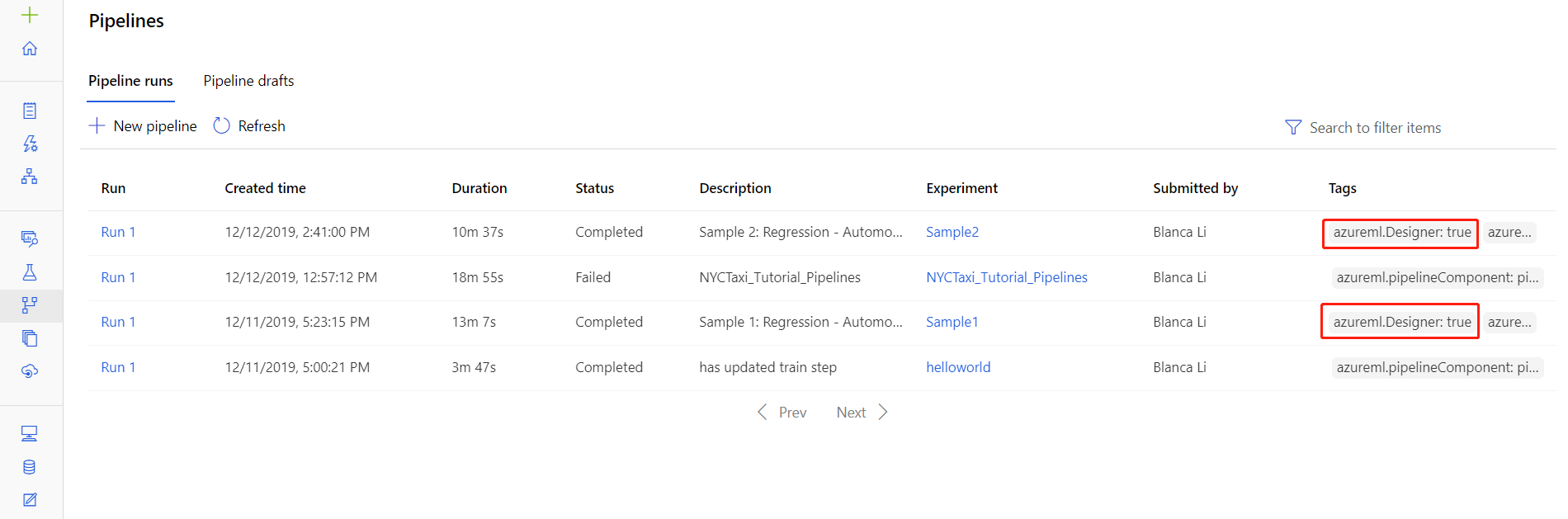
Sélectionnez un composant dans le volet de visualisation.
Dans le volet droit du composant, accédez à l’onglet Sorties + journaux.
Développez le volet droit pour afficher le fichier std_log.txt dans le navigateur, ou sélectionnez le fichier pour télécharger les journaux localement.
Important
Pour mettre à jour un pipeline à partir de la page des détails d’exécution du pipeline, vous devez cloner l’exécution du pipeline dans un nouveau brouillon de pipeline. Une exécution de pipeline est un instantané du pipeline. Elle est similaire à un fichier journal et ne peut pas être modifiée.
Débogage interactif avec Visual Studio Code
Dans certains cas, vous devrez peut-être déboguer interactivement le code Python utilisé dans votre pipeline ML. À l’aide de Visual Studio Code (VS Code) et de debugpy, vous pouvez attacher le code au fur et à mesure de son exécution dans l’environnement d’apprentissage. Pour plus d’informations, consultez le guide de débogage interactif dans VS Code.
HyperdriveStep et AutoMLStep échouent avec l’isolation réseau
Après avoir utilisé HyperdriveStep et AutoMLStep, lorsque vous essayez d’inscrire le modèle, vous pouvez recevoir une erreur.
Vous utilisez le kit de développement logiciel (SDK) v1 d’Azure Machine Learning.
Votre espace de travail Azure Machine Learning est configuré pour l’isolation réseau (VNet).
Votre pipeline tente d’inscrire le modèle généré lors de l’étape précédente. Par exemple, dans l’exemple suivant, le paramètre
inputsest le saved_model à partir d’un HyperdriveStep :register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Solution de contournement
Important
Ce comportement ne survient pas lors de l’utilisation du Kit de développement logiciel (SDK) v2 d’Azure Machine Learning.
Pour contourner cette erreur, utilisez la classe Run pour obtenir le modèle obtenu à partir de HyperdriveStep ou AutoMLStep. Voici un exemple de script qui obtient le modèle de sortie à partir d’un HyperdriveStep :
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
Le fichier peut ensuite servir à partir d’un PythonScriptStep :
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Étapes suivantes
Pour accéder à un tutoriel complet sur l'utilisation de
ParallelRunStep, consultez Tutoriel : Créer un pipeline Azure Machine Learning pour le scoring par lots.Pour obtenir un exemple complet de Machine Learning automatisé dans des pipelines ML, consultez Utiliser le ML automatisé dans un pipeline Azure Machine Learning en Python.
Consultez les informations de référence sur le SDK pour obtenir de l’aide sur les packages azureml-pipelines-core et azureml-pipelines-steps.
Consultez la liste des exceptions et codes d’erreur du concepteur.