Composant Importer des données
Cet article décrit un composant dans le concepteur Azure Machine Learning.
Utilisez ce composant pour charger des données dans un pipeline de Machine Learning des services de données cloud existants.
Notes
Toutes les fonctionnalités fournies par ce composant peuvent être exécutées par le magasin de données et les jeux de données dans la page d’arrivée de l’espace de travail. Nous vous recommandons d’utiliser le magasin de données et le jeu de données qui comprend des fonctionnalités supplémentaires telles que la surveillance des données. Pour plus d’informations, consultez l’article Comment accéder aux données et Comment inscrire des jeux de données. Une fois que vous avez inscrit un jeu de données, vous pouvez le trouver dans la catégorie Jeux de données ->Mes jeux de données dans l’interface du concepteur. Ce composant est réservé aux utilisateurs de Studio (classique) pour une expérience familière.
Le composant Importer des données prend en charge les données lues à partir des sources suivantes :
- URL via HTTP
- Stockages cloud Azure via des magasins de données)
- Conteneur d’objets blob Azure
- Partage de fichiers Azure
- Azure Data Lake
- Azure Data Lake Gen2
- Azure SQL Database
- Azure PostgreSQL
Avant d’utiliser le stockage cloud, vous devez inscrire un magasin de données dans votre espace de travail Azure Machine Learning. Pour plus d’informations, consultez la page Accès aux données.
Après avoir défini les données souhaitées et une fois connecté à la source, Importer des données déduit le type de données de chaque colonne en fonction des valeurs qu’elle contient et charge les données dans votre pipeline de concepteur. La sortie de Importer des données est un jeu de données qui peut être utilisé avec n’importe quel pipeline de concepteur.
Si votre source de données change, vous pouvez actualiser le jeu de données et ajouter de nouvelles données en réexécutant Importer des données.
Avertissement
Si votre espace de travail se trouve dans un réseau virtuel, vous devez configurer vos magasins de données pour qu’ils utilisent les fonctionnalités de visualisation de données du concepteur. Pour plus d’informations sur l’utilisation des magasins de données et des jeux de données sur un réseau virtuel, consultez Isolement réseau pendant l’entraînement et l’inférence avec les réseaux virtuels privés.
Comment configurer Importer des données
Ajoutez le composant Importer des données à votre pipeline. Vous trouverez ce composant dans la catégorie Entrée et sortie de données du concepteur.
Sélectionnez le composant pour ouvrir le volet droit.
Sélectionnez Source de données, puis choisissez le type de source de données. Cela peut être HTTP ou un magasin de données.
Si vous choisissez le magasin de données, vous pouvez sélectionner les magasins de données existants déjà inscrits dans votre espace de travail Azure Machine Learning ou créer un nouveau magasin de données. Ensuite, définissez le chemin d’accès des données à importer dans le magasin de données. Vous pouvez facilement parcourir le chemin en sélectionnant Parcourir le chemin.

Notes
Le composant Importer des données est uniquement destiné aux données tabulaires. Si vous souhaitez importer plusieurs fichiers de données tabulaires à la fois, des erreurs se produiront si les conditions suivantes ne sont pas remplies :
- Pour inclure tous les fichiers de données dans le dossier, vous devez entrer
folder_name/**pour Chemin d’accès. - Tous les fichiers de données doivent être encodés au format unicode-8.
- Tous les fichiers de données doivent avoir les mêmes numéros et noms de colonnes.
- Le résultat de l’importation de plusieurs fichiers de données est une concaténation de toutes les lignes de plusieurs fichiers dans l’ordre.
- Pour inclure tous les fichiers de données dans le dossier, vous devez entrer
Sélectionnez le schéma d’aperçu pour filtrer les colonnes que vous souhaitez inclure. Vous pouvez également définir des paramètres avancés tels que les délimiteurs dans les options d’analyse.
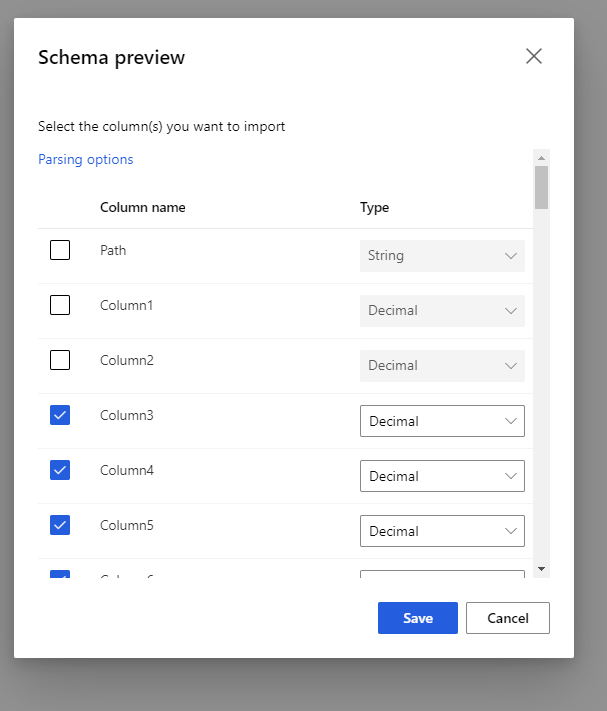
La case à cocher Régénérer la sortie détermine s’il faut exécuter le composant pour régénérer la sortie au moment de l’exécution.
Elle est désélectionnée par défaut, ce qui signifie que si le composant a été exécuté avec les mêmes paramètres par le passé, le système réutilise la sortie de la dernière exécution pour réduire le temps d’exécution.
Si elle est sélectionnée, le système réexécute le composant pour regénérer la sortie. Sélectionnez donc cette option lorsque les données sous-jacentes dans le stockage sont mises à jour. Cela peut vous aider à obtenir les données les plus récentes.
Envoyez le pipeline.
Lorsque le module Importer des données charge les données dans le concepteur, il déduit le type de données de chaque colonne en fonction des valeurs qu’elle contient : numériques ou par catégorie.
Si un en-tête est présent, il est utilisé pour nommer les colonnes du jeu de données de sortie.
S’il n’existe aucun en-tête de colonne dans les données, les nouveaux noms de colonnes sont générés au format col1, col2, ... , coln*.

Résultats
Lorsque l’importation est terminée, cliquez avec le bouton droit sur le jeu de données de sortie et sélectionnez Visualiser pour voir si les données ont bien été importées.
Si vous souhaitez enregistrer les données pour les réutiliser, plutôt que d’importer un nouveau jeu de données à chaque exécution du pipeline, sélectionnez l’icône Inscrire le jeu de données sous l’onglet Sorties + journaux dans le panneau droit du composant. Choisissez un nom pour le jeu de données. Le jeu de données enregistré conserve les données au moment de l’enregistrement. Le jeu de données n’est pas mis à jour lorsque le pipeline est réexécuté, même si le jeu de données dans le pipeline change. Cela peut être utile pour prendre des instantanés de données.
Après l’importation des données, d’autres préparations risquent d’être nécessaires pour la modélisation et l’analyse :
Utilisez Modifier les métadonnées pour changer les noms de colonnes, traiter une colonne comme un autre type de données ou indiquer que certaines colonnes sont des étiquettes ou des caractéristiques.
Utilisez Sélectionner des colonnes dans le jeu de données pour sélectionner un sous-ensemble de colonnes à transformer ou à utiliser dans la modélisation. Les colonnes transformées ou supprimées peuvent facilement être ré-associées au jeu de données d’origine à l’aide du composant Ajouter des colonnes.
Utilisez Partition and Sample (Partition et échantillon) pour diviser le jeu de données, effectuer un échantillonnage ou obtenir les n premières lignes.
Limites
En raison de la limitation de l’accès au magasin de données, si votre pipeline d’inférence contient un composant Importer des données, il est automatiquement supprimé lorsqu’il est déployé sur le point de terminaison en temps réel.
Étapes suivantes
Consultez les composants disponibles pour Azure Machine Learning.