Gérer les erreurs et les exceptions dans Azure Logic Apps
S’applique à : Azure Logic Apps (Consommation + Standard)
Le mode de gestion approprié des temps d’arrêt ou des problèmes dus à des dépendances de systèmes peut se révéler être un défi dans une architecture d’intégration. Pour vous aider à créer des intégrations fiables et résilientes qui gèrent correctement les problèmes et les défaillances, Azure Logic Apps fournit une expérience de qualité pour la gestion des erreurs et des exceptions.
Stratégies de nouvelle tentative
Pour la gestion des exceptions et des erreurs simple, vous pouvez utiliser la stratégie de nouvelle tentative lorsqu’elle est prise en charge sur un déclencheur ou une action, comme l’action HTTP. Si la requête d’origine du déclencheur ou de l’action expire ou échoue, ce qui entraîne une réponse 408, 429 ou 5xx, la stratégie de nouvelle tentative spécifie que le déclencheur ou l’action renvoie la requête par paramètres de stratégie.
Limites de stratégie de nouvelles tentatives
Pour plus d’informations sur les stratégies de nouvelle tentative, les paramètres, les limites et d’autres options, passez en revue les limites des stratégies de nouvelle tentative.
Types de stratégies de nouvelles tentatives
Les opérations de connecteur qui prennent en charge les stratégies de nouvelles tentatives utilisent la stratégie Par défaut, sauf si vous sélectionnez une autre stratégie de nouvelle tentative.
| Stratégie de nouvelle tentative | Description |
|---|---|
| Par défaut | Pour la plupart des opérations, la stratégie Par défaut est une stratégie d’intervalle exponentiel qui envoie jusqu’à 4 nouvelles tentatives à intervalles exponentiellement croissants. Ces intervalles évoluent de 7,5 secondes mais sont limités entre 5 et 45 secondes. Plusieurs opérations utilisent une stratégie de nouvelles tentatives Par défaut différente, telle qu’une stratégie d’intervalle fixe. Pour plus d’informations, consultez le type de stratégie de nouvelles tentatives par défaut. |
| Aucun | Ne renvoie pas la requête. Pour plus d’informations, consultez Aucun - Aucune stratégie de nouvelles tentatives. |
| Intervalle exponentiel | Cette stratégie attend un intervalle aléatoire qui est sélectionné parmi une plage à croissance exponentielle avant d’envoyer la requête suivante. Pour plus d’informations, consultez le type de stratégie d’intervalle exponentiel. |
| Intervalle fixe | Cette stratégie attend l’intervalle spécifié avant d’envoyer la requête suivante. Pour plus d’informations, consultez le type de stratégie d’intervalle fixe. |
Modifier le type de stratégie de nouvelle tentative dans le concepteur
Sur le Portail Azure, ouvrez votre flux de travail d’application logique dans le Concepteur.
Selon que vous travaillez sur un workflow Consommation ou Standard, ouvrez les paramètres du déclencheur ou de l’action.
Consommation : dans la forme d’action, ouvrez le menu points de suspension (...), puis sélectionnez Paramètres.
Standard : dans le concepteur, sélectionnez l’action. Dans le volet d’informations, sélectionnez Paramètres.
Si l’action ou le déclencheur prend en charge les stratégies de nouvelle tentative, sous Stratégie de nouvelle tentative, sélectionnez le type souhaité.
Modifier le type de stratégie de nouvelle tentative dans l’éditeur de vue de code
Si nécessaire, vérifiez si le déclencheur ou l’action prend en charge les stratégies de nouvelle tentative en effectuant les étapes précédentes dans le concepteur.
Ouvrez votre flux de travail d’application logique dans l’éditeur de vue de code.
Dans la définition du déclencheur ou de l’action, ajoutez l’objet JSON
retryPolicyà l’objetinputsdu déclencheur ou de l’action. Sinon, si aucun objetretryPolicyn’existe, le déclencheur ou l’action utilise la stratégie de nouvelle tentativedefault."inputs": { <...>, "retryPolicy": { "type": "<retry-policy-type>", // The following properties apply to specific retry policies. "count": <retry-attempts>, "interval": "<retry-interval>", "maximumInterval": "<maximum-interval>", "minimumInterval": "<minimum-interval>" }, <...> }, "runAfter": {}Obligatoire
Propriété Valeur Type Description type< retry-policy-type> String Type de stratégie de nouvelles tentatives à utiliser : default,none,fixedouexponentialcount< retry-attempts> Integer Pour les types de stratégie fixedetexponential, le nombre de nouvelles tentatives, qui est valeur comprise entre 1 et 90. Pour plus d’informations, consultez Intervalle fixe et Intervalle exponentiel.interval< retry-interval> String Pour les types de stratégie fixedetexponential, la valeur d’intervalle de nouvelle tentative au format ISO 8601. Pour la stratégieexponential, vous pouvez également spécifier des intervalles maximum et minimum facultatifs. Pour plus d’informations, consultez Intervalle fixe et Intervalle exponentiel.
Consommation : 5 secondes (PT5S) à 1 jour (P1D).
Standard : pour les flux de travail avec état, 5 secondes (PT5S) à 1 jour (P1D). Pour les flux de travail sans état, 1 seconde (PT1S) à 1 minute (PT1M).Facultatif
Propriété Valeur Type Description maximumInterval< maximum-interval> String Pour la stratégie exponential, il s’agit du plus grand intervalle pour l’intervalle sélectionné de manière aléatoire au format ISO 8601. La valeur par défaut est 1 jour (P1D). Pour plus d’informations, consultez Intervalle exponentiel.minimumInterval< minimum-interval> String Pour la stratégie exponential, il s’agit du plus petit intervalle pour l’intervalle sélectionné de manière aléatoire au format ISO 8601. La valeur par défaut est de 5 secondes (PT5S). Pour plus d’informations, consultez Intervalle exponentiel.
Stratégie de nouvelle tentative par défaut
Les opérations de connecteur qui prennent en charge les stratégies de nouvelles tentatives utilisent la stratégie Par défaut, sauf si vous sélectionnez une autre stratégie de nouvelle tentative. Pour la plupart des opérations, la stratégie Par défaut est une stratégie d’intervalle exponentiel qui envoie jusqu’à 4 nouvelles tentatives à intervalles exponentiellement croissants. Ces intervalles évoluent de 7,5 secondes mais sont limités entre 5 et 45 secondes. Plusieurs opérations utilisent une stratégie de nouvelles tentatives Par défaut différente, telle qu’une stratégie d’intervalle fixe.
Dans la définition de votre workflow, la définition de déclencheur ou d’action ne définit pas explicitement la stratégie par défaut, mais l’exemple suivant montre comment la stratégie de nouvelles tentatives par défaut se comporte pour l’action HTTP :
"HTTP": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "http://myAPIendpoint/api/action",
"retryPolicy" : {
"type": "exponential",
"interval": "PT7S",
"count": 4,
"minimumInterval": "PT5S",
"maximumInterval": "PT1H"
}
},
"runAfter": {}
}
Aucun - Aucune stratégie de nouvelle tentative
Pour spécifier que l’action ou le déclencheur n’effectue pas de nouvelle tentative en cas d’échec de requête, affectez la valeur none à <retry-policy-type>.
Stratégie de nouvelle tentative d’intervalle fixe
Pour spécifier que l’action ou le déclencheur attend l’intervalle spécifié avant d’envoyer la requête suivante, affectez la valeur fixed à <retry-policy-type>.
Exemple
Cette stratégie de nouvelle tentative tente d’obtenir les dernières actualités deux fois de plus après l’échec de la première requête, avec un délai de 30 secondes entre chaque tentative :
"Get_latest_news": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "https://mynews.example.com/latest",
"retryPolicy": {
"type": "fixed",
"interval": "PT30S",
"count": 2
}
}
}
Stratégie de nouvelle tentative d’intervalle exponentiel
La stratégie de nouvelle tentative d’intervalle exponentiel spécifie que le déclencheur ou l’action attend un intervalle aléatoire avant d’envoyer la requête suivante. L’intervalle aléatoire est sélectionné parmi une plage à croissance exponentielle. Si vous le souhaitez, vous pouvez remplacer les intervalles minimum et maximal par défaut en spécifiant vos propres intervalles minimum et maximal, selon que vous disposez d’un workflow d’application logique Consommation ou Standard.
| Name | Limite pour Consommation | Limite pour Standard | Notes |
|---|---|---|---|
| Délai maximal | Par défaut : 1 jour | Par défaut : 1 heure | Pour modifier la limite par défaut dans un workflow d’application logique de consommation, utilisez le paramètre de stratégie de nouvelle tentative. Pour modifier la limite par défaut dans un workflow d’application logique standard, consultez Modifier les paramètres de l’hôte et de l’application pour les applications logiques dans Azure Logic Apps monolocataire. |
| Délai minimal | Par défaut : 5 secondes | Par défaut : 5 secondes | Pour modifier la limite par défaut dans un workflow d’application logique de consommation, utilisez le paramètre de stratégie de nouvelle tentative. Pour modifier la limite par défaut dans un workflow d’application logique standard, consultez Modifier les paramètres de l’hôte et de l’application pour les applications logiques dans Azure Logic Apps monolocataire. |
Plage des variables aléatoires
Pour la stratégie de nouvelle tentative d’intervalle exponentielle, le tableau suivant montre l’algorithme général que Azure Logic Apps utilise pour générer une variable aléatoire uniforme dans la plage spécifiée pour chaque nouvelle tentative. La plage spécifiée peut aller jusqu’au nombre de nouvelles tentatives.
| Nombre de nouvelles tentatives | Intervalle minimal | Intervalle maximal |
|---|---|---|
| 1 | max(0, <minimum-interval>) | min(interval, <maximum-interval>) |
| 2 | max(interval, <minimum-interval>) | min(2 * interval, <maximum-interval>) |
| 3 | max(2 * interval, <minimum-interval>) | min(4 * interval, <maximum-interval>) |
| 4 | max(4 * interval, <minimum-interval>) | min(8 * interval, <maximum-interval>) |
| .... | .... | .... |
Gérer le comportement « runAfter »
Quand vous ajoutez des actions dans le concepteur de flux de travail, vous déclarez implicitement l’ordre dans lequel exécuter ces actions. Une fois son exécution terminée, une action est marquée avec un état tel que Succeeded, Failed, Skipped ou TimedOut. Par défaut, une action que vous ajoutez dans le concepteur s’exécute uniquement quand le prédécesseur se termine avec l’état Succeeded. Dans la définition sous-jacente de l’action, la propriété runAfter spécifie l’action predécesseur qui doit d’abord se terminer ainsi que les états autorisés pour ce prédécesseur avant que l’action suivante puisse s’exécuter.
Quand une action lève une erreur ou une exception non gérée, elle est marquée Failed et toute action successeur est marquée comme Skipped. Si ce comportement se produit pour une action qui a des branches parallèles, le moteur Azure Logic Apps suit les autres branches pour déterminer leurs états d’achèvement. Par exemple, si une branche se termine par une action Skipped, l’état d’achèvement de cette branche est basé sur l’état du prédécesseur de cette action ignorée. Une fois l’exécution du flux de travail terminé, le moteur détermine l’état de l’exécution complète en évaluant tous les états des branches. Si une branche se termine par un échec, la totalité de l’exécution du flux de travail est marquée Failed.
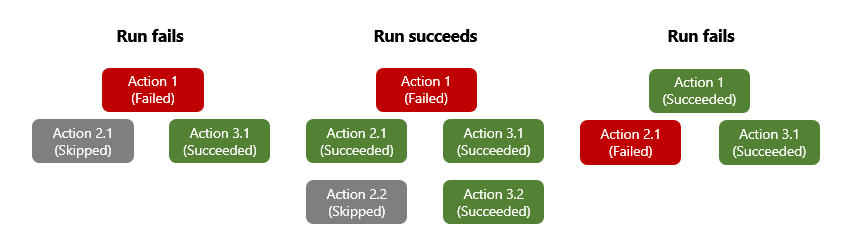
Pour vous assurer qu’une action peut toujours être exécutée malgré l’état de son prédécesseur, vous pouvez modifier comportement « runAfter » d’une action afin de gérer les états d’échec du prédécesseur. De cette façon, l’action s’exécute lorsque l’état du prédécesseur est Succeeded, Failed, Skipped, TimedOut ou tous ces états.
Par exemple, pour exécuter l’action dans Office 365 Outlook Envoyer par e-mail uen fois l’action prédécesseur Excel Online Ajouter une ligne dans un tableau marquée Failed plutôt que Succeeded, modifiez le comportement « runAfter » à l’aide du concepteur ou de l’éditeur de vue de code.
Notes
Dans le concepteur, le paramètre « runAfter » ne s’applique pas à l’action qui suit immédiatement le déclencheur, car le déclencheur doit s’exécuter correctement avant que la première action puisse s’exécuter.
Modifier le comportement « runAfter » dans le concepteur
Sur le Portail Azure, ouvrez le flux de travail d’application logique dans le Concepteur.
Dans le concepteur, sélectionnez la forme de l’action. Dans le volet d’informations, sélectionnez Paramètres.
La section Exécuter après du volet Paramètres affiche l’action du prédécesseur pour l’action actuellement sélectionnée.
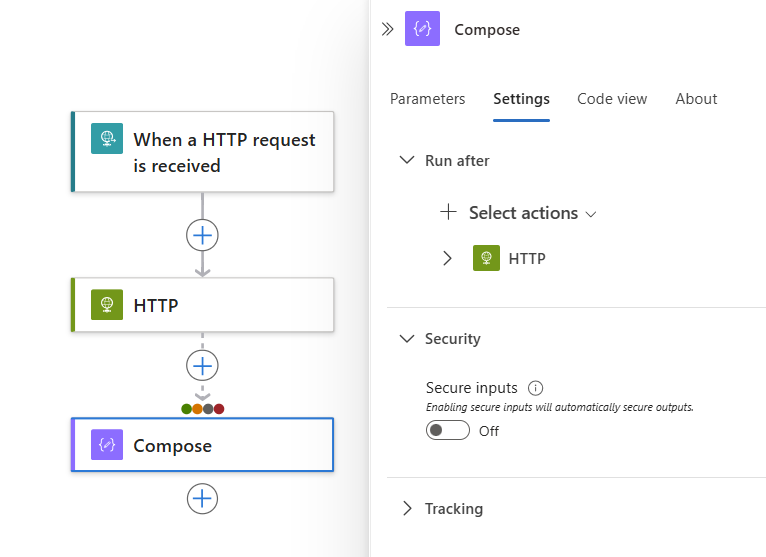
Développez l’action du prédécesseur pour voir tous les états possibles du prédécesseur.
Par défaut, l’état « exécuter après » est défini sur A réussi. Par conséquent, l’action du prédécesseur doit se terminer correctement avant que l’action actuellement sélectionnée puisse s’exécuter.
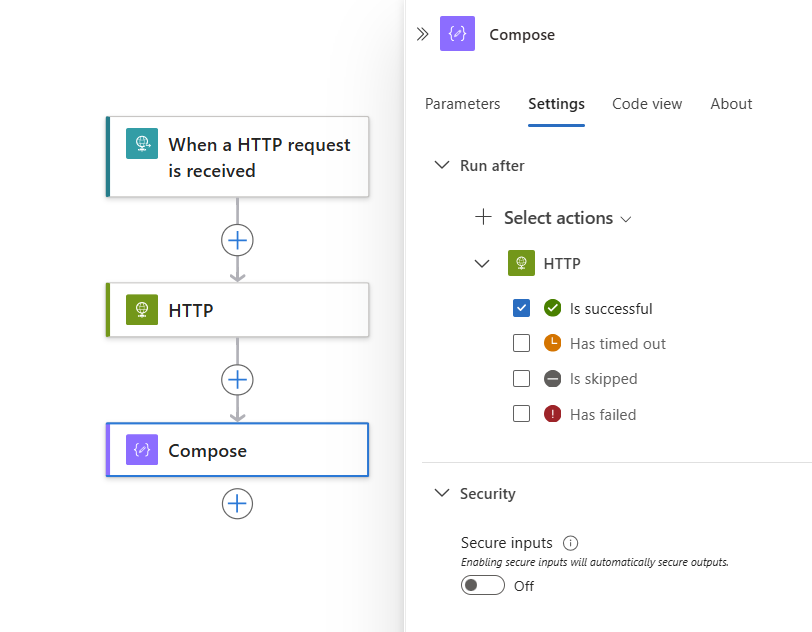
Pour modifier le comportement « exécuter après », sélectionnez les états de votre choix. Vérifiez que vous sélectionnez d’abord une option avant d’effacer l’option par défaut. Vous devez toujours avoir au moins une option sélectionnée.
Dans l’exemple suivant, A échoué est sélectionné.
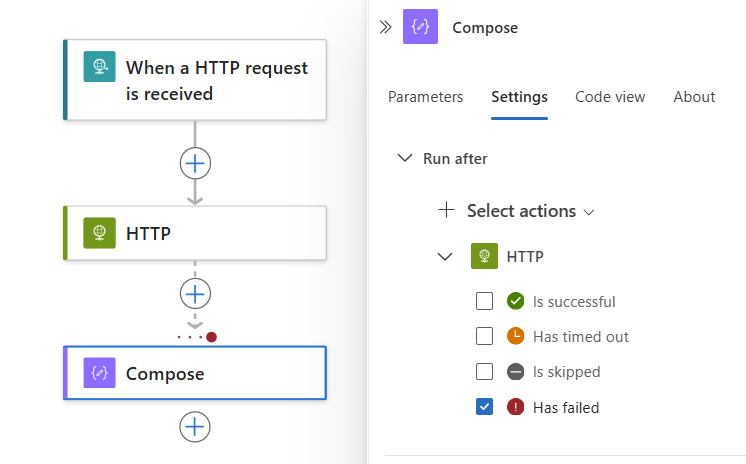
Pour spécifier que l’action actuelle s’exécute lorsque l’action du prédécesseur se termine avec l’état Failed, Skipped ou TimedOut, sélectionnez ces états.
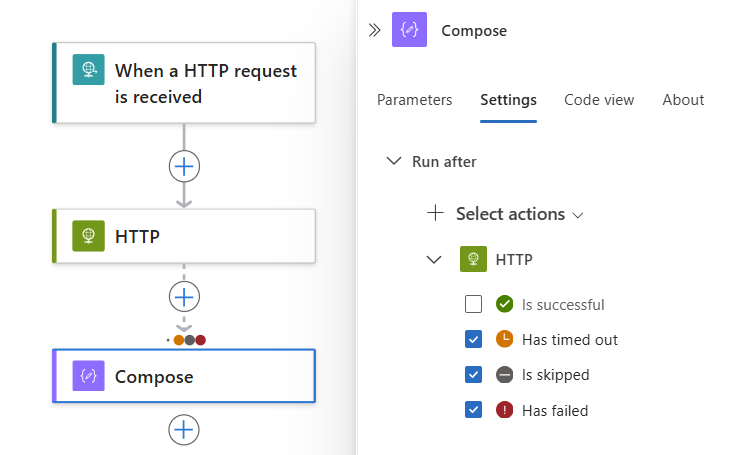
Pour exiger que plusieurs actions prédécesseurs s’exécutent, chacune avec ses propres états « runAfter », développez la liste Sélectionner des actions. Sélectionnez les actions prédécesseurs souhaitées et spécifiez leur état « runAfter » requis.
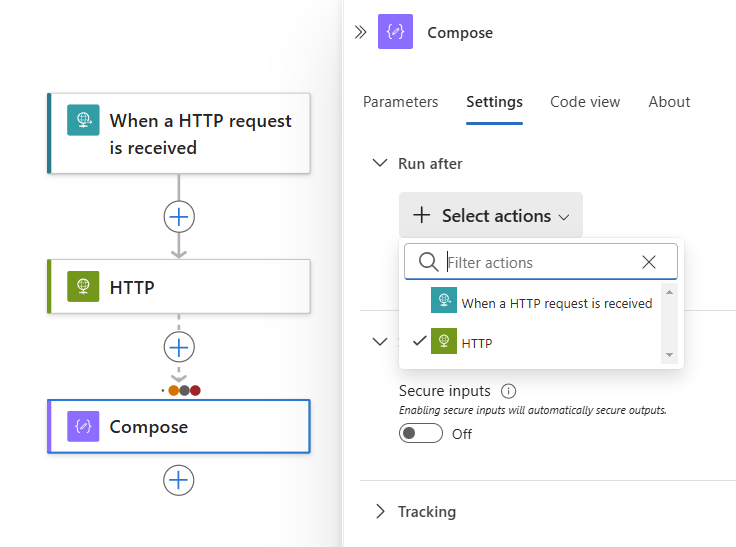
Quand vous êtes prêt, sélectionnez Terminé.
Modifier le comportement « runAfter » dans l’éditeur de vue de code
Dans le Portail Azure, ouvrez votre flux de travail d’application logique dans l’éditeur de vue de code.
Sans la définition JSON de l’action, modifiez la propriété
runAfter, qui suit la syntaxe suivante :"<action-name>": { "inputs": { "<action-specific-inputs>" }, "runAfter": { "<preceding-action>": [ "Succeeded" ] }, "type": "<action-type>" }Pour cet exemple, remplacez la valeur de la propriété
runAfterSucceededparFailed:"Send_an_email_(V2)": { "inputs": { "body": { "Body": "<p>Failed to add row to table: @{body('Add_a_row_into_a_table')?['Terms']}</p>", "Subject": "Add row to table failed: @{body('Add_a_row_into_a_table')?['Terms']}", "To": "Sophia.Owen@fabrikam.com" }, "host": { "connection": { "name": "@parameters('$connections')['office365']['connectionId']" } }, "method": "post", "path": "/v2/Mail" }, "runAfter": { "Add_a_row_into_a_table": [ "Failed" ] }, "type": "ApiConnection" }Pour spécifier que l’action s’exécute si l’action prédécesseur est marquée comme
Failed,SkippedouTimedOut, ajoutez les autres états :"runAfter": { "Add_a_row_into_a_table": [ "Failed", "Skipped", "TimedOut" ] },
Évaluer les actions avec des étendues et leurs résultats
Comme pour l’exécution d’étapes après des actions individuelles avec la propriété runAfter, vous pouvez regrouper des actions dans une étendue. Vous pouvez utiliser des étendues lorsque vous souhaitez regrouper des actions de manière logique, évaluer l’état d’agrégation de l’étendue et effectuer des actions en fonction de cet état. Une fois que toutes les actions d’une étendue ont été exécutées, l’étendue récupère son propre état.
Pour vérifier l’état d’une étendue, vous pouvez utiliser les mêmes critères que ceux utilisés pour vérifier l’état d’exécution d’un flux de travail, tels que Succeeded, Failed, etc.
Par défaut, lorsque toutes les actions de l’étendue réussissent, l’état de l’étendue est défini sur Succeeded. Si l’état de la dernière action d’une étendue est Failed ou Aborted, l’état de l’étendue est défini sur Failed.
Pour intercepter les exceptions dans une étendue Failed et exécuter des actions qui gèrent ces erreurs, vous pouvez utiliser la propriété runAfter de cette étendue Failed. Ainsi, si des actions figurant dans l’étendue échouent, et que vous utilisez la propriété runAfter pour cette étendue, vous pouvez créer une seule action pour intercepter des échecs.
Pour les limites sur les étendues, consultez Limites et configuration.
Configurer une étendue avec « exécuter après » pour la gestion des exceptions
Sur le Portail Azure, ouvrez votre flux de travail d’application logique dans le Concepteur.
Votre flux de travail doit déjà avoir un déclencheur qui démarre le flux de travail.
Dans le concepteur, suivez ces étapes génériques pour ajouter une action Contrôle nommée Étendue à votre flux de travail.
Dans l’action Étendue, suivez ces étapes génériques pour ajouter des actions à exécuter, par exemple :
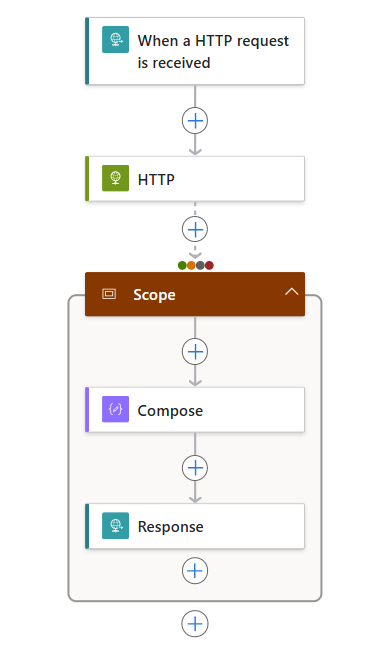
La liste suivante montre quelques exemples d’actions que vous pouvez inclure dans une action Étendue :
- Obtenir des données à partir d’une API.
- Traiter les données.
- Enregistrer les données dans une base de données.
Définissez maintenant les règles « exécuter après » applicables à l’exécution des actions dans l’étendue.
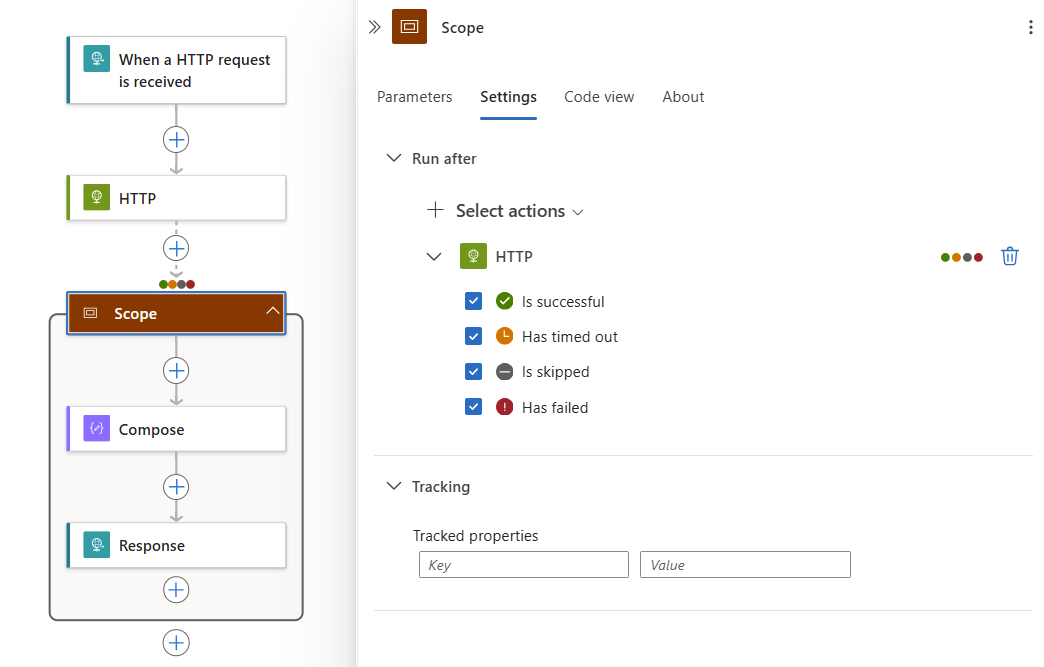
Dans le concepteur, sélectionnez le titre Étendue. Lorsque le volet d’informations de l’étendue s’ouvre, sélectionnez Paramètres.
Si vous avez plusieurs actions précédentes dans le flux de travail, dans la liste Sélectionner des actions, sélectionnez l’action après laquelle vous souhaitez exécuter les actions incluses dans l’étendue.
Pour l’action sélectionnée, sélectionnez tous les états d’action qui peuvent exécuter les actions incluses dans l’étendue.
En d’autres termes, tout état choisi résultant de l’action sélectionnée entraîne l’exécution des actions dans l’étendue.
Dans l’exemple suivant, les actions incluses dans l’étendue s’exécutent une fois que l’action HTTP se termine avec l’un des états sélectionnés :
Obtenir le contexte et les résultats des échecs
Bien que l’interception des échecs d’une étendue soit utile, vous aurez peut-être également de plus de contexte pour savoir précisément quelles sont les actions qui ont échoué, ainsi que les codes d’erreur ou d’état renvoyés. La fonction result() retourne les résultats des actions de niveau supérieur dans une action étendue. Cette fonction accepte le nom de l’étendue en tant que paramètre unique et retourne un tableau avec les résultats de ces actions de niveau supérieur. Ces objets d’action incluent les mêmes attributs que ceux retournés par la fonction actions(), comme l’heure de début, l’heure de fin, l’état, les entrées, les ID de corrélation et les sorties de l’action.
Notes
La fonction result() retourne les résultats uniquement à partir des actions de premier niveau, et non pas à partir d’actions imbriquées plus approfondies telles que les actions de condition ou de basculement.
Pour obtenir le contexte sur les actions qui ont échoué dans une étendue, vous pouvez utiliser l’expression @result() avec le nom de l’étendue et le paramètre RunAfter. Pour filtrer le tableau retourné en fonction des actions qui ont l’état Failed, vous pouvez ajouter l’action Filtrer un tableau. Pour exécuter une action pour une action ayant retourné une erreur, utilisez le tableau filtré retourné avec une boucle For each.
L’exemple JSON qui suit envoie une requête HTTP POST avec le corps de réponse pour toutes les actions qui ont échoué dans l’action d’étendue My_Scope. Une explication détaillée suit l’exemple.
"Filter_array": {
"type": "Query",
"inputs": {
"from": "@result('My_Scope')",
"where": "@equals(item()['status'], 'Failed')"
},
"runAfter": {
"My_Scope": [
"Failed"
]
}
},
"For_each": {
"type": "foreach",
"actions": {
"Log_exception": {
"type": "Http",
"inputs": {
"method": "POST",
"body": "@item()['outputs']['body']",
"headers": {
"x-failed-action-name": "@item()['name']",
"x-failed-tracking-id": "@item()['clientTrackingId']"
},
"uri": "http://requestb.in/"
},
"runAfter": {}
}
},
"foreach": "@body('Filter_array')",
"runAfter": {
"Filter_array": [
"Succeeded"
]
}
}
Les étapes suivantes décrivent ce qui se passe dans cet exemple :
Pour obtenir le résultat de toutes les actions contenues dans My_Scope, l’action Filter Array utilise cette expression de filtre :
@result('My_Scope')La condition de l’action Filtrer le tableau est tout élément
@result()dont l’état est égal àFailed. Cette condition filtre le tableau ayant tous les résultats d’action de My_Scope afin d’obtenir un tableau contenant uniquement les résultats d’action ayant échoué.Exécution d’une action en boucle
For_eachsur les résultats du tableau filtré. Cette étape exécute une action pour chaque résultat d’action ayant échoué filtré précédemment.Si une action dans l’étendue échoue, les actions de la boucle
For_eachs’exécutent une seule fois. Plusieurs actions ayant échoué peuvent provoquer une action par échec.Envoi d’une requête HTTP POST sur le corps de réponse de l’élément
For_each, qui est l’expression@item()['outputs']['body'].La forme de l’élément
@result()est identique à la forme@actions()et peut être analysée de la même façon.Deux en-têtes personnalisés avec le nom de l’action qui a échoué (
@item()['name']) sont également inclus, ainsi que l’ID de suivi du client d’exécution qui a échoué (@item()['clientTrackingId']).
Pour référence, voici un exemple d’un seul élément @result(), montrant le name, le body, et les propriétés clientTrackingId analysés dans l’exemple précédent. En dehors d’une action For_each, @result() retourne un tableau de ces objets.
{
"name": "Example_Action_That_Failed",
"inputs": {
"uri": "https://myfailedaction.azurewebsites.net",
"method": "POST"
},
"outputs": {
"statusCode": 404,
"headers": {
"Date": "Thu, 11 Aug 2016 03:18:18 GMT",
"Server": "Microsoft-IIS/8.0",
"X-Powered-By": "ASP.NET",
"Content-Length": "68",
"Content-Type": "application/json"
},
"body": {
"code": "ResourceNotFound",
"message": "/docs/folder-name/resource-name does not exist"
}
},
"startTime": "2016-08-11T03:18:19.7755341Z",
"endTime": "2016-08-11T03:18:20.2598835Z",
"trackingId": "bdd82e28-ba2c-4160-a700-e3a8f1a38e22",
"clientTrackingId": "08587307213861835591296330354",
"code": "NotFound",
"status": "Failed"
}
Vous pouvez utiliser les expressions décrites plus haut dans cet article pour exécuter différents modèles de gestion des exceptions. Vous pouvez choisir d’exécuter une seule action de gestion des exceptions en dehors de l’étendue qui accepte l’intégralité du tableau filtré d’échecs, et de supprimer l’action For_each. Vous pouvez également inclure d’autres propriétés utiles à partir de la réponse \@result() comme décrit précédemment.
Configurer les journaux Azure Monitor
Les modèles précédents sont des méthodes utiles pour gérer les erreurs et les exceptions qui se produisent dans une exécution. Toutefois, vous pouvez également identifier et répondre aux erreurs qui se produisent indépendamment de l’exécution. Vous pouvez surveiller les journaux d’activité et les mesures pour vos exécutions, ou les publier dans n’importe quel outil de supervision de votre choix pour évaluer les états d’exécution.
Par exemple, Azure Monitor fournit un moyen simplifié d’envoyer tous les événements de flux de travail, y compris tous les états d’exécution et d’action, à une destination. Vous pouvez configurer des alertes pour des métriques et des seuils spécifiques dans Azure Monitor. Vous pouvez également envoyer des événements de flux de travail à un espace de travail Log Analytics ou à un compte de stockage Azure. Vous pouvez également diffuser tous les événements via Azure Event Hubs dans Azure Stream Analytics. Dans Stream Analytics, vous pouvez écrire des requêtes actives basées sur des anomalies, moyennes ou échecs dans les journaux de diagnostic. Vous pouvez utiliser Stream Analytics pour envoyer des informations à d’autres sources de données, telles que des files d’attente, des rubriques, SQL, Azure Cosmos DB ou Power BI.
Pour plus d'informations, consultez Configurer les journaux d'activité Azure Monitor et collecter des données de diagnostic pour Azure Logic Apps.