Configurer des points de terminaison de flux de données
Important
Cette page contient des instructions pour gérer les composants d’Opérations Azure IoT en utilisant des manifestes de déploiement Kubernetes, qui est en préversion. Cette fonctionnalité est fournie avec plusieurs limitations et ne doit pas être utilisée pour les charges de travail de production.
Pour connaître les conditions juridiques qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou plus généralement non encore en disponibilité générale, consultez l’Avenant aux conditions d’utilisation des préversions de Microsoft Azure.
Pour commencer à utiliser des flux de données, commencez par créer des points de terminaison de flux de données. Un point de terminaison de flux de données est le point de connexion utilisé par le flux de données. Vous pouvez utiliser un point de terminaison comme source ou destination pour le flux de données. Certains types de points de terminaison peuvent être utilisés à la fois comme sources et destinations, tandis que d’autres sont uniquement destinés aux destinations. Un flux de données a besoin d’au moins un point de terminaison source et un point de terminaison de destination.
Utilisez le tableau suivant pour choisir le type de point de terminaison à configurer :
| Type de point de terminaison | Description | Peut être utilisé comme une source | Peut être utilisé comme destination |
|---|---|---|---|
| MQTT | Pour la messagerie bidirectionnelle avec les répartiteurs MQTT, notamment l’une intégrée aux opérations Azure IoT et Event Grid. | Oui | Oui |
| Kafka | Pour la messagerie bidirectionnelle avec les répartiteurs Kafka, notamment Azure Event Hubs. | Oui | Oui |
| Data Lake | Pour charger des données dans des comptes de stockage Azure Data Lake Gen2. | Non | Oui |
| Microsoft Fabric OneLake | Pour charger des données dans Microsoft Fabric OneLake lakehouses. | Non | Oui |
| Explorateur de données Azure | Pour charger des données dans des bases de données Azure Data Explorer. | Non | Oui |
| Stockage local | Pour envoyer des données à un volume persistant disponible localement, via lequel vous pouvez télécharger des données via Azure Container Storage activé par les volumes Edge Azure Arc. | Non | Oui |
Important
Les points de terminaison de stockage nécessitent un schéma pour la sérialisation. Pour utiliser le flux de données avec Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer ou Stockage local, vous devez spécifier une référence de schéma.
Pour générer le schéma à partir d’un exemple de fichier de données, utilisez Schema Gen Helper.
Les flux de données doivent utiliser le point de terminaison de l’Agent MQTT local
Quand vous créez un flux de données, vous spécifiez les points de terminaison source et de destination. Le flux de données déplace les données du point de terminaison source vers le point de terminaison de destination. Vous pouvez utiliser le même point de terminaison pour plusieurs flux de données, et vous pouvez utiliser le même point de terminaison à la fois comme source et comme destination dans un flux de données.
Cependant, l’utilisation de points de terminaison personnalisés à la fois comme source et comme destination dans un flux de données n’est pas prise en charge. Cette restriction signifie que l’Agent MQTT intégré dans Opérations Azure IoT doit être au moins un point de terminaison. Il peut s’agir de la source, de la destination ou des deux. Pour éviter les échecs de déploiement de flux de données, utilisez le point de terminaison de flux de données MQTT par défaut comme source ou comme destination pour chaque flux de données.
L’exigence spécifique est que chaque flux de données doit avoir la source ou la destination configurée avec un point de terminaison MQTT qui a l’hôte aio-broker. Il n’est donc pas strictement nécessaire d’utiliser le point de terminaison par défaut, et vous pouvez créer des points de terminaison de flux de données supplémentaires pointant vers l’Agent MQTT local dès lors que l’hôte est aio-broker. Cependant, pour éviter les confusions et les problèmes liés à la gestion, le point de terminaison par défaut est l’approche recommandée.
Le tableau suivant présente les scénarios pris en charge :
| Scénario | Pris en charge |
|---|---|
| Point de terminaison par défaut comme source | Oui |
| Point de terminaison par défaut comme destination | Oui |
| Point de terminaison personnalisé comme source | Oui, si la destination est le point de terminaison par défaut ou un point de terminaison MQTT avec l’hôte aio-broker. |
| Point de terminaison personnalisé comme destination | Oui, si la source est le point de terminaison par défaut ou un point de terminaison MQTT avec l’hôte aio-broker. |
| Point de terminaison personnalisé comme source et comme destination | Non, sauf si un des deux est un point de terminaison MQTT avec l’hôte aio-broker. |
Réutiliser les points de terminaison
Considérez chaque point de terminaison de flux de données comme un ensemble de paramètres de configuration qui contiennent l’endroit où les données doivent provenir ou accéder à (la valeur host), comment s’authentifier auprès du point de terminaison et d’autres paramètres tels que la configuration TLS ou la préférence de traitement par lot. Vous devez donc simplement la créer une seule fois, puis vous pouvez la réutiliser dans plusieurs flux de données où ces paramètres seraient identiques.
Pour faciliter la réutilisation des points de terminaison, le filtre de rubrique MQTT ou Kafka ne fait pas partie de la configuration du point de terminaison. Au lieu de cela, vous spécifiez le filtre de rubrique dans la configuration du flux de données. Cela signifie que vous pouvez utiliser le même point de terminaison pour plusieurs flux de données qui utilisent différents filtres de rubrique.
Par exemple, vous pouvez utiliser le point de terminaison de flux de données du répartiteur MQTT par défaut. Vous pouvez l’utiliser pour la source et la destination avec différents filtres de rubrique :
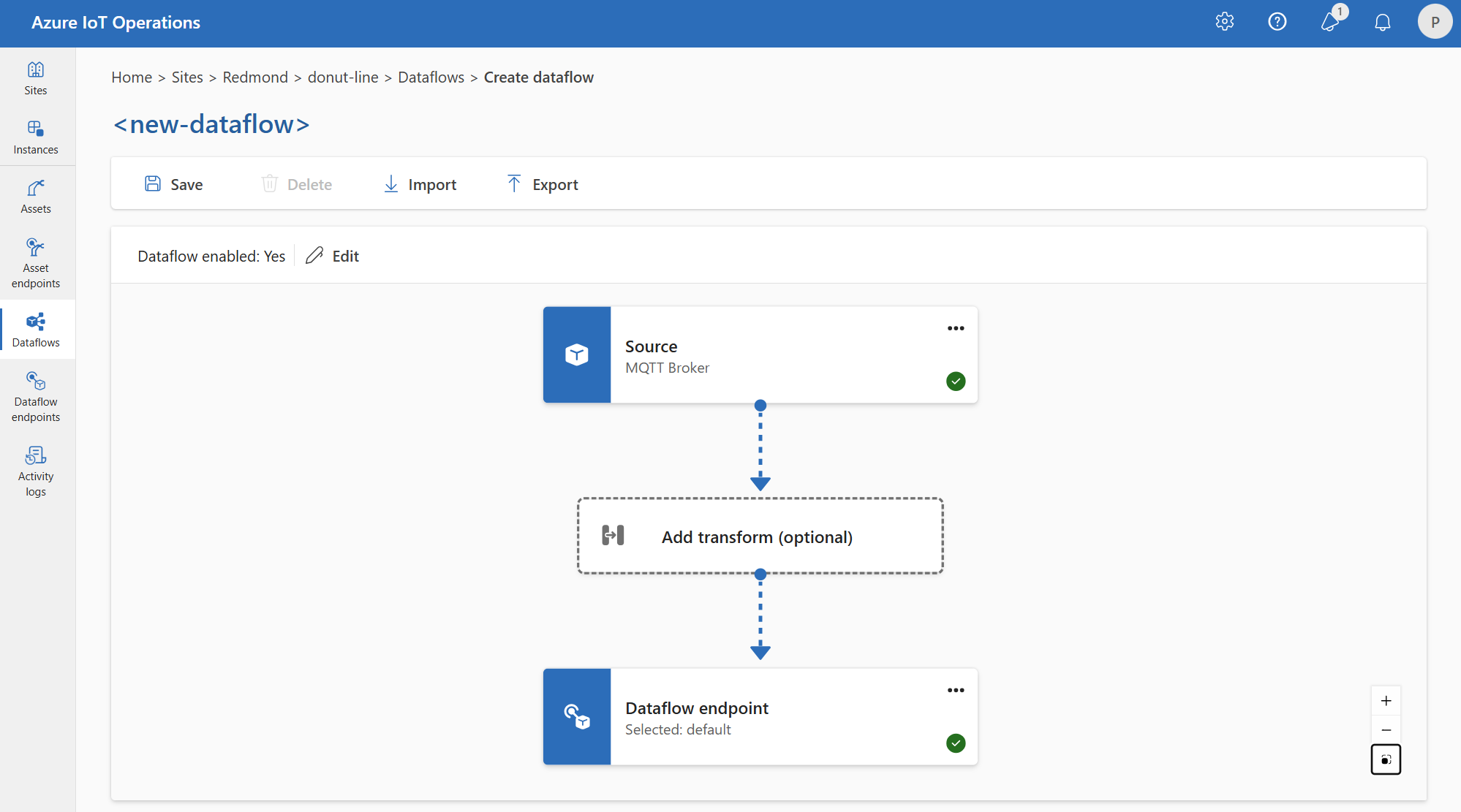
De même, vous pouvez créer plusieurs flux de données qui utilisent le même point de terminaison MQTT pour d’autres points de terminaison et rubriques. Par exemple, vous pouvez utiliser le même point de terminaison MQTT pour un flux de données qui envoie des données à un point de terminaison Event Hubs.
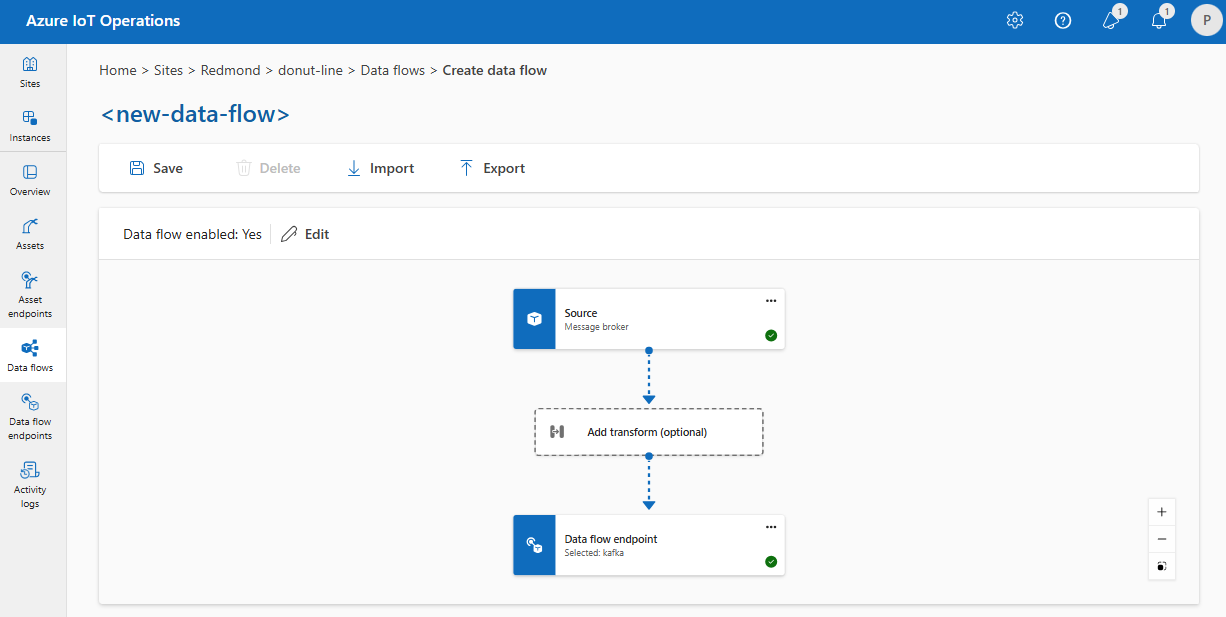
Comme pour l’exemple MQTT, vous pouvez créer plusieurs flux de données qui utilisent le même point de terminaison Kafka pour différentes rubriques, ou le même point de terminaison Data Lake pour différentes tables.
Étapes suivantes
Créez un point de terminaison de flux de données :