Configurer des points de terminaison de flux de données Azure Event Hubs et Kafka
Important
Cette page inclut des instructions pour la gestion des composants Azure IoT Operations à l’aide des manifestes de déploiement Kubernetes, qui sont en version préliminaire. Cette fonctionnalité est fournie avec plusieurs limitations et ne doit pas être utilisée pour les charges de travail de production.
Pour connaître les conditions juridiques qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou plus généralement non encore en disponibilité générale, consultez l’Avenant aux conditions d’utilisation des préversions de Microsoft Azure.
Pour configurer une communication bidirectionnelle entre Opérations Azure IoT et des brokers Apache Kafka, vous pouvez configurer un point de terminaison de flux de données. Cette configuration vous permet de spécifier le point de terminaison, le protocole TLS (Transport Layer Security), l’authentification et d’autres paramètres.
Prérequis
- Une instance d’Opérations Azure IoT
Azure Event Hubs
Azure Event Hubs est compatible avec le protocole Kafka et peut être utilisé avec des flux de données avec certaines limitations.
Créer un espace de noms et un hub d’événements Azure Event Hubs
Tout d’abord, créez un espace de noms Azure Event Hubs activé pour Kafka.
Ensuite, créez un hub d’événements dans l’espace de noms. Chaque hub d’événements individuel correspond à une rubrique Kafka. Vous pouvez créer plusieurs hubs d’événements dans le même espace de noms pour représenter plusieurs rubriques Kafka.
Attribuer une autorisation à une identité managée
Pour configurer un point de terminaison de flux de données pour Azure Event Hubs, nous vous recommandons d’utiliser une identité managée affectée par le système ou par l’utilisateur. Cette approche sécurisée élimine la gestion manuelle des informations d’identification.
Une fois l’espace de noms Azure Event Hubs et l’Event Hub créés, vous devez attribuer un rôle à l’identité managée Opérations Azure IoT qui accorde l’autorisation d’envoyer ou de recevoir des messages vers/depuis l’Event Hub.
Si vous utilisez l’identité managée affectée par le système, accédez à votre instance d’Opérations Azure IoT dans le Portail Azure, puis sélectionnez Vue d’ensemble. Copiez le nom de l’extension mentionné après Extension Arc Opérations Azure IoT. Par exemple, azure-iot-operations-xxxx7. Vous trouverez votre identité managée affectée par le système en utilisant le même nom que l’extension Arc d’Opérations Azure IoT.
Accédez ensuite à l’espace de noms Event Hubs >Access Control (IAM)>Ajouter une attribution de rôle.
- Dans l’onglet Rôle, sélectionnez un rôle approprié, comme
Azure Event Hubs Data SenderouAzure Event Hubs Data Receiver. Cela permet d’accorder à l’identité managée les autorisations nécessaires pour envoyer ou recevoir des messages pour tous les Event Hubs de l’espace de noms. Pour en savoir plus, consultez Authentifier une application avec Microsoft Entra ID pour accéder aux ressources Event Hubs. - Sélectionnez l’onglet Membres :
- Si vous utilisez l’identité managée affectée par le système, pour Attribuer l’accès à, sélectionnez l’option Utilisateur, groupe ou principal de service, puis cliquez sur + Sélectionner des membres et recherchez le nom de l’extension Arc d’Opérations Azure IoT.
- Si vous utilisez l’identité managée affectée par l’utilisateur, pour Attribuer l’accès à, sélectionnez l’option Identité managée, puis cliquez sur + Sélectionner des membres et recherchez votre identité managée affectée par l’utilisateur configurée pour les connexions cloud.
Créer un point de terminaison de flux de données pour Azure Event Hubs
Une fois l’espace de noms Azure Event Hubs et l’Event Hub configurés, vous pouvez créer un point de terminaison de flux de données pour l’espace de noms Azure Event Hubs avec Kafka.
Dans l’expérience des opérations, sélectionnez l’onglet Points de terminaison de flux de données.
Sous Créer un point de terminaison de flux de données, sélectionnez Azure Event Hubs>Nouveau.
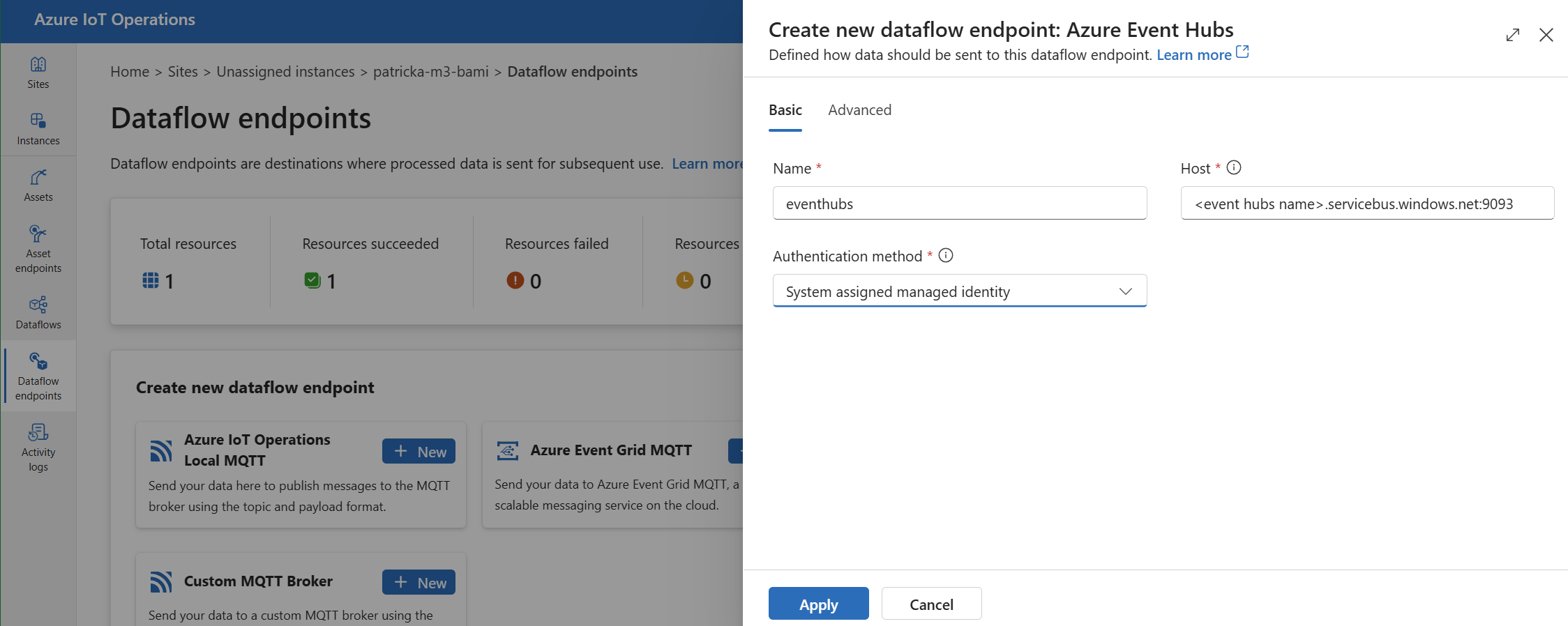
Entrez les paramètres suivants pour le point de terminaison :
Setting Description Nom Nom du point de terminaison de flux de données. Hôte Nom d’hôte du broker Kafka au format <NAMESPACE>.servicebus.windows.net:9093. Incluez le numéro de port9093dans le paramètre d’hôte pour Event Hubs.Méthode d'authentification Méthode utilisée pour l’authentification. Nous recommandons de choisir Identité managée affectée par le système ou Identité managée affectée par l’utilisateur. Sélectionnez Appliquer pour approvisionner le point de terminaison.
Remarque
La rubrique Kafka, ou l’Event Hub individuel, est configuré ultérieurement quand vous créez le flux de données. La rubrique Kafka est la destination des messages de flux de données.
Utiliser la chaîne de connexion pour l’authentification auprès d’Event Hubs
Important
Pour utiliser le portail d’expérience des opérations afin de gérer les secrets, vous devez avoir activé Opérations Azure IoT en utilisant les paramètres sécurisés. Pour cela, configurez un coffre Azure Key Vault et activez les identités de charge de travail. Pour en savoir plus, consultez Activer les paramètres sécurisés dans un déploiement d’Opérations Azure IoT.
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Informations de base, puis choisissez Méthode d’authentification>SASL.
Entrez les paramètres suivants pour le point de terminaison :
| Setting | Description |
|---|---|
| Type SASL | Choisissez Plain. |
| Nom du secret synchronisé | Entrez un nom de secret Kubernetes contenant la chaîne de connexion. |
| Informations de référence sur le nom d’utilisateur ou secret de jeton | Référence au nom d’utilisateur ou au secret de jeton utilisé pour l’authentification SASL. Choisissez-le dans la liste Key Vault ou créez-en un nouveau. La valeur doit être $ConnectionString. |
| Informations de référence sur le mot de passe du secret de jeton | Référence au mot de passe ou au secret de jeton utilisé pour l’authentification SASL. Choisissez-le dans la liste Key Vault ou créez-en un nouveau. La valeur doit être au format Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY>. |
Après avoir sélectionné Ajouter une référence, si vous sélectionnez Créer, entrez les paramètres suivants :
| Setting | Description |
|---|---|
| Nom du secret | Le nom du secret dans Azure Key Vault. Choisissez un nom facile à mémoriser pour pouvoir le sélectionner ultérieurement dans la liste. |
| Valeur secrète | Pour le nom d’utilisateur, entrez $ConnectionString. Pour le mot de passe, entrez la chaîne de connexion au format Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY>. |
| Définir une date d’activation | Si cette option est activée, date à laquelle le secret devient actif. |
| Définir la date d’expiration | Si cette option est activée, date à laquelle le secret expire. |
Pour en savoir plus sur les secrets, consultez Créer et gérer des secrets dans Azure IoT Operations.
Limites
Azure Event Hubs ne prend pas en charge tous les types de compression pris en charge par Kafka. Seule la compression GZIP est actuellement prise en charge pour Event Hubs aux niveaux Premium et Dédié. L’utilisation d’autres types de compression peut entraîner des erreurs.
Répartiteurs Kafka personnalisés
Pour configurer un point de terminaison de flux de données pour des brokers Kafka non Event Hub, définissez l’hôte, le protocole TLS, l’authentification et d’autres paramètres si nécessaire.
Dans l’expérience des opérations, sélectionnez l’onglet Points de terminaison de flux de données.
Sous Créer un point de terminaison de flux de données, sélectionnez Broker Kafka personnalisé>Nouveau.
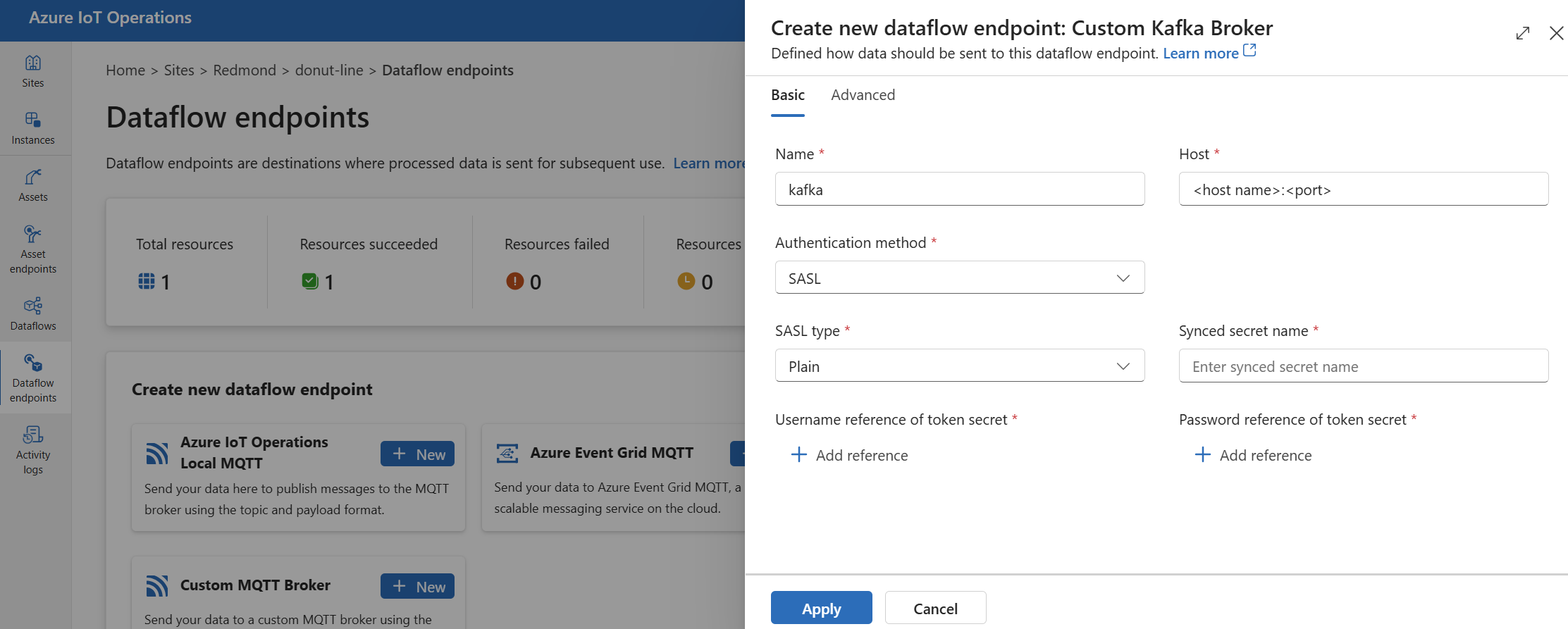
Entrez les paramètres suivants pour le point de terminaison :
Setting Description Nom Nom du point de terminaison de flux de données. Hôte Nom d’hôte du broker Kafka au format <Kafka-broker-host>:xxxx. Incluez le numéro de port dans le paramètre d’hôte.Méthode d'authentification Méthode utilisée pour l’authentification. Choisissez SASL. Type SASL Type d’authentification SASL. Choisissez Plain, ScramSha256ou ScramSha512. Obligatoire si vous utilisez SASL. Nom du secret synchronisé Nom du secret. Obligatoire si vous utilisez SASL. Informations de référence sur le nom d’utilisateur du secret de jeton Référence au nom d’utilisateur dans le secret du jeton SASL. Obligatoire si vous utilisez SASL. Sélectionnez Appliquer pour approvisionner le point de terminaison.
Remarque
Actuellement, l’expérience des opérations ne prend pas en charge l’utilisation d’un point de terminaison de flux de données Kafka comme source. Vous pouvez créer un flux de données avec un point de terminaison de flux de données Kafka source à l’aide de Kubernetes ou de Bicep.
Pour plus d’informations sur la personnalisation des paramètres du point de terminaison, utilisez les sections suivantes.
Méthodes d'authentification disponibles
Les méthodes d’authentification suivantes sont disponibles pour les points de terminaison de flux de données du broker Kafka.
Identité managée affectée par le système
Avant de configurer le point de terminaison de flux de données, attribuez un rôle à l’identité managée d’Opérations Azure IoT qui accorde l’autorisation de se connecter au broker Kafka :
- Dans le Portail Azure, accédez à votre instance d’Opérations Azure IoT, puis sélectionnez Vue d’ensemble.
- Copiez le nom de l’extension mentionné après Extension Arc Opérations Azure IoT. Par exemple, azure-iot-operations-xxxx7.
- Accédez à la ressource cloud dont vous avez besoin pour accorder des autorisations. Par exemple, accédez à l’espace de noms Event Hubs >Access Control (IAM)>Ajouter une attribution de rôle.
- Dans l’onglet Rôle, sélectionnez un rôle approprié.
- Sous l’onglet Membres, pour Attribuer l’accès à, sélectionnez l’option Utilisateur, groupe ou principal de service, puis cliquez sur + Sélectionner des membres et recherchez l’identité managée d’Opérations Azure IoT. Par exemple, azure-iot-operations-xxxx7.
Ensuite, configurez le point de terminaison de flux de données avec les paramètres d’identité managée affectée par le système.
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Informations de base, puis choisissez Méthode d’authentification>Identité managée affectée par le système.
Cette configuration crée une identité managée avec l’audience par défaut, qui est la même que la valeur d’hôte d’espace de noms Event Hubs sous la forme https://<NAMESPACE>.servicebus.windows.net. Toutefois, si vous devez remplacer l’audience par défaut, vous pouvez définir le champ audience sur la valeur souhaitée.
Non pris en charge dans l’expérience des opérations.
Identité managée affectée par l’utilisateur
Pour utiliser l’identité gérée attribuée par l’utilisateur pour l’authentification, vous devez d’abord déployer Azure IoT Operations avec les paramètres sécurisés activés. Vous devez ensuite configurer une identité gérée attribuée par l’utilisateur pour les connexions cloud. Pour en savoir plus, consultez Activer les paramètres sécurisés dans le déploiement d’Azure IoT Operations.
Avant de configurer le point de terminaison de flux de données, attribuez un rôle à l’identité managée affectée par l’utilisateur qui accorde l’autorisation de se connecter au broker Kafka :
- Dans le portail Azure, accédez à la ressource cloud dont vous avez besoin pour accorder des autorisations. Par exemple, accédez à l’espace de noms Event Grid >Access Control (IAM)>Ajouter une attribution de rôle.
- Dans l’onglet Rôle, sélectionnez un rôle approprié.
- Dans l’onglet Membres, pour Attribuer l’accès à, sélectionnez l’option Identité managée, puis cliquez sur + Sélectionner des membres et recherchez votre identité managée affectée par l’utilisateur.
Ensuite, configurez le point de terminaison de flux de données avec les paramètres d’identité managée affectée par l’utilisateur.
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Informations de base, puis choisissez Méthode d’authentification>Identité managée affectée par l’utilisateur.
Ici, l’étendue est l’audience de l’identité managée. La valeur par défaut est la même que la valeur de l’hôte de l’espace de noms Event Hubs sous la forme https://<NAMESPACE>.servicebus.windows.net. Cependant, si vous devez remplacer l’audience par défaut, vous pouvez définir le champ de l’étendue sur la valeur souhaitée en utilisant Bicep ou Kubernetes.
SASL
Pour utiliser SASL pour l’authentification, spécifiez la méthode d’authentification SASL, puis configurez le type de SASL ainsi qu’une référence au secret avec le nom du secret qui contient le jeton SASL.
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Informations de base, puis choisissez Méthode d’authentification>SASL.
Entrez les paramètres suivants pour le point de terminaison :
| Setting | Description |
|---|---|
| Type SASL | Type d’authentification SASL à utiliser. Les types pris en charge sont Plain, ScramSha256 et ScramSha512. |
| Nom du secret synchronisé | Nom du secret Kubernetes qui contient le jeton SASL. |
| Informations de référence sur le nom d’utilisateur ou secret de jeton | Référence au nom d’utilisateur ou au secret de jeton utilisé pour l’authentification SASL. |
| Informations de référence sur le mot de passe du secret de jeton | Référence au mot de passe ou au secret de jeton utilisé pour l’authentification SASL. |
Les types SASL pris en charge sont les suivants :
PlainScramSha256ScramSha512
Le secret doit se trouver dans le même espace de noms que le point de terminaison de flux de données Kafka. Le secret doit avoir le jeton SASL comme paire clé-valeur.
Anonyme
Pour utiliser l’authentification anonyme, mettez à jour la section d’authentification des paramètres Kafka afin d’utiliser la méthode Anonymous.
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Informations de base, puis choisissez Méthode d’authentification>Aucune.
Paramètres avancés
Vous pouvez définir des paramètres avancés pour le point de terminaison de flux de données Kafka, tels que le protocole TLS, le certificat d’autorité de certification approuvé, les paramètres de messagerie Kafka, le traitement par lot et CloudEvents. Vous pouvez définir ces paramètres sous l’onglet de portail Avancé du point de terminaison de flux de données ou dans la ressource du point de terminaison de flux de données.
Dans l’expérience des opérations, sélectionnez l’onglet Avancé du point de terminaison de flux de données.
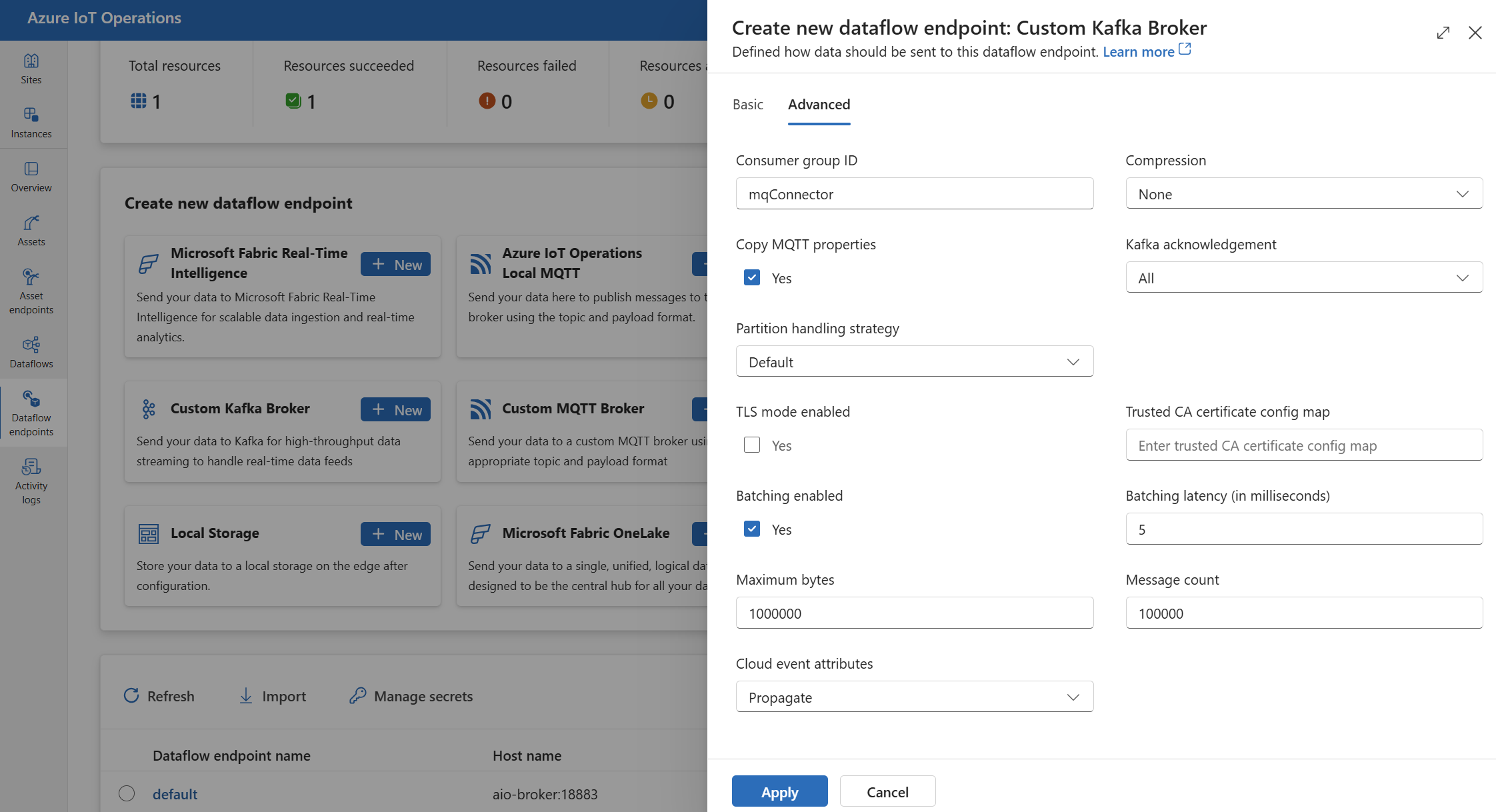
Paramètres TLS
Mode TLS
Pour activer ou désactiver le protocole TLS pour le point de terminaison Kafka, mettez à jour le paramètre mode dans les paramètres TLS.
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Avancé, puis cochez la case à côté de Mode TLS activé.
Le mode TLS peut être défini sur Enabled ou Disabled. Si le mode est défini sur Enabled, le flux de données utilise une connexion sécurisée au broker Kafka. Si le mode est défini sur Disabled, le flux de données utilise une connexion non sécurisée au broker Kafka.
Certificat d’autorité de certification approuvé
Configurez le certificat d’autorité de certification de confiance pour le point de terminaison Kafka afin d’établir une connexion sécurisée à l’agent Kafka. Ce paramètre est important si le broker Kafka utilise un certificat auto-signé ou un certificat signé par une autorité de certification personnalisée qui n’est pas approuvée par défaut.
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Avancé, puis utilisez le champ ConfigMap du certificat d’autorité de certification approuvé pour spécifier le ConfigMap contenant le certificat d’autorité de certification approuvé.
Ce ConfigMap doit contenir le certificat d’autorité de certification au format PEM. Le ConfigMap doit se trouver dans le même espace de noms que la ressource de flux de données Kafka. Par exemple :
kubectl create configmap client-ca-configmap --from-file root_ca.crt -n azure-iot-operations
Conseil
Quand vous vous connectez à Azure Event Hubs, le certificat d’autorité de certification n’est pas obligatoire, car le service Event Hubs utilise un certificat signé par une autorité de certification publique de confiance par défaut.
ID de groupe de consommateurs
L’ID de groupe de consommateurs est utilisé pour identifier le groupe de consommateurs que le flux de données utilise pour lire les messages de la rubrique Kafka. L’ID de groupe de consommateurs doit être unique dans le broker Kafka.
Important
Quand le point de terminaison Kafka est utilisé comme source, l’ID du groupe de consommateurs est requis. Sinon, le flux de données ne peut pas lire les messages de la rubrique Kafka et vous recevez une erreur « Un consumerGroupId doit être défini sur les points de terminaison source de type Kafka ».
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Avancé, puis utilisez le champ ID de groupe de consommateur pour spécifier l’ID de groupe de consommateurs.
Ce paramètre prend effet uniquement si le point de terminaison est utilisé comme source (autrement dit, le flux de données est un consommateur).
Compression
Le champs compression permet la compression des messages envoyés aux rubriques Kafka. La compression permet de réduire la bande passante réseau et l’espace de stockage requis pour le transfert de données. Toutefois, la compression ajoute également une surcharge et une latence au processus. Les types de compression pris en charge sont répertoriés dans le tableau ci-après.
| Valeur | Description |
|---|---|
None |
Aucune compression ou traitement par lot n’est appliqué. Aucun est la valeur par défaut si aucune compression n’est spécifiée. |
Gzip |
La compression et le traitement par lots GZIP sont appliqués. GZIP est un algorithme de compression à usage général qui offre un bon équilibre entre le rapport de compression et la vitesse. Seule la compression GZIP est actuellement prise en charge pour Event Hubs aux niveaux Premium et Dédié. |
Snappy |
La compression Snappy et le traitement par lots sont appliqués. Snappy est un algorithme de compression rapide qui offre un ratio de compression et une vitesse modérés. Ce mode de compression n’est pas pris en charge par Azure Event Hubs. |
Lz4 |
La compression LZ4 et le traitement par lots sont appliqués. LZ4 est un algorithme de compression rapide qui offre un faible ratio de compression et une vitesse élevée. Ce mode de compression n’est pas pris en charge par Azure Event Hubs. |
Pour configurer la compression :
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Avancé, puis utilisez le champ Compression pour spécifier le type de compression.
Ce paramètre prend effet uniquement si le point de terminaison est utilisé comme destination dans laquelle le flux de données est un producteur.
Traitement par lots
Outre la compression, vous pouvez également configurer le traitement par lots des messages avant de les envoyer à des rubriques Kafka. Le traitement par lots vous permet de regrouper plusieurs messages et de les compresser en tant qu’unité unique, ce qui peut améliorer l’efficacité de la compression et réduire la surcharge réseau.
| Champ | Description | Obligatoire |
|---|---|---|
mode |
Peut être Enabled ou Disabled. La valeur par défaut est Enabled, car Kafka n’a pas la notion de messagerie non regroupée par lots. Si la valeur est Disabled, le traitement par lots est réduit au minimum pour créer un lot avec un seul message à chaque fois. |
Non |
latencyMs |
Intervalle de temps maximal en millisecondes au cours duquel les messages peuvent être mis en mémoire tampon avant d’être envoyés. Si cet intervalle est atteint, tous les messages mis en mémoire tampon sont envoyés en tant que lot, quel que soit leur nombre ou leur taille. Si elle n’est pas définie, la valeur par défaut est 5. | Non |
maxMessages |
Nombre maximal de messages pouvant être mis en mémoire tampon avant d’être envoyés. Si ce nombre est atteint, tous les messages mis en mémoire tampon sont envoyés en tant que lot, quel que soit leur taille ou leur durée de mise en mémoire tampon. Si elle n’est pas définie, la valeur par défaut est 100000. | Non |
maxBytes |
Nombre maximal d’octets pouvant être mis en mémoire tampon avant d’être envoyés. Si cette taille est atteinte, tous les messages mis en mémoire tampon sont envoyés en tant que lot, quel que soit leur nombre ou leur durée de mise en mémoire tampon. La valeur par défaut est 1000000 Mo (1 To). | Non |
Par exemple, si vous affectez 1000 à latencyMs, 100 à maxMessages et 1024 à maxBytes, les messages sont envoyés quand la mémoire tampon contient 100 messages, quand la mémoire tampon contient 1 024 octets ou quand 1 000 millisecondes se sont écoulées depuis le dernier envoi, selon ce qui se produit en premier.
Pour configurer le traitement par lot :
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Avancé, puis utilisez le champ Traitement par lot activé pour activer le traitement par lot. Utilisez les champs Latence de traitement par lot, Nombre maximal d’octets et Nombre de messages pour spécifier les paramètres de traitement par lot.
Ce paramètre prend effet uniquement si le point de terminaison est utilisé comme destination dans laquelle le flux de données est un producteur.
Stratégie de gestion des partitions
La stratégie de gestion des partitions contrôle la façon dont les messages sont affectés aux partitions Kafka lors de leur envoi à des rubriques Kafka. Les partitions Kafka sont des segments logiques d’une rubrique Kafka qui activent le traitement parallèle et la tolérance de panne. Chaque message d’une rubrique Kafka dispose d’une partition et d’un décalage utilisés pour identifier et classer les messages.
Ce paramètre prend effet uniquement si le point de terminaison est utilisé comme destination dans laquelle le flux de données est un producteur.
Par défaut, un flux de données attribue des messages à des partitions aléatoires à l’aide d’un algorithme de tourniquet. Toutefois, vous pouvez utiliser différentes stratégies pour affecter des messages à des partitions en fonction de certains critères, tels que le nom de la rubrique MQTT ou une propriété de message MQTT. Cela peut vous aider à améliorer l’équilibrage de charge, la localisation des données ou l’ordre des messages.
| Valeur | Description |
|---|---|
Default |
Attribution des messages à des partitions aléatoires à l’aide d’un algorithme de tourniquet. Il s’agit de la valeur par défaut si aucune stratégie n’est spécifiée. |
Static |
Attribue des messages à un nombre de partition fixe dérivé de l’ID d’instance du flux de données. Cela signifie que chaque instance de flux de données envoie des messages à une partition différente. Cela peut aider à améliorer l’équilibrage de charge ainsi que l’emplacement des données. |
Topic |
Utilise le nom de rubrique MQTT de la source de flux de données comme clé de partitionnement. Cela signifie que les messages portant le même nom de rubrique MQTT sont envoyés à la même partition. Cela peut aider à améliorer l’ordre des messages ainsi que la localisation des données. |
Property |
Utilise une propriété de message MQTT de la source de flux de données comme clé de partitionnement. Spécifiez le nom de la propriété dans le champ partitionKeyProperty. Cela signifie que les messages ayant la même valeur de propriété sont envoyés à la même partition. Cela peut aider à améliorer l’ordre des messages ainsi que la localisation des données lors de critères personnalisés. |
Par exemple, si vous affectez la valeur Property à la stratégie de gestion des partitions, et la valeur device-id à la propriété de clé de partition, les messages ayant la même propriété device-id sont envoyés à la même partition.
Pour configurer la stratégie de gestion des partitions :
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Avancé, puis utilisez le champ Stratégie de gestion des partitions pour spécifier la stratégie de gestion des partitions. Utilisez le champ Propriété de clé de partition pour spécifier la propriété servant au partitionnement, si la stratégie a la valeur Property.
Accusés de réception Kafka
Les accusés de réception Kafka (acks) permettent de contrôler la durabilité et la cohérence des messages envoyés aux rubriques Kafka. Quand un producteur envoie un message à une rubrique Kafka, il peut demander différents niveaux d’accusés de réception à l’agent Kafka pour vérifier que le message est correctement écrit dans la rubrique, et répliqué dans le cluster Kafka.
Ce paramètre prend effet uniquement si le point de terminaison est utilisé comme destination (autrement dit, le flux de données est un producteur).
| Valeur | Description |
|---|---|
None |
Le flux de données n’attend pas d’accusé de réception de la part du broker Kafka. Ce paramètre est l’option la plus rapide mais la moins durable. |
All |
Le flux de données attend que le message soit écrit dans la partition du leader et dans toutes les partitions des suiveurs. Ce paramètre est l’option la plus lente mais la plus durable. Ce paramètre est également l’option par défaut. |
One |
Le flux de données attend que le message soit écrit dans la partition du leader et au moins dans la partition d’un suiveur. |
Zero |
Le flux de données attend que le message soit écrit dans la partition du leader, mais n’attend pas d’accusé de réception de la part des partitions des suiveurs. Cela est plus rapide que One mais moins durable. |
Par exemple, si vous définissez l’accusé de réception Kafka sur All, le flux de données attend que le message soit écrit dans la partition du leader et dans toutes les partitions des suiveurs avant d’envoyer le message suivant.
Pour configurer les accusés de réception Kafka :
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Avancé, puis utilisez le champ Accusé de réception Kafka pour spécifier le niveau d’accusé de réception Kafka.
Ce paramètre prend uniquement effet si le point de terminaison est utilisé comme destination dans laquelle le flux de données est un producteur.
Copier les propriétés MQTT
Par défaut, le paramètre de copie de propriétés MQTT est activé. Ces propriétés utilisateur incluent des valeurs telles que subject, qui stocke le nom de la ressource envoyant le message.
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Avancé, puis cochez la case à côté du champ Copier les propriétés MQTT pour activer ou désactiver la copie des propriétés MQTT.
Les sections suivantes décrivent comment les propriétés MQTT sont traduites en en-têtes d’utilisateur Kafka et vice versa lorsque le paramètre est activé.
Le point de terminaison Kafka est une destination
Quand un point de terminaison Kafka est une destination de flux de données, toutes les propriétés définies par la spécification MQTT v5 sont traduites en en-têtes utilisateur Kafka. Par exemple, un message MQTT v5 avec « Type de contenu » transféré à Kafka se traduit par l’en-tête d’utilisateur Kafka "Content Type":{specifiedValue}. Des règles similaires s’appliquent à d’autres propriétés MQTT intégrées, définies dans le tableau suivant.
| Propriété MQTT | Comportement traduit |
|---|---|
| Indicateur de format de charge utile | Clé : « Indicateur de format de charge utile » Valeur : « 0 » (la charge utile est en octets) ou « 1 » (la charge utile est UTF-8) |
| Rubrique de réponse | Clé : « Rubrique de réponse » Valeur : copie de la rubrique de réponse à partir du message d’origine. |
| Intervalle d’expiration du message | Clé : « Intervalle d’expiration du message » Valeur : représentation UTF-8 du nombre de secondes avant l’expiration du message. Pour plus d’informations, consultez Propriété de l’intervalle d’expiration du message. |
| Données de corrélation : | Clé : « Données de corrélation » Valeur : copie des données de corrélation à partir du message d’origine. Contrairement à de nombreuses propriétés MQTT v5 encodées en UTF-8, les données de corrélation peuvent être des données arbitraires. |
| Type de contenu : | Clé : « Type de contenu » Valeur : copie du type de contenu à partir du message d’origine. |
Les paires clé-valeur de propriété utilisateur MQTT v5 sont directement traduites en en-têtes d’utilisateur Kafka. Si un en-tête d’utilisateur dans un message porte le même nom qu’une propriété MQTT intégrée (par exemple, un en-tête d’utilisateur nommé « Données de corrélation »), la transmission de la valeur de propriété de spécification MQTT v5 ou de la propriété utilisateur n’est pas définie.
Les flux de données ne reçoivent jamais ces propriétés d’un broker MQTT. Donc, un flux de données ne leur transfère jamais :
- Alias de rubrique
- Identificateurs d’abonnement
Propriété Intervalle d’expiration du message
L’intervalle d’expiration du message spécifie la durée pendant laquelle un message peut rester dans un broker MQTT avant d’être ignoré.
Quand un flux de données reçoit un message MQTT dont l’intervalle d’expiration du message est spécifié, il :
- Enregistre l’heure à laquelle le message a été reçu.
- Avant que le message ne soit émis à la destination, l’heure est soustraite du message qui a été mis en file d’attente à partir de l’intervalle d'expiration d'origine.
- Si le message n’a pas expiré (l’opération ci-dessus est > 0), le message est émis vers la destination et il contient la date/heure d’expiration du message mise à jour.
- Si le message a expiré (l’opération ci-dessus est <= 0), le message n’est pas émis par la cible.
Exemples :
- Un flux de données reçoit un message MQTT avec un intervalle d’expiration du message de 3600 secondes. La destination correspondante est temporairement déconnectée, mais peut se reconnecter. 1 000 secondes s’écoulent avant que ce message MQTT soit envoyé à la cible. Dans ce cas, le message de la destination a son intervalle d’expiration de message défini sur 2 600 (3 600 – 1 000) secondes.
- Le flux de données reçoit un message MQTT avec un intervalle d’expiration du message de 3600 secondes. La destination correspondante est temporairement déconnectée, mais peut se reconnecter. Dans ce cas, il faut cependant 4 000 secondes pour se reconnecter. Le message a expiré et le flux de données ne transfère pas ce message à la destination.
Le point de terminaison Kafka est une source de flux de données
Remarque
Il existe un problème connu lors de l’utilisation du point de terminaison Event Hubs comme source de flux de données où l’en-tête Kafka est endommagé lors de sa traduction en MQTT. Cela se produit uniquement si vous utilisez Event Hub via le client Event Hub qui utilise AMQP en arrière-plan. Par exemple "foo"="bar", le « foo » est traduit, mais la valeur devient « \xa1\x03bar ».
Quand un point de terminaison Kafka est une source de flux de données, les en-têtes utilisateur Kafka sont traduits en propriétés MQTT v5. Le tableau suivant décrit comment les en-têtes d’utilisateur Kafka sont traduits en propriétés MQTT v5.
| En-tête Kafka | Comportement traduit |
|---|---|
| Clé | Clé : « Clé » Valeur : copie de la clé à partir du message d’origine. |
| Timestamp | Clé : « Timestamp » Valeur : encodage UTF-8 du timestamp Kafka, qui est le nombre de millisecondes depuis l’époque Unix. |
Les paires clé-valeur d’en-tête utilisateur Kafka , à condition qu’elles soient toutes encodées en UTF-8, sont directement traduites en propriétés clé-valeur utilisateur MQTT.
UTF-8/Incompatibilités binaires
MQTT v5 ne peut prendre en charge que les propriétés basées sur UTF-8. Si un flux de données reçoit un message Kafka qui contient un ou plusieurs en-têtes non UTF-8, le flux de données :
- Supprime la ou les propriétés incriminées.
- Transfère le reste du message en suivant les règles précédentes.
Les applications qui nécessitent un transfert binaire dans les en-têtes source Kafka => les propriétés cible MQTT doivent d’abord les encoder en UTF-8, par exemple via Base64.
Incompatibilités de propriété >=64 Ko
Les propriétés MQTT v5 doivent être inférieures à 64 Ko. Si un flux de données reçoit un message Kafka qui contient un ou plusieurs en-têtes >= 64 Ko, le flux de données :
- Supprime la ou les propriétés incriminées.
- Transfère le reste du message en suivant les règles précédentes.
Traduction de propriétés lors de l’utilisation d’Event Hubs et de producteurs qui utilisent AMQP
Si un client transfère des messages à un point de terminaison source de flux de données Kafka effectuant l’une des actions suivantes :
- Envoi de messages à Event Hubs à l’aide de bibliothèques clientes telles que Azure.Messaging.EventHubs
- Utilisation directe d’AMQP
Il existe des nuances de traduction de propriétés à prendre en compte.
Vous devez effectuer l’une des opérations suivantes :
- Éviter d’envoyer des propriétés
- Si vous devez envoyer des propriétés, envoyez des valeurs encodées en UTF-8.
Lorsqu’Event Hubs traduit les propriétés d’AMQP en Kafka, les types encodés AMQP sous-jacents sont inclus dans son message. Pour plus d’informations sur le comportement, consultez Échange d’événements entre consommateurs et producteurs à l’aide de différents protocoles.
Dans l’exemple de code suivant, quand le point de terminaison de flux de données reçoit la valeur "foo":"bar", il reçoit la propriété en tant que <0xA1 0x03 "bar">.
using global::Azure.Messaging.EventHubs;
using global::Azure.Messaging.EventHubs.Producer;
var propertyEventBody = new BinaryData("payload");
var propertyEventData = new EventData(propertyEventBody)
{
Properties =
{
{"foo", "bar"},
}
};
var propertyEventAdded = eventBatch.TryAdd(propertyEventData);
await producerClient.SendAsync(eventBatch);
Le point de terminaison de flux de données ne peut pas transférer la propriété de charge utile <0xA1 0x03 "bar"> à un message MQTT, car les données ne sont pas en UTF-8. Toutefois, si vous spécifiez une chaîne en UTF-8, le point de terminaison de flux de données traduit la chaîne avant de l’envoyer sur MQTT. Si vous utilisez une chaîne UTF-8, le message MQTT aura "foo":"bar" en tant que propriétés utilisateur.
Seuls les en-têtes UTF-8 sont traduits. Par exemple, étant donné le scénario suivant où la propriété est définie en tant que float :
Properties =
{
{"float-value", 11.9 },
}
Le point de terminaison de flux de données ignore les paquets qui contiennent le champ "float-value".
Toutes les propriétés des données d’événement, y compris propertyEventData.correlationId, ne sont pas transférées. Pour plus d’informations, consultez Propriétés de l’utilisateur d’événement.
CloudEvents
Les CloudEvents sont un moyen de décrire les données d’événements de manière courante. Les paramètres CloudEvents sont utilisés pour envoyer ou recevoir des messages au format CloudEvents. Vous pouvez utiliser CloudEvents pour les architectures pilotées par les événements dans lesquelles différents services doivent communiquer les uns avec les autres dans des fournisseurs de cloud identiques ou différents.
Les options CloudEventAttributes sont Propagate ou CreateOrRemap.
Dans la page des paramètres du point de terminaison de flux de données de l’expérience des opérations, sélectionnez l’onglet Avancé, puis utilisez le champ Attributs d’événement cloud pour spécifier le paramètre CloudEvents.
Les sections suivantes décrivent la façon dont les propriétés CloudEvent sont propagées ou créées, et remappées.
Paramètre Propagate
Les propriétés CloudEvent sont transmises pour les messages qui contiennent les propriétés requises. Si le message ne contient pas les propriétés requises, il est transmis comme tel. Si les propriétés requises sont présentes, un préfixe ce_ est ajouté au nom de la propriété CloudEvent.
| Nom | Requis | Exemple de valeur | Nom de sortie | Valeur de sortie |
|---|---|---|---|---|
specversion |
Oui | 1.0 |
ce-specversion |
Transmise telle quelle |
type |
Oui | ms.aio.telemetry |
ce-type |
Transmise telle quelle |
source |
Oui | aio://mycluster/myoven |
ce-source |
Transmise telle quelle |
id |
Oui | A234-1234-1234 |
ce-id |
Transmise telle quelle |
subject |
Non | aio/myoven/telemetry/temperature |
ce-subject |
Transmise telle quelle |
time |
Non | 2018-04-05T17:31:00Z |
ce-time |
Transmise telle quelle. N’est pas ré-horodatée. |
datacontenttype |
Non | application/json |
ce-datacontenttype |
Remplacée par le type de contenu de données de sortie après la phase de transformation facultative. |
dataschema |
Non | sr://fabrikam-schemas/123123123234234234234234#1.0.0 |
ce-dataschema |
Si un schéma de transformation de données de sortie est donné dans la configuration de la transformation, dataschema est remplacé par le schéma de sortie. |
Paramètre CreateOrRemap
Les propriétés CloudEvent sont transmises pour les messages qui contiennent les propriétés requises. Si le message ne contient pas les propriétés requises, les propriétés sont générées.
| Nom | Requis | Nom de sortie | Valeur générée si elle est manquante |
|---|---|---|---|
specversion |
Oui | ce-specversion |
1.0 |
type |
Oui | ce-type |
ms.aio-dataflow.telemetry |
source |
Oui | ce-source |
aio://<target-name> |
id |
Oui | ce-id |
UUID généré dans le client cible |
subject |
Non | ce-subject |
Rubrique de sortie où le message est envoyé |
time |
Non | ce-time |
Générée en tant que RFC 3339 dans le client cible |
datacontenttype |
Non | ce-datacontenttype |
Remplacée par le type de contenu de données de sortie après la phase de transformation facultative |
dataschema |
Non | ce-dataschema |
Schéma défini dans le registre de schémas |
Étapes suivantes
Pour en savoir plus sur les flux de données, consultez Créer un flux de données.