Utiliser le modèle de formation approfondie Microsoft Cognitive Toolkit avec un cluster Azure HDInsight Spark
Dans cet article, vous suivez les étapes ci-dessous.
Exécuter un script personnalisé pour installer Microsoft Cognitive Toolkit sur un cluster Azure HDInsight Spark.
Charger un bloc-notes Jupyter Notebook sur le cluster Apache Spark pour voir comment appliquer un modèle entraîné d’apprentissage profond Microsoft Cognitive Toolkit aux fichiers d’un compte de Stockage Blob Azure avec l’API Spark Python (PySpark).
Conditions préalables requises
Un cluster Apache Spark sur HDInsight. Consultez Créer un cluster Apache Spark.
Connaissances sur l’utilisation des blocs-notes Jupyter Notebook avec Spark sur HDInsight. Pour plus d’informations, consultez Charger des données et exécuter des requêtes sur un cluster Apache Spark dans Azure HDInsight.
Comment fonctionne cette solution ?
Cette solution est divisée entre cet article et un bloc-notes Jupyter que vous chargez dans le cadre de cet article. Dans cet article, vous suivrez les étapes ci-dessous :
- Exécuter une action de script sur un cluster HDInsight Spark pour installer Microsoft Cognitive Toolkit et les packages Python.
- Chargez le bloc-notes Jupyter qui exécute la solution sur le cluster HDInsight Spark.
Les étapes restantes suivantes sont traitées dans le bloc-notes Jupyter.
- Charger des exemples d’images dans un RDD (Spark Resilient Distributed Dataset).
- Charger des modules et prédéfinir des paramètres
- Télécharger le jeu de données localement sur le cluster Spark
- Convertir le jeu de données en RDD
- Attribuer un score aux images à l’aide d’un modèle Cognitive Toolkit entraîné
- Télécharger le modèle Cognitive Toolkit entraîné vers le cluster Spark
- Définir les fonctions utilisées par les nœuds de travail
- Attribuer un score aux images sur les nœuds de travail
- Évaluer la précision du modèle
Installer Microsoft Cognitive Toolkit
Vous pouvez installer Microsoft Cognitive Toolkit sur un cluster Spark avec une action de script. L’action de script utilise des scripts personnalisés pour installer sur le cluster des composants qui ne sont pas disponibles par défaut. Vous pouvez utiliser le script personnalisé sur le portail Azure, avec le Kit de développement logiciel (SDK) .NET HDInsight ou Azure PowerShell. Vous pouvez également utiliser le script pour installer la boîte à outils lors de la création du cluster ou lorsque le cluster est prêt à fonctionner.
Dans cet article, nous utilisons le portail pour installer la boîte à outils une fois le cluster créé. Pour connaître d’autres façons d’exécuter le script personnalisé, consultez la page Personnaliser des clusters HDInsight avec une action de script.
Utilisation du portail Azure
Pour connaître les instructions liées à l’utilisation du portail Azure afin d'exécuter une action de script, consultez la page Personnaliser des clusters HDInsight avec une action de script. Veillez à fournir les entrées suivantes pour installer Microsoft Cognitive Toolkit. Utilisez les valeurs suivantes pour votre action de script :
| Propriété | Valeur |
|---|---|
| Type de script | - Personnalisé |
| Name | Installer MCT |
| URI de script bash | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| Types de nœud : | Head, Worker |
| Paramètres | None |
Charger le bloc-notes Jupyter sur le cluster Azure HDInsight Spark
Pour utiliser le Microsoft Cognitive Toolkit avec le cluster Azure HDInsight Spark, vous devez charger le bloc-notes Jupyter CNTK_model_scoring_on_Spark_walkthrough.ipynb sur le cluster Azure HDInsight Spark. Ce bloc-notes est disponible sur GitHub à l’adresse https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Téléchargez et décompressez https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Dans un navigateur web, accédez à
https://CLUSTERNAME.azurehdinsight.net/jupyter, oùCLUSTERNAMEest le nom de votre cluster.Dans le bloc-notes Jupyter, sélectionnez Charger dans l’angle supérieur droit, puis accédez au téléchargement et sélectionnez le fichier
CNTK_model_scoring_on_Spark_walkthrough.ipynb.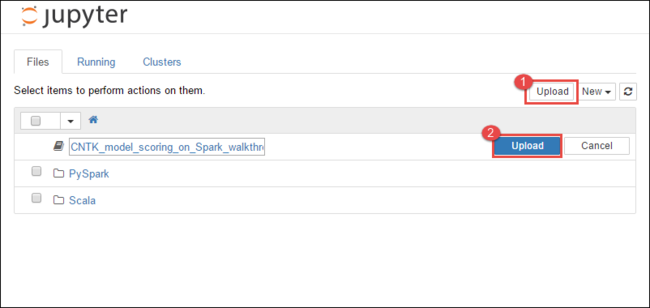
Sélectionnez Charger à nouveau.
Une fois le bloc-notes chargé, cliquez sur son nom, puis suivez les instructions qui se trouvent dans le bloc-notes même pour charger le jeu de données et suivre les instructions de l’article.
Voir aussi
Scénarios
- Apache Spark avec BI : effectuer une analyse interactive des données à l’aide de Spark sur HDInsight avec des outils décisionnels
- Apache Spark avec Machine Learning : Utiliser Spark dans HDInsight pour analyser la température d’un bâtiment à l’aide de données issues des systèmes de chauffage, de ventilation et de climatisation
- Apache Spark avec Machine Learning : utiliser Spark dans HDInsight pour prédire les résultats de l’inspection d’aliments
- Analyse des journaux de site web à l’aide d’Apache Spark dans HDInsight
- Analyse de données de télémétrie Application Insight avec Spark dans HDInsight
Création et exécution d’applications
- Créer une application autonome avec Scala
- Exécuter des tâches à distance avec Apache Livy sur un cluster Apache Spark
Outils et extensions
- Utilisation du plugin d’outils HDInsight pour IntelliJ IDEA pour créer et soumettre des applications Spark Scala
- Utiliser le plug-in Azure HDInsight Tools pour IntelliJ IDEA afin de déboguer des applications Apache Spark à distance
- Utiliser des blocs-notes Apache Zeppelin avec un cluster Apache Spark sur HDInsight
- Noyaux disponibles pour bloc-notes Jupyter dans un cluster Apache Spark pour HDInsight
- Utiliser des packages externes avec des blocs-notes Jupyter
- Install Jupyter on your computer and connect to an HDInsight Spark cluster (Installer Jupyter sur un ordinateur et se connecter au cluster Spark sur HDInsight)