Utiliser Azure Toolkit for IntelliJ pour déboguer des applications Apache Spark à distance dans HDInsight via VPN
Nous vous recommandons de déboguer les applications Apache Spark à distance via SSH. Pour obtenir des instructions, consultez Déboguer des applications Spark à distance sur un cluster HDInsight avec Azure Toolkit for IntelliJ via SSH.
Cet article fournit des instructions pas à pas sur l’utilisation d’HDInsight Tools dans le kit de ressources Azure pour IntelliJ afin de soumettre un travail Spark sur un cluster Spark HDInsight et effectuer un débogage à distance à partir de votre poste de travail. Pour effectuer ces tâches, vous devez suivre les étapes générales suivantes :
- Créer un réseau virtuel Azure de site à site ou de point à site. Les étapes décrites dans ce document supposent d’utiliser un réseau de site à site.
- Créer dans HDInsight un cluster Spark faisant partie du réseau virtuel de site à site.
- Vérifier la connectivité entre le nœud principal du cluster et votre poste de travail.
- Créer une application Scala dans IntelliJ IDEA, puis la configurer pour le débogage à distance.
- Exécuter et déboguer l’application.
Prérequis
- Un abonnement Azure. Pour plus d’informations, consultez Get a free trial of Azure (Obtenir un essai gratuit d’Azure).
- Un cluster Apache Spark dans HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight.
- SDK Oracle Java. Vous pouvez l’installer à partir du site web Oracle.
- IntelliJ IDEA. Cet article utilise la version 2017.1. Vous pouvez l’installer à partir du site web JetBrains.
- Outils HDInsight dans le kit de ressources Azure pour IntelliJ. HDInsight Tools pour IntelliJ est disponible dans le cadre du kit de ressources Azure pour IntelliJ. Pour obtenir des instructions sur l’installation du kit de ressources Azure, consultez Installer le kit de ressources Azure pour IntelliJ.
- Connectez-vous à votre abonnement Azure à partir d’IntelliJ IDEA. Suivez les instructions dans Utiliser Azure Toolkit for IntelliJ pour créer des applications Apache Spark pour un cluster HDInsight.
- Solution de contournement pour une exception. Quand l’application Spark Scala s’exécute pour le débogage à distance sur un ordinateur Windows, vous pouvez obtenir une exception. Cette exception est expliquée dans le document SPARK-2356 et se produit en raison d’un fichier WinUtils.exe manquant dans Windows. Pour contourner cette erreur, vous devez télécharger Winutils.exe vers un emplacement tel que C:\WinUtils\bin. Ajoutez une variable d’environnement HADOOP_HOME, puis définissez la valeur de la variable sur C\WinUtils.
Étape 1 : Création d'un réseau virtuel Azure
Suivez les instructions contenues dans les liens suivants pour créer un réseau virtuel Azure, puis vérifiez la connectivité entre votre ordinateur de bureau et le réseau virtuel :
- Créer un réseau virtuel avec une connexion VPN de site à site à l’aide du portail Azure
- Créer un réseau virtuel avec une connexion VPN de site à site à l’aide de PowerShell
- Configurer une connexion point à site à un réseau virtuel à l’aide de PowerShell
Étape 2 : Créer un cluster HDInsight Spark
Nous vous recommandons également de créer dans Azure HDInsight un cluster Apache Spark faisant partie du réseau virtuel Azure que vous avez créé. Utilisez les informations disponibles dans l’article Création de clusters Hadoop basés sur Linux dans HDInsight. Dans le cadre de la configuration facultative, sélectionnez le réseau virtuel Azure que vous avez créé à l’étape précédente.
Étape 3 : Vérifier la connectivité entre le nœud principal du cluster et votre poste de travail
Récupérez l’adresse IP du nœud principal. Ouvrez l’interface utilisateur Ambari du cluster. Dans le panneau du cluster, sélectionnez Tableau de bord.
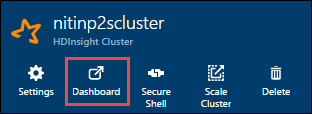
À partir de l’interface utilisateur Ambari, sélectionnez Hosts (Hôtes).

Vous obtenez une liste de nœuds principaux, de nœuds worker et de nœuds zookeeper. Les nœuds principaux ont le préfixe hn\*. Sélectionnez le premier nœud principal.
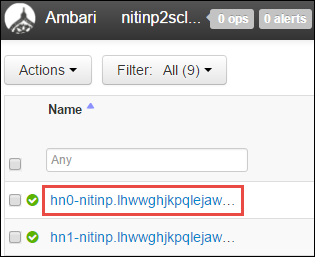
Dans le volet Résumé en bas de la page qui s’ouvre, copiez l’adresse IP du nœud principal et le nom d’hôte.
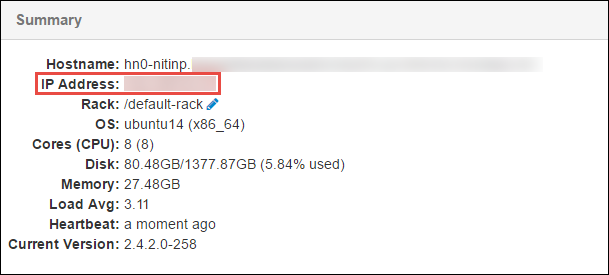
Ajoutez l’adresse IP et le nom d’hôte du nœud principal au fichier hosts de l’ordinateur sur lequel vous souhaitez exécuter et déboguer à distance le travail Spark. Cela vous permet de communiquer avec le nœud principal à l’aide de l’adresse IP et du nom d’hôte.
a. Ouvrez un fichier Bloc-notes avec des autorisations élevées. Dans le menu Fichier, sélectionnez Ouvrir et recherchez l’emplacement du fichier hosts. Sur un ordinateur Windows, l’emplacement est C:\Windows\System32\Drivers\etc\hosts.
b. Ajoutez les informations suivantes au fichier hosts :
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netÀ partir de l’ordinateur que vous avez connecté au réseau virtuel Azure utilisé par le cluster HDInsight, vérifiez que vous pouvez exécuter une commande ping sur les nœuds principaux aussi bien avec l’adresse IP qu’avec le nom d’hôte.
Utilisez SSH pour vous connecter au nœud principal du cluster en suivant les instructions fournies dans la section Connexion à un cluster HDInsight sous Linux. À partir du nœud principal du cluster, exécutez une commande ping sur l’adresse IP du poste de travail. Tester la connectivité aux deux adresses IP assignées à l’ordinateur :
- Une pour la connexion réseau
- Une pour le réseau virtuel Azure
Répétez ces étapes pour l’autre nœud principal.
Étape 4 : Créer une application Apache Spark Scala en utilisant HDInsight Tools dans Azure Toolkit for IntelliJ et la configurer pour le débogage à distance
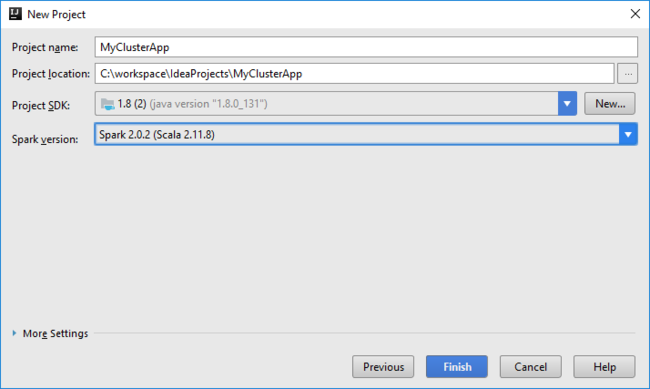
Ouvrez IntelliJ IDEA et créez un projet. Dans la boîte de dialogue Nouveau projet , procédez comme suit :
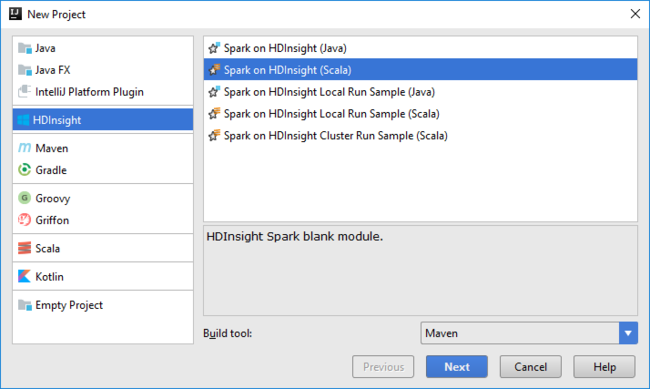
a. Sélectionnez HDInsight>Spark sur HDInsight (Scala) .
b. Sélectionnez Suivant.
Dans la boîte de dialogue Nouveau projet, effectuez les opérations suivantes, puis sélectionnez Terminer :
Entrez un nom et un emplacement pour le projet.
Dans la liste déroulante Project SDK (SDK du projet), sélectionnez Java 1.8 pour le cluster Spark 2.x, ou sélectionnez Java 1.7 pour le cluster Spark 1.x.
Dans la liste déroulante Version Spark, l’Assistant de création de projets Scala intègre la version correcte pour le SDK Spark et le SDK Scala. Si la version du cluster Spark est antérieure à la version 2.0, sélectionnez Spark 1.x. Sinon, sélectionnez Spark 2.x. Cet exemple utilise Spark 2.0.2 (Scala 2.11.8) .
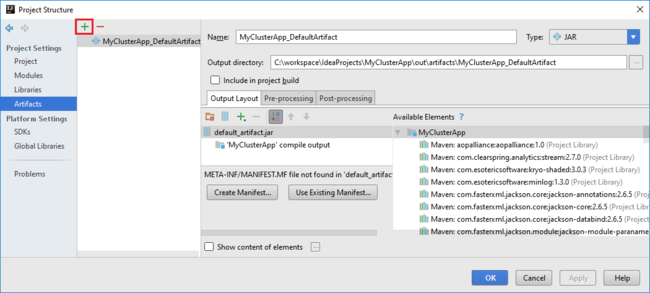
Le projet Spark crée automatiquement un artefact. Pour afficher l’artefact, procédez comme suit :
a. Dans le menu Fichier, sélectionnez Structure de projet.
b. Dans la boîte de dialogue Project Structure, sélectionnez Artifacts pour voir l’artefact par défaut qui a été créé. Vous pouvez également créer votre propre artefact en sélectionnant le signe plus ( + ).
Ajoutez des bibliothèques à votre projet. Pour ajouter une bibliothèque, effectuez les opérations suivantes :
a. Cliquez avec le bouton droit sur le nom du projet dans l’arborescence du projet, puis sélectionnez Open Module Settings(Ouvrir les paramètres du module).
b. Dans la boîte de dialogue Project Structure (Structure de projet), sélectionnez Libraries (Bibliothèques), sélectionnez le symbole ( + ), puis sélectionnez From Maven(À partir de Maven).
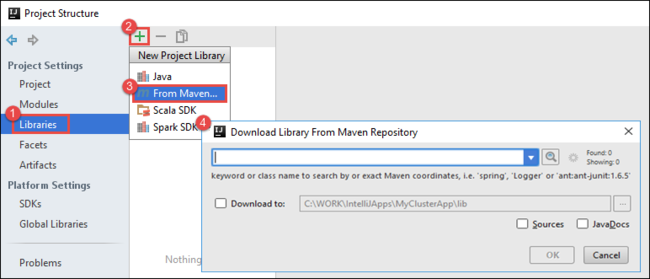
c. Dans la boîte de dialogue Download Library from Maven Repository (Télécharger la bibliothèque à partir du référentiel Maven), recherchez et ajoutez les bibliothèques suivantes :
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
Copiez
yarn-site.xmletcore-site.xmlà partir du nœud principal du cluster et ajoutez-les au projet. Exécutez les commandes suivantes pour copier les fichiers. Vous pouvez utiliser Cygwin pour exécuter les commandesscpsuivantes afin de copier les fichiers à partir des nœuds principaux du cluster :scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .Étant donné que nous avons déjà ajouté l’adresse IP et les noms d’hôtes des nœuds principaux du cluster pour le fichier hosts de notre ordinateur de bureau, nous pouvons utiliser les commandes
scpde la manière suivante :scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .Pour ajouter ces fichiers à votre projet, copiez-les dans le dossier /src dans l’arborescence de votre projet, par exemple
<your project directory>\src.Mettez à jour le fichier
core-site.xmlpour effectuer les modifications suivantes :a. Remplacez la clé chiffrée. Le fichier
core-site.xmlinclut la clé chiffrée du compte de stockage associé au cluster. Dans le fichiercore-site.xmlque vous avez ajouté au projet, remplacez la clé chiffrée par la clé de stockage réelle associée au compte de stockage par défaut. Pour plus d’informations, consultez Gérer les clés d’accès au compte de stockage.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b. Supprimez les entrées suivantes de
core-site.xml:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. Enregistrez le fichier .
Ajoutez la classe principale pour votre application. Dans l’Explorateur de projets, cliquez avec le bouton droit sur src, pointez sur Nouveau, puis sélectionnez Scala class (Classe Scala).
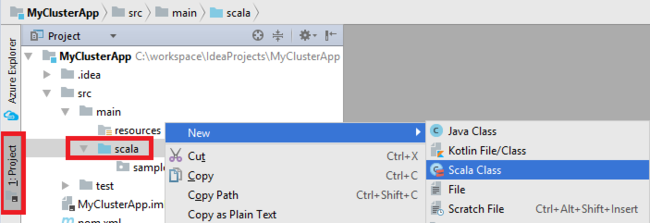
Dans la boîte de dialogue Create New Scala Class (Créer une classe Scala), indiquez un nom, dans la zone Kind (Genre), sélectionnez Objet, puis OK.
Collez le code suivant dans le fichier
MyClusterAppMain.scala. Ce code crée le contexte Spark et ouvre une méthodeexecuteJobà partir de l’objetSparkSample.import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Répétez les étapes 8 et 9 pour ajouter un nouvel objet Scala appelé
*SparkSample. Ajoutez le code suivant à cette classe. Ce code lit les données du fichier HVAC.csv (disponible dans tous les clusters HDInsight Spark). Il récupère les lignes qui contiennent uniquement un chiffre dans la septième colonne du fichier CSV, puis écrit la sortie dans /HVACOut sous le conteneur de stockage par défaut du cluster.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }Répétez les étapes 8 et 9 pour ajouter une nouvelle classe appelée
RemoteClusterDebugging. Cette classe implémente le framework de test Spark utilisée pour déboguer les applications. Ajoutez le code suivant à la classeRemoteClusterDebugging:import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Deux points importants sont à prendre en considération :
- Pour
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar"), assurez-vous que le fichier JAR de l’assembly Spark est disponible sur le stockage de cluster dans le chemin d’accès spécifié. - Pour
setJars, spécifiez l’emplacement où le fichier JAR de l’artefact est créé. En général, il s’agit du répertoire<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jar.
- Pour
Dans la classe
*RemoteClusterDebugging, cliquez avec le bouton droit sur le mot-clétest, puis sélectionnez Create RemoteClusterDebugging Configuration (Créer une configuration RemoteClusterDebugging).
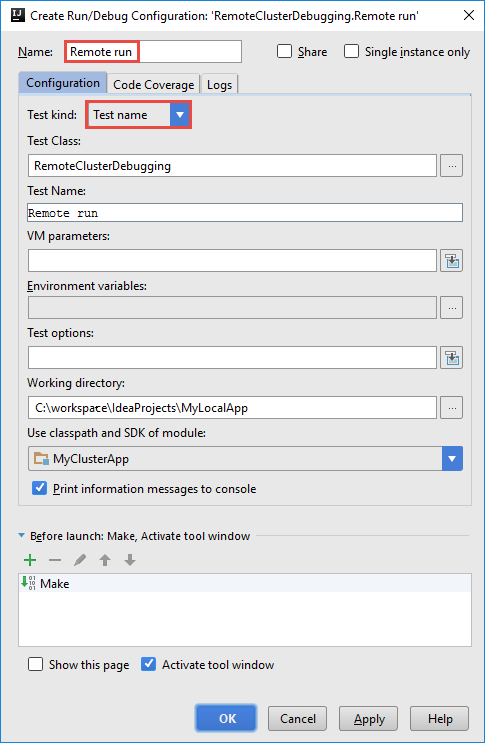
Dans la boîte de dialogue Create RemoteClusterDebugging Configuration (Créer une configuration RemoteClusterDebugging), fournissez un nom pour la configuration, puis sélectionnez Test kind(Type de test) pour Test name (Nom de test). Conservez les autres valeurs par défaut. Sélectionnez Apply (Appliquer), puis OK.
Une liste déroulante Remote run (Exécution à distance) s’affiche maintenant dans la barre de menus.

Étape 5 : Exécuter l’application en mode débogage
Dans votre projet IntelliJ IDEA, ouvrez
SparkSample.scalaet créez un point d’arrêt en regard deval rdd1. Dans le menu contextuel Create Breakpoint for (Créer un point d’arrêt pour), sélectionnez line in function executeJob (ligne dans la fonction executeJob).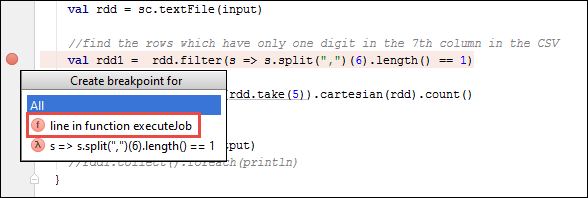
Pour exécuter l’application, cliquez sur le bouton Debug Run (Exécuter le débogage) situé en regard de la liste déroulante de configuration Remote Run (Exécution à distance).

Quand l’exécution du programme atteint le point d’arrêt, un onglet Debugger (Débogueur) apparaît dans le volet inférieur.
Pour ajouter un espion, sélectionnez l’icône ( + ).
Dans cet exemple, l’application s’est arrêtée avant que la variable
rdd1ne soit créée. À l’aide de cet espion, nous pouvons voir les cinq premières lignes dans la variablerdd. Sélectionnez Enter (Entrer).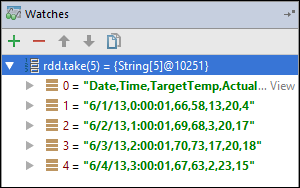
Dans l’image précédente, on constate que, au moment de l’exécution, il est possible d’interroger des téraoctets de données et de corriger la progression de votre application. Par exemple, dans la sortie illustrée ci-dessus, vous pouvez voir que la première ligne de la sortie est un en-tête. Sur la base de cette sortie, vous pouvez modifier votre code d’application pour ignorer la ligne d’en-tête, si nécessaire.
Vous pouvez maintenant sélectionner l’icône Resume Program (Reprendre le programme) pour poursuivre l’exécution de votre application.
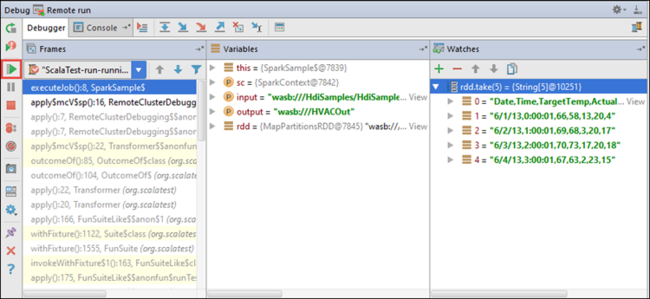
Si l’application se termine correctement, vous devez obtenir une sortie similaire à ce qui suit :
Étapes suivantes
Scénarios
- Apache Spark avec BI : Effectuer une analyse interactive des données à l’aide de Spark dans HDInsight avec les outils décisionnels
- Apache Spark avec Machine Learning : utiliser Spark dans HDInsight pour analyser la température de bâtiments à l’aide des données des systèmes HVAC
- Apache Spark avec Machine Learning : utiliser Spark dans HDInsight pour prédire les résultats de l’inspection d’aliments
- Analyse des journaux de site web à l’aide d’Apache Spark dans HDInsight
Création et exécution d’applications
- Créer une application autonome avec Scala
- Exécuter des tâches à distance avec Apache Livy sur un cluster Apache Spark
Outils et extensions
- Utiliser Azure Toolkit for IntelliJ afin de créer des applications Apache Spark pour un cluster HDInsight
- Utiliser Azure Toolkit for IntelliJ pour déboguer des applications Apache Spark à distance par SSH
- Utiliser HDInsight Tools dans Azure Toolkit for Eclipse pour créer des applications Apache Spark
- Utiliser des blocs-notes Apache Zeppelin avec un cluster Apache Spark sur HDInsight
- Noyaux accessibles à Jupyter Notebook dans un cluster Apache Spark pour HDInsight
- Utiliser des packages externes avec des blocs-notes Jupyter
- Install Jupyter on your computer and connect to an HDInsight Spark cluster (Installer Jupyter sur un ordinateur et se connecter au cluster Spark sur HDInsight)