Échec du débogage du travail Spark avec le kit de ressources Azure pour IntelliJ (préversion)
Cet article fournit des instructions pas à pas sur l’utilisation des outils HDInsight dans le kit de ressources Azure pour IntelliJ pour exécuter des applications de débogage d’échec Spark.
Prérequis
Le SDK Oracle Java. Ce tutoriel utilise Java version 8.0.202.
IntelliJ IDEA. Cet article utilise IntelliJ IDEA Community 2019.1.3.
Azure Toolkit for IntelliJ. Consultez Installation d’Azure Toolkit for IntelliJ.
Se connecter au cluster HDInsight. Consultez Se connecter au cluster HDInsight.
Explorateur Stockage Microsoft Azure. Consultez Téléchargez l’Explorateur Stockage Microsoft Azure.
Créez un projet avec le modèle de débogage
Créer un projet Spark 2.3.2 pour continuer le débogage, prenez l’exemple de fichier de débogage d’échec de travail dans ce document.
Ouvrez IntelliJ IDEA. Ouvrez la fenêtre Nouveau projet.
a. Sélectionnez Azure Spark/HDInsight dans le volet gauche.
b. Dans la fenêtre principale, sélectionnez Projet Spark avec échec de débogage de travail (préversion) (Scala) .
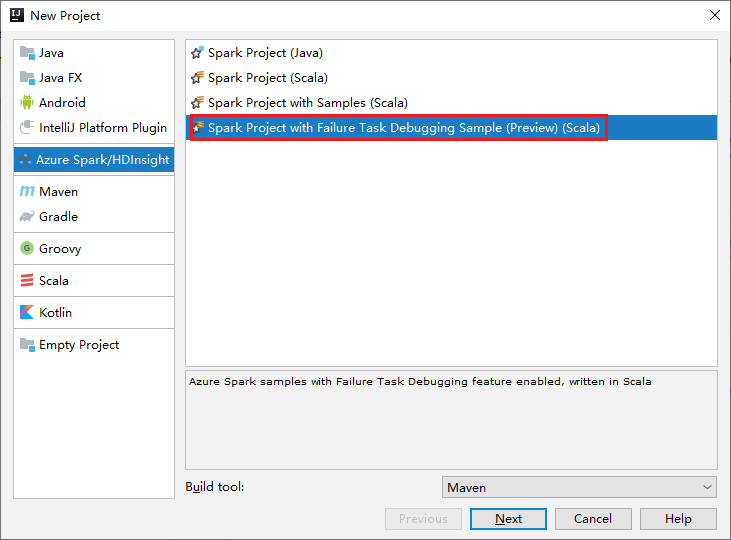
c. Sélectionnez Suivant.
Dans la boîte de dialogue New Project (Nouveau projet), effectuez les étapes suivantes :
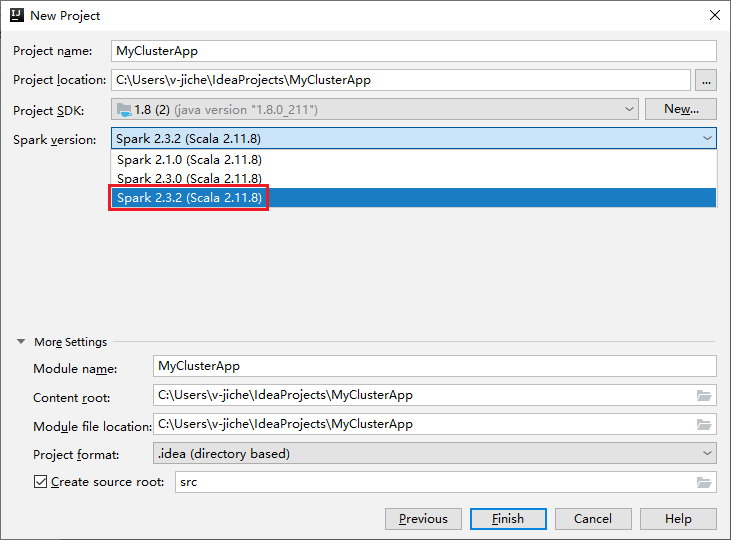
a. Entrez un nom de projet et un emplacement de projet.
b. Dans la liste déroulante Kit de développement logiciel de projet, sélectionnez Java 1.8 pour le cluster Spark 2.3.2.
c. Dans la liste déroulante Version Spark, sélectionnez Spark 2.3.2 (Scala 2.11.8) .
d. Sélectionnez Terminer.
Sélectionnez src>principal>scala pour ouvrir votre code dans le projet. Cet exemple utilise le script AgeMean_Div() .
Exécutez une application Spark Scala/Java sur un cluster HDInsight
Créez une application Spark Scala/Java, puis exécutez l’application sur un cluster Spark en procédant comme suit :
Cliquez sur Ajouter une configuration pour ouvrir la fenêtre Configurations d’exécution/de débogage.

Dans la boîte de dialogue Exécuter le débogage des configurations, sélectionnez le signe plus (+). Sélectionnez ensuite l’option Apache Spark on HDInsight.
Basculez vers l’onglet Remotely Run in Cluster (Exécuter à distance dans le cluster) . Entrez les informations sur le Nom, le Cluster Spark et le Nom principal de la classe. Nos outils prennent en charge le débogage avec Exécuteurs. Pour numExecutors, la valeur par défaut est 5, et vous ne pouvez pas définir une valeur supérieure à 3. Pour réduire le temps d’exécution, vous pouvez ajouter spark.yarn.maxAppAttempts dans les configurations de travail et définir la valeur sur 1. Cliquez sur le bouton OK pour enregistrer la configuration.
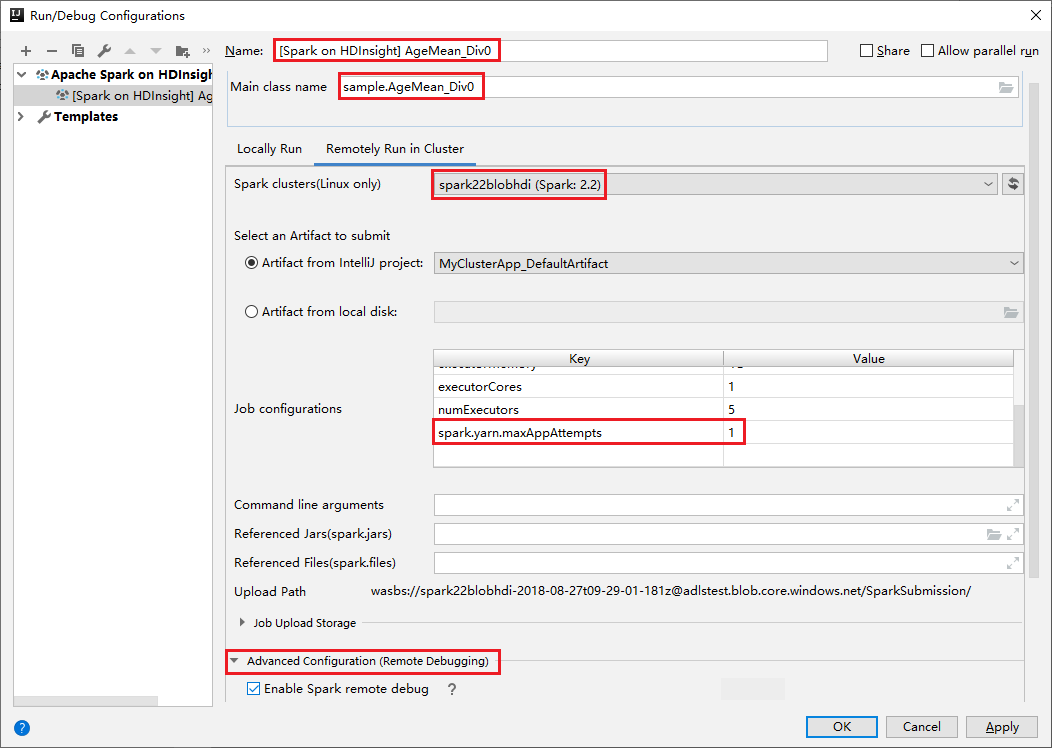
La configuration est maintenant enregistrée avec le nom fourni. Pour afficher les détails de configuration, sélectionnez le nom de configuration. Pour apporter des modifications, sélectionnez Modifier les configurations.
Une fois le paramétrage des configurations terminé, vous pouvez exécuter le projet sur le cluster à distance.

Vous pouvez vérifier l’ID de l’application dans la fenêtre de sortie.

Téléchargez le profil de travail ayant échoué
En cas d’échec de l’envoi du travail, vous pouvez télécharger le profil du travail ayant échoué sur la machine locale pour poursuivre le débogage.
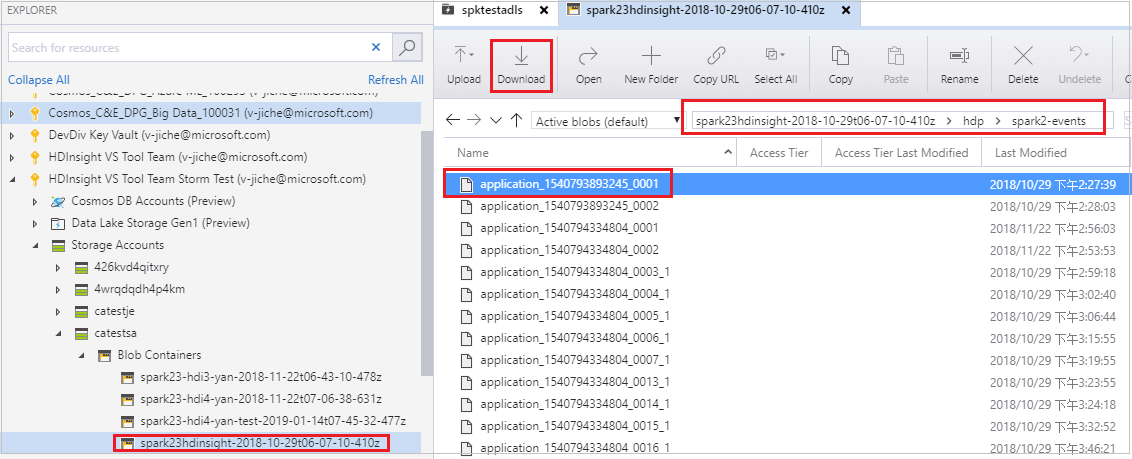
Ouvrez Explorateur Stockage Microsoft Azure, recherchez le compte HDInsight du cluster pour le travail ayant échoué, téléchargez les ressources de travail ayant échoué à partir de l’emplacement correspondant :\hdp\spark2-events\.spark-failures<ID d’application> dans un dossier local. La fenêtre des activités affiche la progression du téléchargement.
Configurez l’environnement de débogage local et déboguer en cas d’échec
Ouvrez le projet d’origine ou créez un nouveau projet et associez-le au code source d’origine. Seule la version de Spark 2.3.2 est prise en charge pour le débogage d’échec actuellement.
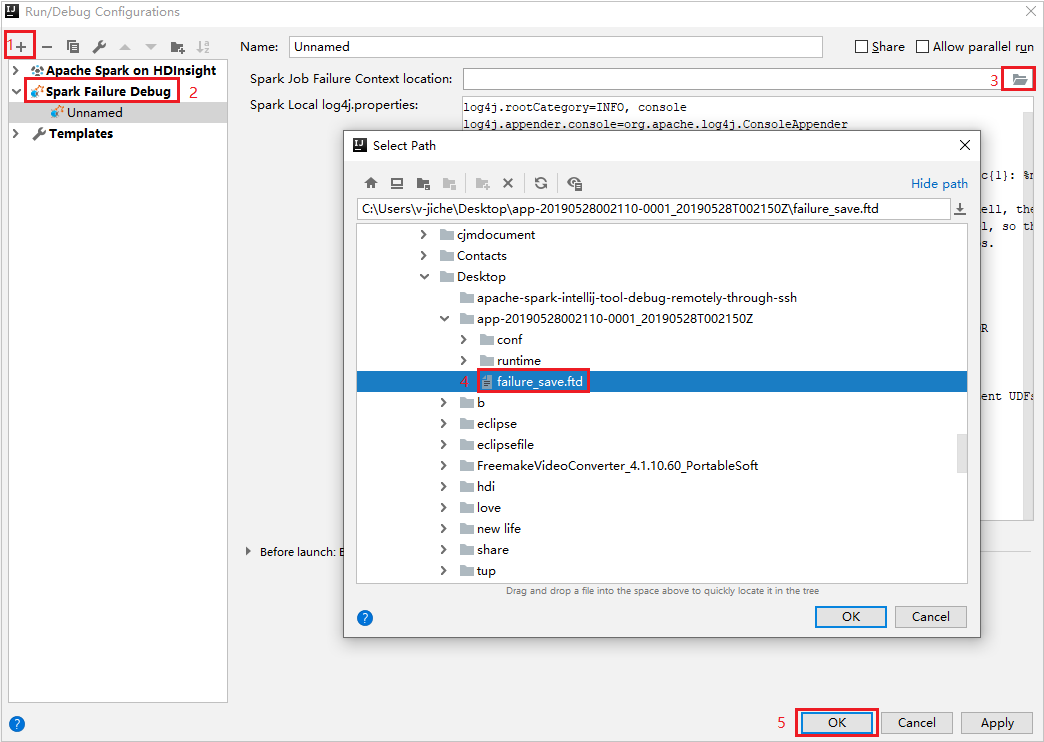
Dans IntelliJ IDEA, créez un fichier de configuration de débogage d’échec Spark, puis sélectionnez le fichier DFT dans les ressources de travail ayant échoué précédemment téléchargées pour le champ Emplacement du contexte de l’échec du travail Spark.
Cliquez sur le bouton d’exécution local dans la barre d’outils, l’erreur s’affiche dans la fenêtre Exécuter.
Définissez le point d’arrêt comme le journal l’indique, puis cliquez sur le bouton de débogage local pour effectuer le débogage local tout comme vos projets Scala/Java normaux dans IntelliJ.
Après le débogage, si le projet se termine correctement, vous pouvez renvoyer le travail ayant échoué à votre cluster Spark sur HDInsight.
Étapes suivantes
Scénarios
- Apache Spark avec BI : Effectuer une analyse interactive des données à l’aide de Spark dans HDInsight avec les outils décisionnels
- Apache Spark avec Machine Learning : utiliser Spark dans HDInsight pour analyser la température de bâtiments à l’aide des données des systèmes HVAC
- Apache Spark avec Machine Learning : utiliser Spark dans HDInsight pour prédire les résultats de l’inspection d’aliments
- Analyse des journaux de site web à l’aide d’Apache Spark dans HDInsight
Création et exécution d’applications
- Créer une application autonome avec Scala
- Exécuter des tâches à distance avec Apache Livy sur un cluster Apache Spark
Outils et extensions
- Utiliser Azure Toolkit for IntelliJ afin de créer des applications Apache Spark pour un cluster HDInsight
- Utiliser Azure Toolkit for IntelliJ pour déboguer des applications Apache Spark à distance par VPN
- Utiliser HDInsight Tools dans Azure Toolkit for Eclipse pour créer des applications Apache Spark
- Utiliser des blocs-notes Apache Zeppelin avec un cluster Apache Spark sur HDInsight
- Noyaux disponibles pour Jupyter Notebook dans le cluster Apache Spark pour HDInsight
- Utiliser des packages externes avec des blocs-notes Jupyter
- Install Jupyter on your computer and connect to an HDInsight Spark cluster (Installer Jupyter sur un ordinateur et se connecter au cluster Spark sur HDInsight)