Gérer des points de terminaison de mise en service des modèles
Cet article décrit comment gérer les points de terminaison de mise en service des modèles à l’aide de l’interface utilisateur Serving (Mise en service) et de l’API REST. Consultez Points de terminaison de mise en service dans la référence de l’API REST.
Pour créer des points de terminaison de service de modèle, utilisez l’une des options suivantes :
- Créer des points de terminaison pour des modèles personnalisés.
- Créez des points de terminaison de mise en service de modèles de base.
Obtenir l’état du point de terminaison du modèle
Dans l’interface utilisateur Serving (Mise en service), vous pouvez vérifier l’état d’un point de terminaison à partir de l’indicateur État du point de terminaison de mise en service en haut de la page des détails de votre point de terminaison.
Vérifiez l’état et les détails d’un point de terminaison de manière programmatique à l’aide de l’API REST ou du kit de développement logiciel (SDK) MLflow Deployments :
API REST
GET /api/2.0/serving-endpoints/{name}
L’exemple suivant crée un point de terminaison qui sert la première version du my-ads-model modèle inscrit dans le registre du modèle catalogue Unity. Vous devez fournir le nom complet du modèle, y compris le catalogue parent et le schéma tels que . catalog.schema.example-model
Dans l’exemple de réponse suivant, le champ state.ready est « PRÊT », ce qui signifie que le point de terminaison est prêt à recevoir du trafic. Le champ state.update_state est NOT_UPDATING et pending_config n’est plus retourné, car la mise à jour a été terminée avec succès.
{
"name": "unity-model-endpoint",
"creator": "customer@example.com",
"creation_timestamp": 1666829055000,
"last_updated_timestamp": 1666829055000,
"state": {
"ready": "READY",
"update_state": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "my-ads-model",
"entity_name": "myCatalog.mySchema.my-ads-model",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": false,
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "customer@example.com",
"creation_timestamp": 1666829055000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"permission_level": "CAN_MANAGE"
}
Kit de développement logiciel (SDK) de déploiements MLflow
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.get_endpoint(endpoint="chat")
assert endpoint == {
"name": "chat",
"creator": "alice@company.com",
"creation_timestamp": 0,
"last_updated_timestamp": 0,
"state": {...},
"config": {...},
"tags": [...],
"id": "88fd3f75a0d24b0380ddc40484d7a31b",
}
Arrêter un point de terminaison de mise en service de modèle
Vous pouvez arrêter temporairement un point de terminaison de mise en service de modèle et le démarrer ultérieurement. Lorsqu’un point de terminaison est arrêté, les ressources approvisionnées pour ce point sont arrêtées et le point de terminaison n’est pas en mesure de traiter les requêtes tant qu’il n’est pas redémarré. Seuls les points de terminaison qui servent des modèles personnalisés, ne sont pas optimisés pour l’itinéraire et n’ont pas de mises à jour en cours peuvent être arrêtés. Les points de terminaison arrêtés ne sont pas comptabilisés dans le quota de ressources. Les requêtes envoyées à un point de terminaison arrêté retournent une erreur 400.
Vous pouvez arrêter un point de terminaison dans la page de détails du point de terminaison, dans l’interface utilisateur Serving (Mise en service).
- Cliquez sur le point de terminaison à arrêter.
- Dans le coin supérieur droit, cliquez sur Arrêter.
Vous pouvez également arrêter un point de terminaison de mise en service de manière programmatique en utilisant l’API REST comme suit :
POST /api/2.0/serving-endpoints/{name}/config:stop
Lorsque vous êtes prêt à démarrer un point de terminaison de mise en service de modèle arrêté, vous pouvez le faire à partir de la page des détails du point de terminaison dans l’interface utilisateur Serving.
- Cliquez sur le point de terminaison à démarrer.
- Dans le coin supérieur droit, cliquez sur Démarrer.
Vous pouvez également démarrer un point de terminaison de mise en service arrêté de manière programmatique en utilisant l’API REST comme suit :
POST /api/2.0/serving-endpoints/{name}/config:start
Supprimer un point de terminaison de mise en service de modèles
Pour désactiver la mise en service pour un modèle, vous pouvez supprimer le point de terminaison sur lequel il est servi.
Vous pouvez supprimer un point de terminaison dans la page de détails du point de terminaison, dans l’interface utilisateur Serving (Mise en service).
- Cliquez sur Mise en service dans la barre latérale.
- Cliquez sur le point de terminaison à supprimer.
- Cliquez sur le menu kebab en haut et sélectionnez Supprimer.
Sinon, vous pouvez supprimer un point de terminaison de mise en service de manière programmatique à l’aide de l’API REST ou du Kit de développement logiciel (SDK) MLflow Deployments
API REST
DELETE /api/2.0/serving-endpoints/{name}
Kit de développement logiciel (SDK) de déploiements MLflow
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
client.delete_endpoint(endpoint="chat")
Déboguer votre point de terminaison de mise en service de modèles
Pour déboguer les problèmes liés au point de terminaison, vous pouvez extraire :
- Les journaux de build de conteneur de serveur de modèle
- Les journaux du serveur de modèle
Ces journaux sont également accessibles à partir de l’IU Points de terminaison sous l’onglet Journaux.
Pour les journaux de génération d’un modèle servi, vous pouvez utiliser la requête suivante. Pour plus d’informations, consultez le guide de débogage du service model.
GET /api/2.0/serving-endpoints/{name}/served-models/{served-model-name}/build-logs
{
“config_version”: 1 // optional
}
Pour les journaux du serveur de modèle pour un modèle de service, vous pouvez utiliser la requête suivante :
GET /api/2.0/serving-endpoints/{name}/served-models/{served-model-name}/logs
{
“config_version”: 1 // optional
}
Gérer les autorisations sur votre point de terminaison de service de modèles
Vous devez avoir au moins l’autorisation PEUT GÉRER sur un point de terminaison de service pour modifier les autorisations. Pour plus d’informations sur les niveaux d’autorisation, consultez ACL de point de terminaison de service.
Obtenez la liste des autorisations sur le point de terminaison de service.
databricks permissions get servingendpoints <endpoint-id>
Accorder à l’utilisateur(-trice)jsmith@example.com l’autorisation PEUT DEMANDER sur le point de terminaison de service.
databricks permissions update servingendpoints <endpoint-id> --json '{
"access_control_list": [
{
"user_name": "jsmith@example.com",
"permission_level": "CAN_QUERY"
}
]
}'
Vous pouvez également modifier les autorisations de point de terminaison de service à l’aide de l’API Autorisations.
Ajouter une stratégie budgétaire pour un point de terminaison de mise en service de modèle
Important
Cette fonctionnalité se trouve dans Préversion publique et n’est pas disponible pour les points de terminaison qui servent des modèles externes.
Les stratégies budgétaires permettent à votre organisation d’appliquer des étiquettes personnalisées sur l’usage sans serveur pour une attribution granulaire de la facturation. Si votre espace de travail utilise des politiques budgétaires pour gérer l’utilisation sans serveur, vous pouvez ajouter une politique budgétaire à vos points de terminaison de mise en service de modèle. Consultez Utilisation sans serveur d’attribut avec des stratégies budgétaires.
Pendant la création du point de terminaison du modèle, vous pouvez sélectionner la stratégie budgétaire de votre point de terminaison dans le menu stratégie budgétaire dans l’interface utilisateur de mise en service. Si vous disposez d’une stratégie budgétaire affectée à vous, tous les points de terminaison que vous créez sont affectés à cette stratégie budgétaire, même si vous ne sélectionnez pas de stratégie dans le menu Stratégie budgétaire.
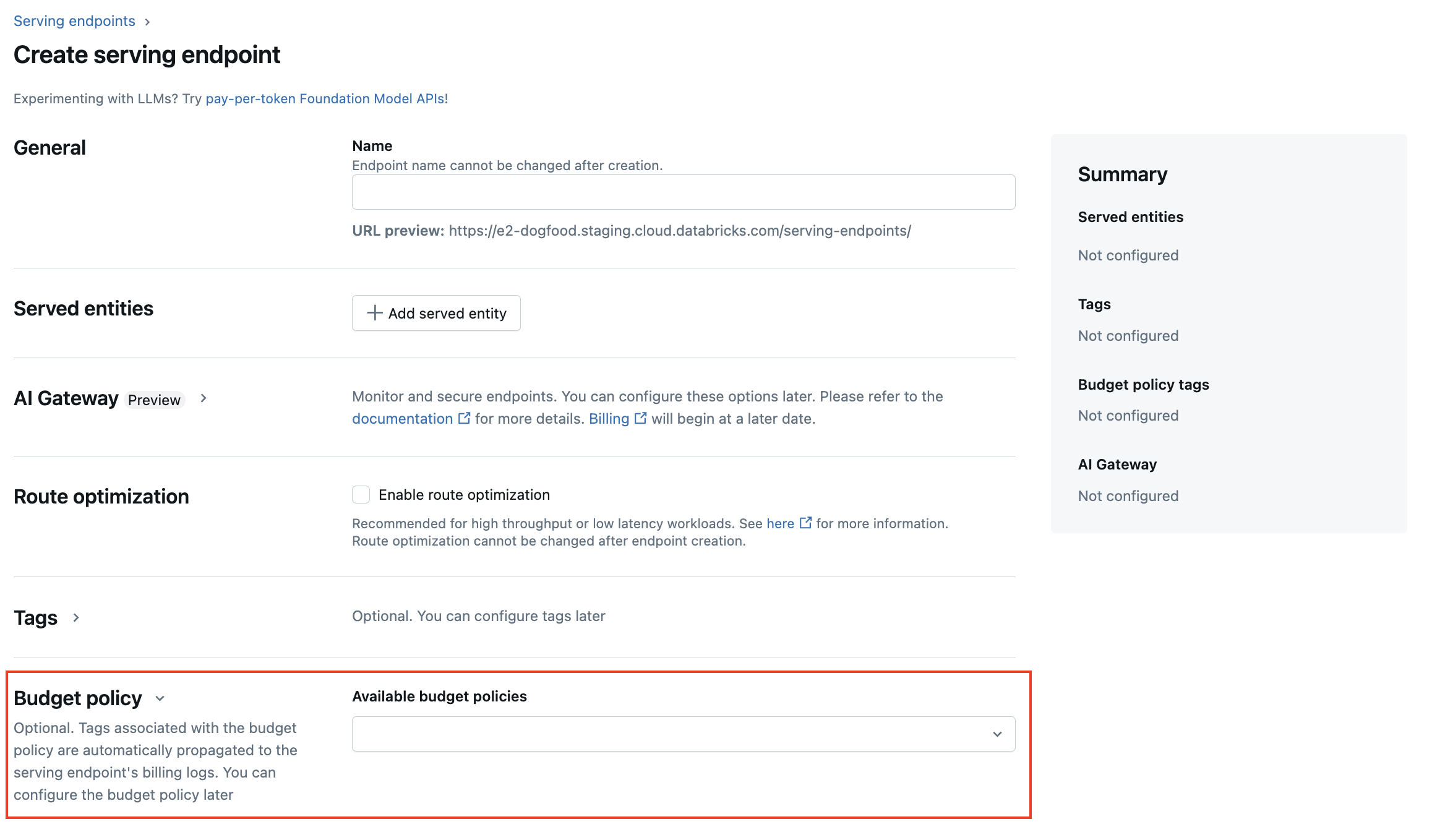
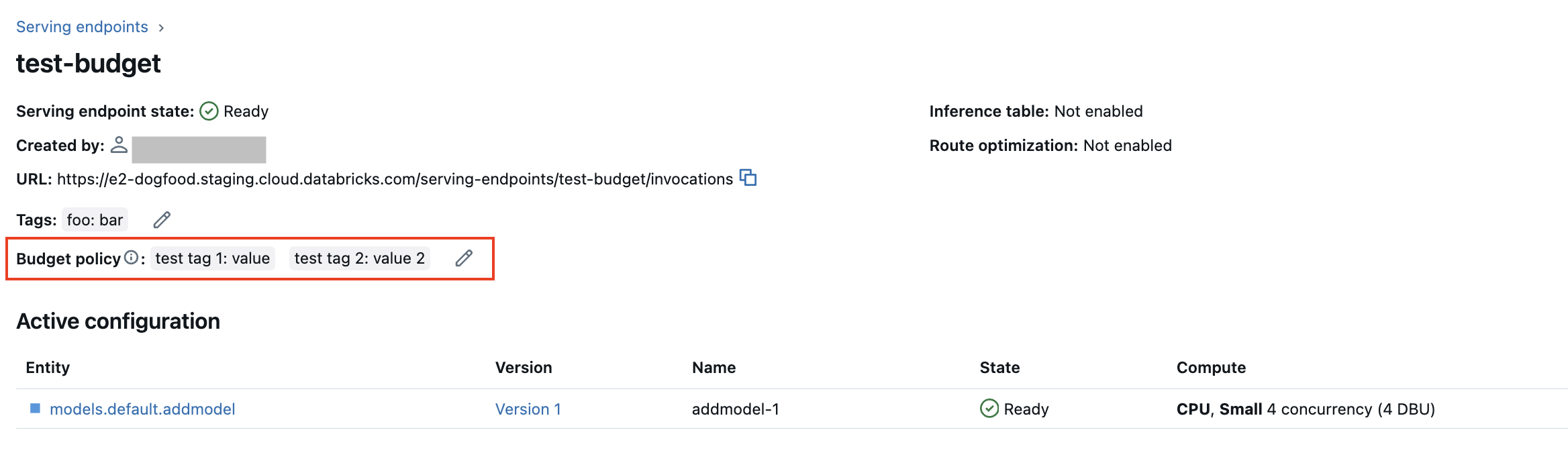
Si vous disposez d’autorisations MANAGE pour un point de terminaison existant, vous pouvez modifier ou ajouter une politique budgétaire à ce point de terminaison à partir de la page des détails du point de terminaison de l’interface utilisateur.
Remarque
Si vous avez reçu une politique budgétaire, vos points de terminaison existants ne sont pas automatiquement associés à votre politique. Vous devez mettre à jour manuellement les points de terminaison existants si vous souhaitez attacher une stratégie budgétaire à ces points de terminaison.
Obtenir un point de terminaison de schéma de mise en service de modèles
Important
La prise en charge du service des schémas de requête de point de terminaison est disponible en Préversion publique. Cette fonctionnalité est disponible dans Mise en service de modèles de régions.
Un schéma de requête de point d'accès est une description formelle du point de terminaison à l'aide de la spécification OpenAPI standard au format JSON. Il contient des informations sur le point de terminaison, notamment son chemin d'accès, des détails permettant de l'interroger, comme le format du corps de la requête et de la réponse, et le type de données pour chaque champ. Ces informations peuvent être utiles pour les scénarios de reproductibilité ou lorsque vous avez besoin d'informations sur le point de terminaison, mais que vous n'êtes pas le créateur ou le propriétaire du point de terminaison original.
Pour obtenir le schéma de point de terminaison de service du modèle, le modèle servi doit avoir une signature de modèle enregistrée et le point de terminaison doit être dans un état READY.
Les exemples suivants montrent comment obtenir par programme le schéma du point de terminaison du service de modèle à l'aide de l'API REST. Pour connaître les schémas de point de terminaison de service de fonctionnalités, consultez Qu’est-ce que la fonctionnalité de mise en service Databricks ?.
Le schéma renvoyé par l’API se présente sous la forme d’un objet JSON conforme à la spécification OpenAPI.
ACCESS_TOKEN="<endpoint-token>"
ENDPOINT_NAME="<endpoint name>"
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Détails de la réponse au schéma
La réponse est une spécification OpenAPI au format JSON, généralement incluant des champs tels que openapi, info, servers et paths. La réponse au schéma étant un objet JSON, vous pouvez l'analyser à l'aide de langages de programmation courants et générer du code client à partir de la spécification à l'aide d'outils tiers.
Vous pouvez également visualiser la spécification OpenAPI à l’aide d’outils tiers tels que Swagger Editor.
Les principaux champs de la réponse sont les suivants :
- Le champ
info.titleaffiche le nom du point de terminaison de service. - Le champ
serverscontient toujours un objet, généralement le champurlqui est l’URL de base du point de terminaison. - L’objet
pathsde la réponse contient tous les chemins d’accès pris en charge pour un point de terminaison. Les clés de l’objet sont l’URL du chemin d’accès. Chaquepathpeut prendre en charge plusieurs formats d’entrées. Ces entrées sont répertoriées dans le champoneOf.
Voici un exemple de réponse du schéma de point de terminaison :
{
"openapi": "3.1.0",
"info": {
"title": "example-endpoint",
"version": "2"
},
"servers": [{ "url": "https://example.databricks.com/serving-endpoints/example-endpoint"}],
"paths": {
"/served-models/vanilla_simple_model-2/invocations": {
"post": {
"requestBody": {
"content": {
"application/json": {
"schema": {
"oneOf": [
{
"type": "object",
"properties": {
"dataframe_split": {
"type": "object",
"properties": {
"columns": {
"description": "required fields: int_col",
"type": "array",
"items": {
"type": "string",
"enum": [
"int_col",
"float_col",
"string_col"
]
}
},
"data": {
"type": "array",
"items": {
"type": "array",
"prefixItems": [
{
"type": "integer",
"format": "int64"
},
{
"type": "number",
"format": "double"
},
{
"type": "string"
}
]
}
}
}
},
"params": {
"type": "object",
"properties": {
"sentiment": {
"type": "number",
"format": "double",
"default": "0.5"
}
}
}
},
"examples": [
{
"columns": [
"int_col",
"float_col",
"string_col"
],
"data": [
[
3,
10.4,
"abc"
],
[
2,
20.4,
"xyz"
]
]
}
]
},
{
"type": "object",
"properties": {
"dataframe_records": {
"type": "array",
"items": {
"required": [
"int_col",
"float_col",
"string_col"
],
"type": "object",
"properties": {
"int_col": {
"type": "integer",
"format": "int64"
},
"float_col": {
"type": "number",
"format": "double"
},
"string_col": {
"type": "string"
},
"becx_col": {
"type": "object",
"format": "unknown"
}
}
}
},
"params": {
"type": "object",
"properties": {
"sentiment": {
"type": "number",
"format": "double",
"default": "0.5"
}
}
}
}
}
]
}
}
}
},
"responses": {
"200": {
"description": "Successful operation",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"predictions": {
"type": "array",
"items": {
"type": "number",
"format": "double"
}
}
}
}
}
}
}
}
}
}
}
}