Qu’est-ce que Databricks Feature Serving ?
Databricks Feature Serving met les données de la plateforme Databricks à disposition des modèles ou des applications déployés en dehors d’Azure Databricks. Les points de terminaison Feature Serving se mettent automatiquement à l’échelle pour s’adapter au trafic en temps réel et fournissent un service à haute disponibilité et à faible latence pour servir les fonctionnalités. Cette page décrit comment configurer et utiliser Feature Serving. Pour découvrir un tutoriel étape par étape, consultez Déployer et interroger un point de terminaison de mise en service de fonctionnalités.
Lorsque vous utilisez le service de modèles Mosaic AI pour servir un modèle créé à l’aide de fonctionnalités de Databricks, le modèle recherche et transforme automatiquement les fonctionnalités pour les demandes d’inférence. Avec Databricks Feature Serving, vous pouvez servir des données structurées pour les applications de génération augmentée de récupération (RAG), ainsi que les fonctionnalités requises pour d’autres applications, telles que les modèles servis en dehors de Databricks ou toute autre application nécessitant des fonctionnalités basées sur les données dans Unity Catalog.
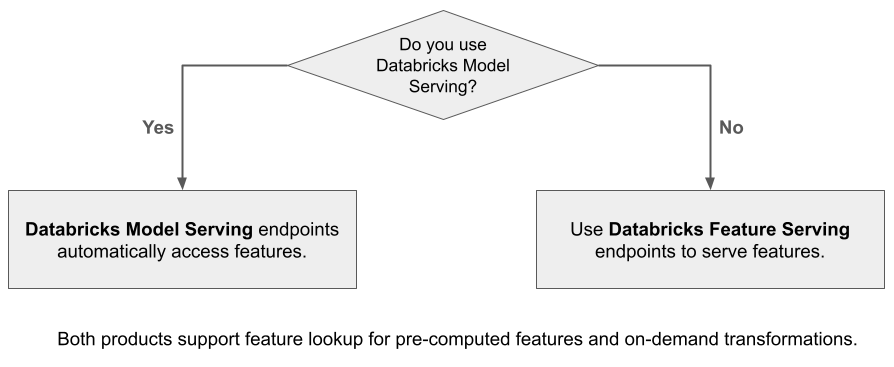
Pourquoi utiliser Feature Serving ?
Databricks Feature Serving fournit une interface unique qui sert des fonctionnalités pré-matérialisées et à la demande. Cela comprend également les avantages suivants :
- Simplicité. Databricks gère l’infrastructure. Avec un seul appel d’API, Databricks crée un environnement de mise en service prêt pour la production.
- Haute disponibilité et scalabilité. Les points de terminaison Feature Serving effectuent automatiquement un scale-up et un scale-down pour s’adapter au volume des demandes de service.
- Sécurité. Les points de terminaison sont déployés dans une limite réseau sécurisée et se servent d’un calcul dédié qui se termine à la suppression du point de terminaison ou sa mise à l’échelle vers zéro.
Exigences
- Databricks Runtime 14.2 ML ou une version ultérieure.
- Pour utiliser l’API Python, Feature Serving nécessite
databricks-feature-engineeringversion 0.1.2 ou ultérieure, qui est intégré à Databricks Runtime 14.2 ML. Pour les versions antérieures de Databricks Runtime ML, installez manuellement la version requise à l’aide de%pip install databricks-feature-engineering>=0.1.2. Si vous utilisez un notebook Databricks, redémarrez le noyau Python en exécutant cette commande dans une nouvelle cellule :dbutils.library.restartPython(). - Pour utiliser le SDK Databricks, Feature Serving nécessite
databricks-sdkversion 0.18.0 ou ultérieure. Pour installer manuellement la version requise, utilisez%pip install databricks-sdk>=0.18.0. Si vous utilisez un notebook Databricks, redémarrez le noyau Python en exécutant cette commande dans une nouvelle cellule :dbutils.library.restartPython().
Databricks Feature Serving fournit une interface utilisateur et plusieurs options programmatiques pour créer, mettre à jour, interroger et supprimer des points de terminaison. Cet article contient des instructions pour chacune des options suivantes :
- Interface utilisateur Databricks
- API REST
- API Python
- Kit de développement logiciel (SDK) Databricks
Pour utiliser l’API REST ou le Kit de développement logiciel (SDK) des déploiements MLflow, vous devez avoir un jeton d’API Databricks.
Important
À titre de meilleure pratique de sécurité pour les scénarios de production, Databricks vous recommande d’utiliser des jetons OAuth machine à machine pour l’authentification en production.
Pour les tests et le développement, Databricks recommande d’utiliser un jeton d’accès personnel appartenant à des principaux de service et non pas à des utilisateurs de l’espace de travail. Pour créer des jetons d’accès pour des principaux de service, consultez la section Gérer les jetons pour un principal de service.
Authentification pour Feature Serving
Pour plus d’informations sur l’authentification, consultez Autoriser l’accès aux ressources Azure Databricks.
Créez une classe FeatureSpec
FeatureSpec est un ensemble de fonctions et de caractéristiques définies par l’utilisateur. Vous pouvez combiner des fonctions et des caractéristiques dans un FeatureSpec.
FeatureSpecs sont stockés (dans) et gérés par Unity Catalog et apparaissent dans l’Explorateur de catalogues.
Les tables spécifiées dans un FeatureSpec doivent être publiées dans une table en ligne ou un magasin tiers en ligne. Consultez Utiliser des tables en ligne pour la mise à disposition de caractéristiques en temps réel ou Magasins tiers en ligne.
Vous devez utiliser le package databricks-feature-engineering pour créer un FeatureSpec.
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates a - b.
input_bindings={"a": "ytd_spend", "b": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Créer un point de terminaison
Le FeatureSpec définit le point de terminaison. Pour plus d’informations, consultez Créer des points de terminaison de service de modèle personnalisé, la documentation de l’API Pythonou la documentation SDK Databricks pour plus d’informations.
Remarque
Pour les charges de travail sensibles à la latence ou nécessitant un nombre élevé de requêtes par seconde, la Mise en service de modèles offre une optimisation des routes sur les points de terminaison de mise en service de modèles personnalisés, consultez Configurer l’optimisation des routes sur les points de terminaison de service.
API REST
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
Kit de développement logiciel (SDK) Databricks – Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
API Python
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
Pour afficher le point de terminaison, cliquez sur Mise en service dans la barre latérale gauche de l’interface utilisateur Databricks. Lorsque l’état est Prêt, le point de terminaison est prêt à répondre aux requêtes. Pour en savoir plus sur le service de modèles Mosaic AI, consultez Service de modèles Mosaic AI.
Obtenir un point de terminaison
Vous pouvez utiliser le SDK Databricks ou l’API Python pour obtenir les métadonnées et l’état d’un point de terminaison.
Kit de développement logiciel (SDK) Databricks – Python
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
API Python
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Obtenir un schéma de point de terminaison
Vous pouvez utiliser l’API REST pour obtenir le schéma d’un point de terminaison. Pour obtenir des informations sur le schéma de point de terminaison, consultez Obtenir un schéma de point de terminaison de mise en service de modèles.
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Interroger un point de terminaison
Vous pouvez utiliser l’API REST, le SDK de déploiements MLflow ou l’interface utilisateur de service pour interroger un point de terminaison.
Le code suivant montre comment configurer les informations d’identification et créer le client pendant l’utilisation du kit de développement logiciel (SDK) des déploiements MLflow.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Remarque
En guise de bonne pratique de sécurité, quand vous vous authentifiez avec des outils, systèmes, scripts et applications automatisés, Databricks recommande d’utiliser des jetons d’accès personnels appartenant à des principaux de service et non des utilisateurs de l’espace de travail. Pour créer des jetons d’accès pour des principaux de service, consultez la section Gérer les jetons pour un principal de service.
Interroger un point de terminaison à l’aide d’API
Cette section inclut des exemples d’interrogation d’un point de terminaison à l’aide de l’API REST ou du SDK de déploiements MLflow.
API REST
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
Kit de développement logiciel (SDK) de déploiements MLflow
Important
L’exemple suivant utilise l’API predict() à partir du Kit SDK de déploiements MLflow. Cette API est expérimentale et sa définition est susceptible de changer.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
Interroger un point de terminaison à l’aide de l’interface utilisateur
Vous pouvez interroger un point de terminaison de mise en service directement à partir de l’interface utilisateur de Mise en service. L’interface utilisateur inclut des exemples de code générés que vous pouvez utiliser pour interroger le point de terminaison.
Dans la barre latérale gauche de l’espace de travail Azure Databricks, cliquez sur Mise en service.
Cliquez sur le point de terminaison à interroger.
En haut à droite de l’écran, cliquez sur Point de terminaison de requête.
Dans la zone Requête, saisissez le corps de la demande au format JSON.
Cliquez sur Envoyer la demande.
// Example of a request body.
{
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]
}
La boîte de dialogue du point de terminaison de requête contient des exemples de code générés dans curl, Python et SQL. Cliquez sur les onglets pour afficher et copier l’exemple de code.
Pour copier le code, cliquez sur l’icône de copie en haut à droite de la zone de texte.
Mettre à jour un point de terminaison
Vous pouvez mettre à jour un point de terminaison à l’aide de l’API REST, du SDK Databricks ou de l’interface utilisateur de Mise en service.
Mettre à jour un point de terminaison à l’aide d’API
API REST
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Kit de développement logiciel (SDK) Databricks – Python
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
Mettre à jour un point de terminaison à l’aide de l’interface utilisateur
Pour utiliser l’interface utilisateur de Mise en service, procédez comme suit :
- Dans la barre latérale gauche de l’espace de travail Azure Databricks, cliquez sur Mise en service.
- Dans la table, cliquez sur le nom du point de terminaison à mettre à jour. L’écran du point de terminaison s’affiche.
- En haut à droite de l’écran, cliquez sur Modifier le point de terminaison.
- Dans la boîte de dialogue Modifier le point de terminaison de mise en service, modifiez les paramètres de point de terminaison en fonction des besoins.
- Cliquez sur Mettre à jour pour enregistrer vos modifications.

Supprimer un point de terminaison
Avertissement
Cette action est irréversible.
Vous pouvez supprimer un point de terminaison à l’aide de l’API REST, du SDK Databricks, de l’API Python, ou de l’interface utilisateur de mise en service.
Supprimer un point de terminaison à l’aide d’API
API REST
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Kit de développement logiciel (SDK) Databricks – Python
workspace.serving_endpoints.delete(name="customer-features")
API Python
fe.delete_feature_serving_endpoint(name="customer-features")
Supprimer un point de terminaison à l’aide de l’interface utilisateur
Procédez comme suit pour supprimer un point de terminaison à l’aide de l’interface utilisateur de mise en service :
- Dans la barre latérale gauche de l’espace de travail Azure Databricks, cliquez sur Mise en service.
- Dans la table, cliquez sur le nom du point de terminaison à supprimer. L’écran du point de terminaison s’affiche.
- En haut à droite de l’écran, cliquez sur le menu des trois points
 et sélectionnez Supprimer.
et sélectionnez Supprimer.

Surveiller l’intégrité d’un point de terminaison
Pour plus d’informations sur les journaux et les métriques disponibles pour les points de terminaison Feature Serving, consultez Surveiller la qualité des modèles et l’intégrité des points de terminaison.
Contrôle d’accès
Pour obtenir plus d’informations sur les autorisations sur des points de terminaison Feature Serving, consultez Gérer les autorisations sur votre point de terminaison de mise en service de modèles.
Exemple de bloc-notes
Ce notebook suivant illustre comment utiliser le Kit de développement logiciel (SDK) Databricks pour créer un point de terminaison de mise en service des fonctionnalités en utilisant des tables en ligne Databricks.