Workflows LLMOps sur Azure Databricks
Cet article complète Flux de travail MLOps sur Databricks en ajoutant des informations spécifiques aux flux de travail LLMOps. Pour plus d’informations, consultez The Big Book of MLOps.
Comment le flux de travail MLOps change-t-il pour les LLM ?
Les LLM sont une classe de modèles de traitement du langage naturel (NLP) qui ont considérablement dépassé leurs prédécesseurs en termes de taille et de performances parmi une variété de tâches, telles que la réponse à des questions ouvertes, la synthèse et l’exécution d’instructions.
Le développement et l’évaluation des LLM diffèrent de manières importantes par rapport aux modèles ML traditionnels. Cette section récapitule brièvement certaines des principales propriétés des LLM et les implications pour MLOps.
| Propriétés clés des machines virtuelles LLM | Implications pour MLOps |
|---|---|
| Les LLM sont disponibles sous de nombreuses formes. - Modèles propriétaires généraux et OSS qui sont accessibles à l’aide d’API payantes. - Modèles open source prêts à l’emploi qui varient d’une application générale à une application spécifique. - Modèles personnalisés qui ont été affinés pour des applications spécifiques. - Applications pré-formées personnalisées. |
Processus de développement : les projets se développent souvent de manière incrémentielle, à partir de modèles existants, tiers ou open source et se terminant par des modèles ajustés personnalisés. |
| De nombreux LLM prennent des requêtes et des instructions générales en langage naturel en tant qu’entrée. Ces requêtes peuvent contenir des invites soigneusement conçues pour susciter les réponses souhaitées. | Processus de développement : concevoir des modèles de texte pour l’interrogation de LLM est souvent une partie importante du développement de nouveaux pipelines LLM. Packaging d’artefacts ML : de nombreux pipelines LLM utilisent des points de terminaison de service LLM ou LLM existants. La logique ML développée pour ces pipelines peut se concentrer sur les modèles, agents ou chaînes d’invite au lieu du modèle lui-même. Les artefacts ML empaquetés et promus en production peuvent être ces pipelines plutôt que des modèles. |
| De nombreux LLM peuvent recevoir des invites avec des exemples, un contexte ou d’autres informations, afin de permettre de répondre à la requête. | Infrastructure de service : lors de l’augmentation des requêtes LLM avec contexte, vous pouvez utiliser des outils supplémentaires tels que des bases de données vectorielles pour rechercher un contexte pertinent. |
| Les API tierces fournissent des modèles propriétaires et open source. | Gouvernance des API : utiliser la gouvernance centralisée des API permet de basculer facilement entre les fournisseurs d’API. |
| Les LLM sont des modèles d’apprentissage profond très volumineux, allant souvent de gigaoctets à des centaines de gigaoctets. | Infrastructure de service : les LLM peuvent nécessiter des GPU pour le service de modèle en temps réel et un stockage rapide pour les modèles qui doivent être chargés dynamiquement. Compromis coût/performances : étant donné que les modèles plus volumineux nécessitent davantage de calcul et sont plus coûteux à servir, des techniques de réduction de la taille et du calcul du modèle peuvent être requises. |
| Les LLM sont difficiles à évaluer à l’aide de mesures ML traditionnelles, car il n’existe souvent aucune « bonne » réponse unique. | Retour humain : le retour humain est essentiel pour l’évaluation et le test des LLM. Vous devez incorporer le retour des utilisateurs directement dans le processus MLOps, notamment pour les tests, la surveillance et le réglage ultérieur. |
Points communs entre MLOps et LLMOps
De nombreux aspects des processus MLOps ne changent pas pour les LLM. Par exemple, les instructions suivantes s’appliquent également aux LLM :
- Utilisez des environnements distincts pour le développement, la gestion intermédiaire et la production.
- Utiliser Git pour la gestion de versions.
- Gérez le développement de modèles avec MLflow et utilisez des Modèles dans le catalogue Unity pour gérer le cycle de vie du modèle.
- Stocker des données dans une architecture Lakehouse avec des tables Delta.
- Votre infrastructure CI/CD existante ne doit pas nécessiter de modifications.
- La structure modulaire de MLOps reste la même, avec des pipelines pour la caractérisation, la formation du modèle, l’inférence de modèle, et ainsi de suite.
Diagrammes de l'architecture de référence
Cette section utilise deux applications basées sur LLM pour illustrer certains des ajustements apportés à l’architecture de référence du MLOps traditionnel. Les diagrammes montrent l’architecture de production pour 1) une application de génération augmentée de récupération (RAG) à l’aide d’une API tierce, et 2) une application RAG à l’aide d’un modèle ajusté auto-hébergé. Les deux diagrammes montrent une base de données vectorielle facultative ; cet élément peut être remplacé en interrogeant directement le LLM via le point de terminaison Model Serving.
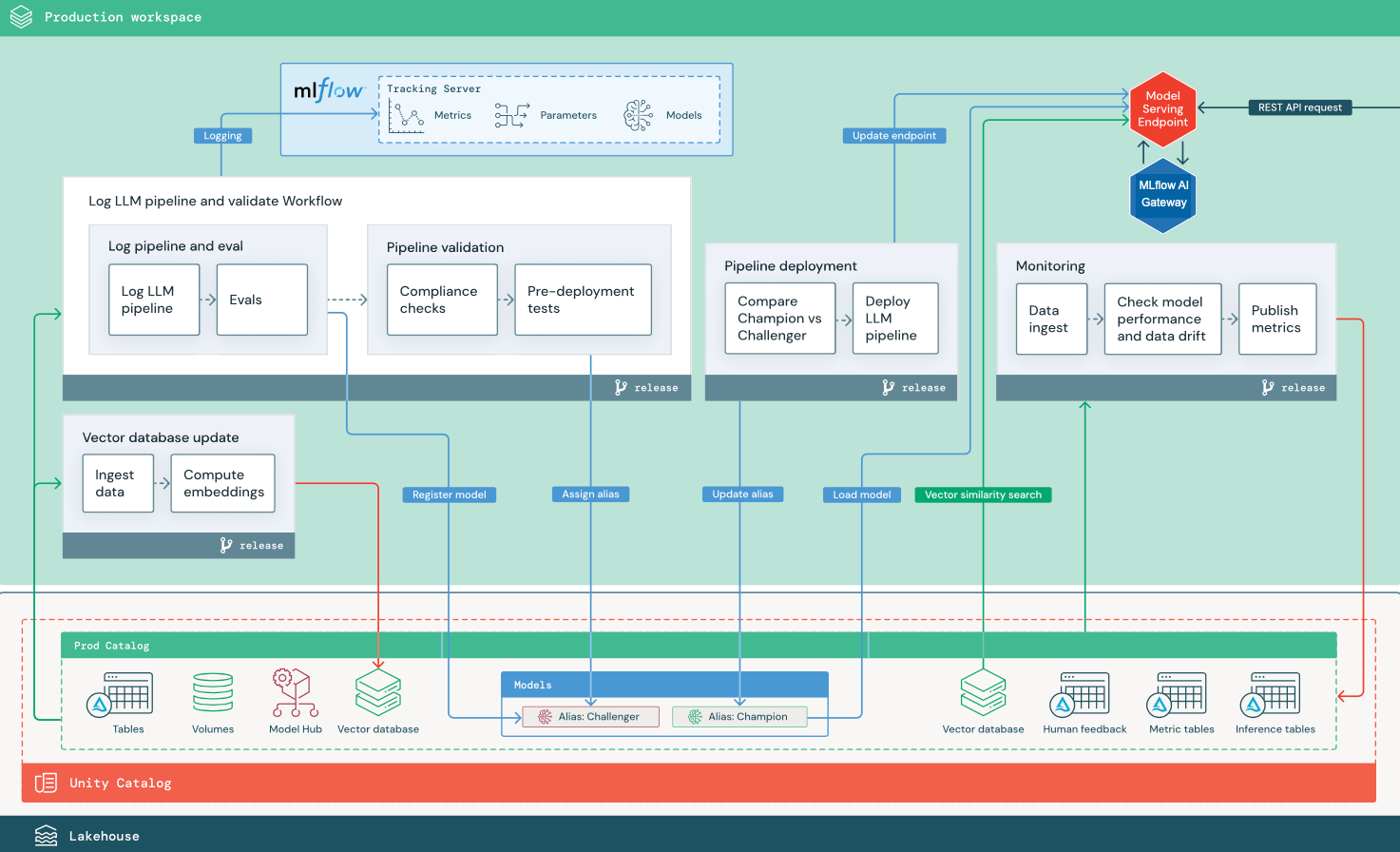
RAG avec une API LLM tierce
Le diagramme montre une architecture de production pour une application RAG qui se connecte à une API LLM tierce à l’aide de modèles Databricks externes.
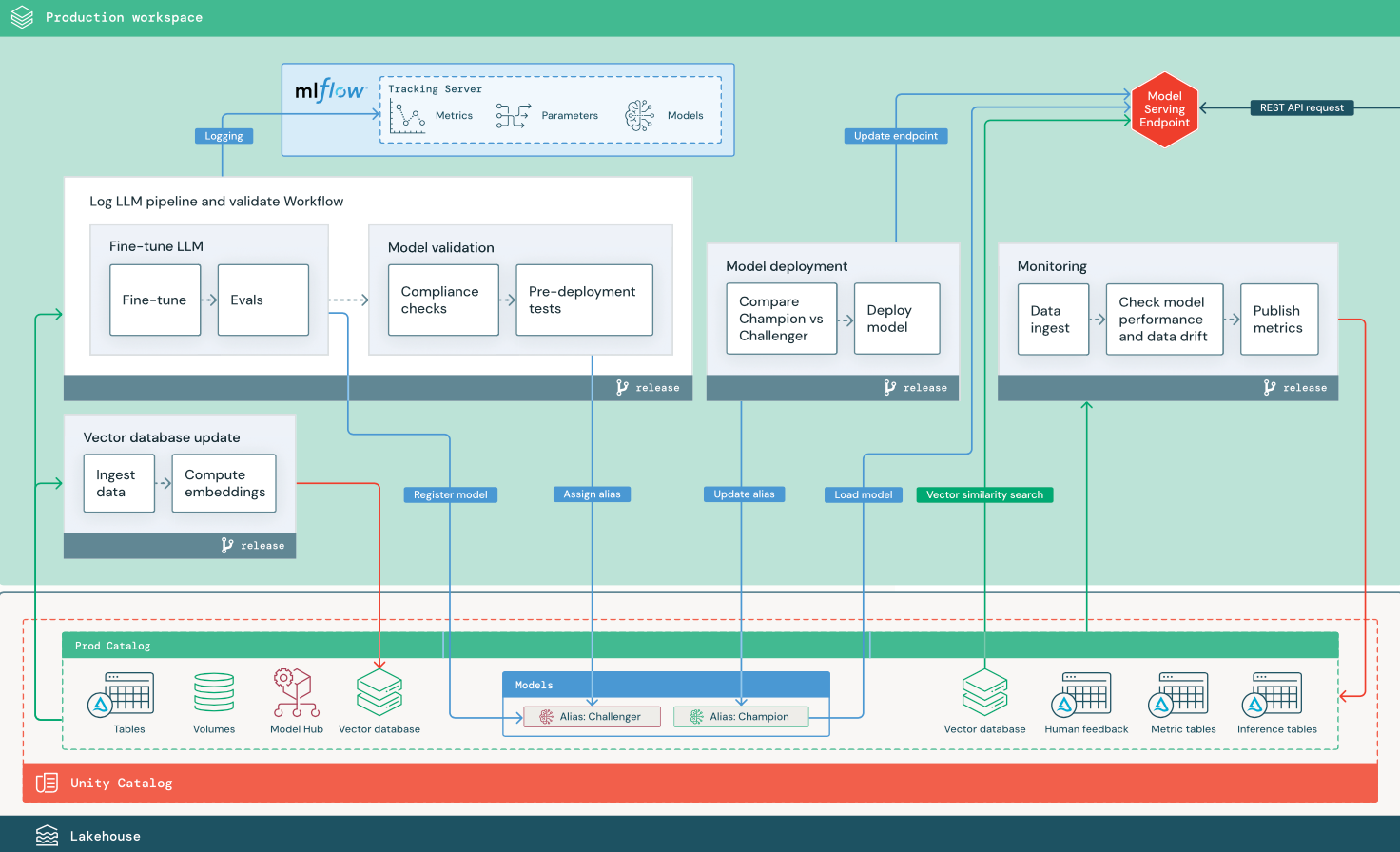
RAG avec un modèle open source ajusté
Le diagramme montre une architecture de production pour une application RAG qui ajuste un modèle open source.
Modifications LLMOps apportées à l’architecture de production MLOps
Cette section met en évidence les principales modifications apportées à l’architecture de référence MLOps pour les applications LLMOps.
Hub de modèle
Les applications LLM utilisent souvent des modèles existants et pré-formés sélectionnés à partir d’un hub de modèle interne ou externe. Le modèle peut être utilisé tel qu’il est ou ajusté.
Databricks comprend une sélection de modèles de fondation pré-formés de haute qualité dans le catalogue Unity et sur la place de marché Databricks. Vous pouvez utiliser ces modèles pré-formés pour accéder à des capacités d'IA de pointe, ce qui vous permet ainsi d'économiser du temps et des dépenses liées à la création de vos propres modèles personnalisés. Pour plus d’informations, consultez les Modèles pré-formés dans le catalogue et la place de marché Unity.
Base de données vectorielles
Certaines applications LLM utilisent des bases de données vectorielles pour des recherches de similarité rapide, par exemple pour fournir des connaissances de contexte ou de domaine dans les requêtes LLM. Databricks fournit une fonctionnalité de recherche vectorielle intégrée qui vous permet d’utiliser n’importe quelle table Delta dans le catalogue Unity en tant que base de données vectorielle. L’index de recherche vectorielle se synchronise automatiquement avec la table Delta. Pour plus d’informations, consultez Recherche vectorielle.
Vous pouvez créer un artefact de modèle qui encapsule la logique, afin de récupérer des informations à partir d’une base de données vectorielle et qui fournit les données retournées en tant que contexte au LLM. Vous pouvez ensuite journaliser le modèle à l’aide de la saveur du modèle MLflow LangChain ou PyFunc.
Ajuster le LLM
Étant donné que les modèles LLM sont coûteux et fastidieux à créer à partir de zéro, les applications LLM ajustent souvent un modèle existant pour améliorer ses performances dans un scénario particulier. Dans l’architecture de référence, l’ajustement et le déploiement de modèles sont représentés sous forme de travaux Databricks distincts. La validation d’un modèle ajusté avant le déploiement est souvent un processus manuel.
Databricks fournit un réglage précis du modèle Foundation, qui vous permet d’utiliser vos propres données pour personnaliser un LLM existant afin d’optimiser ses performances pour votre application spécifique. Pour plus d’informations, consultez Réglage précis du modèle Foundation.
Mise en service de modèles
Dans le RAG à l’aide d’un scénario d’API tierce, une modification architecturale importante est que le pipeline LLM effectue des appels d’API externes, du point de terminaison Model Serving aux API LLM internes ou tierces. Cela ajoute de la complexité, de la latence potentielle et de la gestion des informations d’identification supplémentaires.
Databricks fournit Mosaic AI Model Serving, qui fournit une interface unifiée pour déployer, régir et interroger des modèles IA. Pour plus d’informations, consultez Mosaic AI Model Serving.
Retour d'expérience humain dans la surveillance et l’évaluation
Les boucles de retour humain sont essentielles dans la plupart des applications LLM. Les commentaires humains doivent être gérés comme d’autres données, idéalement intégrés à la surveillance en fonction du streaming en temps quasi réel.
L’application de révision d’infrastructure de l’agent Mosaic AI vous aide à recueillir des retours d’expérience des réviseurs humains. Pour plus de détails, consultez Obtenir des commentaires sur la qualité d’une application agentique.