Calculer des caractéristiques à la demande avec des fonctions Python définies par l’utilisateur
Cet article explique comment créer et utiliser des fonctionnalités à la demande dans Azure Databricks.
Pour utiliser des caractéristiques à la demande, votre espace de travail doit prendre en charge Unity Catalog et vous devez utiliser Databricks Runtime 13.3 LTS ML ou ultérieur.
Présentation des caractéristiques à la demande
Le terme « à la demande » fait référence à des caractéristiques dont les valeurs ne sont pas connues à l’avance, mais qui sont calculées au moment de l’inférence. Dans Azure Databricks, vous utilisez des fonctions Python définies par l’utilisateur (UDF) pour spécifier comment calculer les caractéristiques à la demande. Ces fonctions sont régies par Unity Catalog et sont découvrables dans Catalog Explorer.
Spécifications
- Pour utiliser une fonction définie par l’utilisateur (UDF) pour créer un jeu d’apprentissage ou pour créer un point de terminaison de mise en service des fonctionnalités, vous devez disposer du privilège
USE CATALOGsur le cataloguesystemdans le catalogue Unity.
Workflow
Pour calculer une caractéristique à la demande, spécifiez une fonction Python définie par l’utilisateur (UDF) qui décrit comment calculer les valeurs de la caractéristique.
- Pendant l’entraînement, fournissez cette fonction et ses liaisons d’entrée au paramètre
feature_lookupsde l’APIcreate_training_set. - Vous devez enregistrer le modèle entraîné à l’aide de la méthode
log_modeldu magasin de caractéristiques. De cette façon, le modèle évalue automatiquement les caractéristiques à la demande quand il est utilisé pour l’inférence. - Pour le scoring par lots, l’API
score_batchcalcule et retourne automatiquement toutes les valeurs de caractéristiques, y compris celles à la demande. - Quand vous servez un modèle avec le service de modèles Mosaic AI, le modèle utilise automatiquement la fonction UDF Python afin de calculer les caractéristiques à la demande pour chaque demande de scoring.
Créer une fonction UDF Python
Vous pouvez créer une fonction UDF Python dans un notebook ou dans Databricks SQL.
Par exemple, l’exécution du code suivant dans une cellule de notebook crée la fonction UDF Python example_feature dans le catalogue main et le schéma default.
%sql
CREATE FUNCTION main.default.example_feature(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
Après avoir exécuté le code, vous pouvez parcourir l’espace de noms à trois niveaux dans Catalog Explorer pour voir la définition de la fonction :
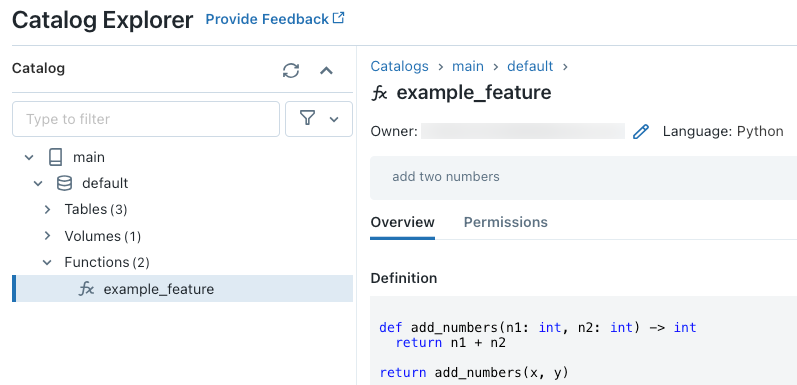
Pour plus d’informations sur la création de fonctions UDF Python, consultez Inscrire une fonction UDF Python auprès d’Unity Catalog et le manuel du langage SQL.
Comment gérer les valeurs de fonctionnalité manquantes
Lorsqu’une fonction UDF Python dépend du résultat d’une fonctionnalité Lookup, la valeur retournée si la clé de recherche demandée est introuvable dépend de l’environnement. Lors de l’utilisation de score_batch, la valeur retournée est None. Lors de l’utilisation du service en ligne, la valeur retournée est float("nan").
Le code suivant est un exemple de la manière de traiter les deux cas.
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
Entraîner un modèle avec des caractéristiques à la demande
Pour entraîner le modèle, utilisez une FeatureFunction qui est passée à l’API create_training_set dans le paramètre feature_lookups.
L’exemple de code suivant utilise la fonction UDF Python main.default.example_feature définie dans la section précédente.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
Consigner le modèle et l’inscrire auprès d’Unity Catalog
Les modèles empaquetés avec des métadonnées de caractéristique peuvent être inscrits auprès d’Unity Catalog. Les tables de caractéristiques utilisées pour créer le modèle doivent être stockées dans Unity Catalog.
Pour vous assurer que le modèle évalue automatiquement les caractéristiques à la demande quand il est utilisé pour l’inférence, vous devez définir l’URI du registre, puis consigner le modèle, comme suit :
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
Si la fonction UDF Python qui définit les caractéristiques à la demande importe des packages Python, vous devez spécifier ces packages à l’aide de l’argument extra_pip_requirements. Par exemple :
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Limitation
Les caractéristiques à la demande peuvent générer en sortie tous les types de données pris en charge par le magasin de caractéristiques, sauf MapType et ArrayType.
Exemples de notebooks : caractéristiques à la demande
Le notebook suivant présente un exemple montrant comment effectuer l’apprentissage et le scoring d’un modèle qui utilise une caractéristique à la demande.
Notebook de base de démonstration des caractéristiques à la demande
Le notebook suivant présente un exemple de modèle de recommandation de restaurant. L’emplacement du restaurant est recherché à partir d’une table Databricks en ligne. La localisation actuelle de l’utilisateur est envoyée dans le cadre de la demande de scoring. Le modèle utilise une caractéristique à la demande pour calculer la distance en temps réel entre l’utilisateur et le restaurant. Cette distance est ensuite utilisée comme entrée du modèle.