Étendue de la plateforme lakehouse
Infrastructure de plateforme d’IA et de données modernes
Pour discuter de l’étendue de la plateforme de Data intelligence de Databricks, il est utile de définir d’abord une infrastructure de base pour la plateforme moderne de données et d’IA :
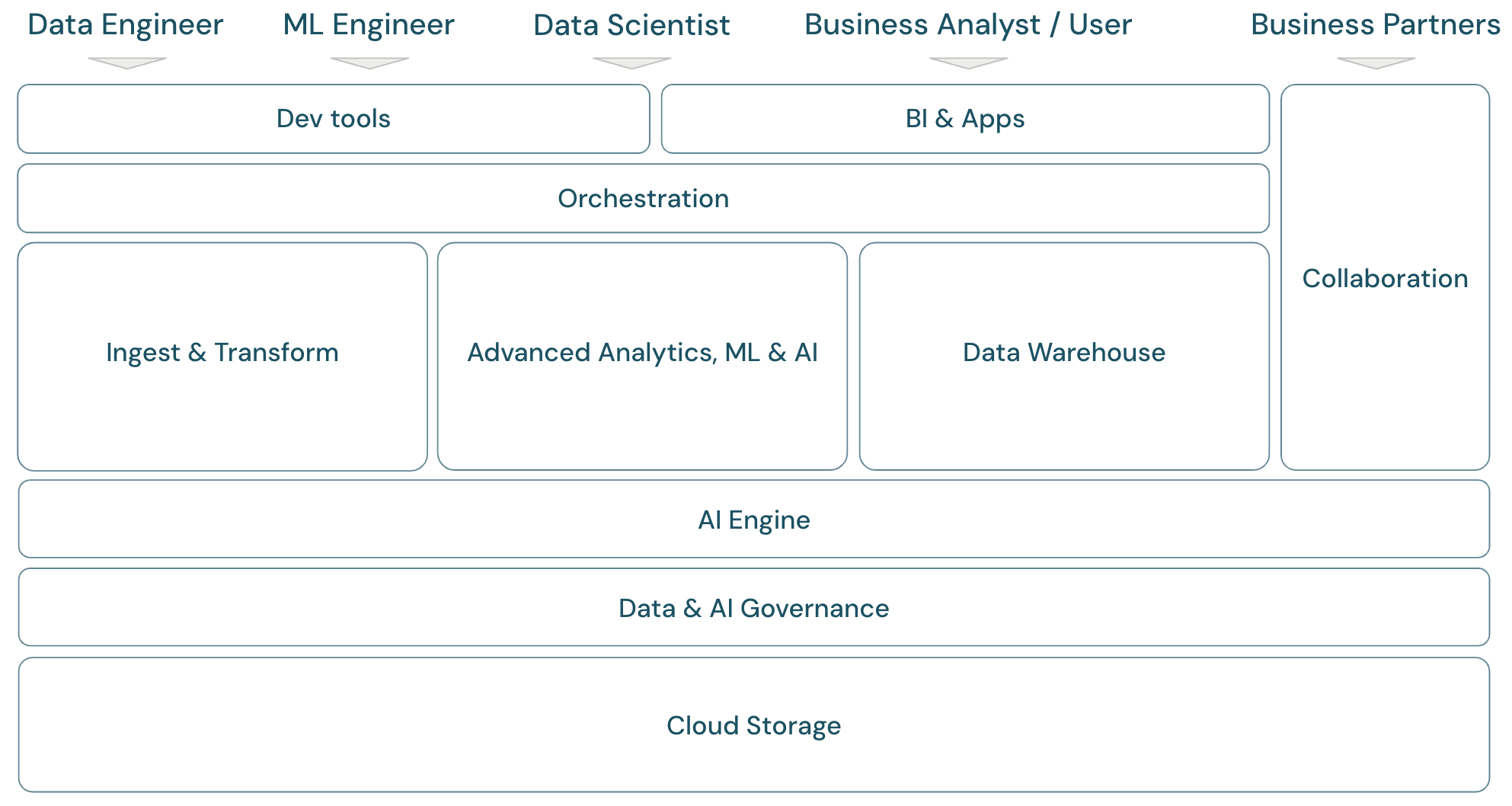
Vue d’ensemble de l’étendue lakehouse
La plateforme de Data Intelligence de Databricks couvre l’infrastructure complète d’une plateforme de données moderne. Elle repose sur l’architecture lakehouse et est alimentée par un moteur de Data Intelligence qui reconnaît les caractéristiques uniques de vos données. C’est une base ouverte et unifiée pour les charges de travail ETL, ML/IA et DWH/BI, et utilise Unity Catalog comme solution centrale de gouvernance des données et de l’IA.
Personas de l’infrastructure de plateforme
L’infrastructure couvre les membres principaux de l’équipe de données (personas) qui travaillent avec les applications de l’infrastructure :
- Les ingénieurs de données fournissent aux data scientifiques et aux analystes d’entreprise des données précises et reproductibles pour une prise de décision rapide et des informations en temps réel. Ils implémentent des processus ETL hautement cohérents et fiables pour accroître la confiance et la confiance des utilisateurs dans les données. Ils garantissent que les données sont bien intégrées aux différents piliers de l’entreprise et suivent généralement les meilleures pratiques en matière d’ingénierie logicielle.
- Les scientifiques des données associent expertise analytique et compréhension des métiers pour transformer les données en perspectives stratégiques et en modèles prédictifs. Ils sont capables de traduire les défis commerciaux en solutions basées sur des données, que ce soit par des analyses rétrospectives ou par des modèles prédictifs tournés vers l’avenir. En s’appuyant sur des techniques de modélisation des données et d’apprentissage automatique, ils conçoivent, développent et déploient des modèles qui dévoilent des schémas, des tendances et des prévisions à partir des données. Ils agissent comme un pont, en convertissant des données complexes en histoires compréhensibles, en s’assurant que les parties prenantes non seulement comprennent mais aussi peuvent agir sur les suggestions basées sur les données, ce qui conduit à une approche centrée sur les données pour résoudre les problèmes au sein d’une organisation.
- Les ingénieurs ML (ingénieurs en apprentissage automatique) dirigent l’application pratique de la science des données dans les produits et les solutions en construisant, en déployant et en maintenant des modèles d’apprentissage automatique. Ils se concentrent principalement sur l'aspect technique du développement et du déploiement des modèles. Les ingénieurs ML assurent la robustesse, la fiabilité et l’évolutivité des systèmes d’apprentissage automatique dans des environnements réels, en relevant les défis liés à la qualité des données, à l’infrastructure et à la performance. En intégrant les modèles d’IA et de ML dans les processus opérationnels et les produits destinés aux utilisateurs, ils facilitent l’utilisation de la science des données pour résoudre les défis commerciaux, en veillant à ce que les modèles ne restent pas seulement dans le domaine de la recherche mais génèrent une valeur commerciale tangible.
- Les analystes commerciaux permettent aux parties prenantes et aux équipes commerciales de disposer de données exploitables. Ils interprètent souvent les données et créent des rapports ou d’autres documents pour la direction à l’aide d’outils décisionnels standard. Ils sont généralement le point de contact privilégié des collègues non techniques des entreprises et des opérations pour les questions d’analyse rapide.
- Les partenaires commerciaux sont des parties prenantes importantes dans un monde des affaires de plus en plus interconnecté. Ils sont définis comme étant une entreprise ou des personnes individuelles avec lesquelles une entreprise entretient une relation formelle pour atteindre un objectif commun, et ils peuvent inclure des vendeurs, des fournisseurs, des distributeurs et d’autres partenaires tiers. Le partage des données est un aspect important des partenariats commerciaux, car il permet le transfert et l’échange de données afin d’améliorer la collaboration et la prise de décision fondée sur les données.
Domaines de l’infrastructure de plateforme
La plateforme se compose de plusieurs domaines :
Stockage : dans le cloud, les données sont principalement stockées dans des stockages d’objets cloud évolutifs, efficaces et résilients sur des fournisseurs de cloud.
Gouvernance : capacités relatives à la gouvernance des données, par exemple contrôle d’accès, audit, gestion des métadonnées, suivi de la traçabilité, et surveillance de l’ensemble des données et des ressources d’IA.
Moteur IA : le moteur IA fournit des capacités d’IA générative pour l’ensemble de la plateforme.
Ingestion et transformation : Capacités pour les charges de travail ETL.
Analyses avancées, ML et IA : Toutes les capacités liées au machine learning, à l’IA, à l’IA générative et à l’analyse en streaming.
Entrepôt de données : Domaine prenant en charge les cas d’utilisation DWH et BI.
Orchestration : Gestion centralisée des workflows de traitement des données, de machine learning et de pipelines d’analyse.
Outils ETL et DS : Les outils front-end utilisés principalement par les ingénieurs de données, les scientifiques de données et les ingénieurs ML dans le cadre de leur travail.
Outils décisionnels : Les outils front-end utilisés principalement par les analystes décisionnels dans le cadre de leur travail.
Collaboration: Capacités de partage de données entre deux ou plusieurs parties.
Étendue de la plateforme Databricks
La plateforme de Data Intelligence de Databricks et ses composants peuvent être mis en correspondance avec l’infrastructure de la manière suivante :
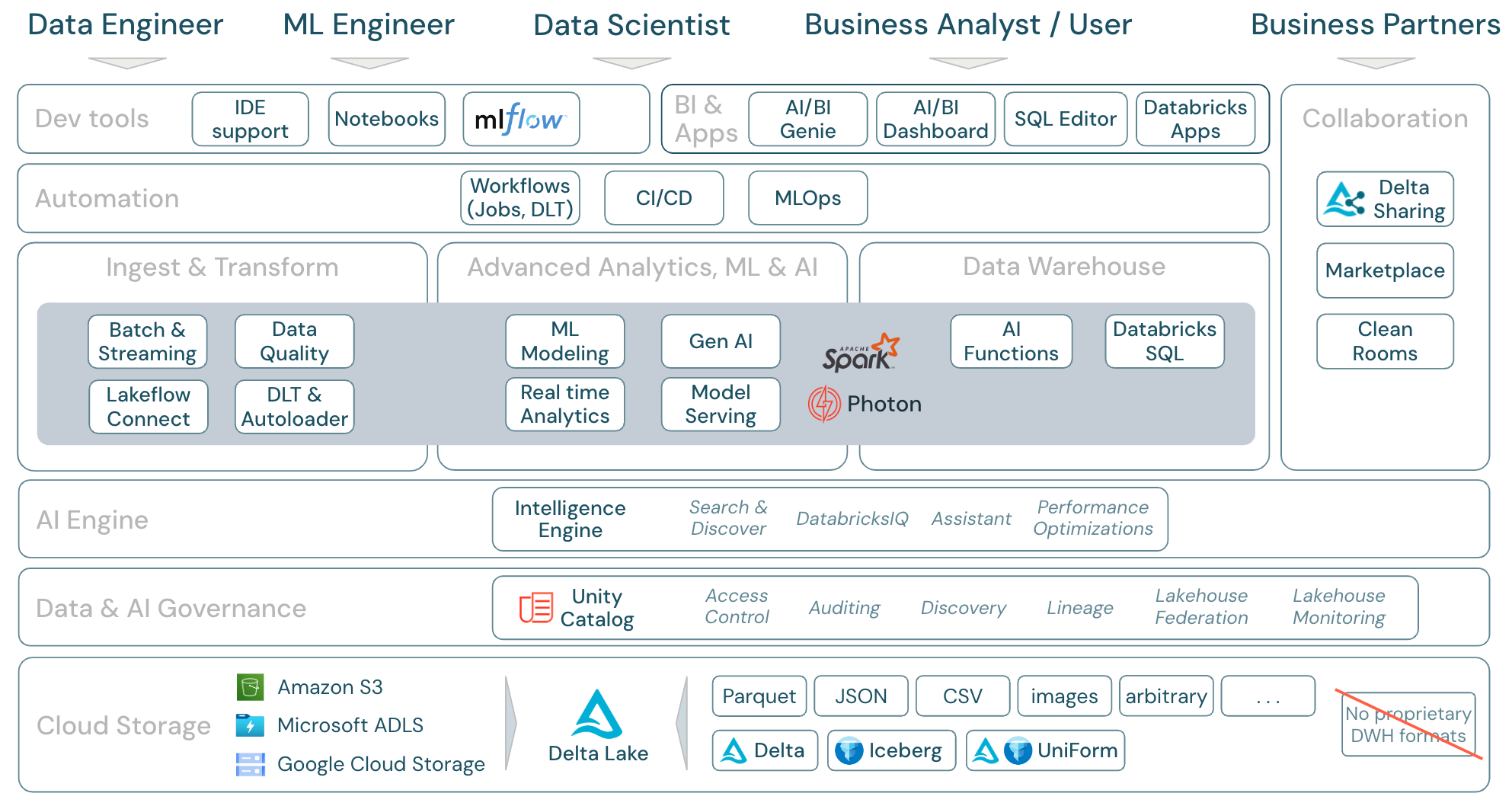
Télécharger : Étendue du lakehouse – Composants Databricks
Charges de travail de données sur Azure Databricks
Plus important encore, la plateforme de Data Intelligence de Databricks couvre toutes les charges de travail pertinentes pour le domaine des données en une seule plateforme, avec Apache Spark/Photon en tant que moteur :
Ingérer et transformer
Pour l’ingestion des données, Auto Loader traite de manière incrémentielle et automatique les fichiers qui atterrissent dans le stockage cloud dans le cadre de tâches planifiées ou continues, sans qu’il soit nécessaire de gérer les informations relatives à l’état. Une fois ingérées, les données brutes doivent être transformées afin d’être prêtes pour la Business intelligence et le Machine Learning (ML) ou l’Intelligence artificielle (IA). Databricks fournit de puissantes capacités ETL pour les ingénieurs de données, les scientifiques de données et les analystes.
Delta Live Tables (DLT) permet aux travaux ETL d’être écrits de manière déclarative, ce qui simplifie l’ensemble du processus d’implémentation. La qualité des données peut être améliorée en définissant attentes en matière de données.
Analyses avancées, ML et IA
La plateforme inclut Databricks Mosaic AI, un ensemble d’outils d’apprentissage automatique et d’IA entièrement intégrés pour l’apprentissage automatique et le Deep Learning traditionnels, ainsi que l’IA générative et des grands modèles de langage (LLM). Elle couvre l’ensemble du workflow, de la préparation des données à la création de modèles d’apprentissage automatique et de Deep Learning jusqu’au service de modèles Mosaic AI.
Spark Structured Streaming et DLT permettent des analyses en temps réel.
Data Warehouse
La plateforme de Data Intelligence de Databricks fournit également une solution complète d’entrepôt de données avec Databricks SQL, gouvernée de façon centralisée par Unity Catalog avec un contrôle d’accès précis.
Aperçu des domaines de fonctionnalités d’Azure Databricks
Voici un mappage des fonctionnalités de la plateforme de Data Intelligence de Databricks aux autres couches du framework, de bas en haut :
Stockage dans le cloud
Toutes les données du lakehouse sont stockées dans le système de stockage d’objets du fournisseur de services cloud. Databricks prend en charge trois fournisseurs de services cloud : AWS, Azure et GCP. Les fichiers dans différents formats structurés et semi-structurés (par exemple, Parquet, CSV, JSON et Avro) ainsi que dans des formats non structurés (comme des images et des documents) sont ingérés et transformés en utilisant des processus par lots ou de diffusion en continu.
Delta Lake est le format de données recommandé pour la maison du lac (transactions de fichiers, fiabilité, cohérence, mises à jour, etc.) et est entièrement open source pour éviter le verrouillage. Et Delta Universal Format (UniForm) vous permet de lire des tables Delta avec des clients de lecteur Iceberg.
Aucun format de données propriétaire n’est utilisé dans la plateforme de Data Intelligence de Databricks.
Gouvernance des données
Au-dessus de la couche de stockage, Unity Catalog offre une large gamme de fonctionnalités de gouvernance des données, notamment la gestion des métadonnées dans le metastore, le contrôle d’accès, l’audit, la découverte de données, la traçabilité des données.
La supervision du lakehouse fournit des métriques de qualité prêtes à l’emploi pour les ressources de données et d’IA, ainsi que des tableaux de bord générés automatiquement pour visualiser ces métriques.
Des sources SQL externes peuvent être intégrées dans le lakehouse et Unity Catalog via la fédération lakehouse.
Moteur IA
La plateforme de Data Intelligence est construite sur l’architecture lakehouse et améliorée par le moteur de Data Intelligence DatabricksIQ. DatabricksIQ combine l’IA générative avec les avantages d’unification de l’architecture lakehouse pour comprendre la sémantique unique de vos données. La recherche intelligente et l’Assistant Databricks sont des exemples de services alimentés par l’IA qui simplifient l’utilisation de la plateforme pour chaque utilisateur.
Orchestration
Les travaux Databricks vous permettent d’exécuter diverses charges de travail pour l’ensemble du cycle de vie des données et de l’IA sur n’importe quel cloud. Ils vous permettent d’orchestrer des tâches ainsi que des tables Delta Live pour SQL, Spark, les notebooks, DBT, les modèles ML, et plus encore.
Outils ETL et DS
Au niveau de la consommation, les ingénieurs de données et les ingénieurs ML travaillent généralement avec la plateforme à l’aide d’IDE. Les scientifiques des données préfèrent souvent les notebooks et utilisent les runtimes ML et AI, ainsi que le système de flux de travail d’apprentissage automatique MLflow pour suivre les expériences et gérer le cycle de vie des modèles.
Outils décisionnels
Les analystes commerciaux utilisent généralement leur outil décisionnel préféré pour accéder à l’entrepôt de données de Databricks. Databricks SQL peut être interrogé par différents outils d’analyse et de décision, consultez Décision et visualisation
Par ailleurs, la plateforme offre des outils d’interrogation et d’analyse prêts à l’emploi :
- Tableaux de bord permettant de créer des visualisations de données par glisser-déposer et de partager des insights.
- Les éditeur SQL pour les analystes SQL afin d’analyser les données.
Collaboration
Delta Sharing est un protocole ouvert développé par Databricks pour le partage sécurisé de données avec d’autres organisations, indépendamment des plateformes informatiques utilisées.
La Place de marché Databricks est un forum ouvert pour l’échange de produits de données. Elle tire parti de Delta Sharing pour donner aux fournisseurs de données les outils nécessaires pour partager des produits de données en toute sécurité et aux consommateurs de données le pouvoir d’explorer et d’élargir leur accès aux données et aux services de données dont ils ont besoin.