Meilleures pratiques Unity Catalog
Ce document fournit des recommandations pour l’utilisation de Unity Catalog et de Delta Sharing afin de satisfaire vos besoins en matière de gouvernance des données.
Unity Catalog est une solution affinée de gouvernance des données et de l’IA sur la plateforme Databricks. Il simplifie la sécurité et la gouvernance de vos données en fournissant un emplacement central pour administrer et auditer l’accès aux données. Delta Sharing est une plateforme de partage de données sécurisée qui permet de partager des données dans Azure Databricks avec des utilisateurs extérieurs à votre organisation. Il utilise Unity Catalog pour gérer et auditer le comportement de partage.
Blocs de construction de la gouvernance des données et de l’isolation des données
Pour développer un modèle de gouvernance de données et un plan d’isolation des données qui fonctionne pour votre organisation, il est utile de comprendre les principaux blocs de construction disponibles lorsque vous créez votre solution de gouvernance des données dans Azure Databricks.
Le diagramme suivant illustre la hiérarchie de données principale dans Unity Catalog (certains objets sécurisables sont grisés pour souligner la hiérarchie des objets gérés sous les catalogues).
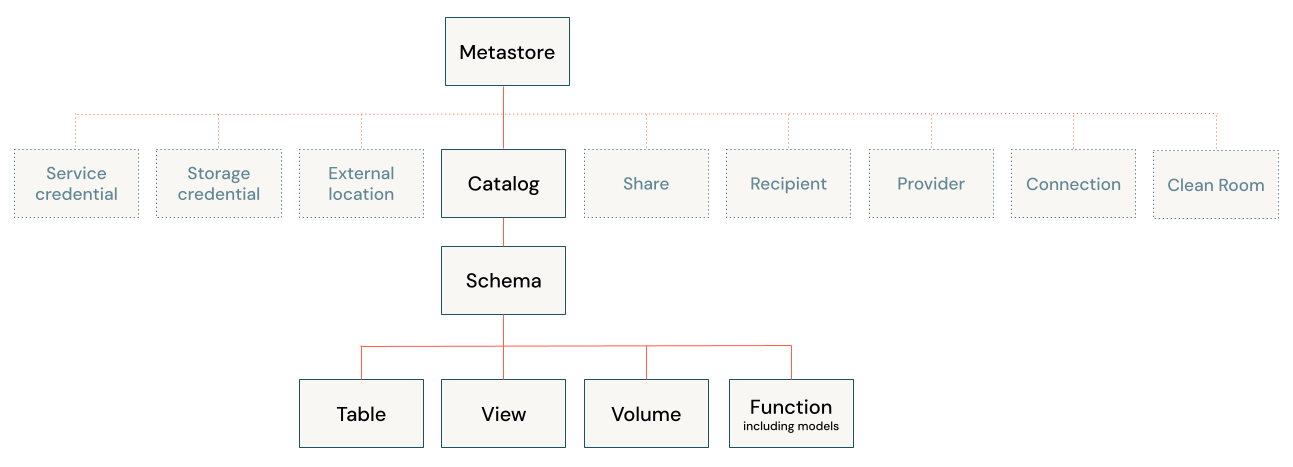
Les objets de cette hiérarchie incluent les éléments suivants :
Metastore : un metastore est le conteneur de niveau supérieur des objets dans Unity Catalog. Les metastores vivent au niveau du compte et fonctionnent en haut de la pyramide dans le modèle de gouvernance des données Azure Databricks.
Les metastores gèrent les ressources de données (tables, vues et volumes), ainsi que les autorisations qui régissent l’accès à celles-ci. Les administrateurs de compte Azure Databricks peuvent créer un metastore pour chaque région dans laquelle ils opèrent et l’attribuer à plusieurs espaces de travail Azure Databricks dans la même région. Les administrateurs de metastore peuvent gérer tous les objets du metastore. Ils n’ont pas d’accès direct à la lecture et à l’écriture aux tables inscrites dans le metastore, mais ils disposent d’un accès indirect grâce à leur capacité à transférer la propriété de l’objet de données.
Le stockage physique d’un metastore donné est, par défaut, isolé du stockage pour tout autre metastore de votre compte.
Les metastores fournissent une isolation régionale, mais ne sont pas destinés à être des unités d’isolation des données. L’isolation des données doit commencer au niveau du catalogue.
Catalogue : les catalogues sont le niveau le plus élevé de la hiérarchie de données (catalogue >schéma > table/vue/volume) gérée par le metastore Unity Catalog. Ils sont destinés à être l’unité principale de l’isolation des données dans un modèle de gouvernance des données Azure Databricks classique.
Les catalogues représentent un regroupement logique de schémas, généralement limité par les exigences d’accès aux données. Les catalogues reflètent souvent des unités d’organisation ou des étendues de cycle de vie de développement logiciel. Vous pouvez choisir, par exemple, d’avoir un catalogue pour les données de production et un catalogue pour les données de développement, ou un catalogue pour les données non client et un catalogue pour les données client sensibles.
Les catalogues peuvent être stockés au niveau du metastore, ou vous pouvez configurer un catalogue pour qu’il soit stocké séparément du reste du metastore parent. Si votre espace de travail a été activé automatiquement pour le catalogue Unity, il n’existera aucun stockage au niveau du metastore, et vous allez devoir spécifier un emplacement de stockage lorsque vous créez un catalogue.
Si le catalogue est l’unité principale d’isolation des données dans le modèle de gouvernance des données Azure Databricks, l’espace de travail est l’environnement principal pour l’utilisation des ressources de données. Les administrateurs de metastore et les propriétaires de catalogue peuvent gérer l’accès aux catalogues indépendamment des espaces de travail, ou lier des catalogues à des espaces de travail spécifiques pour garantir que certains types de données sont traités uniquement dans ces espaces de travail. Vous pouvez souhaiter disposer d’espaces de travail de production et de développement distincts, par exemple, ou d’un espace de travail distinct pour le traitement des données sensibles.
Par défaut, les autorisations d’accès pour un objet sécurisable sont héritées par les enfants de cet objet, avec des catalogues en haut de la hiérarchie. Cela facilite la configuration des règles d’accès par défaut pour vos données et la spécification de règles différentes à chaque niveau de la hiérarchie uniquement là où vous en avez besoin.
Schéma (base de données) : Les schémas, également appelés bases de données, sont des regroupements logiques de données tabulaires (tables et vues), de données non tabulaires (volumes), de fonctions et de modèles Machine Learning. Ils vous permettent d’organiser et de contrôler l’accès aux données plus granulaires que les catalogues. En règle générale, ils représentent un seul cas d’usage, un projet ou un bac à sable d’équipe.
Les schémas peuvent être stockés dans le même stockage physique que le catalogue parent, ou vous pouvez configurer un schéma pour qu’il soit stocké séparément du reste du catalogue parent.
Les administrateurs de metastore, les propriétaires de catalogues parents et les propriétaires de schémas peuvent gérer l’accès aux schémas.
Tables : les tables résident dans la troisième couche de l’espace de noms à trois niveaux de Unity Catalog. Elles contiennent des lignes de données.
Unity Catalog vous permet de créer des tables managées et des tables externes.
Pour les tables managées, Unity Catalog gère entièrement le cycle de vie et la disposition des fichiers. Par défaut, les tables managées sont stockées à l’emplacement de stockage racine configuré lors de la création d’un metastore. Vous pouvez choisir à la place d’isoler le stockage pour les tables managées au niveau du catalogue ou du schéma.
Les tables externes sont des tables dont le cycle de vie des données et la disposition des fichiers sont gérés à l’aide de votre fournisseur de cloud et d’autres plateformes de données, et non Unity Catalog. Utilisez des tables externes pour inscrire de grandes quantités de vos données existantes, ou si vous avez également besoin d’un accès en écriture aux données à l’aide d’outils en dehors des clusters Azure Databricks et des entrepôts SQL Databricks. Une fois qu’une table externe est inscrite dans un metastore Unity Catalog, vous pouvez gérer et auditer l’accès d’Azure Databricks à celle-ci comme avec des tables managées.
Les propriétaires de catalogue parents et de schémas peuvent gérer l’accès aux tables, tout comme les administrateurs de metastore (indirectement).
Vues : une vue est un objet en lecture seule dérivé d’une ou plusieurs tables et vues dans un metastore.
Lignes et colonnes : l’accès au niveau des lignes et des colonnes ainsi que le masquage des données sont accordés à l’aide de vues dynamiques ou en filtrant les lignes et masquant les colonnes. Les vues dynamiques sont en lecture seule.
Volumes : les volumes se situent dans la troisième couche de l’espace de noms à trois niveaux d’Unity Catalog. Ils gèrent les données non tabulaires. Vous pouvez utiliser des volumes pour stocker, organiser et accéder à des fichiers dans n’importe quel format, y compris des données structurées, semi-structurées et non structurées. Les fichiers dans les volumes ne peuvent pas être inscrits en tant que tables.
Modèles et fonctions : bien qu’il ne s’agisse pas à strictement parler de ressources de données, les fonctions définies par l’utilisateur et les modèles inscrits peuvent également être gérés dans Unity Catalog et résident au niveau le plus bas de la hiérarchie d’objets. Consultez Gérer le cycle de vie de modèles dans Unity Catalog et Fonctions définies par l’utilisateur (UDF) dans Unity Catalog.
Planifier votre modèle d’isolation des données
Lorsqu’une organisation utilise une plateforme de données comme Azure Databricks, il est souvent nécessaire d’avoir des limites d’isolation des données entre les environnements (tels que le développement et la production) ou entre les unités opérationnelles de l’organisation.
Les normes d’isolation peuvent varier selon votre organisation, mais elles incluent généralement les attentes suivantes :
- Les utilisateurs peuvent uniquement accéder aux données en fonction de règles d’accès spécifiées.
- Les données peuvent être gérées uniquement par des personnes ou des équipes désignées.
- Les données sont physiquement séparées dans le stockage.
- Les données sont accessibles uniquement dans des environnements désignés.
Le besoin d’isolation des données peut conduire à des environnements cloisonnés qui peuvent rendre la gouvernance des données et la collaboration inutilement difficiles. Azure Databricks résout ce problème à l’aide de Unity Catalog, qui fournit un certain nombre d’options d’isolation des données tout en conservant une plateforme de gouvernance des données unifiée. Cette section décrit les options d’isolation des données disponibles dans Azure Databricks et comment les utiliser, que vous préfériez un modèle de gouvernance des données centralisé ou distribué.
Les utilisateurs peuvent uniquement accéder aux données en fonction de règles d’accès spécifiées
La plupart des organisations ont des exigences strictes en matière d’accès aux données en fonction d’exigences internes ou réglementaires. Parmi les exemples classiques de données qui doivent être sécurisées, citons les informations sur le salaire des employés ou les informations de paiement par carte de crédit. L’accès à ce type d’informations est généralement étroitement contrôlé et audité régulièrement. Unity Catalog vous offre un contrôle granulaire sur les ressources de données au sein du catalogue pour répondre à ces normes du secteur. Avec les contrôles fournis par Unity Catalog, les utilisateurs peuvent voir et interroger uniquement les données qu’ils ont le droit de voir et d’interroger.
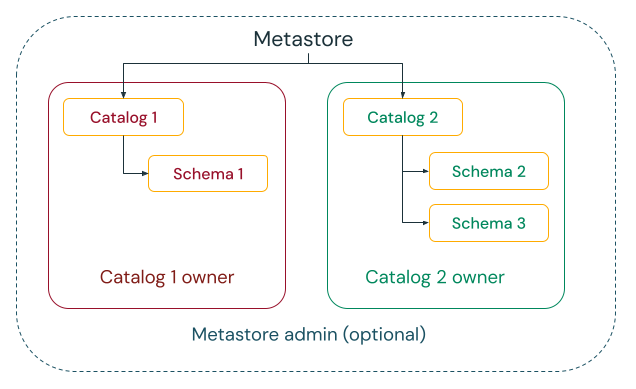
Les données peuvent être gérées uniquement par des personnes ou des équipes désignées
Unity Catalog vous donne la possibilité de choisir entre les modèles de gouvernance centralisée et distribuée.
Dans le modèle de gouvernance centralisée, vos administrateurs de gouvernance sont propriétaires du metastore et peuvent prendre possession de n’importe quel objet, et accorder et révoquer des autorisations.
Dans un modèle de gouvernance distribuée, le catalogue ou un ensemble de catalogues est le domaine de données. Le propriétaire de ce catalogue peut créer et posséder toutes les ressources et gérer la gouvernance au sein de ce domaine. Les propriétaires d’un domaine donné peuvent fonctionner indépendamment des propriétaires d’autres domaines.
Que vous choisissiez le metastore ou les catalogues comme domaine de données, Databricks vous recommande vivement de définir un groupe en tant qu’administrateur de metastore ou propriétaire de catalogue.
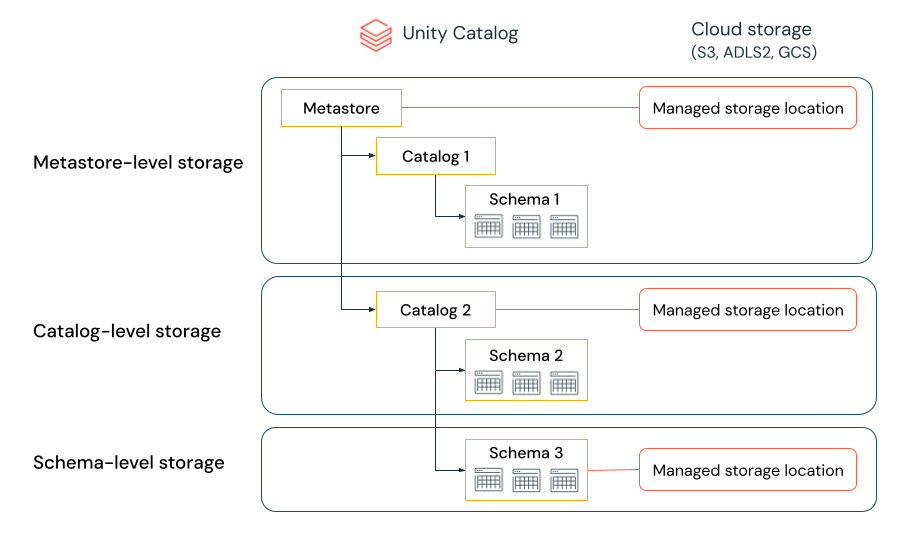
Les données sont physiquement séparées dans le stockage
Une organisation peut exiger que les données de certains types soient stockées dans des comptes ou compartiments spécifiques dans leur locataire cloud.
Unity Catalog permet de configurer des emplacements de stockage au niveau du metastore, du catalogue ou du schéma pour répondre à ces exigences.
Par exemple, supposons que la stratégie de conformité d’entreprise de votre organisation nécessite que les données de production relatives aux ressources humaines résident dans le conteneur abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net. Dans Unity Catalog, vous pouvez répondre à cette exigence en définissant un emplacement au niveau du catalogue, en créant un catalogue appelé par exemple hr_prod, et en lui attribuant l’emplacement abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net/unity-catalog. Cela signifie que les tables ou volumes managés créés dans le catalogue hr_prod (en utilisant CREATE TABLE hr_prod.default.table …, par exemple) stockent leurs données dans abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net/unity-catalog. Si vous le souhaitez, vous pouvez choisir de fournir des emplacements au niveau du schéma pour organiser les données dans hr_prod catalog à un niveau plus granulaire.
Si une telle isolation du stockage n’est pas nécessaire, vous pouvez définir un emplacement de stockage au niveau du metastore. Il en résulte que cet emplacement sert d’emplacement par défaut pour stocker des tables et des volumes managés sur des catalogues et des schémas dans le metastore.
Le système évalue la hiérarchie des emplacements de stockage du schéma au catalogue, puis au metastore.
Par exemple, si une table myCatalog.mySchema.myTable est créée dans my-region-metastore, l’emplacement de stockage de la table est déterminé en fonction de la règle suivante :
- Si un emplacement a été fourni pour
mySchema, elle sera stockée là. - Si ce n’est pas le cas et qu’un emplacement a été fourni sur
myCatalog, elle sera stockée là. - Enfin, si aucun emplacement n’a été fourni sur
myCatalog, elle sera stockée à l’emplacement associé àmy-region-metastore.
Les données sont accessibles uniquement dans des environnements désignés
Les exigences organisationnelles et de conformité spécifient souvent que vous conservez certaines données, telles que les informations d’identification personnelle, accessibles uniquement dans certains environnements. Vous pouvez également conserver les données de production isolées des environnements de développement ou vous assurer que certains jeux de données et domaines ne sont jamais regroupés.
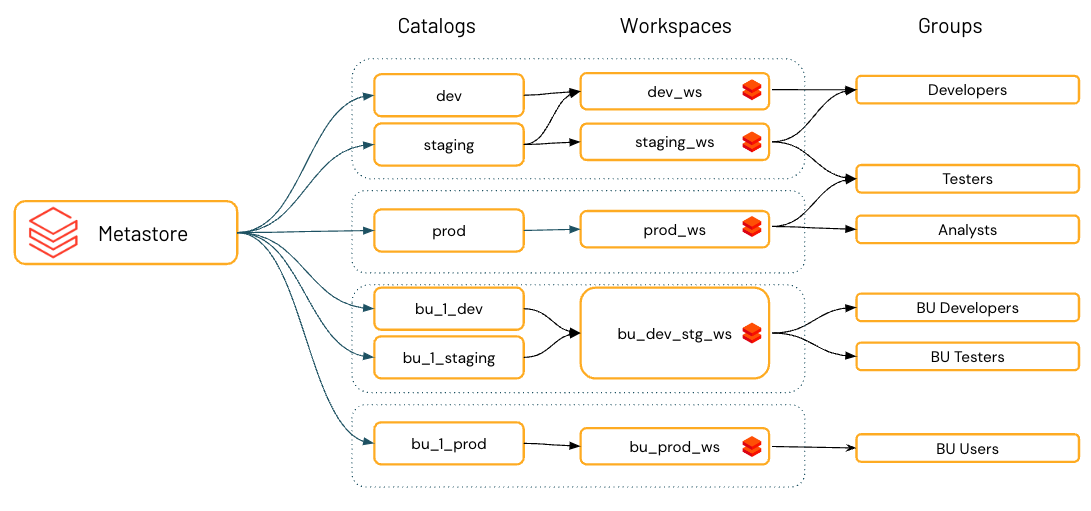
Dans Databricks, l’espace de travail est l’environnement de traitement des données principal, et les catalogues sont le domaine de données principal. Unity Catalog permet aux administrateurs de metastore et aux propriétaires de catalogue d’affecter (ou « lier ») des catalogues à des espaces de travail spécifiques. Ces liaisons prenant en charge l’environnement vous permettent de vous assurer que seuls certains catalogues sont disponibles dans un espace de travail, quels que soient les privilèges spécifiques sur les objets de données accordés à un utilisateur.
Examinons maintenant plus en détail le processus de configuration de Unity Catalog pour répondre à vos besoins.
Configurer un metastore Unity Catalog
Un metastore est le conteneur de niveau supérieur des objets dans Unity Catalog. Les metastores gèrent les ressources de données (tables, vues et volumes) ainsi que d’autres objets sécurisables gérés par Unity Catalog. Pour obtenir la liste complète des objets sécurisables, consultez Objets sécurisables dans Unity Catalog.
Cette section fournit des conseils pour créer et configurer des metastores. Si votre espace de travail a été automatiquement activé pour le catalogue Unity, vous n’avez pas besoin de créer un metastore, mais les informations présentées dans cette section peuvent toujours être utiles. Consultez l’article Activation automatique de Unity Catalog.
Conseils pour la configuration des metastores :
Vous devez configurer un metastore pour chaque région dans laquelle vous avez des espaces de travail Azure Databricks.
Chaque espace de travail attaché à un metastore régional unique a accès aux données gérées par le metastore. Si vous souhaitez partager des données entre des metastores, utilisez Partage Delta.
Chaque metastore peut être configuré avec un emplacement de stockage managé (également appelé stockage racine) dans votre locataire cloud qui peut être utilisé pour stocker des tables et volumes managés.
Si vous choisissez de créer un emplacement managé au niveau du metastore, vous devez vous assurer qu’aucun utilisateur ne dispose d’un accès direct à celui-ci (autrement dit, via le compte cloud qui le contient). Donner accès à cet emplacement de stockage pourrait permettre à un utilisateur de contourner les contrôles d’accès d’un metastore Unity Catalog, ce qui perturberait les capacités d’audit. Pour ces raisons, votre stockage de metastore managé doit être un conteneur dédié. Vous ne devez pas réutiliser un conteneur qui est également votre système de fichiers racine DBFS ou qui l’a été précédemment.
Vous avez également la possibilité de définir le stockage managé au niveau du catalogue et du schéma, en remplaçant l’emplacement de stockage racine du metastore. Dans la plupart des scénarios, Databricks recommande de stocker les données managées au niveau du catalogue.
Vous devez comprendre les privilèges des administrateurs d’espace de travail, dans les espaces de travail activés pour Unity Catalog, et passer en revue vos attributions existantes d’administrateur d’espace de travail.
Les administrateurs d’espace de travail peuvent gérer les opérations de leur espace de travail, notamment ajouter des utilisateurs et des principaux de service, créer des clusters et déléguer le rôle d’administrateur d’espace de travail à d’autres utilisateurs. Si votre espace de travail a été activé automatiquement pour le catalogue Unity, les administrateurs de l’espace de travail ont la possibilité de créer des catalogues et de nombreux autres objets de catalogue Unity par défaut. Consultez Privilèges d’administrateur de l’espace de travail lorsque ceux-ci sont activés automatiquement pour Unity Catalog
Les administrateurs d’espace de travail ont également la capacité à réaliser des tâches de gestion de l’espace de travail telles que la gestion de la propriété des travaux et l’affichage des blocs-notes, ce qui peut donner un accès indirect aux données inscrites dans le catalogue Unity. Le rôle d’administrateur d’espace de travail est un rôle privilégié que vous devez distribuer avec soin.
Si vous utilisez des espaces de travail pour isoler l’accès aux données utilisateur, vous pouvez utiliser des liaisons espace de travail-catalogue. Les liaisons espace de travail-catalogue vous permettent de limiter l’accès au catalogue par des limites d’espace de travail. Par exemple, vous pouvez vous assurer que les administrateurs et les utilisateurs de l’espace de travail peuvent uniquement accéder aux données de production dans
prod_catalogà partir d’un environnement d’espace de travail de production,prod_workspace. La valeur par défaut consiste à partager le catalogue avec tous les espaces de travail attachés au metastore actuel. Consultez Limiter l’accès au catalogue à des espaces de travail spécifiques.Si votre espace de travail a été activé automatiquement pour le catalogue Unity, le catalogue d’espaces de travail approvisionné préalablement est lié à votre espace de travail par défaut.
Consultez Créer un metastore Unity Catalog.
Configurer les emplacements externes et les informations d’identification de stockage
Les emplacements externes permettent à Unity Catalog de lire et d’écrire des données sur votre locataire Cloud pour le compte des utilisateurs. Les emplacements externes sont définis comme un chemin d’accès au stockage cloud, combiné avec des informations d’identification de stockage qui peuvent être utilisées pour accéder à cet emplacement.
Vous pouvez utiliser des emplacements externes pour inscrire des tables et des volumes externes dans Unity Catalog. Le contenu de ces entités se trouve physiquement sur un sous-chemin dans un emplacement externe référencé lorsqu’un utilisateur crée le volume ou la table.
Les informations d’identification de stockage encapsulent des informations d’identification cloud à long terme qui permettent d’accéder au stockage cloud. Il peut s’agir d’une identité managée Azure (fortement recommandé) ou d’un principal de service. L’utilisation d’une identité managée Azure présente les avantages suivants par rapport à l’utilisation d’un principal de service :
- Les identités managées ne nécessitent pas de gestion d’informations d’identification ou de rotation des secrets.
- Si votre espace de travail Azure Databricks est déployé sur votre propre réseau virtuel (également appelé injection de réseau virtuel), vous pouvez vous connecter à un compte Azure Data Lake Storage Gen2 protégé par un pare-feu de stockage.
Pour une isolation accrue des données, vous pouvez lier des informations d’identification de service, des informations d’identification de stockage et des emplacements externes à des espaces de travail spécifiques. Voir (Facultatif) Affecter des informations d’identification de service à des espaces de travail spécifiques, (Facultatif) Affecter un emplacement externe à des espaces de travail spécifiques et (Facultatif) Attribuer des informations d’identification de stockage à des espaces de travail spécifiques.
Conseil
Les emplacements externes, en combinant des informations d’identification de stockage et des chemins de stockage, fournissent un contrôle fort et une auditabilité de l’accès au stockage. Pour empêcher les utilisateurs de contourner le contrôle d’accès fourni par Unity Catalog, vous devez vous assurer de limiter le nombre d’utilisateurs disposant d’un accès direct à n’importe quel conteneur utilisé comme emplacement externe. Pour la même raison, vous ne devez pas monter des comptes de stockage sur DBFS s’ils sont également utilisés comme emplacements externes. Databricks recommande que vous migrez les montages des emplacements de stockage cloud vers des emplacements externes au sein de Unity Catalog via Catalog Explorer.
Pour obtenir la liste des meilleures pratiques de gestion des emplacements externes, consultez Gérer les emplacements externes, les tables externes et les volumes externes. Consulter aussi Créer un emplacement externe pour connecter un stockage cloud à Azure Databricks.
Organiser vos données
Databricks recommande d’utiliser des catalogues pour assurer la séparation dans l’architecture des informations de votre organisation. Cela signifie souvent que les catalogues peuvent correspondre à l’étendue, à l’équipe ou à l’unité commerciale de l’environnement de développement logiciel. Si vous utilisez des espaces de travail comme outil d’isolation des données( par exemple, en utilisant différents espaces de travail pour les environnements de production et de développement, ou un espace de travail spécifique pour travailler avec des données hautement sensibles, vous pouvez également lier un catalogue à des espaces de travail spécifiques. Cela garantit que tout le traitement des données spécifiées est géré dans l’espace de travail approprié. Consultez Limiter l’accès au catalogue à des espaces de travail spécifiques.
Un schéma (également appelé base de données) est la deuxième couche de l'espace de noms à trois niveaux d’Unity Catalog, il permet d’organiser les tables, les vues et les volumes. Vous pouvez utiliser des schémas pour organiser et définir des autorisations pour vos ressources.
Les objets régis par Unity Catalog peuvent être gérés ou externes :
Les objets managés sont la méthode par défaut pour créer des objets de données dans Unity Catalog.
Unity Catalog gère le cycle de vie et la disposition de fichiers pour ces sécurisables. Vous ne devez pas utiliser d’outils en dehors de Azure Databricks pour manipuler directement des fichiers dans des tables ou des volumes managés.
Les tables et volumes managés sont stockés dans un stockage managé qui peut exister au niveau du metastore, du catalogue ou du schéma pour une table ou un volume donné. Consultez Les données sont physiquement séparées dans le stockage.
Les tables et volumes managés constituent une solution pratique lorsque vous souhaitez approvisionner un emplacement régi pour votre contenu sans surcharge liée à la création et à la gestion des emplacements externes et des informations d’identification de stockage.
Les tables managées utilisent toujours le format de table Delta.
Les objets externes sont des sécurisables dont le cycle de vie des données et la disposition des fichiers ne sont pas gérés par Unity Catalog.
Les volumes et les tables externes sont inscrits sur un emplacement externe pour permettre l’accès à un grand nombre de fichiers qui existent déjà dans le stockage cloud sans nécessiter d’activité de copie de données. Utilisez des objets externes lorsque vous avez des fichiers qui sont produits par d’autres systèmes et que vous souhaitez les mettre en place pour y accéder à partir d’Azure Databricks, ou lorsque des outils en dehors d’Azure Databricks nécessitent un accès direct à ces fichiers.
Les tables externes prennent en charge Delta Lake et de nombreux autres formats de données, notamment Parquet, JSON et CSV. Les volumes managés et externes peuvent être utilisés pour accéder et stocker des fichiers de formats arbitraires : les données peuvent être structurées, semi-structurées ou non structurées.
Pour plus d’informations sur la création de tables et de volumes, consultez Qu’est-ce que les tables et les vues ? et Qu’est-ce que les volumes catalogue Unity ?.
Gérer les emplacements externes, les tables externes et les volumes externes
Le diagramme ci-dessous représente la hiérarchie du système de fichiers d’un seul conteneur de stockage cloud, avec quatre emplacements externes qui partagent une seule information d’identification de stockage.
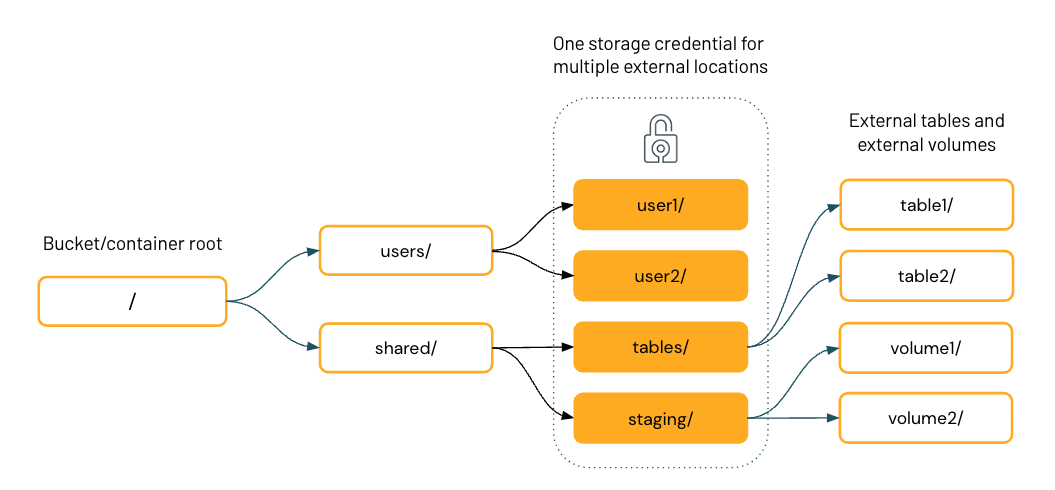
Une fois que vous avez configuré des emplacements externes dans Unity Catalog, vous pouvez créer des tables et des volumes externes sur des répertoires à l’intérieur des emplacements externes. Vous pouvez ensuite utiliser Unity Catalog pour gérer l’accès des utilisateurs et des groupes à ces tables et volumes. Cela vous permet de fournir à des utilisateurs ou des groupes spécifiques l’accès à des répertoires et fichiers spécifiques dans le conteneur de stockage cloud.
Remarque
Lorsque vous définissez un volume externe, l’accès à l’URI cloud aux données sous le chemin du volume est régi par les privilèges accordés sur le volume, et non les privilèges accordés sur l’emplacement externe où le volume est stocké.
Recommandations pour l’utilisation d’emplacements externes
Recommandations pour l’octroi d’autorisations sur des emplacements externes :
Accordez la possibilité de créer des emplacements externes uniquement à un administrateur chargé de configurer des connexions entre Unity Catalog et le stockage cloud, ou à des ingénieurs données de confiance.
Les emplacements externes fournissent un accès à partir d’Unity Catalog vers un emplacement largement englobant dans le stockage cloud. Par exemple, un compartiment entier ou un conteneur (abfss://my-container@storage-account.dfs.core.windows.net) ou un sous-tracé large (abfss://my-container@storage-account.dfs.core.windows.net/path/to/subdirectory). L’objectif est qu’un administrateur cloud puisse être impliqué dans la configuration de quelques emplacements externes, puis délègue la responsabilité de la gestion de ces emplacements à un administrateur Azure Databricks au sein de votre organisation. L’administrateur Azure Databricks peut ensuite organiser davantage l’emplacement externe en zones disposant d’autorisations plus précises en inscrivant des volumes externes ou des tables externes à des préfixes spécifiques sous l’emplacement externe.
Étant donné que les emplacements externes sont très englobants, Databricks recommande d’accorder l’autorisation
CREATE EXTERNAL LOCATIONuniquement à un administrateur chargé de configurer les connexions entre Unity Catalog et le stockage cloud, ou à des ingénieurs données approuvés. Pour fournir à d’autres utilisateurs un accès plus granulaire, Databricks recommande d’inscrire des tables ou des volumes externes par-dessus des emplacements externes et d’accorder aux utilisateurs l’accès aux données à l’aide de volumes ou de tables. Étant donné que les tables et les volumes sont les enfants d’un catalogue et d’un schéma, les administrateurs de catalogues ou de schémas ont le contrôle total sur les autorisations d’accès.Vous pouvez également contrôler l’accès à un emplacement externe en le liant à des espaces de travail spécifiques. Voir (Facultatif) Affecter un emplacement externe à des espaces de travail spécifiques.
N’accordez pas d’autorisations générales
READ FILESouWRITE FILESd’autorisations sur des emplacements externes aux utilisateurs finaux.Avec la disponibilité des volumes, les utilisateurs ne doivent pas utiliser d’emplacements externes pour créer des tables, des volumes ou des emplacements managés. Ils ne doivent pas utiliser d’emplacements externes pour l’accès basé sur le chemin d’accès pour la science des données ou d’autres cas d’utilisation de données non tabulaires.
Les volumes prennent en charge l’utilisation de fichiers à l’aide de commandes SQL, de dbutils, d’API Spark, d’API REST, de Terraform et d’une interface utilisateur pour la navigation, le chargement et le téléchargement de fichiers. En outre, les volumes offrent un montage FUSE accessible sur le système de fichiers local sous
/Volumes/<catalog_name>/<schema_name>/<volume_name>/. Le montage FUSE permet aux scientifiques des données et aux ingénieurs d’Azure Machine Learning d’accéder aux fichiers comme s’ils se trouvaient dans un système de fichiers local, comme requis par de nombreuses bibliothèques de système d’exploitation ou de Machine Learning.Si vous devez accorder un accès direct aux fichiers dans un emplacement externe (pour explorer des fichiers dans le stockage cloud avant qu’un utilisateur crée une table ou un volume externe, par exemple), vous pouvez accorder
READ FILES. Les cas d’usage d’octroiWRITE FILESsont rares.
Vous devez utiliser des emplacements externes pour effectuer les opérations suivantes :
- Inscrire des tables et des volumes externes à l’aide des commandes
CREATE EXTERNAL VOLUMEouCREATE TABLE. - Explorer les fichiers existants dans le stockage cloud avant de créer une table ou un volume externe à un préfixe spécifique. Le privilège
READ FILESest une condition préalable. - Inscrivez un emplacement en tant que stockage managé pour les catalogues et les schémas au lieu du compartiment racine du metastore. Le privilège
CREATE MANAGED STORAGEest une condition préalable.
Autres recommandations pour l’utilisation d’emplacements externes :
Évitez les conflits de chevauchement de chemin d’accès : ne créez jamais de volumes ou de tables externes à la racine d’un emplacement externe.
Si vous créez des volumes ou des tables externes à la racine de l’emplacement externe, vous ne pouvez pas créer de volumes ou de tables externes supplémentaires sur l’emplacement externe. Au lieu de cela, créez des volumes ou des tables externes sur un sous-répertoire à l’intérieur de l’emplacement externe.
Recommandations pour l’utilisation de volumes externes
Vous devez utiliser des volumes externes pour effectuer les opérations suivantes :
- Inscrire les zones d’atterrissage pour les données brutes produites par des systèmes externes afin de prendre en charge leur traitement dans les premières étapes des pipelines ETL et d’autres activités d’ingénierie des données.
- Inscrire des emplacements intermédiaires pour l’ingestion, par exemple à l’aide d’instructions Auto Loader,
COPY INTOou CTAS (CREATE TABLE AS). - Fournir des emplacements de stockage de fichiers pour les scientifiques des données, les analystes de données et les ingénieurs Machine Learning à utiliser dans le cadre de leur analyse exploratoire des données et d’autres tâches de science des données, lorsque les volumes managés ne sont pas une option.
- Donner aux utilisateurs Azure Databricks l’accès à des fichiers arbitraires produits et déposés dans le stockage cloud par d’autres systèmes, par exemple de grandes collections de données non structurées (telles que des fichiers image, audio, vidéo et PDF) capturées par des systèmes de surveillance ou des appareils IoT, ou des fichiers de bibliothèque (fichiers JAR et Python wheels) exportés à partir de systèmes de gestion des dépendances locaux ou de pipelines d’intégration continue et de livraison continue (CI/CD).
- Stocker les données opérationnelles, telles que la journalisation ou les fichiers de point de contrôle, lorsque les volumes managés ne sont pas une option.
Autres recommandations pour l’utilisation de volumes externes :
- Databricks vous recommande de créer des volumes externes à partir d’un emplacement de stockage au sein d’un schéma.
Conseil
Pour les cas d’utilisation d’ingestion dans lesquels les données sont copiées vers un autre emplacement, par exemple à l’aide du chargeur automatique ou COPY INTO, utilisez des volumes externes. Utilisez des tables externes lorsque vous souhaitez interroger des données en place en tant que table, sans aucune copie.
Recommandations pour l’utilisation de tables externes
Vous devez utiliser des tables externes pour prendre en charge des modèles d’interrogation normaux par-dessus les données stockées dans le stockage cloud, lorsque la création de tables managées n’est pas une option.
Autres recommandations pour l’utilisation de tables externes :
- Databricks vous recommande de créer des tables externes en utilisant un emplacement externe par schéma.
- Azure Databricks recommande vivement de ne pas inscrire des tables courantes en tant que tables externes dans plusieurs metastores en raison du risque de problèmes de cohérence. Par exemple, une modification du schéma dans un metastore ne s’inscrit pas dans le deuxième metastore. Utilisez Delta Sharing pour partager des données entre des metastores. Consultez Partager de façon sécurisée des données à l’aide de Delta Sharing.
Configurer le contrôle d’accès
Chaque objet sécurisable dans Unity Catalog a un propriétaire. Le principal qui crée un objet devient son propriétaire initial. Le propriétaire d’un objet dispose de tous les privilèges sur l’objet, tels que SELECT et MODIFY sur une table, ainsi que de l’autorisation d’octroyer des privilèges sur l’objet sécurisable à d’autres principaux. Seuls les propriétaires d’un objet sécurisable sont autorisés à octroyer des privilèges sur cet objet à d’autres principaux. Par conséquent, la meilleure pratique consiste à attribuer la propriété relative à tous les objets au groupe chargé de l’administration des octrois sur l’objet. Le propriétaire et les administrateurs de metastore peuvent transférer la propriété d’un objet sécurisable à un groupe. En outre, si l’objet est contenu dans un catalogue (comme une table ou une vue), le propriétaire du catalogue et du schéma peut modifier la propriété de l’objet.
Les objets sécurisables dans Unity Catalog sont hiérarchiques et les privilèges sont hérités vers le bas. Cela signifie que l’octroi d’un privilège sur un catalogue ou un schéma accorde automatiquement le privilège à tous les objets actuels et futurs au sein du catalogue ou du schéma. Pour plus d’informations, consultez Modèle d’héritage.
Pour pouvoir lire les données d’une table ou d’une vue, un utilisateur doit disposer des privilèges suivants :
SELECTsur la table ou la vueUSE SCHEMAsur le schéma auquel appartient la tableUSE CATALOGsur le catalogue auquel appartient le schéma
USE CATALOG permet au bénéficiaire de parcourir le catalogue afin d’accéder à ses objets enfant et USE SCHEMA permet au bénéficiaire de parcourir le schéma afin d’accéder à ses objets enfant. Par exemple, pour sélectionner des données dans une table, les utilisateurs doivent disposer du privilège SELECT sur cette table et du privilège USE CATALOG sur son catalogue parent, avec le privilège USE SCHEMA sur son schéma parent. Par conséquent, vous pouvez utiliser ce privilège pour limiter l’accès aux sections de votre espace de noms de données à des groupes spécifiques. Un scénario courant consiste à configurer un schéma par équipe où seule cette équipe dispose des privilèges USE SCHEMA et CREATE sur le schéma. Cela signifie que les tables produites par les membres de l’équipe ne peuvent être partagées qu’au sein de l’équipe.
Vous pouvez sécuriser l’accès à une table à l’aide de la syntaxe SQL suivante :
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
Vous pouvez sécuriser l’accès aux colonnes à l’aide d’une vue dynamique dans un schéma secondaire, comme le montre la syntaxe SQL suivante :
CREATE VIEW < catalog_name >.< schema_name >.< view_name > as
SELECT
id,
CASE WHEN is_account_group_member(< group_name >) THEN email ELSE 'REDACTED' END AS email,
country,
product,
total
FROM
< catalog_name >.< schema_name >.< table_name >;
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >.< view_name >;
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< view_name >;
TO < group_name >;
Vous pouvez sécuriser l’accès aux lignes à l’aide d’une vue dynamique dans un schéma secondaire, comme le montre la syntaxe SQL suivante :
CREATE VIEW < catalog_name >.< schema_name >.< view_name > as
SELECT
*
FROM
< catalog_name >.< schema_name >.< table_name >
WHERE
CASE WHEN is_account_group_member(managers) THEN TRUE ELSE total <= 1000000 END;
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
Vous pouvez également accorder aux utilisateurs un accès sécurisé aux tableaux en utilisant un filtrage des lignes et un masquage des colonnes. Pour plus d’informations, consultez Filtrer les données de table sensibles à l’aide de filtres de lignes et de masques de colonne.
Pour plus d’informations sur tous les privilèges dans Unity Catalog, consultez Gérer les privilèges dans Unity Catalog.
Gérer les configurations de cluster
Databricks recommande d’utiliser des stratégies de cluster pour limiter la possibilité de configurer des clusters à partir d’un ensemble de règles. Les stratégies de cluster vous permettent de restreindre l’accès afin que seuls des clusters Unity Catalog puissent être créés. L’utilisation de stratégies de cluster réduit les choix disponibles, ce qui simplifie considérablement le processus de création de cluster pour les utilisateurs et leur garantit un accès transparent aux données. Les stratégies de cluster vous permettent également de contrôler les coûts en limitant le coût maximal par cluster.
Pour garantir l’intégrité des contrôles d’accès et appliquer des garanties d’isolation fortes, Unity Catalog impose des exigences de sécurité sur les ressources de calcul. Pour cette raison, Unity Catalog introduit le concept de mode d’accès d’un cluster. Unity Catalog est sécurisé par défaut. Si un cluster n’est pas configuré avec un mode d’accès approprié, il ne peut pas accéder aux données dans Unity Catalog. Consultez Conditions requises pour le calcul.
Databricks recommande d’utiliser le mode d’accès partagé lors du partage d’un cluster, et le mode d’accès Utilisateur unique pour des travaux automatisés et des charges de travail Machine Learning.
Le JSON ci-dessous fournit une définition de politique pour un cluster avec le mode d'accès partagé :
{
"spark_version": {
"type": "regex",
"pattern": "1[0-1]\\.[0-9]*\\.x-scala.*",
"defaultValue": "10.4.x-scala2.12"
},
"access_mode": {
"type": "fixed",
"value": "USER_ISOLATION",
"hidden": true
}
}
Le JSON ci-dessous fournit une définition de stratégie pour un cluster de travaux automatisé avec le mode d’accès Utilisateur unique :
{
"spark_version": {
"type": "regex",
"pattern": "1[0-1]\\.[0-9].*",
"defaultValue": "10.4.x-scala2.12"
},
"access_mode": {
"type": "fixed",
"value": "SINGLE_USER",
"hidden": true
},
"single_user_name": {
"type": "regex",
"pattern": ".*",
"hidden": true
}
}
Auditer l’accès
Une solution complète de gouvernance des données requiert un audit de l’accès aux données et la fourniture de fonctionnalités d’alerte et de surveillance. Unity Catalog capture un journal d’audit des actions effectuées sur le metastore. Ces journaux sont fournis dans le cadre des journaux d’audit d’Azure Databricks.
Vous pouvez accéder aux journaux d’audit de votre compte à l’aide de tables système. Pour plus d’informations sur la table système du journal d’audit, consultez Référence de table système du journal d’audit.
Consultez Surveiller votre plateforme Databricks Data Intelligence avec des journaux d’audit pour savoir comment bénéficier d’une vue complète des événements critiques liés à votre plateforme Databricks Data Intelligence.
Partager de façon sécurisée des données à l’aide de Delta Sharing
Delta Sharing est un protocole ouvert développé par Databricks pour le partage sécurisé de données avec d’autres organisations, ou avec d’autres services de votre organisation, quelle que soit la plateforme de calcul utilisée. Lorsque Delta Sharing est activé sur un metastore, Unity Catalog exécute un serveur Delta Sharing.
Pour partager les données entre les metastores, vous pouvez tirer parti du partage Delta entre Databricks. Cela vous permet d’inscrire des tables dans différentes régions à partir de metastores. Ces tables apparaîtront comme des objets en lecture seule dans le metastore de consommation. L’accès à ces tables peut être octroyé comme pour n’importe quel autre objet dans Unity Catalog.
Lorsque vous utilisez Databricks-to-Databricks Delta Sharing pour partager entre des metastores, gardez à l’esprit que le contrôle d’accès est limité à un metastore. Si un objet sécurisable, comme une table, a des subventions et que cette ressource est partagée avec un metastore intra-compte, les subventions de la source ne s’appliquent pas au partage de destination. Le partage de destination doit définir ses propres subventions.