Télécharger les architectures de référence lakehouse
Cet article couvre les orientations architecturales pour le lakehouse en termes de source de données, d’ingestion, de transformation, d’interrogation et de traitement, de mise en service, d’analyse et de sortie, et de stockage.
Chaque architecture de référence est accompagnée d’un PDF téléchargeable au format 11 x 17 (A3).
Architecture générique de référence
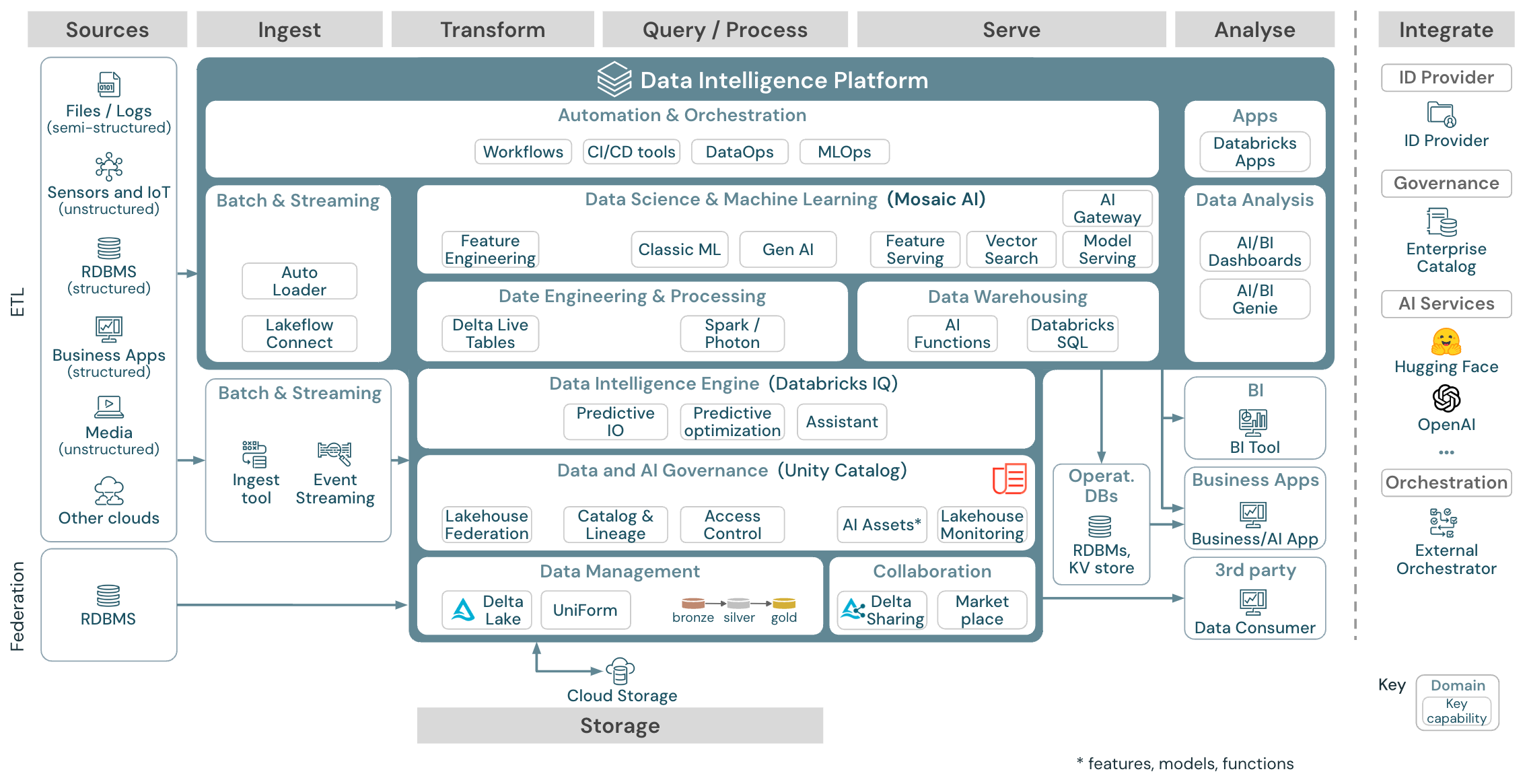
Télécharger : Architecture générique lakehouse de référence pour Databricks (PDF)
Organisation des architectures de référence
L’architecture de référence est structurée selon les axes Source, Ingestion, Transformation, Interrogation et Traitement, Mise en service, Analyseet Storage :
Source
L’architecture fait la distinction entre les données semi-structurées et non structurées (capteurs et IoT, médias, fichiers/journaux), et les données structurées (SGBDR, applications d’entreprise). Les sources SQL (SGBDR) peuvent également être intégrées dans le lac de données et le catalogue Unity sans ETL via la fédération lakehouse. En outre, les données peuvent être chargées à partir d’autres fournisseurs de services cloud.
Ingérer
Les données peuvent être ingérées dans le lakehouse par lots ou par diffusion en continu :
- Les fichiers remis au stockage cloud peuvent être chargés directement à l’aide du chargement automatique Databricks.
- Pour l’ingestion par lots de données provenant d’applications d’entreprise dans Delta Lake, le lakehouse Databricks s’appuie sur des outils d’ingestion partenaires dotés d’adaptateurs spécifiques pour ces systèmes d’enregistrement.
- Les événements diffusés en continu peuvent être ingérés directement à partir de systèmes de diffusion d’événements tels que Kafka à l’aide du Structured Streaming de Databricks. Les sources de diffusion en continu peuvent être des capteurs, des IoT ou des processus decapture de données modifiées.
Stockage
LLes données sont généralement stockées dans le système de stockage cloud où les pipelines ETL utilisent l’architecture en médaillon pour stocker les données de manière organisée sous forme de fichiers/tables Delta.
Transformation et interrogation et traitement
Le lakehouse Databricks utilise ses moteurs Apache Spark et Photon pour toutes les transformations et requêtes.
En raison de sa simplicité, le cadre déclaratif appelé Delta Live Tables (DLT) est un choix judicieux pour la construction de pipelines de traitement de données fiables, faciles à maintenir et à tester.
Alimentée par Apache Spark et Photon, la Databricks Data Intelligence Platform prend en charge les deux types de charges de travail : Les requêtes SQL via les entrepôts SQL, et les charges de travail SQL, Python et Scala via les clusters d’espace de travail .
Pour la science des données (Modélisation ML et Gen AI), la plateforme Databricks IA et Machine Learning fournit des runtimes ML spécialisés pour AutoML et pour le codage des tâches ML. Tous les flux de travail d’opérations d’apprentissage automatique (MLOps) et de science des données sont les mieux pris en charge par MLflow.
Mise en service
Pour les cas d’usage Data Warehouse (DWH) et Business intelligence (BI), le lakehouse de Databricks fournit Databricks SQL, l’entrepôt de données alimenté par des entrepôts SQL et des entrepôts SQL serverless.
Pour le Machine Learning, la mise en service de modèles est une capacité de mise en service de modèles évolutive, en temps réel et de niveau entreprise, hébergée dans le plan de contrôle de Databricks.
Bases de données opérationnelles : Les systèmes externes, tels que les bases de données opérationnelles, peuvent être utilisés pour stocker et fournir des produits de données finaux aux applications utilisateur.
Collaboration : Les partenaires commerciaux bénéficient d’un accès sécurisé aux données dont ils ont besoin via le Partage Delta. Basé sur le partage Delta, la Place de marché Databricks est un forum ouvert pour échanger des produits de données.
Analyse
Les dernières applications commerciales se trouvent dans cette voie. Les exemples incluent des clients personnalisés tels que des applications IA connectées au Service de modèles Databricks pour l’inférence en temps réel ou les applications qui accèdent aux données envoyées à partir du lakehouse vers une base de données opérationnelle.
Pour les cas d’usage décisionnels (BI), les analystes utilisent généralement outils décisionnels pour accéder à l’entrepôt de données. Par ailleurs, les développeurs SQL peuvent utiliser l’éditeur SQL de Databricks (non illustré dans le diagramme) pour les requêtes et les tableaux de bord.
La plateforme Data Intelligence propose également des tableaux de bord qui permettent de créer des visualisations de données et de partager des insights.
Capacités pour vos charges de travail
De plus, le lakehouse de Databricks est doté de capacités de gestion qui prennent en charge toutes les charges de travail :
Gouvernance des données et de l’IA
Le système central de gouvernance des données et de l’IA dans la plateforme de Data Intelligence de Databricks est le catalogue Unity Catalog. Unity Catalog fournit un emplacement unique pour gérer les stratégies d’accès aux données qui s’appliquent à tous les espaces de travail et prend en charge toutes les ressources créées ou utilisées dans le lakehouse, telles que les tables, les volumes, les fonctionnalités (magasin de fonctionnalités) et les modèles (registre de modèles). Unity Catalog peut également être utilisé pour capturer la traçabilité des données des runtimes parmi les requêtes exécutées sur les Databricks.
La supervision du lakehouse de Databricks permet de contrôler la qualité des données dans toutes les tables de votre compte. Il peut également suivre les performances des modèlesMachine Learning et des points de terminaison de mise en service de modèles.
Pour l’observabilité, les tables système sont un magasin analytique hébergé par Databricks qui contient les données opérationnelles de votre compte. Les tables système peuvent être utilisées pour l’observabilité historique de votre compte.
Moteur Data Intelligence
La plateforme de Data Intelligence de Databricks permet à l’ensemble de votre organisation d’utiliser les données et l’IA. Elle est alimentée par DatabricksIQ et combine l’IA générative avec les avantages de l’unification d’un lakehouse pour comprendre la sémantique unique de vos données.
L’Assistant Databricks est disponible dans les notebooks Databricks, l’éditeur SQL et l’éditeur de fichiers en tant qu’assistant IA prenant en charge le contexte pour les développeurs.
Orchestration
Les travaux Databricks orchestrent les pipelines de traitement de données, de Machine Learning et d’analyse sur la plateforme Databricks Data Intelligence. Delta Live Tables vous permet de créer des pipelines ETL fiables et gérables avec une syntaxe déclarative.
Architecture de référence de la plateforme de Data Intelligence sur Azure
L’architecture de référence Azure Databricks est dérivée de l’architecture de référence générique en ajoutant des services spécifiques à Azure pour les éléments Source, d’Ingestion, de Mise en service, d’Analyse/Sortie et de Stockage.
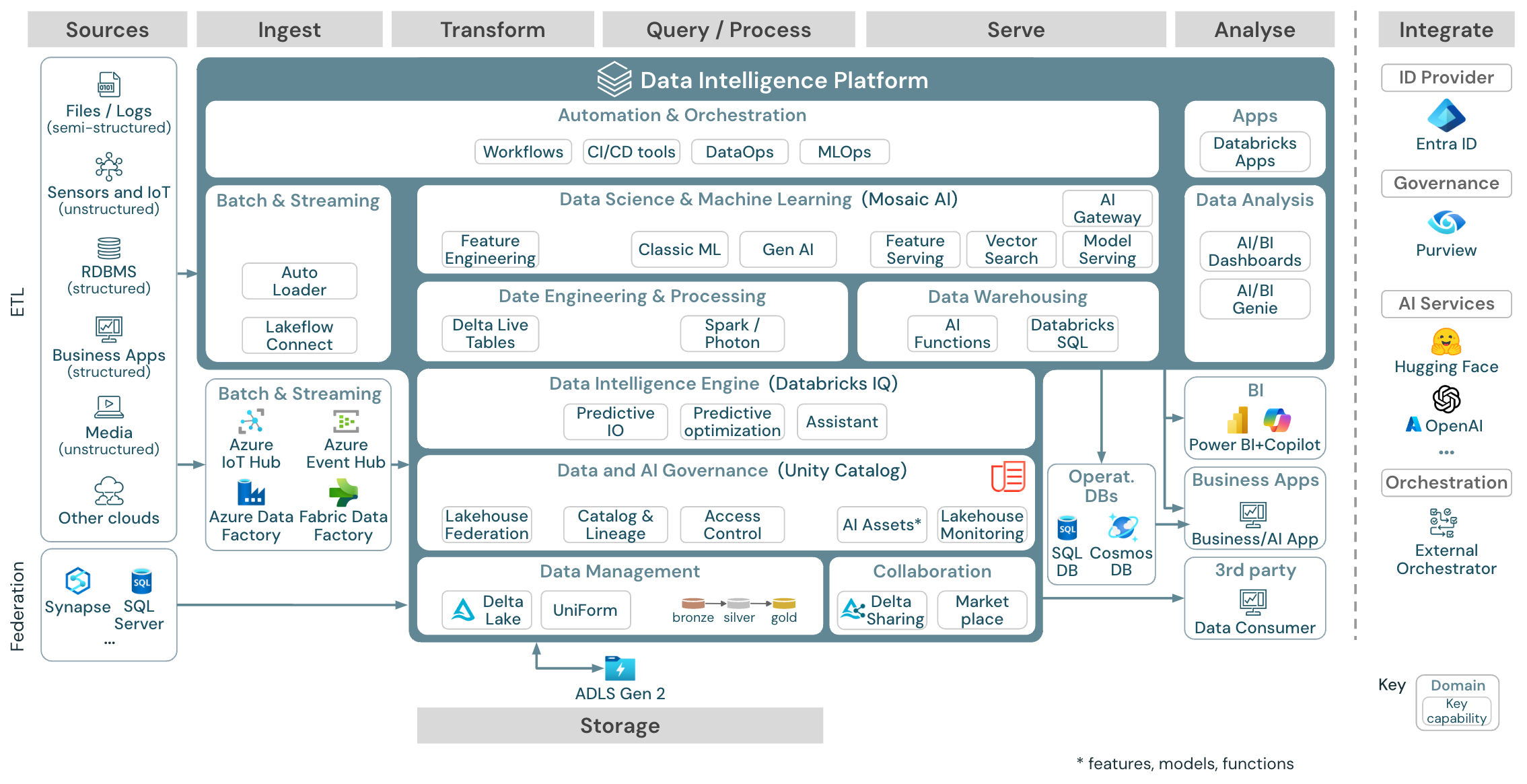
Télécharger : Architecture de référence pour le lakehouse de Databricks sur Azure
L’architecture de référence Azure présente les services spécifiques Azure suivants : Ingestion, Stockage, Mise en service et Analyse/Sortie :
- Azure Synapse et SQL Server en tant que systèmes sources pour la fédération Lakehouse
- Azure IoT Hub et Azure Event Hubs pour l’ingestion par diffusion en continu
- Azure Data Factory pour l’ingestion par lots
- Azure Data Lake Storage Gen2 (ADLS) comme stockage d’objets
- Azure SQL DB et Azure Cosmos DB en tant que bases de données opérationnelles
- Azure Purview en tant que catalogue d’entreprise vers lequel l’UC exportera les informations de schéma et de traçabilité
- Power BI en tant qu’outil décisionnel
Remarque
- Cette vue de l’architecture de référence se concentre uniquement sur les services Azure et lakehouse de Databricks. Le lakehouse sur Databricks est une plateforme ouverte qui s’intègre à un large écosystème d’outils partenaires.
- Les services des fournisseurs de services cloud présentés ne sont pas exhaustifs. Ils sont sélectionnés pour illustrer le concept.
Cas d’utilisation : ETL par lots
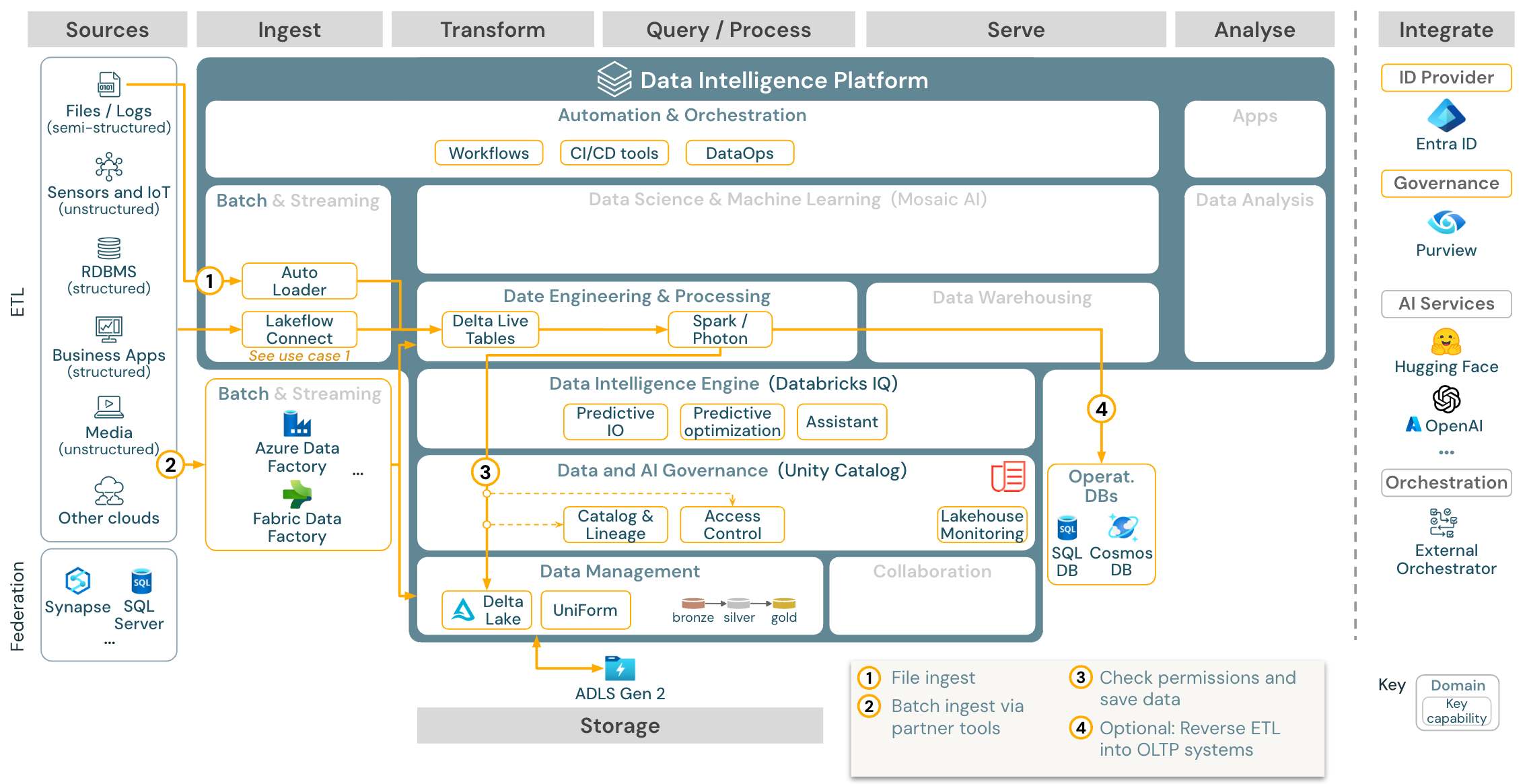
Télécharger : Architecture de référence ETL par lots pour Azure Databricks
Les outils d’ingestion utilisent des adaptateurs spécifiques à la source pour lire les données à partir de la source et ensuite soit les stocker dans le stockage cloud à partir duquel Auto Loader peut les lire, soit appeler Databricks directement (par exemple, avec des outils d’ingestion partenaires intégrés dans le lakehouse de Databricks). Pour charger les données, le moteur ETL et de traitement de Databricks (via DLT) exécute les requêtes. Les workflows à une ou plusieurs tâches peuvent être orchestrés par des travaux Databricks et régis par Unity Catalog (contrôle d’accès, audit, traçabilité, etc.). Si les systèmes opérationnels à faible latence nécessitent l’accès à des golden tables spécifiques, celles-ci peuvent être exportées vers une base de données opérationnelle telle qu’un SGBDR ou un magasin de valeurs clés à la fin du pipeline ETL.
Cas d’usage : Diffusion en continu et capture des changements de données (CDC)
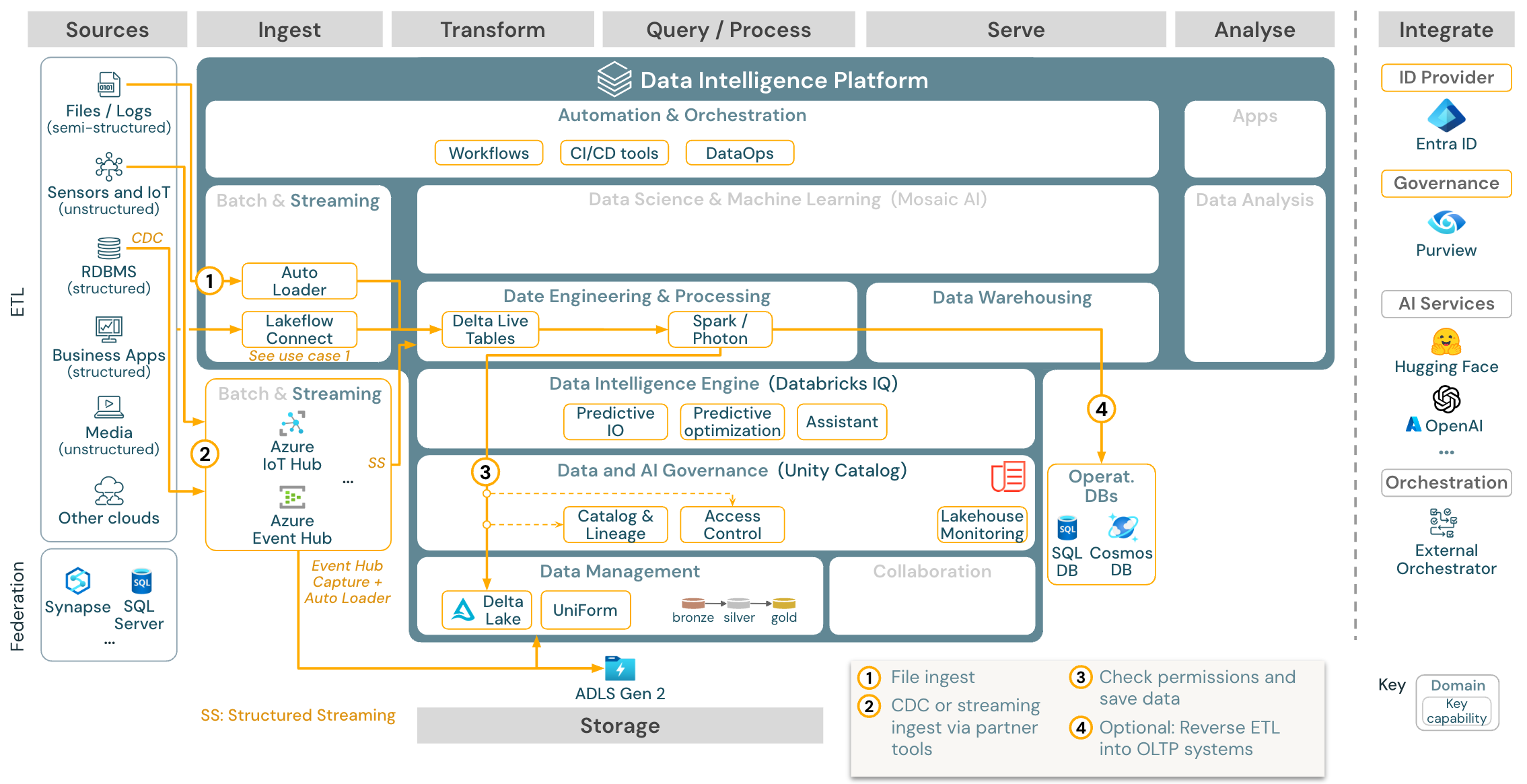
Télécharger : Architecture de diffusion en continu structurée Spark pour Azure Databricks
Le moteur Databricks ETL utilise Spark Structured Streaming pour lire les files d’attente d’événements telles que Apache Kafka ou Azure Event Hub. Les étapes en aval suivent l’approche du cas d’usage Batch ci-dessus.
La capture des changements de données (CDC) en temps réel utilise généralement une file d’attente d’événements pour stocker les événements extraits. À partir de là, le cas d’usage suit le cas d’usage de diffusion en continu.
Si le CDC est effectué par lots et que les enregistrements extraits sont d’abord stockés dans le cloud, Databricks Autoloader peut les lire et le cas d’utilisation correspond à l’ETL par lots.
Cas d’utilisation : Apprentissage automatique et IA
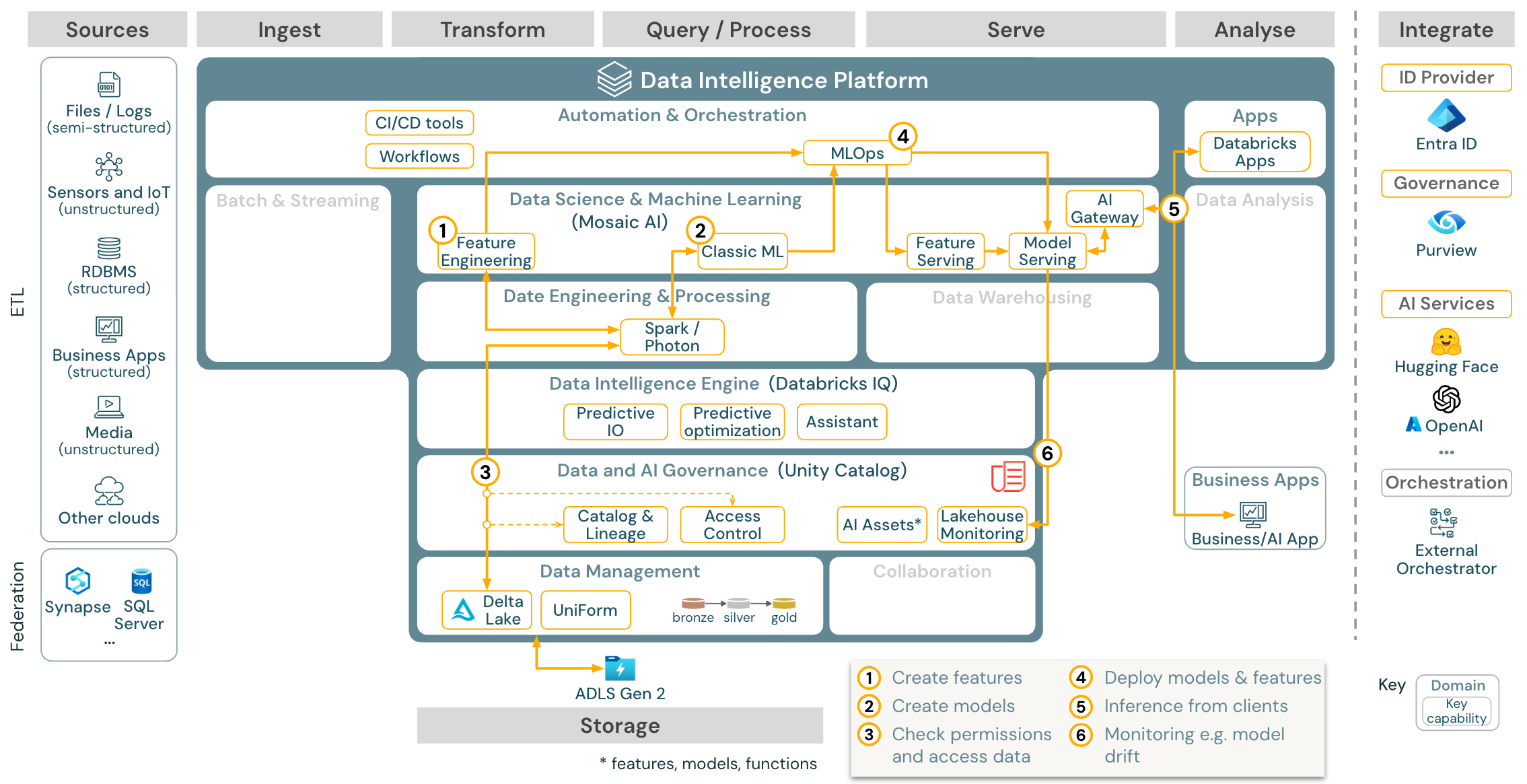
Pour l’apprentissage automatique, la plateforme de Data Intelligence de Databricks fournit Mosaic AI, qui comprend des bibliothèques d’apprentissage automatique et de deep learning à la pointe de la technologie. Il fournit des fonctionnalités telles que le Magasin de fonctionnalités et le Registre de modèles (tous deux intégrés dans Unity Catalog), des fonctionnalités à faible code avec AutoML, et l’intégration de MLflow dans le cycle de vie de la science des données.
Toutes les ressources liées à la science des données (tables, fonctionnalités et modèles) sont régies par Unity Catalog, et les scientifiques des données peuvent utiliser des travaux Databricks pour orchestrer leurs travaux.
Pour déployer des modèles de manière évolutive et à l’échelle de l’entreprise, utilisez les capacités des MLOps pour publier les modèles dans le service de modèles.
Cas d’utilisation : Génération augmentée de la recherche (Gen AI)
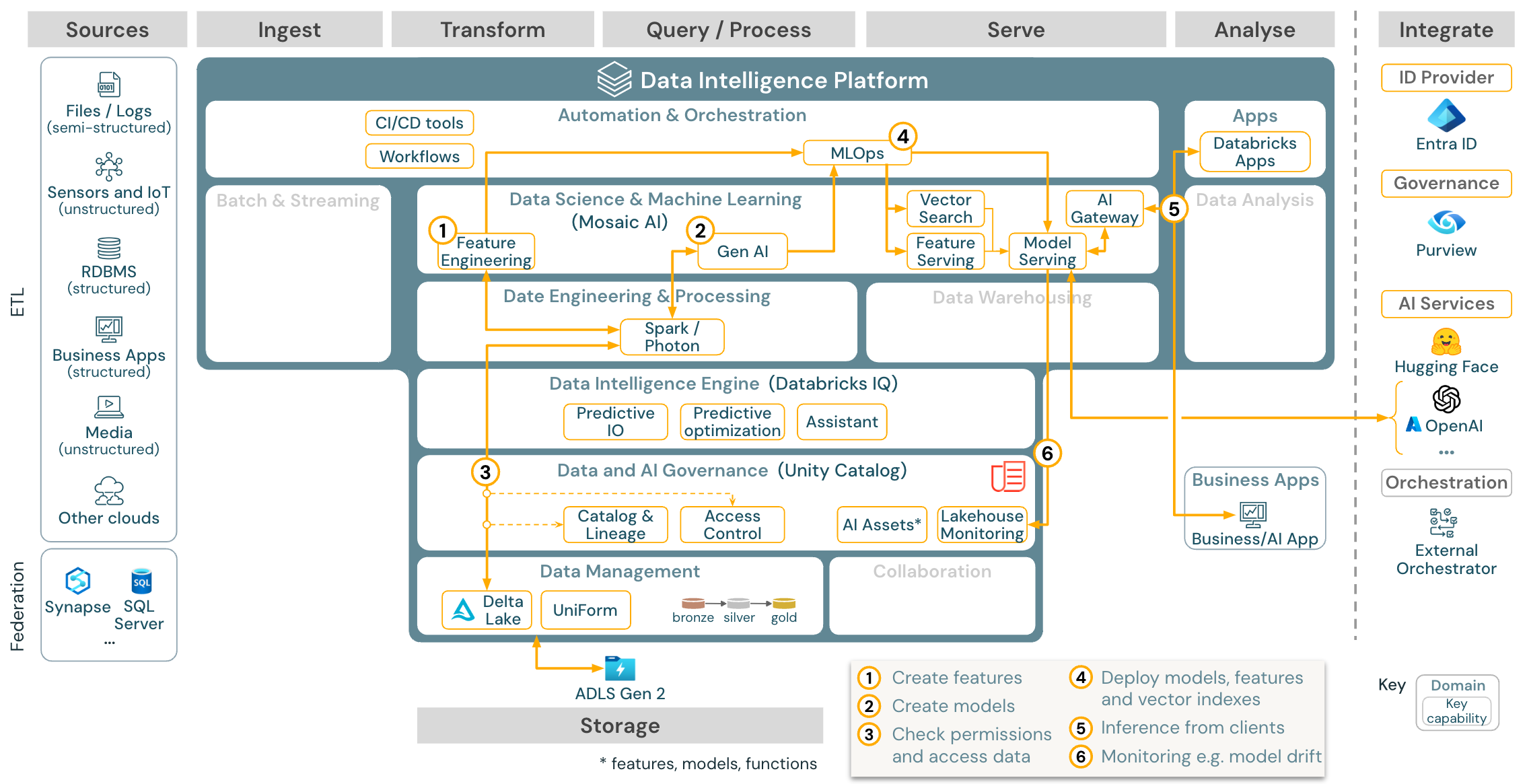
Télécharger : Architecture de référence Gen AI RAG pour Azure Databricks
Pour les cas d’usage de l’IA générative, Mosaic AI est livré avec des bibliothèques de pointe et des capacités Gen AI spécifiques allant de l’ingénierie d’invite à l’affinement des modèles existants et au préapprentissage à partir de zéro. L'architecture ci-dessus montre un exemple de la manière dont la recherche vectorielle peut être intégrée pour créer une application d'IA de type RAG (retrieval augmented generation).
Pour déployer des modèles de manière évolutive et à l’échelle de l’entreprise, utilisez les capacités des MLOps pour publier les modèles dans le service de modèles.
Cas d’usage : Business intelligence et Analytique SQL
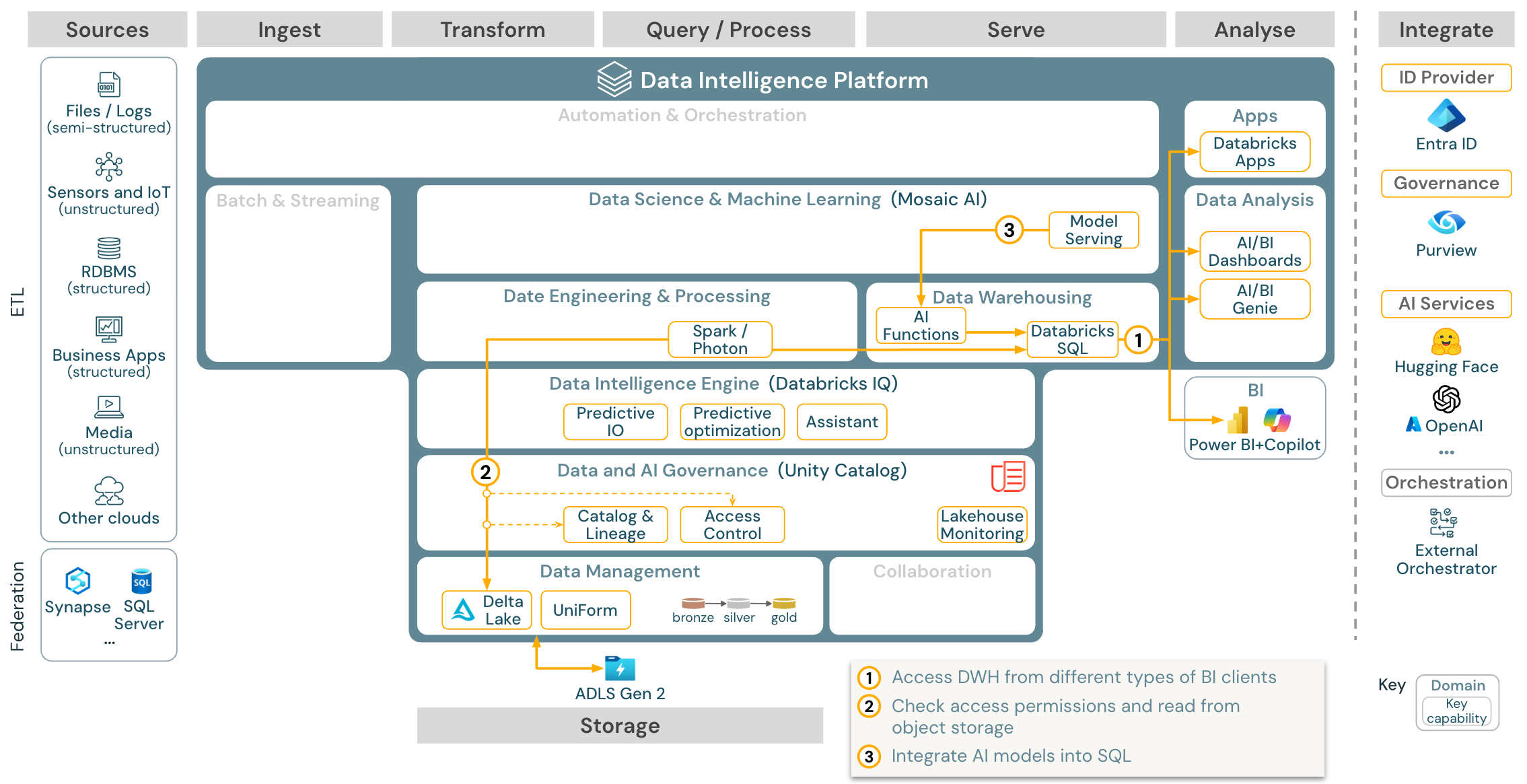
Télécharger : Architecture de référence pour la décision et l’analytique SQL pour Azure Databricks
Pour les cas d’usage de business intelligence, les analystes métier peuvent utiliser des tableaux de bord, l’éditeur Databricks SQL ou des outils de business intelligence spécifiques tels que Tableau ou Power BI. Dans tous les cas, le moteur est Databricks SQL (serverless ou non serverless) et la découverte, l’exploration et le contrôle d’accès sont assurés par Unity Catalog.
Cas d’usage : Fédération Lakehouse
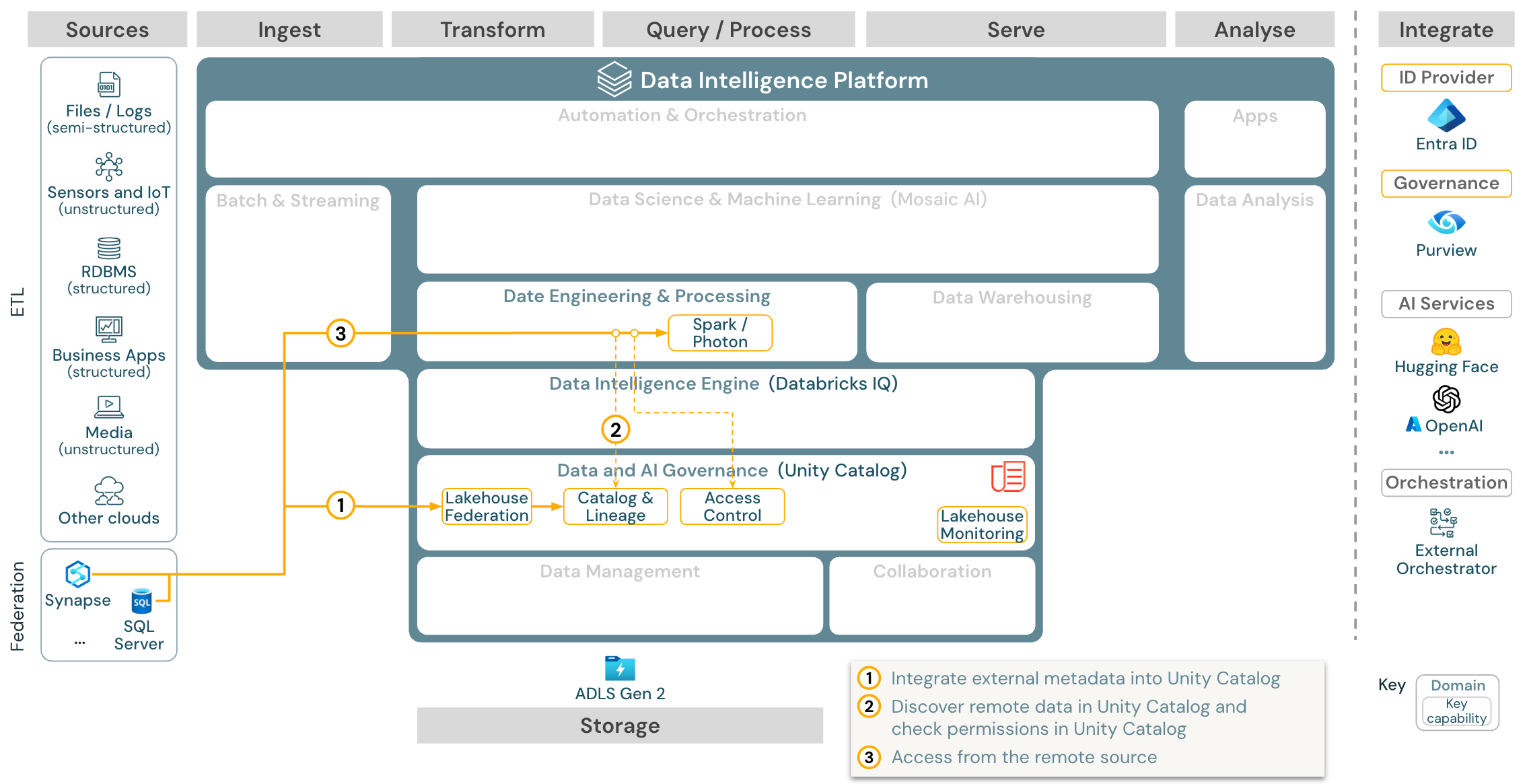
Télécharger : Architecture de référence de la fédération Lakehouse pour Azure Databricks
La fédération Lakehouse permet d’intégrer des bases de données SQL externes (telles que MySQL, Postgres, SQL Server ou Azure Synapse) à Databricks.
Toutes les charges de travail (IA, DWH et BI) peuvent en bénéficier sans qu’il soit nécessaire de procéder au préalable à l’ETL des données dans le stockage objet. Le catalogue source externe est mappé dans le catalogue Unity et le contrôle d’accès affiné peut être appliqué pour accéder via la plateforme Databricks.
Cas d’usage : Partage de données d’entreprise
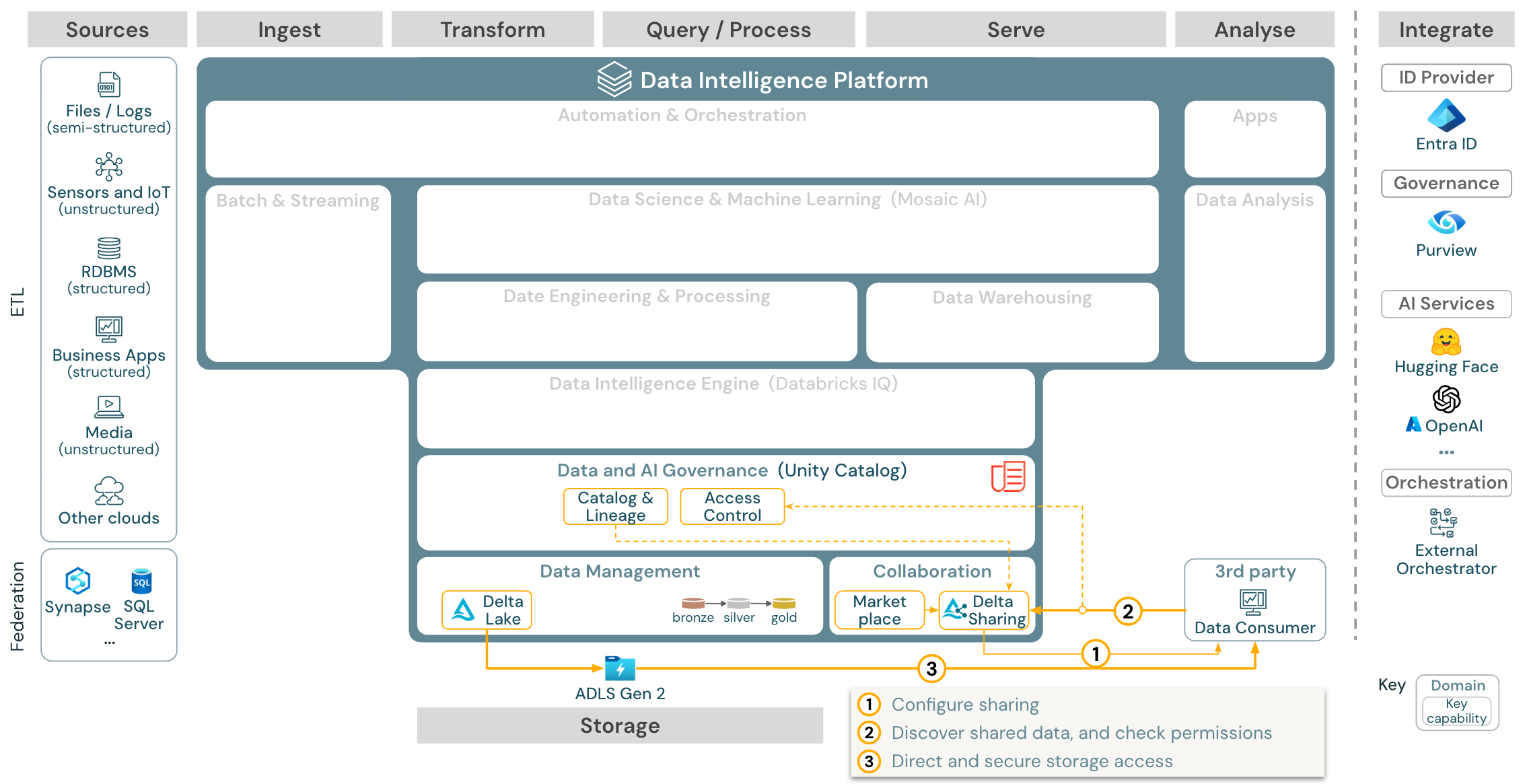
Télécharger : Architecture de référence du partage de données d’entreprise pour Azure Databricks
Le partage des données au niveau de l’entreprise est assuré par Delta Sharing. Il offre un accès direct aux données du magasin d’objets sécurisé par Unity Catalog, et la Place de marché Databricks est un forum ouvert pour l’échange de produits de données.