Créer des agents IA dans le code
Cet article explique comment créer un agent IA dans du code à l’aide de MLflow ChatModel. Azure Databricks tire parti de MLflow ChatModel pour garantir la compatibilité avec les fonctionnalités de l’agent IA Databricks telles que l’évaluation, le suivi et le déploiement.
Qu’est-ce que ChatModel ?
ChatModel est une classe MLflow conçue pour simplifier la création d’agents IA conversationnels. Il fournit une interface standardisée pour la création de modèles compatibles avec l’API ChatCompletion d’OpenAI.
ChatModel étend le schéma ChatCompletion d’OpenAI. Cette approche vous permet de maintenir une compatibilité étendue avec les plateformes prenant en charge la norme ChatCompletion, tout en ajoutant vos propres fonctionnalités personnalisées.
En utilisant ChatModel, les développeurs peuvent créer des agents compatibles avec les outils Databricks et MLflow pour le suivi, l’évaluation et la gestion du cycle de vie des agents, qui sont essentiels pour le déploiement de modèles prêts pour la production.
Consultez MLflow : Prise en main de ChatModel.
Spécifications
Databricks recommande d’installer la dernière version du client Python MLflow lors du développement d’agents.
Pour créer et déployer des agents à l’aide de l’approche décrite dans cet article, vous devez répondre aux exigences suivantes :
- Installer
databricks-agentsversion 0.15.0 et versions ultérieures - Installer
mlflowversion 2.20.0 et ultérieure
%pip install -U -qqqq databricks-agents>=0.15.0 mlflow>=2.20.0
Créer un agent ChatModel
Vous pouvez créer votre agent en tant que sous-classe de mlflow.pyfunc.ChatModel. Cette méthode offre les avantages suivants :
- Vous permet d’écrire du code de l’agent compatible avec le schéma ChatCompletion à l’aide de classes Python typées.
- MLflow déduira automatiquement une signature compatible avec l’achèvement de la conversation lors de l’enregistrement de l’agent, même en l’absence de
input_example. Cela simplifie le processus d’inscription et de déploiement de l’agent. Consultez Inférence de signature de modèle lors de l’enregistrement.
Le code suivant est le mieux exécuté dans un notebook Databricks. Les notebooks fournissent un environnement pratique pour le développement, le test et l’itération sur votre agent.
La classe MyAgent étend mlflow.pyfunc.ChatModel, implémentant la méthode predict requise. Cela garantit la compatibilité avec Mosaïque AI Agent Framework.
La classe inclut également les méthodes facultatives _create_chat_completion_chunk et les predict_stream pour gérer les sorties de diffusion en continu.
from dataclasses import dataclass
from typing import Optional, Dict, List, Generator
from mlflow.pyfunc import ChatModel
from mlflow.types.llm import (
# Non-streaming helper classes
ChatCompletionRequest,
ChatCompletionResponse,
ChatCompletionChunk,
ChatMessage,
ChatChoice,
ChatParams,
# Helper classes for streaming agent output
ChatChoiceDelta,
ChatChunkChoice,
)
class MyAgent(ChatModel):
"""
Defines a custom agent that processes ChatCompletionRequests
and returns ChatCompletionResponses.
"""
def predict(self, context, messages: list[ChatMessage], params: ChatParams) -> ChatCompletionResponse:
last_user_question_text = messages[-1].content
response_message = ChatMessage(
role="assistant",
content=(
f"I will always echo back your last question. Your last question was: {last_user_question_text}. "
)
)
return ChatCompletionResponse(
choices=[ChatChoice(message=response_message)]
)
def _create_chat_completion_chunk(self, content) -> ChatCompletionChunk:
"""Helper for constructing a ChatCompletionChunk instance for wrapping streaming agent output"""
return ChatCompletionChunk(
choices=[ChatChunkChoice(
delta=ChatChoiceDelta(
role="assistant",
content=content
)
)]
)
def predict_stream(
self, context, messages: List[ChatMessage], params: ChatParams
) -> Generator[ChatCompletionChunk, None, None]:
last_user_question_text = messages[-1].content
yield self._create_chat_completion_chunk(f"Echoing back your last question, word by word.")
for word in last_user_question_text.split(" "):
yield self._create_chat_completion_chunk(word)
agent = MyAgent()
model_input = ChatCompletionRequest(
messages=[ChatMessage(role="user", content="What is Databricks?")]
)
response = agent.predict(context=None, model_input=model_input)
print(response)
Pendant que la classe d’agent MyAgent est définie dans un bloc-notes, vous devez créer un bloc-notes de pilote distinct. Le bloc-notes du pilote enregistre l’agent dans le Registre de modèles et déploie l’agent à l’aide de Model Serve.
Cette séparation suit le flux de travail recommandé par Databricks pour l’enregistrement des modèles à l'aide de la méthodologie "Models from Code" de MLflow.
Exemple : encapsuler LangChain dans ChatModel
Si vous disposez d’un modèle LangChain existant et que vous souhaitez l’intégrer à d’autres fonctionnalités de l’agent Mosaic AI, vous pouvez l’encapsuler dans un ChatModel MLflow pour garantir la compatibilité.
Cet exemple de code effectue les étapes suivantes pour encapsuler un LangChain exécutable en tant que ChatModel:
- Encapsuler la sortie finale de LangChain avec
mlflow.langchain.output_parsers.ChatCompletionOutputParserpour produire une signature de sortie de fin de conversation - La classe
LangchainAgentétendmlflow.pyfunc.ChatModelet implémente deux méthodes clés :predict: gère les prédictions synchrones en appelant la chaîne et en retournant une réponse mise en forme.predict_stream: gère les prédictions de diffusion en continu en appelant la chaîne et en produisant des blocs de réponses.
from mlflow.langchain.output_parsers import ChatCompletionOutputParser
from mlflow.pyfunc import ChatModel
from typing import Optional, Dict, List, Generator
from mlflow.types.llm import (
ChatCompletionResponse,
ChatCompletionChunk
)
chain = (
<your chain here>
| ChatCompletionOutputParser()
)
class LangchainAgent(ChatModel):
def _prepare_messages(self, messages: List[ChatMessage]):
return {"messages": [m.to_dict() for m in messages]}
def predict(
self, context, messages: List[ChatMessage], params: ChatParams
) -> ChatCompletionResponse:
question = self._prepare_messages(messages)
response_message = self.chain.invoke(question)
return ChatCompletionResponse.from_dict(response_message)
def predict_stream(
self, context, messages: List[ChatMessage], params: ChatParams
) -> Generator[ChatCompletionChunk, None, None]:
question = self._prepare_messages(messages)
for chunk in chain.stream(question):
yield ChatCompletionChunk.from_dict(chunk)
Utiliser des paramètres pour configurer l’agent
Dans Agent Framework, vous pouvez utiliser des paramètres pour contrôler la façon dont les agents sont exécutés. Cela vous permet d’itérer rapidement en modifiant les caractéristiques de votre agent sans modifier le code. Les paramètres sont des paires clé-valeur que vous définissez dans un dictionnaire Python ou un fichier .yaml.
Pour configurer le code, créez un ModelConfig, un ensemble de paramètres clé-valeur. ModelConfig est un dictionnaire Python ou un fichier .yaml. Par exemple, vous pouvez utiliser un dictionnaire pendant le développement, puis le convertir en fichier .yaml pour le déploiement de production et CI/CD. Pour plus d’informations sur ModelConfig, consultez la documentation MLflow.
Un exemple ModelConfig est illustré ci-dessous.
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
Pour appeler la configuration à partir de votre code, utilisez l’une des options suivantes :
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
value = model_config.get('sample_param')
Définir le schéma de l’extracteur
Les agents IA utilisent souvent des récupérateurs, un type d’outil d’agent qui recherche et retourne des documents pertinents à l’aide d’un index recherche vectorielle. Pour plus d’informations sur les récupérateurs, consultez Outils d’assistant IA de récupération non structurés.
Pour vous assurer que les retrieveurs sont correctement suivis, appelez mlflow.models.set_retriever_schema lorsque vous définissez votre agent dans le code. Utilisez set_retriever_schema pour mapper les noms de colonnes dans la table retournée aux champs attendus de MLflow, tels que primary_key, text_column et doc_uri.
# Define the retriever's schema by providing your column names
# These strings should be read from a config dictionary
mlflow.models.set_retriever_schema(
name="vector_search",
primary_key="chunk_id",
text_column="text_column",
doc_uri="doc_uri"
# other_columns=["column1", "column2"],
)
Remarque
La colonne doc_uri est particulièrement importante lors de l’évaluation des performances du dispositif de récupération. doc_uri est l’identificateur principal des documents retournés par le récupérateur, ce qui vous permet de les comparer aux jeux d’évaluation de la vérité de terrain. Consultez ensembles d'évaluation.
Vous pouvez également spécifier des colonnes supplémentaires dans le schéma de votre extracteur en fournissant une liste de noms de colonnes avec le champ other_columns.
Si vous avez plusieurs extracteurs, vous pouvez définir plusieurs schémas à l’aide de noms uniques pour chacun d’entre eux.
Entrées et sorties personnalisées
Certains scénarios peuvent nécessiter des entrées d’agents supplémentaires, telles que client_type et session_id, ou des sorties telles que les liens sources de récupération qui ne doivent pas être inclus dans l’historique des conversations pour les interactions futures.
Pour ces scénarios, ChatModel MLflow prend de manière native en charge l’augmentation des demandes et réponses de fin de conversation OpenAI avec les champs ChatParams custom_input et custom_output.
Consultez les exemples suivants pour découvrir comment créer des entrées et des sorties personnalisées pour les agents PyFunc et LangGraph.
Avertissement
L'application de révision de l'évaluation de l'agent ne prend actuellement pas en charge la génération des traces pour les agents comportant des champs d'entrée supplémentaires.
Schémas personnalisés PyFunc
Les notebooks suivants montrent un exemple de schéma personnalisé utilisant PyFunc.
Bloc-notes de l’agent de schéma personnalisé PyFunc
Bloc-notes du pilote de schéma personnalisé PyFunc
Schémas personnalisés LangGraph
Les notebooks suivants montrent un exemple de schéma personnalisé en utilisant LangGraph. Vous pouvez modifier la fonction wrap_output dans les blocs-notes pour analyser et extraire des informations du flux de messages.
Bloc-notes de l’agent de schéma personnalisé LangGraph
Bloc-notes du pilote de schéma personnalisé LangGraph
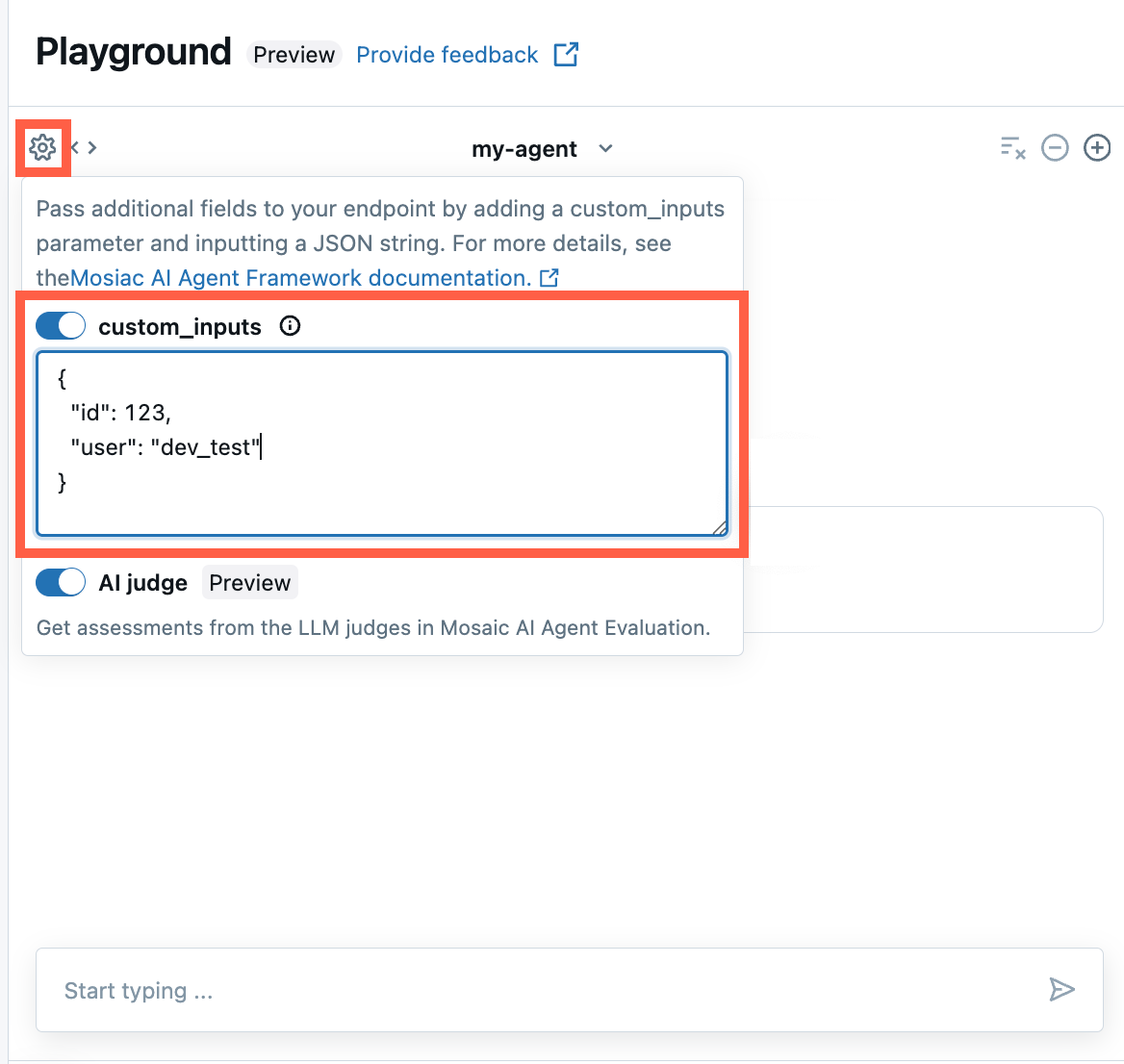
Fournir custom_inputs dans l’application AI Playground et l’application de révision d’agent
Si votre agent accepte des entrées supplémentaires à l’aide du champ custom_inputs, vous pouvez fournir manuellement ces entrées à la fois dans le AI Playground et dans l'application de révision de l'agent .
Dans l’application AI Playground ou de révision d’agent, sélectionnez l’icône en forme d’engrenage
 .
.Activez custom_inputs.
Fournissez un objet JSON qui correspond au schéma d’entrée défini de votre agent.
Propagation des erreurs de streaming
Propagation Mosaic AI des erreurs rencontrées lors du streaming avec le dernier jeton sous databricks_output.error. Il incombe au client appelant de gérer correctement et de faire apparaître cette erreur.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute"
}
}
}
Exemples de notebooks
Ces notebooks créent une chaîne simple « Hello, world » pour illustrer la création d’un agent dans Databricks. Le premier exemple crée une chaîne simple, et le deuxième exemple de notebook montre comment utiliser des paramètres pour réduire les modifications de code pendant le développement.