Définir le schéma d’entrée et de sortie d’un agent
Les signatures de modèle MLflow définissent les exigences de schéma d’entrée et de sortie pour votre agent IA. La signature de modèle indique aux composants internes et externes comment interagir avec votre agent. La signature de modèle est une vérification de validation pour s’assurer que les entrées respectent les exigences de schéma.
Par exemple, pour utiliser l’application de révision d’évaluation de l’agent, votre agent doit respecter le schéma d’entrée d’évaluation de l’agent.
Schémas d’entrée pris en charge
Mosaïque AI Agent Framework prend en charge les schémas d’entrée suivants.
Schéma d’achèvement de conversation OpenAI
Remarque
Databricks recommande le schéma d’achèvement de conversation OpenAI, car il est largement utilisé et interopérable avec de nombreuses infrastructures et applications d’agent. Si le schéma d’achèvement de conversation OpenAI ne répond pas à vos besoins, vous pouvez définir votre propre schéma. Consultez les schémas d’agent personnalisé.
(Recommandé) Databricks recommande d’utiliser le schéma d’achèvement de conversation OpenAI. Le schéma d’achèvement de conversation OpenAI doit avoir un tableau d’objets en tant que
messagesparamètre. Ce format est idéal pour les applications RAG.question = { "messages": [ { "role": "user", "content": "What is Retrieval-Augmented Generation?", }, { "role": "assistant", "content": "RAG, or Retrieval Augmented Generation, is a generative AI design pattern that combines a large language model (LLM) with external knowledge retrieval. This approach allows for real-time data connection to generative AI applications, improving their accuracy and quality by providing context from your data to the LLM during inference. Databricks offers integrated tools that support various RAG scenarios, such as unstructured data, structured data, tools & function calling, and agents.", }, { "role": "user", "content": "How to build RAG for unstructured data", }, ] }
SplitChatMessageRequest
SplitChatMessagesRequest est recommandé pour les applications de conversation multitours, en particulier lorsque vous souhaitez gérer séparément la requête et l’historique actuels.
question = {
"query": "What is MLflow",
"history": [
{
"role": "user",
"content": "What is Retrieval-augmented Generation?"
},
{
"role": "assistant",
"content": "RAG is"
}
]
}
Langchain Expression Language
Si votre agent utilise LangChain, vous pouvez écrire votre chaîne dans le langage d’expression LangChain. Dans votre code de définition de chaîne, vous pouvez utiliser un itemgetter pour obtenir les messages ou query history les objets en fonction de votre format d’entrée.
Schémas de sortie pris en charge
Mosaïque AI Agent Framework prend en charge les schémas de sortie suivants.
ChatCompletionResponse
(Recommandé) ChatCompletionResponse est recommandé pour les clients disposant de l’interopérabilité du format de réponse OpenAI.
LangChain - ChatCompletionsOutputParser
Si votre agent utilise LangChain, utilisez ChatCompletionsOutputParser() MLflow comme étape de chaîne finale. Cela met en forme le message LangChain AI dans un format compatible avec l’agent.
from mlflow.langchain.output_parsers import ChatCompletionsOutputParser
chain = (
{
"user_query": itemgetter("messages")
| RunnableLambda(extract_user_query_string),
"chat_history": itemgetter("messages") | RunnableLambda(extract_chat_history),
}
| RunnableLambda(DatabricksChat)
| ChatCompletionsOutputParser()
)
PyFunc - annoter les classes d’entrée et de sortie
Si vous utilisez PyFunc, Databricks recommande d’utiliser des indicateurs de type pour annoter la fonction predict() avec des classes de données d’entrée et de sortie qui sont des sous-classes de classes définies dans mlflow.models.rag_signatures.
Vous pouvez construire un objet de sortie à partir de la classe de données à l’intérieur predict(). L’objet retourné doit être transformé en représentation de dictionnaire afin de garantir qu’il puisse être sérialisé.
from mlflow.models.rag_signatures import ChatCompletionRequest, ChatCompletionResponse, ChainCompletionChoice, Message
class RAGModel(PythonModel):
...
def predict(self, context, model_input: ChatCompletionRequest) -> ChatCompletionResponse:
...
return asdict(ChatCompletionResponse(
choices=[ChainCompletionChoice(message=Message(content=text))]
))
Signatures explicites et déduites
MLflow peut déduire le schéma d’entrée et de sortie de votre agent au moment de l’exécution et créer automatiquement une signature. Si vous utilisez des schémas d’entrée et de sortie pris en charge, les signatures déduites sont compatibles avec Agent Framework. Pour plus d’informations sur les schémas pris en charge, consultez Schémas d’entrée pris en charge.
Toutefois, si vous utilisez un schéma d’agent personnalisé, vous devez définir explicitement votre signature de modèle en fonction des instructions fournies dans les schémas d’agent personnalisé.
Schémas d’agent personnalisés
Vous pouvez personnaliser le schéma d’un agent pour passer et retourner des champs supplémentaires vers et depuis l’agent en créant une sous-classe d’un schéma d’entrée/sortie pris en charge. Ensuite, ajoutez les clés custom_inputs supplémentaires et custom_outputs pour contenir les champs supplémentaires. Consultez des exemples de code pour Pyfunc et Langchain et une méthode basée sur l’interface utilisateur pour utiliser des entrées personnalisées.
Pour utiliser le databricks-agents Kit de développement logiciel (SDK), les interfaces utilisateur clientes Databricks, telles que le terrain de jeu d’intelligence artificielle ia et l’application de révision, ainsi que d’autres fonctionnalités de l’infrastructure de l’agent AI Mosaïque, doivent répondre aux exigences suivantes :
- L’agent doit utiliser
mlflowla version 2.17.1 ou ultérieure. - Dans le bloc-notes de l’agent, marquez les champs supplémentaires ajoutés dans votre sous-classe en tant que
Optionalvaleurs par défaut. - Dans le bloc-notes du pilote, construisez une
ModelSignatureutilisation avecinfer_signaturedes instances de vos sous-classes. - Dans le bloc-notes du pilote, créez un exemple d’entrée en appelant
asdictvotre sous-classe.
Schémas personnalisés PyFunc
En plus des exigences ci-dessus, les agents PyFunc doivent également répondre aux exigences suivantes pour interagir avec les fonctionnalités de l’agent Mosaïque IA.
Configuration requise pour le schéma personnalisé PyFunc
Dans le notebook de l’agent, les fonctions de prédiction et de prédiction de flux doivent répondre aux exigences suivantes :
- Avoir des indicateurs de type pour votre sous-classe d’entrée.
- Utilisez la notation par points pour accéder aux champs de la classe de données (par exemple, utilisez
model_input.custom_input.idplutôt quemodel_input["custom_inputs"]). - Retournez une
dictionary. Vous pouvez appelerasdictune instance de votre sous-classe pour mettre en forme le retour en tant que dictionnaire.
Les notebooks suivants montrent un exemple de schéma personnalisé à l’aide de PyFunc.
Bloc-notes de l’agent de schéma personnalisé PyFunc
Bloc-notes du pilote de schéma personnalisé PyFunc
Schémas personnalisés Langchain
Les notebooks suivants montrent un exemple de schéma personnalisé à l’aide de LangChain. Vous pouvez modifier la fonction wrap_output dans les blocs-notes pour analyser et extraire des informations du flux de messages.
Bloc-notes de l’agent de schéma personnalisé Langchain
Bloc-notes du pilote de schéma personnalisé Langchain
Fournir custom_inputs dans l’application de révision de l’ia Playground et de l’agent
Si vous définissez un schéma d’agent personnalisé avec des entrées supplémentaires à l’aide du custom_inputs champ, vous pouvez fournir manuellement ces entrées dans ai Playground et l’application de révision de l’agent. Si aucune entrée personnalisée n’est fournie, l’agent utilise les valeurs par défaut spécifiées dans votre schéma.
Dans le terrain de jeu IA ou l’application de révision de l’agent, sélectionnez l’icône
 d’engrenage .
d’engrenage .Activez custom_inputs.
Fournissez un objet JSON qui correspond au schéma d’entrée défini de votre agent.
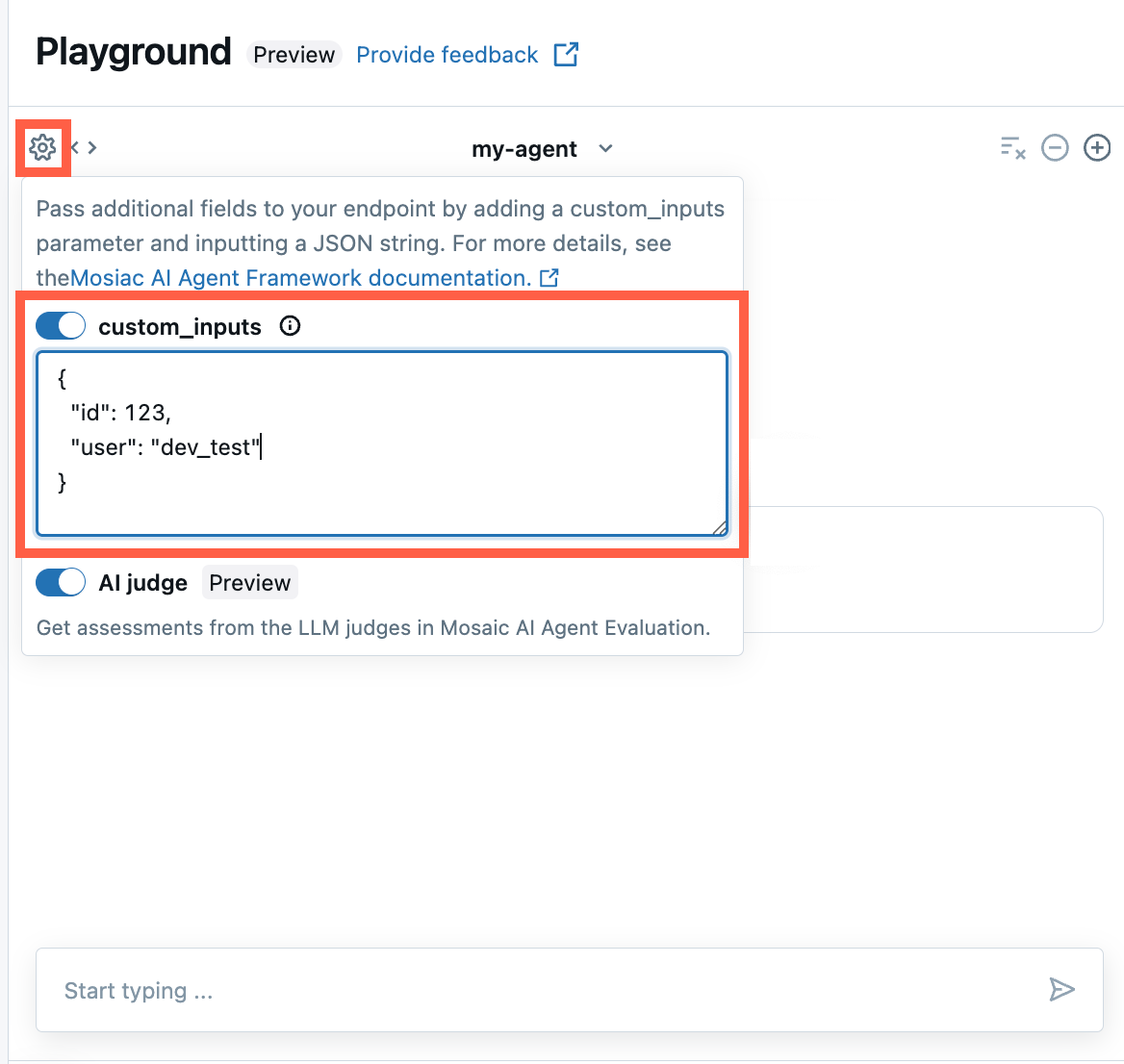
L’objet JSON doit correspondre au schéma d’entrée de l’agent. Par exemple, si vous avez une custom_inputs classe de données définie comme suit :
@dataclass
class CustomInputs():
id: int = 0
user: str = "default"
Ensuite, la chaîne JSON que vous entrez dans le champ custom_inputs doit fournir des valeurs id et user, comme illustré dans l’exemple suivant :
{
"id": 123
"user": "dev_test",
}