Transformer des données avec des pipelines
Cet article explique comment vous pouvez utiliser Delta Live Tables pour déclarer des transformations sur des jeux de données, et spécifier la façon dont les enregistrements sont traités via la logique de requête. Il contient également des exemples de modèles de transformation courants pour la création de pipelines Delta Live Tables.
Vous pouvez définir un jeu de données pour n’importe quelle requête retournant un DataFrame. Vous pouvez utiliser des opérations intégrées Apache Spark, des fonctions définies par l’utilisateur, une logique personnalisée et les modèles MLflow en tant que transformations dans votre pipeline Delta Live Tables. Une fois que les données ont été ingérées dans votre pipeline Delta Live Tables, vous pouvez définir de nouveaux jeux de données sur des sources en amont pour créer de nouvelles tables de streaming, des vues matérialisées et des vues.
Pour savoir comment effectuer efficacement un traitement avec état avec Delta Live Tables, consultez Optimiser le traitement avec état dans Delta Live Tables avec des filigranes.
Quand utiliser les vues, les vues matérialisées et les tables de streaming
Lors de l’implémentation de vos requêtes de pipeline, choisissez le meilleur type de jeu de données pour vous assurer qu’ils sont efficaces et gérables.
Envisagez d’utiliser une vue pour effectuer les opérations suivantes :
- Arrêtez une requête volumineuse ou complexe que vous souhaitez gérer plus facilement.
- Validez les résultats intermédiaires à l’aide des attentes.
- Réduisez les coûts de stockage et de calcul pour les résultats que vous n’avez pas besoin de conserver. Étant donné que les tables sont matérialisées, elles nécessitent des ressources de calcul et de stockage supplémentaires.
Utilisez une vue matérialisée dans les cas suivants :
- Plusieurs requêtes en aval consomment la table. Étant donné que les vues sont calculées à la demande, la vue est calculée à nouveau chaque fois que la vue est interrogée.
- D’autres pipelines, travaux ou requêtes consomment la table. Étant donné que les vues ne sont pas matérialisées, vous ne pouvez les utiliser que dans le même pipeline.
- Vous souhaitez afficher les résultats d’une requête pendant le développement. Étant donné que les tables sont matérialisées et peuvent être consultées et interrogées en dehors du pipeline, l’utilisation de tables pendant le développement peut vous aider à valider l’exactitude des calculs. Après la validation, convertissez les requêtes qui ne nécessitent pas de matérialisation en vues.
Utilisez une table de streaming dans les cas suivants :
- Une requête est définie sur une source de données qui augmente en continu ou de manière incrémentielle.
- Les résultats de requête doivent être calculés de manière incrémentielle.
- Le pipeline a besoin d’un débit élevé et d’une faible latence.
Remarque
Les tables de streaming sont toujours définies sur des sources de streaming. Vous pouvez également utiliser des sources de streaming avec APPLY CHANGES INTO pour appliquer des mises à jour à partir de flux CDC. Voir API APPLY CHANGES : Simplifier la capture des changements de données dans Delta Live Tables.
Exclure les tables du schéma cible
Si vous devez calculer des tables intermédiaires non destinées à une consommation externe, vous pouvez les empêcher d’être publiées dans un schéma à l’aide du TEMPORARY mot clé. Les tables temporaires stockent et traitent toujours les données en fonction de la sémantique Delta Live Tables, mais elles ne doivent pas être accessibles en dehors du pipeline actuel. Une table temporaire persiste pendant la durée de vie du pipeline qui la crée. Utilisez la syntaxe suivante pour déclarer des tables temporaires :
SQL
CREATE TEMPORARY STREAMING TABLE temp_table
AS SELECT ... ;
Python
@dlt.table(
temporary=True)
def temp_table():
return ("...")
Combiner des tables de streaming et des vues matérialisées dans un même pipeline
Les tables de streaming héritent des garanties de traitement d’Apache Spark Structured Streaming, et sont configurées pour traiter les requêtes provenant de sources de données avec ajout uniquement, où les nouvelles lignes sont toujours insérées dans la table source au lieu d’être modifiées.
Remarque
Bien que, par défaut, les tables de diffusion en continu nécessitent des sources de données en ajout uniquement, quand une source de diffusion en continu est une autre table de diffusion en continu qui nécessite des mises à jour ou des suppressions, vous pouvez remplacer ce comportement en utilisant l’indicateur skipChangeCommits.
Un modèle de streaming courant implique l’ingestion de données sources pour créer les jeux de données initiaux dans un pipeline. Ces jeux de données initiaux sont couramment appelés tables bronze et effectuent souvent des transformations simples.
En revanche, les tables finales d’un pipeline, communément appelées tables d’or, nécessitent souvent des agrégations complexes ou une lecture à partir de cibles d’une APPLY CHANGES INTO opération. Dans la mesure où ces opérations créent par nature des mises à jour plutôt que des ajouts, elles ne sont pas prises en charge en tant qu’entrées dans les tables de streaming. Ces transformations sont plus adaptées aux vues matérialisées.
En combinant les tables de streaming et les vues matérialisées dans un seul pipeline, vous pouvez simplifier votre pipeline, éviter une réingestion ou un retraitement coûteux des données brutes, et disposer de toute la puissance du SQL pour calculer des agrégations complexes sur un jeu de données codé et filtré efficacement. L’exemple suivant illustre ce type de traitement mixte :
Remarque
Ces exemples utilisent Auto Loader pour charger des fichiers à partir du stockage cloud. Si vous souhaitez charger des fichiers avec Auto Loader dans un pipeline pour lequel Unity Catalog est activé, vous devez utiliser des emplacements externes. Pour en savoir plus sur l’utilisation de Unity Catalog avec Delta Live Tables, consultez l’article Utiliser Unity Catalog avec vos pipelines Delta Live Tables.
Python
@dlt.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://path/to/raw/data")
)
@dlt.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return spark.readStream.table("streaming_bronze").where(...)
@dlt.table
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return spark.readStream.table("streaming_silver").groupBy("user_id").count()
SQL
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM read_files(
"abfss://path/to/raw/data", "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM streaming_silver GROUP BY user_id
En savoir plus sur l’utilisation du chargeur automatique pour ingérer de manière incrémentielle des fichiers JSON à partir du stockage Azure.
Jointures statiques de flux
Les jointures statiques de flux sont un bon choix pour la dénormalisation d’un flux continu de données avec ajout uniquement sur une table de dimension principalement statique.
À chaque mise à jour du pipeline, les nouveaux enregistrements du flux sont joints à la capture instantanée la plus récente de la table statique. Si des enregistrements sont ajoutés ou mis à jour dans la table statique après le traitement des données correspondantes de la table de streaming, les enregistrements résultants ne sont pas recalculés, sauf si une actualisation complète est effectuée.
Dans les pipelines configurés pour l’exécution déclenchée, la table statique retourne les résultats au moment du démarrage de la mise à jour. Dans les pipelines configurés pour l’exécution continue, la version la plus récente de la table statique est interrogée chaque fois que la table traite une mise à jour.
Voici un exemple de jointure statique de flux :
Python
@dlt.table
def customer_sales():
return spark.readStream.table("sales").join(spark.readStream.table("customers"), ["customer_id"], "left")
SQL
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(sales)
INNER JOIN LEFT customers USING (customer_id)
Calculer efficacement les agrégats
Vous pouvez utiliser des tables de streaming pour calculer de manière incrémentielle des agrégats distributifs simples, par exemple le nombre, la valeur minimale, la valeur maximale ou la somme, et des agrégats algébriques tels que la moyenne ou l’écart type. Databricks recommande l’agrégation incrémentielle pour les requêtes avec un nombre limité de groupes, comme une requête avec une GROUP BY country clause. Seules les nouvelles données d’entrée sont lues à chaque mise à jour.
Pour en savoir plus sur l’écriture de requêtes Delta Live Tables qui effectuent des agrégations incrémentielles, consultez Effectuer des agrégations fenêtrées avec des filigranes.
Utiliser des modèles MLflow dans un pipeline de tables dynamiques Delta
Remarque
Pour utiliser les modèles MLflow dans un pipeline compatible avec Unity Catalog, celui-ci doit être configuré pour utiliser le canal preview. Pour utiliser le canal current, votre pipeline doit être configuré pour publier dans le Metastore Hive.
Vous pouvez utiliser des modèles entraînés par MLflow dans des pipelines Delta Live Tables. Les modèles MLflow sont traités comme des transformations dans Azure Databricks, ce qui signifie qu’ils agissent sur une entrée de DataFrame Spark, et qu’ils retournent des résultats sous la forme d’un DataFrame Spark. Étant donné que delta Live Tables définit des jeux de données sur des DataFrames, vous pouvez convertir des charges de travail Apache Spark qui utilisent MLflow en tables dynamiques Delta avec seulement quelques lignes de code. Pour plus d’informations sur MLflow, consultez MLflow pour l’agent IA générative et le cycle de vie du modèle ML.
Si vous disposez déjà d’un notebook Python appelant un modèle MLflow, vous pouvez adapter ce code à Delta Live Tables en utilisant l’élément décoratif @dlt.table et en vérifiant que les fonctions sont définies pour retourner les résultats de la transformation. Delta Live Tables n’installe pas MLflow par défaut. Vérifiez donc que vous avez installé les bibliothèques MLFlow avec %pip install mlflow et que vous avez importé mlflow et dlt en haut de votre bloc-notes. Pour une présentation de la syntaxe Delta Live Tables, consultez Développer du code de pipeline avec Python.
Pour utiliser des modèles MLflow dans Delta Live Tables, suivez les étapes ci-dessous :
- Obtenez l’ID d’exécution et le nom de modèle du modèle MLflow. L’ID d’exécution et le nom de modèle sont utilisés pour construire l’URI du modèle MLflow.
- Utilisez l’URI pour définir une FDU Spark afin de charger le modèle MLflow.
- Appelez l’UDF dans vos définitions de table pour utiliser le modèle MLflow.
L’exemple suivant illustre la syntaxe de base de ce modèle :
%pip install mlflow
import dlt
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dlt.table
def model_predictions():
return spark.read.table(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
Voici un exemple complet où le code suivant comporte une fonction Spark définie par l’utilisateur, nommée loaded_model_udf, qui charge un modèle MLflow entraîné sur des données relatives à des risques de prêt. Les colonnes de données utilisées pour effectuer la prédiction sont passées en tant qu’argument à la fonction définie par l’utilisateur. La table loan_risk_predictions calcule les prédictions pour chaque ligne de loan_risk_input_data.
%pip install mlflow
import dlt
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dlt.table(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return spark.read.table("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
Conserver les suppressions ou mises à jour manuelles
Delta Live Tables vous permet de supprimer ou de mettre à jour manuellement les enregistrements d’une table, et d’effectuer une opération d’actualisation pour recalculer les tables en aval.
Par défaut, Delta Live Tables recalcule les résultats des tables en fonction des données d’entrée chaque fois qu’un pipeline est mis à jour. Vous devez donc vérifier que l’enregistrement supprimé n’est pas rechargé à partir des données sources. La définition de la pipelines.reset.allowed propriété de table pour false empêcher les actualisations d’une table, mais n’empêche pas les écritures incrémentielles dans les tables ou les nouvelles données de circuler dans la table.
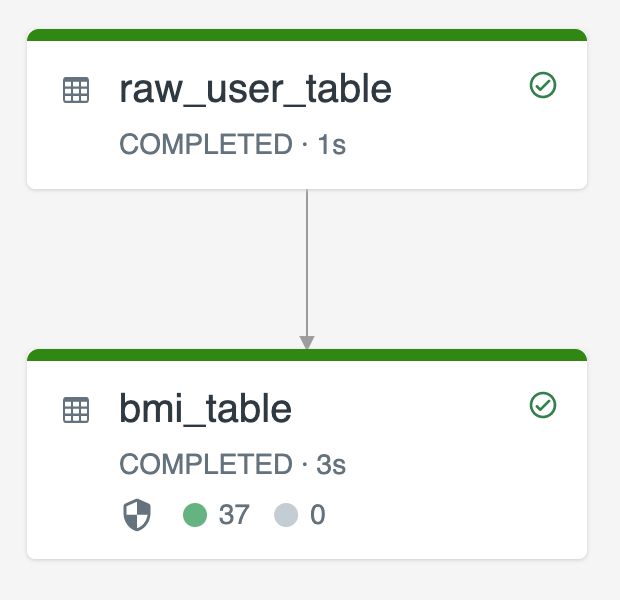
Le diagramme suivant illustre un exemple utilisant deux tables de streaming :
-
raw_user_tableingère des données utilisateur brutes à partir d’une source. -
bmi_tablecalcule de manière incrémentielle les scores de IMC à l’aide du poids et de la hauteur deraw_user_table.
Vous souhaitez supprimer ou mettre à jour manuellement les enregistrements utilisateur de raw_user_table, et recalculer le bmi_table.
Le code suivant illustre l’affectation de la valeur pipelines.reset.allowed à la propriété de table false pour désactiver l’actualisation complète de raw_user_table. Ainsi, les changements prévus sont conservés au fil du temps, mais les tables en aval sont recalculées quand une mise à jour du pipeline est exécutée :
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM read_files("/databricks-datasets/iot-stream/data-user", "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(raw_user_table);